




在 2024 年 4 月,我们发布了 Jina Reader,这是一个简单的 API,只需添加前缀 r.jina.ai 就能将任何 URL 转换为适合 LLM 使用的 markdown 格式。尽管背后涉及复杂的网络编程,但核心的"阅读"部分其实很直观。首先,我们使用无头 Chrome 浏览器获取网页源代码。然后,我们利用 Mozilla 的 Readability 包来提取主要内容,移除页眉、页脚、导航栏和侧边栏等元素。最后,我们使用 regex 和 Turndown 库将清理后的 HTML 转换为 markdown。最终得到的是一个结构良好的 markdown 文件,可供 LLM 用于知识增强、总结和推理。
在 Jina Reader 发布的最初几周,我们收到了大量反馈,特别是关于内容质量的问题。有些用户认为内容太详细,而其他人则觉得不够详细。还有报告说 Readability 过滤器移除了错误的内容,或者 Turndown 在将某些 HTML 部分转换为 markdown 时遇到困难。幸运的是,通过添加新的正则表达式模式或启发式规则,我们成功解决了许多这些问题。
从那时起,我们一直在思考一个问题:与其用更多的启发式规则和正则表达式来修补(这越来越难以维护,而且不利于多语言支持),我们能否用语言模型来实现端到端的解决方案?
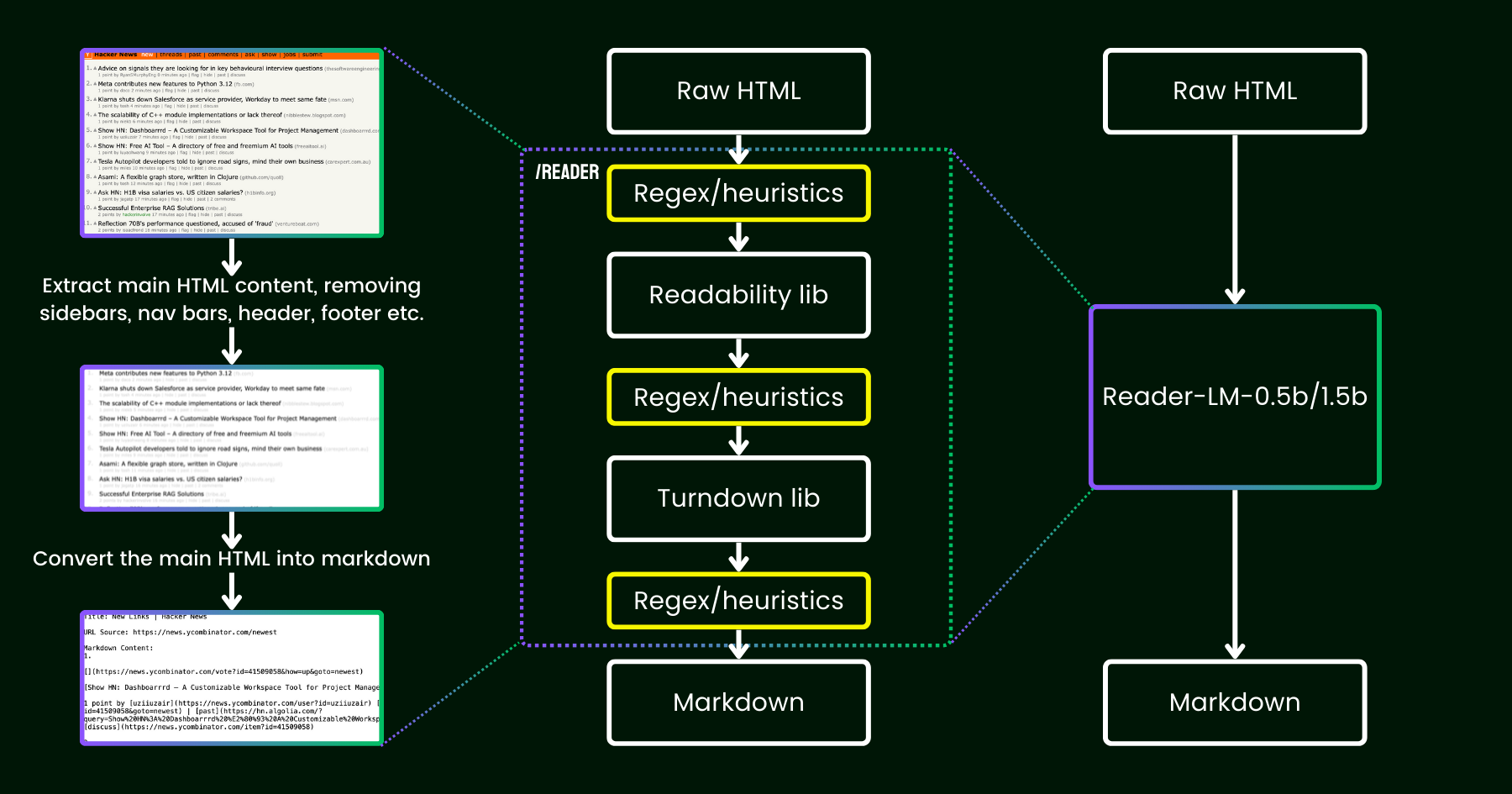
reader-lm,使用小型语言模型替代 readability+turndown+regex 启发式规则的管道。乍看之下,使用 LLM 进行数据清理似乎有些过度,因为它们的成本效益低且速度较慢。但如果我们考虑使用一个小型语言模型(SLM)——参数少于 10 亿,可以在边缘设备上高效运行的模型呢?这听起来就更有吸引力了,对吧?但这真的可行吗,还是只是一厢情愿?根据缩放定律,参数越少通常意味着推理和总结能力越弱。因此,如果参数规模太小,SLM 甚至可能难以生成任何有意义的内容。让我们进一步分析 HTML 转 Markdown 这个任务:
- 首先,我们考虑的任务不像典型的 LLM 任务那样需要创造性和复杂性。在将 HTML 转换为 markdown 的情况下,模型主要需要对输入进行选择性复制(即跳过 HTML 标记、侧边栏、页眉、页脚),只需花费很少的精力生成新内容(主要是插入 markdown 语法)。这与 LLM 处理的更广泛任务(如生成诗歌或编写代码)形成鲜明对比,后者的输出涉及更多创造性,而不是直接从输入复制粘贴。这个观察表明 SLM 可能可行,因为这个任务看起来比更通用的文本生成简单。
- 其次,我们需要优先考虑长文本上下文支持。现代 HTML 通常包含比简单的
<div>标记更多的噪声。内联 CSS 和脚本很容易使代码膨胀到数十万个 token。要使 SLM 在这种情况下实用,上下文长度必须足够大。像 8K 或 16K 这样的 token 长度完全不够用。
看来我们需要的是一个浅而宽的 SLM。"浅"是指任务主要是简单的"复制粘贴",因此需要较少的 transformer 模块;"宽"是指它需要长文本上下文支持才能实用,所以注意力机制需要特别设计。之前的研究表明,上下文长度和推理能力是密切相关的。对于 SLM 来说,在保持参数规模小的同时优化这两个维度是极具挑战性的。
今天,我们很高兴宣布推出这个解决方案的第一个版本:reader-lm-0.5b 和 reader-lm-1.5b,这两个 SLM 经过专门训练,可以直接从嘈杂的原始 HTML 生成整洁的 markdown。两个模型都支持多语言,并且支持长达 256K tokens 的上下文长度。尽管规模小巧,这些模型在此任务上达到了最先进的性能,超越了更大的 LLM,同时只有它们尺寸的 1/50。

以下是这两个模型的规格:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # Parameters | 494M | 1.54B |
| Context length | 256K | 256K |
| Hidden Size | 896 | 1536 |
| # Layers | 24 | 28 |
| # Query Heads | 14 | 12 |
| # KV Heads | 2 | 2 |
| Head Size | 64 | 128 |
| Intermediate Size | 4864 | 8960 |
| Multilingual | Yes | Yes |
| HuggingFace Repo | Link | Link |
tag开始使用 Reader-LM
tag在 Google Colab 上使用
体验 reader-lm 最简单的方法是运行我们的 Colab notebook,在其中我们演示了如何使用 reader-lm-1.5b 将 Hacker News 网站转换为 markdown。该 notebook 已针对 Google Colab 的免费 T4 GPU 进行了优化。您也可以加载 reader-lm-0.5b 或将 URL 更改为任何网站并探索输出结果。请注意,模型的输入(即提示)是原始 HTML——不需要任何前缀指令。

请注意,免费版 T4 GPU 有一些限制,可能会影响模型执行时的高级优化使用。T4 不支持 bfloat16 和 flash attention 等特性,这可能会导致更高的 VRAM 使用率,以及在处理较长输入时性能较慢。对于生产环境,我们建议使用 RTX 3090/4090 等更高端的 GPU 以获得显著更好的性能。
tag生产环境:即将登陆 Azure 和 AWS
Reader-LM 已在 Azure Marketplace 和 AWS SageMaker 上提供。如果您需要在这些平台之外或在公司内部使用这些模型,请注意两个模型都采用 CC BY-NC 4.0 许可证。如需商业用途咨询,请随时联系我们。


tag基准测试
为了定量评估 Reader-LM 的性能,我们将其与多个大型语言模型进行了比较,包括:GPT-4o、Gemini-1.5-Flash、Gemini-1.5-Pro、LLaMA-3.1-70B、Qwen2-7B-Instruct。
使用以下指标评估这些模型:
- ROUGE-L(越高越好):这个指标在摘要和问答任务中广泛使用,用于衡量预测输出和参考在 n-gram 层面的重叠程度。
- Token Error Rate(TER,越低越好):这个指标计算生成的 markdown 标记在原始 HTML 内容中不出现的比率。我们设计这个指标来评估模型的幻觉率,帮助我们识别模型产生未在 HTML 中出现的内容的情况。将基于案例研究进行进一步改进。
- Word Error Rate(WER,越低越好):在 OCR 和 ASR 任务中常用,WER 考虑词序并计算插入(ADD)、替换(SUB)和删除(DEL)等错误。这个指标详细评估生成的 markdown 与预期输出之间的不匹配。
为了使用 LLM 完成这个任务,我们使用了以下统一的指令作为前缀提示:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.结果如下表所示。
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tag定性研究
我们通过视觉检查输出的 markdown 进行了定性研究。我们选择了 22 个 HTML 源,包括新闻文章、博客文章、落地页、电商页面和论坛帖子,涉及多种语言:英语、德语、日语和中文。我们还将 Jina Reader API 作为基线,它依赖正则表达式、启发式方法和预定义规则。
评估聚焦于输出的四个关键维度,每个模型按 1(最低)到 5(最高)的等级进行评分:
- 标题提取:评估每个模型如何识别和格式化文档的 h1、h2、...、h6 标题,使用正确的 markdown 语法。
- 主要内容提取:评估模型准确转换正文的能力,包括保留段落、格式化列表和维持表现的一致性。
- 丰富结构保存:分析每个模型如何有效维护文档的整体结构,包括标题、子标题、项目符号和有序列表。
- Markdown 语法使用:评估每个模型将 HTML 元素如
<a>(链接)、<strong>(粗体文本)和<em>(斜体)正确转换为相应 markdown 等价形式的能力。
结果如下图所示。

Reader-LM-1.5B 在所有维度上表现都很出色,尤其在结构保存和 markdown 语法使用方面表现突出。虽然它并不总是超越 Jina Reader API,但其性能与 Gemini 1.5 Pro 等更大的模型相当,使其成为大型 LLM 的高效替代方案。Reader-LM-0.5B 尽管规模较小,但仍表现稳健,特别是在结构保存方面。
tag我们如何训练 Reader-LM
tag数据准备
我们使用 Jina Reader API 生成原始 HTML 及其对应 markdown 的训练对。在实验过程中,我们发现 SLM 对训练数据的质量特别敏感。因此我们构建了一个数据管道,确保只有高质量的 markdown 条目被包含在训练集中。
此外,我们添加了一些由 GPT-4o 生成的合成 HTML 及其 markdown 对应内容。与真实世界的 HTML 相比,合成数据往往更短,结构更简单和可预测,噪声水平也显著降低。
最后,我们使用聊天模板连接 HTML 和 markdown。最终的训练数据格式如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
完整的训练数据总计 25 亿个标记。
tag两阶段训练
我们实验了从 65M 和 135M 到 3B 参数的各种模型规模。下表列出了每个模型的具体规格。
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
模型训练分为两个阶段:
- 简短 HTML:在这个阶段,最大序列长度(HTML + markdown)设置为 32K tokens,总共训练了 15 亿个 tokens。
- 长文本复杂 HTML:序列长度扩展到 128K tokens,训练了 12 亿个 tokens。我们在这个阶段实现了来自朱子林的"Ring Flash Attention"(2024)的 zigzag-ring-attention 机制。
由于训练数据包含了长达 128K tokens 的序列,我们认为模型可以毫无问题地支持到 256K tokens。然而,处理 512K tokens 可能会有挑战,因为将 RoPE 位置编码扩展到训练序列长度的四倍可能会导致性能下降。
对于 65M 和 135M 参数的模型,我们观察到它们能够实现合理的"复制"行为,但仅限于短序列(少于 1K tokens)。随着输入长度的增加,这些模型难以产生任何合理的输出。考虑到现代 HTML 源代码很容易超过 100K tokens,1K tokens 的限制远远不够。
tag退化和无趣循环
我们遇到的主要挑战之一是退化,特别是以重复和循环的形式出现。在生成一些 tokens 后,模型会开始重复生成相同的 token,或陷入循环,不断重复一个短序列的 tokens,直到达到最大允许的输出长度。

为解决这个问题:
- 我们采用了对比搜索作为解码方法,并在训练过程中加入对比损失。根据我们的实验,这种方法在实践中有效地减少了重复生成。
- 我们在 transformer pipeline 中实现了一个简单的重复停止标准。这个标准会自动检测模型何时开始重复 tokens,并提前停止解码以避免无趣循环。这个想法受到了这个讨论的启发。
tag长输入的训练效率
为了降低处理长输入时内存溢出(OOM)的风险,我们实现了分块模型前向传播。这种方法用较小的块来编码长输入,减少显存使用。
我们改进了基于 Transformers Trainer 的训练框架中的数据打包实现。为了优化训练效率,多个短文本(如 2K tokens)被连接成一个长序列(如 30K tokens),实现无填充训练。然而,在原始实现中,一些短样例被分成两个子文本并包含在不同的长训练序列中。在这种情况下,第二个子文本会失去其上下文(在我们的案例中是原始 HTML 内容),导致训练数据损坏。这迫使模型依赖其参数而不是输入上下文,我们认为这是幻觉的主要来源。
最终,我们选择了 0.5B 和 1.5B 模型进行发布。0.5B 模型是能够在长上下文输入上实现所需"选择性复制"行为的最小模型,而 1.5B 模型是在不产生参数规模相关的收益递减的情况下,能显著提升性能的最小模型。
tag替代架构:仅编码器模型
在项目早期,我们也探索了使用仅编码器架构来处理这个任务。如前所述,HTML 到 Markdown 的转换任务主要是一个"选择性复制"任务。给定一个训练对(原始 HTML 和 markdown),我们可以将同时存在于输入和输出中的 tokens 标记为 1,其余的标记为 0。这将问题转换为一个类似于命名实体识别(NER)的 token 分类任务。
虽然这种方法看起来合理,但在实践中遇到了重大挑战。首先,来自真实世界的原始 HTML 极其嘈杂且冗长,使得 1 标签极其稀疏,因此模型难以学习。其次,在 0-1 模式中编码特殊的 markdown 语法证明是有问题的,因为像 ## title、*bold* 和 | table | 这样的符号在原始 HTML 输入中并不存在。第三,输出 tokens 并不总是严格遵循输入的顺序。特别是在表格和链接中经常发生微小的重排序,这使得在简单的 0-1 模式中表示这种重排序行为变得困难。短距离重排序可以通过动态规划或对齐扭曲算法引入像 -1, -2, +1, +2 这样的标签来表示距离偏移,将二元分类问题转换为多类 token 分类任务。
总的来说,使用仅编码器架构并将其作为 token 分类任务来解决问题有其魅力,特别是因为与仅解码器模型相比,训练序列要短得多,这使得它更加显存友好。然而,主要挑战在于准备好的训练数据。当我们意识到在数据预处理上花费的时间和精力——使用动态规划和启发式方法来创建完美的 token 级别标记序列——过于庞大时,我们决定放弃这种方法。
tag结论
Reader-LM 是一款专门用于网络数据提取和清洗的新型小型语言模型(SLM)。受 Jina Reader 的启发,我们的目标是创建一个能够将原始、杂乱的 HTML 转换为整洁 markdown 的端到端语言模型解决方案。同时,我们注重成本效益,保持模型规模较小,以确保 Reader-LM 实用且可用。这也是 Jina AI 首个训练的解码器专用长上下文模型。
虽然这项任务最初看起来像是一个简单的"选择性复制"问题,但将 HTML 转换和清洗为 markdown 远非易事。具体来说,它要求模型在位置感知和基于上下文的推理方面表现出色,这需要更大的参数规模,特别是在隐藏层方面。相比之下,学习 markdown 语法相对简单直接。
在实验过程中,我们还发现从头开始训练 SLM 特别具有挑战性。从预训练模型开始,然后继续进行特定任务训练,显著提高了训练效率。在效率和质量方面仍有很大的改进空间:扩展上下文长度、加快解码速度,以及在输入中添加指令支持,这将使 Reader-LM 能够将网页的特定部分提取为 markdown。
