

在将 Jina Embeddings 集成到 Deepset 的 Haystack 2.0 以及发布 Jina Reranker 之后,我们很高兴地宣布 Jina Reranker 现在也可以通过 Jina Haystack 扩展使用了。


Haystack 是一个端到端框架,可以在 GenAI 项目生命周期的每个步骤中为您提供支持。无论您想要执行文档搜索、检索增强生成(RAG)、问答还是答案生成,Haystack 都可以将最先进的 embedding 模型和 LLM 编排到管道中,以构建端到端的 NLP 应用程序并解决您的用例。
在这篇文章中,我们将展示如何使用它们来创建您自己的 Jira 工单搜索引擎,以简化您的运营并且永远不会浪费时间创建重复的问题。
要学习本教程,您需要一个 Jina Reranker API 密钥。您可以从 Jina Reranker 网站创建一个包含一百万个令牌免费试用额度的密钥。
tag检索 Jira 支持工单
任何处理复杂项目的团队都经历过这种挫折感:想要提交一个问题,但不知道是否已经存在相关工单。
在接下来的教程中,我们将向您展示如何使用 Jina Reranker 和 Haystack 管道轻松创建一个工具,该工具可以为新创建的工单建议可能的重复工单。
- 通过输入需要与所有现有工单进行检查的工单,管道将首先从数据库中检索所有相关问题。
- 然后它会从列表中删除初始工单(如果它已经存在于数据库中)和任何子工单(即其父 ID 对应原始工单的工单)。
- 最终的选择现在只包括可能涵盖与原始工单相同主题的问题,但在数据库中未通过其 ID 标记为此类问题。这些工单会被重新排序以确保最大的相关性,并使您能够识别数据库中的重复条目。
tag获取数据集
要实现我们的解决方案,我们选择了 Apache Zookeeper 项目中所有"进行中"的 Jira 工单。这是一个用于协调分布式应用程序进程的开源服务。
我们已将工单放在一个 JSON 文件中以使其更方便使用。请下载该文件到您的工作空间。
tag设置前提条件
要安装必需的包,请运行:
pip install --q chromadb haystack-ai jina-haystack chroma-haystack
要输入 API 密钥,将其设置为环境变量:
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
getpass.getpass() 将提示您在相应的代码块下输入 API 密钥。您可以在那里输入密钥并按 enter 键继续教程。如果您愿意,也可以直接用 API 密钥替换 getpass.getpass()。tag构建索引管道
索引管道将预处理工单,将它们转换为向量并存储。我们将使用 Chroma DocumentStore 作为我们的向量数据库来存储向量 embeddings,通过 Chroma Document Store Haystack 集成。
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore()
我们将首先定义我们的自定义数据预处理器,只考虑相关的文档字段并删除所有空条目:
import json
from typing import List
from haystack import Document, component
relevant_keys = ['Summary', 'Issue key', 'Issue id', 'Parent id', 'Issue type', 'Status', 'Project lead', 'Priority', 'Assignee', 'Reporter', 'Creator', 'Created', 'Updated', 'Last Viewed', 'Due Date', 'Labels',
'Description', 'Comment', 'Comment__1', 'Comment__2', 'Comment__3', 'Comment__4', 'Comment__5', 'Comment__6', 'Comment__7', 'Comment__8', 'Comment__9', 'Comment__10', 'Comment__11', 'Comment__12',
'Comment__13', 'Comment__14', 'Comment__15']
@component
class RemoveKeys:
@component.output_types(documents=List[Document])
def run(self, file_name: str):
with open(file_name, 'r') as file:
tickets = json.load(file)
cleaned_tickets = []
for t in tickets:
t = {k: v for k, v in t.items() if k in relevant_keys and v}
cleaned_tickets.append(t)
return {'documents': cleaned_tickets}
然后我们需要创建一个自定义 JSON 转换器,将工单转换为 Haystack 可以理解的 Document 对象:
@component
class JsonConverter:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document]):
tickets_documents = []
for t in tickets:
if 'Parent id' in t:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': t['Parent id']})
else:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': ''})
tickets_documents.append(t)
return {'documents': tickets_documents}
最后,我们对 Documents 进行 embedding 并将这些 embeddings 写入 ChromaDocumentStore:
from haystack import Pipeline
from haystack.components.writers import DocumentWriter
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.components.embedders.jina import JinaDocumentEmbedder
retriever = ChromaEmbeddingRetriever(document_store=document_store)
retriever_reranker = ChromaEmbeddingRetriever(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component('cleaner', RemoveKeys())
indexing_pipeline.add_component('converter', JsonConverter())
indexing_pipeline.add_component('embedder', JinaDocumentEmbedder(model='jina-embeddings-v2-base-en'))
indexing_pipeline.add_component('writer', DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
indexing_pipeline.connect('cleaner', 'converter')
indexing_pipeline.connect('converter', 'embedder')
indexing_pipeline.connect('embedder', 'writer')
indexing_pipeline.run({'cleaner': {'file_name': 'tickets.json'}})
这应该会创建一个进度条并输出一个简短的 JSON,其中包含有关存储内容的信息:
Calculating embeddings: 100%|██████████| 1/1 [00:01<00:00, 1.21s/it]
{'embedder': {'meta': {'model': 'jina-embeddings-v2-base-en',
'usage': {'total_tokens': 20067, 'prompt_tokens': 20067}}},
'writer': {'documents_written': 31}}tag构建查询流程
让我们创建一个查询流程,以便开始比较工单。在 Haystack 2.0 中,检索器与 DocumentStore 紧密耦合。如果我们在之前初始化的检索器中传入文档存储,这个流程就可以访问我们生成的文档,并将它们传递给重排序器。重排序器然后直接将这些文档与问题进行比较,并基于相关性对它们进行排序。
我们首先定义一个自定义清理器,用于移除包含与作为查询传入的工单相同的问题 ID 或父 ID 的工单:
from typing import Optional
@component
class RemoveRelated:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document], query_id: Optional[str]):
retrieved_tickets = []
for t in tickets:
if not t.meta['Issue id'] == query_id and not t.meta['Parent id'] == query_id:
retrieved_tickets.append(t)
return {'documents': retrieved_tickets}
然后我们对查询进行嵌入,检索相关文档,清理选择,最后进行重排序:
from haystack_integrations.components.embedders.jina import JinaTextEmbedder
from haystack_integrations.components.rankers.jina import JinaRanker
query_pipeline_reranker = Pipeline()
query_pipeline_reranker.add_component('query_embedder_reranker', JinaTextEmbedder(model='jina-embeddings-v2-base-en'))
query_pipeline_reranker.add_component('query_retriever_reranker', retriever_reranker)
query_pipeline_reranker.add_component('query_cleaner_reranker', RemoveRelated())
query_pipeline_reranker.add_component('query_ranker_reranker', JinaRanker())
query_pipeline_reranker.connect('query_embedder_reranker.embedding', 'query_retriever_reranker.query_embedding')
query_pipeline_reranker.connect('query_retriever_reranker', 'query_cleaner_reranker')
query_pipeline_reranker.connect('query_cleaner_reranker', 'query_ranker_reranker')
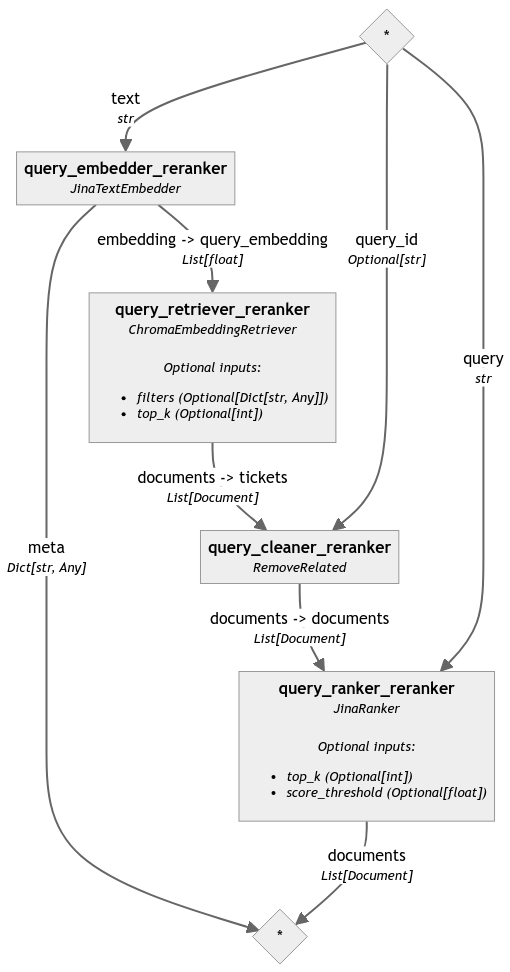
为了突出重排序器带来的差异,我们分析了同一个流程但去掉最后重排序步骤的情况(为了便于阅读,本文省略了相应的代码,但可以在 notebook 中找到):
为了比较这两个流程的结果,我们现在以现有工单的形式定义查询,这里是"ZOOKEEPER-3282":
query_ticket_key = 'ZOOKEEPER-3282'
with open('tickets.json', 'r') as file:
tickets = json.load(file)
for ticket in tickets:
if ticket['Issue key'] == query_ticket_key:
query = str(ticket)
query_ticket_id = ticket['Issue id']
它涉及"文档的一次大规模重构"[原文如此]。你会看到,尽管有拼写错误,Jina Reranker 仍然能够正确检索到相似的工单。
{
"Summary": "a big refactor for the documetations"
"Issue key": "ZOOKEEPER-3282"
"Issue id:: 13216608
"Parent id": ""
"Issue Type": "Task"
"Status": "In Progress"
"Project lead": "phunt"
"Priority": "Major"
"Assignee": "maoling"
"Reporter": "maoling"
"Creator": "maoling"
"Created": "19/Feb/19 11:50"
"Updated": "04/Aug/19 12:48"
"Last Viewed": "12/Mar/24 11:56"
"Description": "Hi guys: I'am working on doing a big refactor for the documetations.it aims to - 1.make a better reading experiences and help users know more about zookeeper quickly,as good as other projects' doc(e.g redis,hbase). - 2.have less changes to diff with the original docs as far as possible. - 3.solve the problem when we have some new features or improvements,but cannot find a good place to doc it. The new catalog may looks kile this: * is new one added. ** is the one to keep unchanged as far as possible. *** is the one modified. -------------------------------------------------------------- |---Overview |---Welcome ** [1.1] |---Overview ** [1.2] |---Getting Started ** [1.3] |---Release Notes ** [1.4] |---Developer |---API *** [2.1] |---Programmer's Guide ** [2.2] |---Recipes *** [2.3] |---Clients * [2.4] |---Use Cases * [2.5] |---Admin & Ops |---Administrator's Guide ** [3.1] |---Quota Guide ** [3.2] |---JMX ** [3.3] |---Observers Guide ** [3.4] |---Dynamic Reconfiguration ** [3.5] |---Zookeeper CLI * [3.6] |---Shell * [3.7] |---Configuration flags * [3.8] |---Troubleshooting & Tuning * [3.9] |---Contributor Guidelines |---General Guidelines * [4.1] |---ZooKeeper Internals ** [4.2] |---Miscellaneous |---Wiki ** [5.1] |---Mailing Lists ** [5.2] -------------------------------------------------------------- The Roadmap is: 1.(I pick up it : D) 1.1 write API[2.1], which includes the: 1.1.1 original API Docs which is a Auto-generated java doc,just give a link. 1.1.2. Restful-api (the apis under the /zookeeper-contrib-rest/src/main/java/org/apache/zookeeper/server/jersey/resources) 1.2 write Clients[2.4], which includes the: 1.2.1 C client 1.2.2 zk-python, kazoo 1.2.3 Curator etc....... look at an example from: https://redis.io/clients # write Recipes[2.3], which includes the: - integrate "Java Example" and "Barrier and Queue Tutorial"(Since some bugs in the examples and they are obsolete,we may delete something) into it. - suggest users to use the recipes implements of Curator and link to the Curator's recipes doc. # write Zookeeper CLI[3.6], which includes the: - about how to use the zk command line interface [./zkCli.sh] e.g ls /; get ; rmr;create -e -p etc....... - look at an example from redis: https://redis.io/topics/rediscli # write shell[3.7], which includes the: - list all usages of the shells under the zookeeper/bin. (e.g zkTxnLogToolkit.sh,zkCleanup.sh) # write Configuration flags[3.8], which includes the: - list all usages of configurations properties(e.g zookeeper.snapCount): - move the original Advanced Configuration part of zookeeperAdmin.md into it. look at an example from:https://coreos.com/etcd/docs/latest/op-guide/configuration.html # write Troubleshooting & Tuning[3.9], which includes the: - move the original "Gotchas: Common Problems and Troubleshooting" part of Administrator's Guide.md into it. - move the original "FAQ" into into it. - add some new contents (e.g https://www.yumpu.com/en/document/read/29574266/building-an-impenetrable-zookeeper-pdf-github). look at an example from:https://redis.io/topics/problems https://coreos.com/etcd/docs/latest/tuning.html # write General Guidelines[4.1], which includes the: - move the original "Logging" part of ZooKeeper Internals into it as the logger specification. - write specifications about code, git commit messages,github PR etc ... look at an example from: http://hbase.apache.org/book.html#hbase.commit.msg.format # write Use Cases[2.5], which includes the: - just move the context from: https://cwiki.apache.org/confluence/display/ZOOKEEPER/PoweredBy into it. - add some new contents.(e.g Apache Projects:Spark;Companies:twitter,fb) -------------------------------------------------------------- BTW: - Any insights or suggestions are very welcomed.After the dicussions,I will create a series of tickets(An umbrella) - Since these works can be done parallelly, if you are interested in them, please don't hesitate,just assign to yourself, pick it up. (Notice: give me a ping to avoid the duplicated work)."
}
最后,我们运行查询流程。在这种情况下,它检索 20 个工单,删除 ID 相关条目,对它们重新排序,并输出 10 个最相关问题的最终选择。
在 reranking 步骤之前,输出包含 17 个 tickets:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13191544 | ZOOKEEPER-3170 | Umbrella for eliminating ZooKeeper flaky tests |
| 2 | 13400622 | ZOOKEEPER-4375 | Quota cannot limit the specify value when multiply clients create/set znodes |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 13295073 | ZOOKEEPER-3775 | Wrong message in IOException |
| 5 | 13268474 | ZOOKEEPER-3617 | ZK digest ACL permissions gets overridden |
| 6 | 13296971 | ZOOKEEPER-3787 | Apply modernizer-maven-plugin to build |
| 7 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 8 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
| 9 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 10 | 13262130 | ZOOKEEPER-3578 | Add a new CLI: multi |
| 11 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 12 | 13262494 | ZOOKEEPER-3583 | Add new apis to get node type and ttl time info |
| 13 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 14 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 15 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 16 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 17 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
加入 reranker 后,现在运行查询管道:
result = query_pipeline_reranker.run(data={'query_embedder_reranker':{'text': query},
'query_retriever_reranker': {'top_k': 20},
'query_cleaner_reranker': {'query_id': query_ticket_id},
'query_ranker_reranker': {'query': query, 'top_k': 10}
}
)
for idx, res in enumerate(result['query_ranker_reranker']['documents']):
print('Doc {}:'.format(idx + 1), res)
最终输出的 10 个最相关的 tickets:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 2 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
| 5 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 6 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 7 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 8 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 9 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 10 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
tagJina Embeddings 和 Reranker 的优势
总结本教程,我们基于 Jina Embeddings、Jina Reranker 和 Haystack 2.0 构建了一个重复 ticket 识别工具。上述结果清楚地显示了同时使用 Jina Embeddings(通过向量搜索检索相关文档)和 Jina Reranker(获取最相关内容)的必要性。
例如,如果我们看两个关于添加文档的问题,即"ZOOKEEPER-3585"和"ZOOKEEPER-3587",我们可以看到在检索步骤之后,它们分别位于第 11 和第 9 位。经过文档重新排序后,它们现在都进入了前 5 个最相关文档,分别位于第 5 和第 1 位,显示出显著的改进。
通过在 Haystack 的管道中集成这两个模型,整个工具就可以投入使用了。这种组合使得 Jina Haystack 扩展成为您应用的完美解决方案。





