


自从 OpenAI 发布了 O1 模型以来,AI 社区最热议的话题之一就是扩展测试时计算。这指的是在推理阶段(AI 模型对输入生成输出的阶段)而不是预训练阶段分配额外的计算资源。一个广为人知的例子是"思维链"多步推理,它使模型能够进行更广泛的内部深思,比如评估多个潜在答案、更深入的规划、在得出最终答案前的自我反思。这种策略提高了答案质量,特别是在复杂推理任务中。阿里巴巴最近发布的 QwQ-32B-Preview 模型就遵循了这种通过增加测试时计算来改进 AI 推理的趋势。
在使用 OpenAI 的 O1 模型时,用户可以清楚地注意到多步推理需要额外的时间,因为模型需要构建推理链来解决问题。
在 Jina AI,我们更关注 embeddings 和 rerankers 而不是 LLMs,所以对我们来说,从这个角度考虑扩展测试时计算是很自然的:如何将"思维链"应用于 embedding 模型?虽然这一开始可能不太直观,但本文探讨了一个新的视角,并展示了如何将扩展测试时计算应用于 jina-clip 来对分布外(OOD)图像进行分类——解决原本不可能完成的任务。

tag案例研究

我们的实验使用 TheFusion21/PokemonCards 数据集进行宝可梦分类,该数据集包含数千张宝可梦卡牌图像。这是一个图像分类任务,输入是裁剪后的宝可梦卡牌艺术作品(移除了所有文字/描述),输出是从预定义名称集中选择正确的宝可梦名称。这个任务对 CLIP embedding 模型来说特别具有挑战性,因为:
- 宝可梦的名称和视觉表现对模型来说属于小众、分布外的概念,使直接分类变得具有挑战性
- 每个宝可梦都有明显的视觉特征,可以分解为基本元素(形状、颜色、姿势),这些是 CLIP 可能更容易理解的
- 卡牌艺术作品提供了一致的视觉格式,同时通过不同的背景、姿势和艺术风格引入了复杂性
- 该任务需要同时整合多个视觉特征,类似于语言模型中的复杂推理链

Absol G,Aerodactyl,Weedle,Caterpie、Azumarill、Bulbasaur、Venusaur、Absol、Aggron、Beedrill δ、Alakazam、Ampharos、Dratini、Ampharos、Ampharos、Arcanine、Blaine's Moltres、Aerodactyl、Celebi & Venusaur-GX、Caterpie]tag基准方法
基准方法使用宝可梦卡牌插图和名称之间的简单直接比较。首先,我们裁剪每张宝可梦卡牌图片以移除所有文字信息(标题、页脚、描述),以防止 CLIP 模型因这些文本中出现的宝可梦名称而进行简单猜测。然后我们使用 jina-clip-v1 和 jina-clip-v2 模型对裁剪后的图片和宝可梦名称进行编码,获取各自的嵌入表示。分类是通过计算这些图像和文本嵌入之间的余弦相似度来完成的——每个图像都与具有最高相似度分数的名称相匹配。这在卡牌插图和宝可梦名称之间建立了直接的一对一匹配,而不需要任何额外的上下文或属性信息。下面的伪代码总结了基准方法。
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag分类的"思维链"
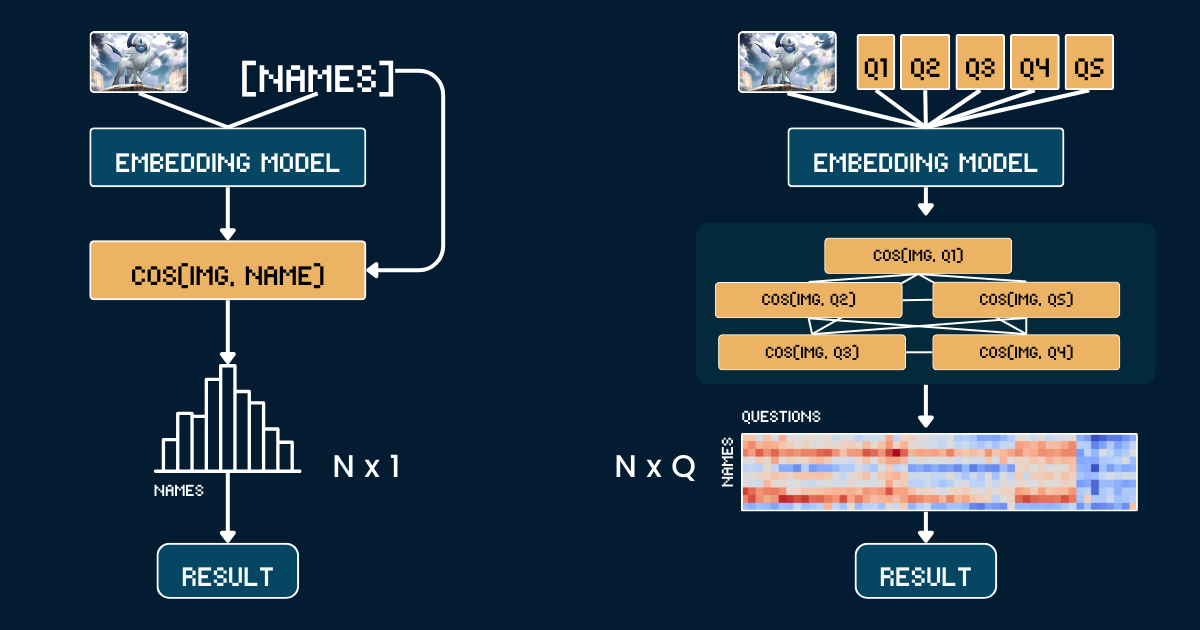
我们不是直接将图像与名称匹配,而是将宝可梦识别分解为一个结构化的视觉属性系统。我们定义了五个关键属性组:主要颜色(如"白色"、"蓝色")、主要形态(如"一只狼"、"一只有翅膀的爬行动物")、关键特征(如"一只白色的角"、"大翅膀")、体型(如"四脚着地的狼形"、"有翅膀且纤细")以及背景场景(如"外太空"、"绿色森林")。
对于每个属性组,我们创建特定的文本提示(如"这个宝可梦的身体主要是{}色的")与相关选项配对。然后我们使用模型计算图像与每个属性选项之间的相似度分数。这些分数通过 softmax 转换为概率,以获得更校准的置信度衡量。
完整的思维链(CoT)结构包含两个部分:classification_groups 描述提示组,以及 pokemon_rules 定义每个宝可梦应该匹配哪些属性选项。例如,Absol 应该在颜色上匹配"白色",在形态上匹配"狼形"。完整的 CoT 如下所示(我们稍后会解释如何构建):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
最终的分类结合了这些属性概率——我们现在不是进行单一的相似度比较,而是进行多个结构化比较并聚合它们的概率,以做出更明智的决定。
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tag复杂度分析
假设我们要将一张图像分类到 N 个宝可梦名称中的一个。基准方法需要计算 N 个文本嵌入(每个宝可梦名称一个)。相比之下,我们的缩放测试时间计算方法需要计算 Q 个文本嵌入,其中
Q 是所有问题中问题-选项组合的总数。两种方法都需要计算一个图像嵌入并执行最终分类步骤,因此我们在比较中排除这些共同操作。在本案例研究中,我们的 N=13 和 Q=52。在极端情况下,当 Q = N 时,我们的方法实际上就会退化为基线方法。然而,有效扩展测试时计算的关键在于:
- 构建精心设计的问题以增加
Q - 确保每个问题都能为最终答案提供独特、有信息量的线索
- 设计尽可能正交的问题以最大化它们的联合信息增益
这种方法类似于"二十个问题"游戏,每个问题都经过战略性选择,以有效缩小可能的答案范围。
tag评估
我们的评估在 117 张测试图像上进行,涵盖 13 个不同的宝可梦类别。结果如下:
| 方法 | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| 基线 | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| 改进 | +15.25% | +22.04% |
可以看到,相同的 CoT 分类方法在这个不常见或分布外(OOD)任务上为两个模型都带来了显著的改进(分别提升了 15.25% 和 22.04%)。这也表明,一旦构建了 pokemon_system,同一个 CoT 系统可以有效地在不同模型之间迁移;并且不需要微调或后期训练。
值得注意的是 v1 在宝可梦分类上相对较强的基线性能(31.36%)。这个模型是在包含宝可梦相关内容的 LAION-400M 上训练的。相比之下,v2 是在 DFN-2B(抽样 400M 实例)上训练的,这是一个质量更高但经过更多过滤的数据集,可能排除了宝可梦相关内容,这解释了 v2 在这个特定任务上较低的基线性能(16.10%)。
tag有效构建 pokemon_system
我们的扩展测试时计算方法的有效性很大程度上取决于我们如何构建 pokemon_system。构建这个系统有不同的方法,从手动到完全自动化。
手动构建
最直接的方法是手动分析宝可梦数据集并创建属性组、提示和规则。领域专家需要识别关键的视觉属性,如颜色、形态和独特特征。然后为每个属性编写自然语言提示,列举每个属性组的可能选项,并将每个宝可梦映射到其正确的属性选项。虽然这提供了高质量的规则,但它很耗时且不适合更大的 N。
LLM 辅助构建
我们可以利用 LLM 来加速这个过程,通过提示它们生成分类系统。一个结构良好的提示应该要求基于视觉特征的属性组、自然语言提示模板、全面且互斥的选项,以及每个宝可梦的映射规则。LLM 可以快速生成初稿,尽管其输出可能需要验证。
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}一个更健壮的方法是将 LLM 生成与人工验证相结合。首先,LLM 生成一个初始系统。然后,人类专家审查和纠正属性分组、选项完整性和规则准确性。LLM 基于这些反馈完善系统,这个过程迭代进行直到达到令人满意的质量。这种方法在效率和准确性之间取得平衡。
使用 DSPy 自动化构建
对于完全自动化的方法,我们可以使用 DSPy 来迭代优化 pokemon_system。该过程从一个简单的 pokemon_system 开始,可以是手动或由 LLM 编写的初始提示。每个版本都在留出集上进行评估,使用准确率作为 DSPy 的反馈信号。基于这个性能,生成优化的提示(即新版本的 pokemon_system)。这个循环重复进行直到收敛,在整个过程中,嵌入模型完全保持固定。
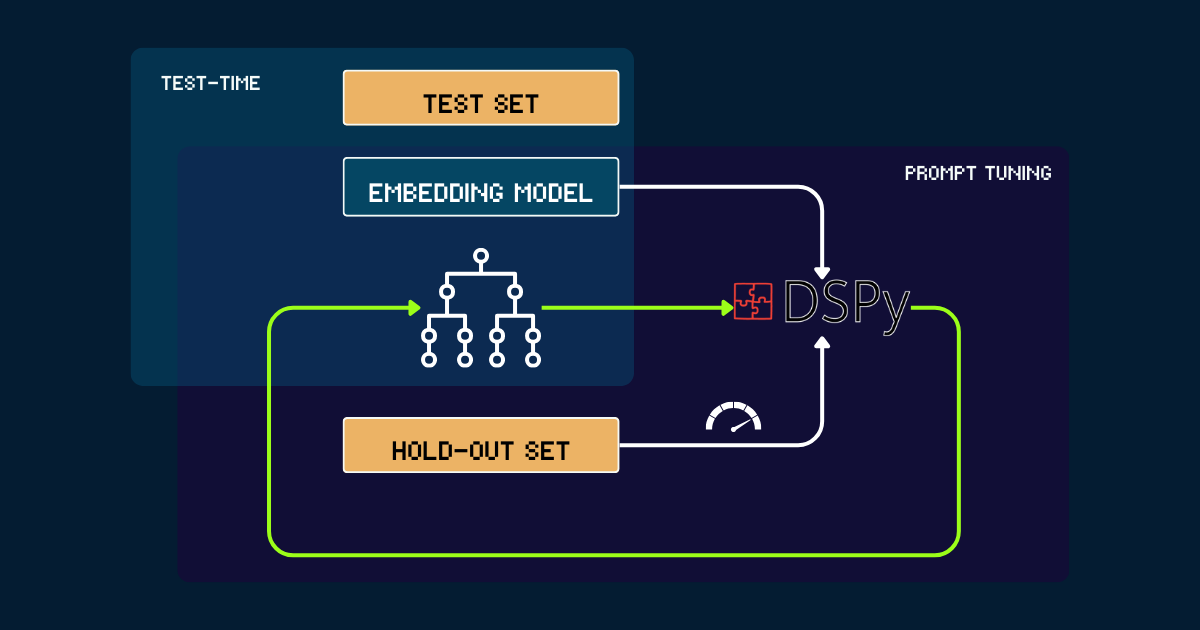
pokemon_system CoT 设计;每个任务只需要进行一次调优过程。tag为什么要扩展嵌入模型的测试时计算?
因为扩展预训练最终会变得在经济上难以承受。
自 Jina 嵌入套件发布以来——包括 jina-embeddings-v1、v2、v3、jina-clip-v1、v2 和 jina-ColBERT-v1、v2——每次通过扩展预训练进行的模型升级都带来了更多成本。例如,我们的第一个模型 jina-embeddings-v1 于 2023 年 6 月发布,拥有 1.1 亿参数。当时训练它的成本在 5,000 到 10,000 美元之间,具体取决于如何计算。对于 jina-embeddings-v3,改进显著,但主要来自增加的资源投入。前沿模型的成本轨迹已经从数千美元上升到数万美元,对于较大的 AI 公司,甚至达到了数亿美元。虽然在预训练上投入更多的金钱、资源和数据会产生更好的模型,但边际收益最终会使进一步扩展在经济上变得不可持续。

另一方面,现代嵌入模型正变得越来越强大:多语言、多任务、多模态,并且具有强大的零样本和遵循指令的性能。这种多功能性为算法改进和扩展测试时计算留下了很大空间。
问题转变为:用户愿意为他们深度关心的查询支付什么样的成本?如果容忍固定预训练模型更长的推理时间能显著提高结果质量,许多人会认为这是值得的。在我们看来,扩展嵌入模型的测试时计算还有很大的未开发潜力。这代表着一个转变,从仅仅在训练期间增加模型大小,转向在推理阶段增加计算努力以实现更好的性能。
tag结论
我们对 jina-clip-v1/v2 测试时计算的案例研究显示了几个关键发现:
- 我们在不常见或分布外(OOD)数据上取得了更好的性能,而无需对嵌入进行任何微调或后期训练。
- 系统通过迭代细化相似度搜索和分类标准,做出了更细致的区分。
- 通过纳入动态提示调整和迭代推理,我们将嵌入模型的推理过程从单一查询转变为更复杂的思维链。
这个案例研究仅仅触及了测试时计算可能性的表面。在算法上仍有很大的扩展空间。例如,我们可以开发方法来迭代选择最有效缩小答案空间的问题,类似于"二十个问题"游戏中的最优策略。通过扩展测试时计算,我们可以推动嵌入模型超越其当前限制,使它们能够处理曾经看似无法达到的更复杂、更微妙的任务。
