


Jina AI 在其顶尖重排模型系列中推出新模型,现已在 AWS Sagemaker 和 Hugging Face 上线:jina-reranker-v1-turbo-en 和 jina-reranker-v1-tiny-en。这些模型在保持标准基准测试高性能的同时优先考虑速度和体积,为那些对响应时间和资源使用要求严格的环境提供更快速、更节省内存的重排流程。




Reranker Turbo 和 Tiny 为信息检索应用优化了极速响应时间。与我们的嵌入模型一样,它们使用 JinaBERT 架构,这是一种增强了对称双向 ALiBi 变体的 BERT 架构。这种架构支持长文本序列,我们的模型可接受多达 8,192 个令牌,非常适合对大型文档进行深度分析和需要详细语言理解的复杂查询。
Turbo 和 Tiny 模型借鉴了Jina Reranker v1 的经验。重排可能是信息检索应用的主要瓶颈。传统搜索应用是一项非常成熟的技术,其性能已经得到充分理解。重排器为基于文本的检索增加了很高的精确度,但 AI 模型体积大,运行可能较慢且成本较高。
许多用户更倾向于使用更小、更快、更便宜的模型,即使这会在一定程度上影响准确性。有了单一目标——重排搜索结果——就可以精简模型,在更紧凑的模型中为用户提供有竞争力的性能。通过减少隐藏层,我们加快了处理速度并减小了模型体积。这些模型运行成本更低,更快的速度使它们更适用于不能容忍太多延迟的应用,同时保留了几乎所有大型模型的性能。
在本文中,我们将向您展示 Reranker Turbo 和 Reranker Tiny 的架构,测量其性能,并向您展示如何开始使用它们。
tag精简架构
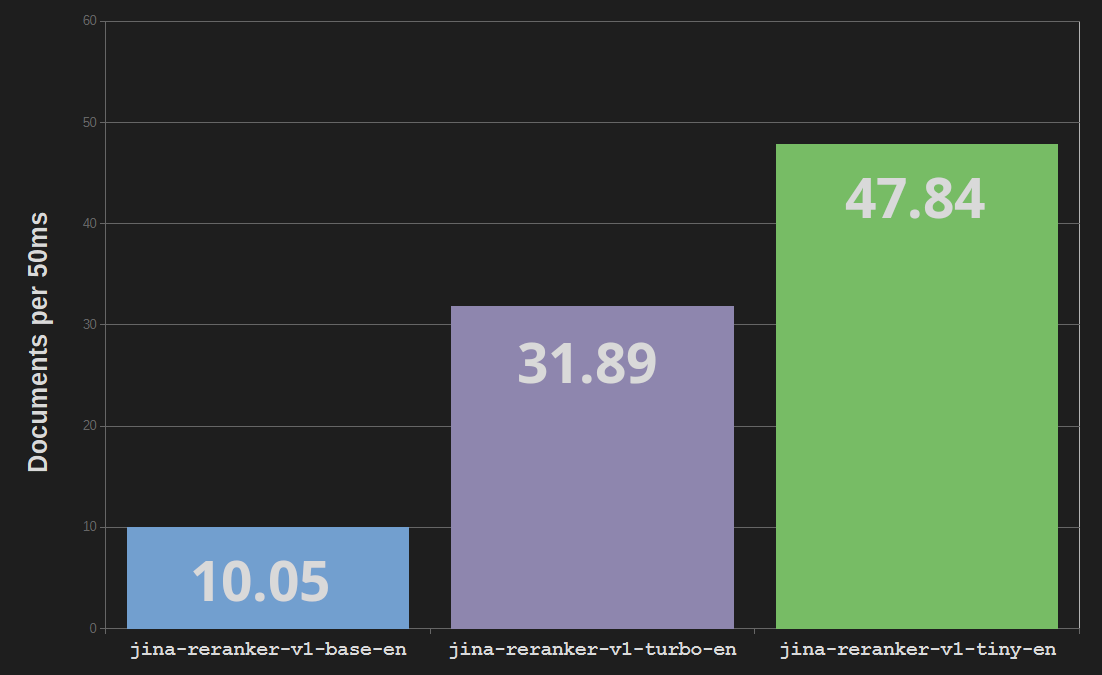
Jina Reranker Turbo(jina-reranker-v1-turbo-en)使用六层架构,总共 3,780 万个参数,而基础重排模型 jina-reranker-v1-base-en 则有 1.37 亿个参数和十二层。这使模型体积减少了四分之三,处理速度提高了近三倍。
Reranker Tiny(jina-reranker-v1-tiny-en)使用四层架构,有 3,300 万个参数,提供更强的并行处理能力和更快的速度——比基础 Reranker 模型快近五倍——同时比 Turbo 模型节省 13% 的内存成本。
tag知识蒸馏
我们使用知识蒸馏技术训练 Reranker Turbo 和 Tiny。这是一种使用现有 AI 模型来训练另一个模型以匹配其行为的技术。我们不使用外部数据源,而是使用现有模型来生成训练数据。我们使用 Jina Reranker 基础模型对文档集合进行排名,然后使用这些结果来训练 Turbo 和 Tiny。这样,我们可以将更多数据引入训练过程,因为我们不受可用真实数据的限制。
这有点像学生向老师学习:已经训练好的高性能模型——Jina Reranker Base 模型——通过生成新的训练数据来"教导"未训练的 Jina Turbo 和 Jina Tiny 模型。这种技术广泛用于从大型模型创建小型模型。在最好的情况下,"教师"模型和"学生"之间在任务性能上的差异可以很小。
tagBEIR 评估
精简和知识蒸馏带来的好处对性能质量的影响相对较小。在信息检索的 BEIR 基准测试中,jina-reranker-v1-turbo-en 的准确率仅略低于 jina-reranker-v1-base-en 的 95%,而 jina-reranker-v1-tiny-en 的得分达到了基础模型得分的 92.5%。
所有 Jina Reranker 模型都能与其他流行的重排模型竞争,而这些模型大多体积要大得多。
| Model | BEIR Score (NDCC@10) | Parameters |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 52.45 | 137M |
| jina-reranker-v1-turbo-en | 49.60 | 38M |
| jina-reranker-v1-tiny-en | 48.54 | 33M |
| Other reranking models | ||
mxbai-rerank-base-v1 |
49.19 | 184M |
mxbai-rerank-xsmall-v1 |
48.80 | 71M |
ms-marco-MiniLM-L-6-v2 |
48.64 | 23M |
bge-reranker-base |
47.89 | 278M |
ms-marco-MiniLM-L-4-v2 |
47.81 | 19M |
NDCC@10:使用标准化折损累积增益计算前 10 个结果的分数。
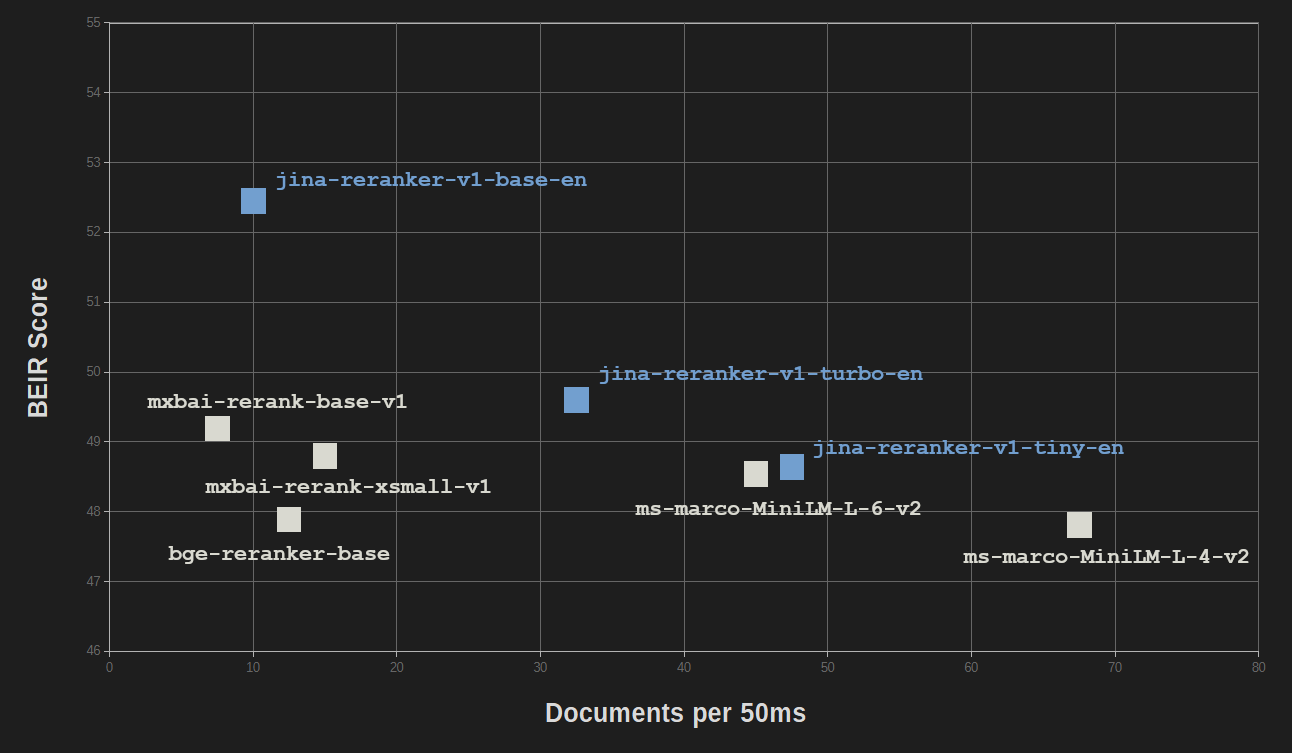
只有 MiniLM-L6(ms-marco-MiniLM-L-6-v2)和 MiniLM-L4(ms-marco-MiniLM-L-4-v2)具有相似的大小和速度,而 jina-reranker-v1-turbo-en 和 jina-reranker-v1-tiny-en 的表现相当或明显更好。
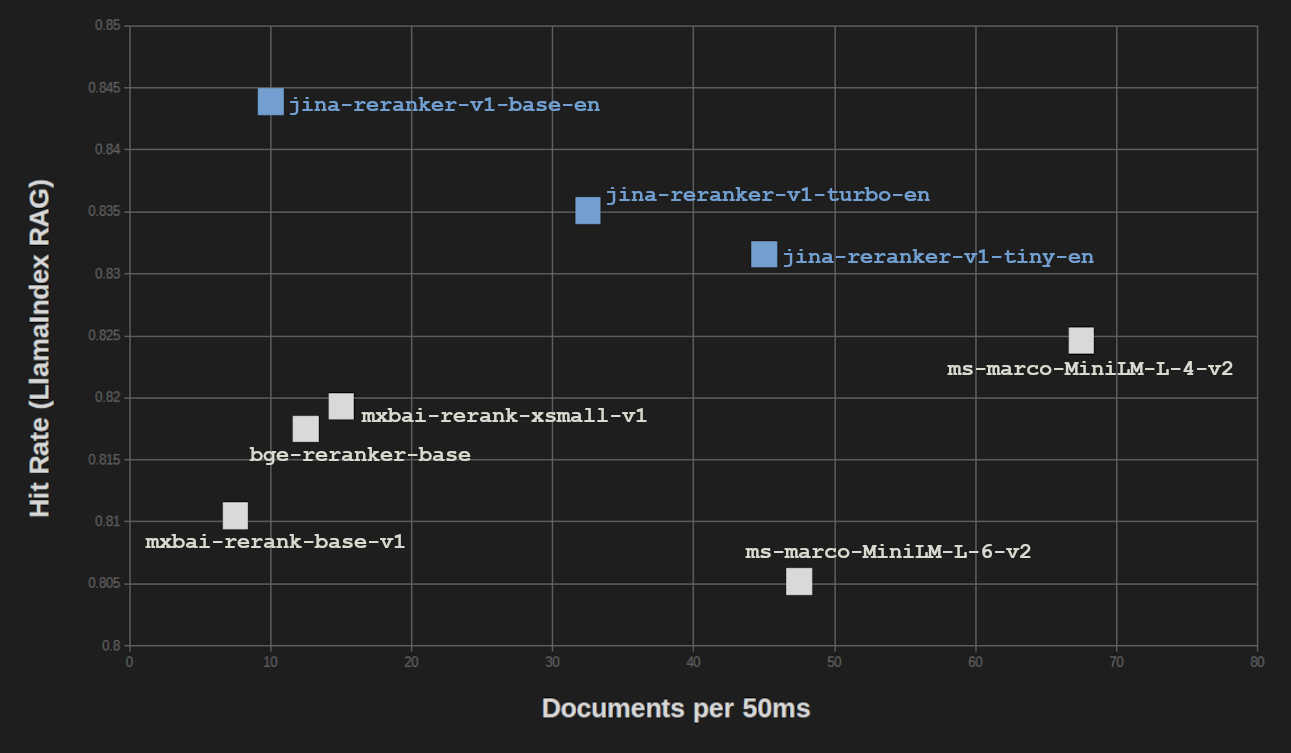
在 LlamaIndex RAG 基准测试中,我们得到了类似的结果。我们在 RAG 设置中测试了全部三个 Jina Reranker,使用了三个用于向量搜索的嵌入模型(jina-embeddings-v2-base-en、bge-base-en-v1.5 和 Cohere-embed-english-v3.0),并对分数进行了平均。
| Reranker Model | Avg. Hit Rate | Avg. MRR |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 0.8439 | 0.7006 |
| jina-reranker-v1-turbo-en | 0.8351 | 0.6498 |
| jina-reranker-v1-tiny-en | 0.8316 | 0.6761 |
| Other reranking models | ||
mxbai-rerank-base-v1 |
0.8105 | 0.6583 |
mxbai-rerank-xsmall-v1 |
0.8193 | 0.6673 |
ms-marco-MiniLM-L-6-v2 |
0.8052 | 0.6121 |
bge-reranker-base |
0.8175 | 0.6480 |
ms-marco-MiniLM-L-4-v2 |
0.8246 | 0.6354 |
MRR:平均倒数排名
对于检索增强生成(RAG)任务,结果质量的损失甚至比 BEIR 纯信息检索基准测试更小。当将 RAG 性能与处理速度进行对比时,我们发现只有 ms-marco-MiniLM-L-4-v2 提供了显著更高的吞吐量,但代价是结果质量的显著降低。
tagAWS 上的成本节省
使用 Reranker Turbo 和 Reranker Tiny 可以为需要支付内存使用和 CPU 时间费用的 AWS 和 Azure 用户带来巨大的成本节省。尽管不同用例的节省程度有所不同,但大约 75% 的内存使用量减少直接对应于按内存收费的云系统节省 75% 的成本。
此外,更快的吞吐量意味着您可以在更便宜的 AWS 实例上运行更多查询。
tag开始使用
Jina Reranker 模型易于使用并集成到您的应用程序和工作流程中。要开始使用,您可以访问 Reranker API 页面,了解如何使用我们的服务,并获得 100 万个免费令牌来亲自试用。

我们的模型也在 AWS SageMaker 上提供。如需了解更多信息,请参阅我们关于如何在 AWS 上设置检索增强生成系统的教程。

Jina Reranker 模型也可以在 Hugging Face 上以 Apache 2.0 许可下载:
