



在 2023 年 10 月,我们推出了 jina-embeddings-v2,这是第一个能够处理长达 8,192 个 token 输入的开源 embedding 模型系列。在此基础上,今年我们发布了 jina-embeddings-v3,在保持相同的输入长度支持的同时进行了进一步的增强。

在这篇文章中,我们将深入探讨长文本 embeddings,并回答一些问题:将如此大量的文本整合到单个向量中在什么时候是实用的?分段是否能提升检索效果,如果能,该如何实现?在对文本进行分段时,我们如何保持文档不同部分的上下文?
为了回答这些问题,我们将比较几种生成 embeddings 的方法:
- 长文本 embedding(编码最多 8,192 个 token 的文档)与短文本(即在 192 个 token 处截断)的对比。
- 不分块 vs. 朴素分块 vs. 后期分块。
- 在朴素分块和后期分块中使用不同的块大小。
tag长文本处理真的有用吗?
有了将长达十页文本编码成单个 embedding 的能力,长文本 embedding 模型为大规模文本表示开启了新的可能性。但这真的有用吗?根据很多人的说法...并没有。




来源:Nils Reimer 在 How AI Is Built 播客中的引用,brainlag 推文,egorfine 在 Hacker News 的评论,andy99 在 Hacker News 的评论
我们将通过详细研究长文本处理能力,以及何时有用、何时应该(或不应该)使用它来回应所有这些质疑。但首先,让我们听听这些质疑者的意见,看看长文本 embedding 模型面临的一些问题。
tag长文本 Embeddings 的问题
假设我们正在为文章构建一个文档搜索系统,比如我们 Jina AI 博客上的文章。有时一篇文章可能涉及多个主题,就像这篇关于我们参加 ICML 2024 会议的报告,其中包含:
- 介绍部分,包含了关于 ICML 的一般信息(参会人数、地点、范围等)。
- 我们的工作展示(jina-clip-v1)。
- ICML 上展示的其他有趣研究论文的总结。
如果我们仅为这篇文章创建一个 embedding,那这个 embedding 就代表了三个不同主题的混合:
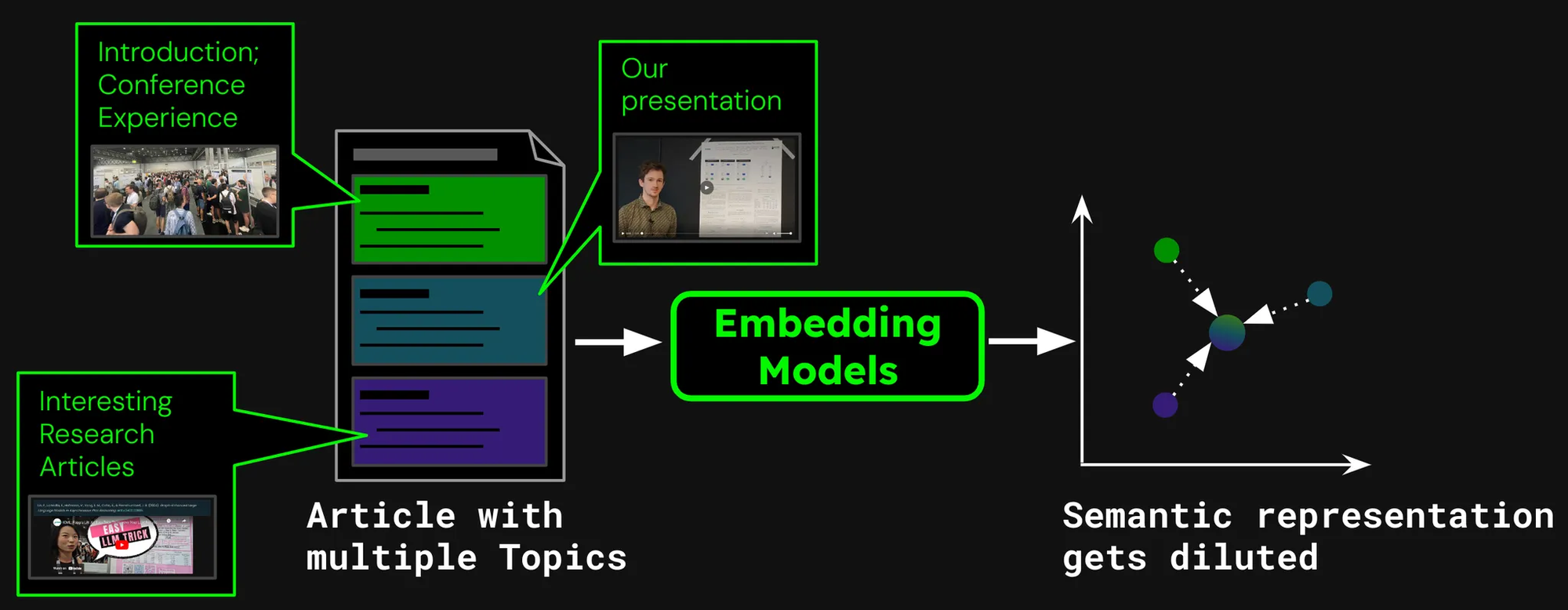
这会导致几个问题:
- 表示稀释:虽然文本中的所有主题可能相关,但用户的搜索查询可能只与其中一个相关。然而,单个 embedding(在这种情况下是整篇博文的 embedding)仅是向量空间中的一个点。随着更多文本输入到模型中,embedding 会转向捕捉文章的整体主题,在表示特定段落内容时效果下降。
- 有限容量:Embedding 模型生成固定大小的向量,与输入长度无关。随着输入内容的增加,模型越来越难以在向量中表示所有这些信息。可以把它想象成将图像缩小到 16×16 像素 — 如果你缩小一个简单物体的图像,比如苹果,你仍然可以从缩小的图像中获得意义。但如果是缩小柏林的街道地图?就没那么容易了。
- 信息丢失:在某些情况下,即使是长文本 embedding 模型也会达到其限制;许多模型支持最多 8,192 个 token 的文本编码。更长的文档在 embedding 之前需要被截断,导致信息丢失。如果与用户相关的信息位于文档末尾,它将完全不会被 embedding 捕捉到。
- 你可能需要文本分段:某些应用需要文本特定段落的 embedding 而不是整个文档的 embedding,比如在文本中识别相关段落。
tag长文本 vs. 截断
为了看看长文本处理是否真的有价值,让我们来看看两种检索场景的表现:
- 编码最多 8,192 个 token 的文档(约 10 页文本)。
- 在 192 个 token 处截断文档并进行编码。
我们将使用以下方法比较结果:
使用 nDCG@10 检索指标测试 jina-embeddings-v3。我们测试了以下数据集:| 数据集 | 描述 | 查询示例 | 文档示例 | 平均文档长度(字符) |
|---|---|---|---|---|
| NFCorpus | 一个全文医疗检索数据集,包含 3,244 个查询和主要来自 PubMed 的文档。 | "使用饮食治疗哮喘和湿疹" | "他汀类药物使用与乳腺癌存活率:芬兰全国队列研究 最近的研究表明 [...]" | 326,753 |
| QMSum | 一个基于查询的会议总结数据集,需要总结相关会议片段。 | "教授是提出这个问题的人,并建议使用知识工程技巧 [...]" | "项目经理:现在没问题了吗?{声音} 好的。抱歉?好的,大家都准备好开始会议了吗?[...]" | 37,445 |
| NarrativeQA | 包含长篇故事及其特定内容相关问题的问答数据集。 | "Sophia 在巴黎拥有什么样的生意?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53,336 |
| 2WikiMultihopQA | 一个最多需要 5 步推理的多跳问答数据集,设计时使用模板以避免捷径。 | "歌曲 The Seeker(The Who 乐队的歌曲)的作曲家获得了什么奖项?" | "段落 1:\n布里恩伯爵夫人玛格丽特\nMarguerite d'Enghien(生于 1365 年 - 卒于 1394 年后),是 suo jure 统治者 [...]" | 30,854 |
| SummScreenFD | 一个剧本总结数据集,包含电视剧剧本和需要整合分散情节的摘要。 | "Penny 得到了一把新椅子,Sheldon 很喜欢,直到他发现她是从 [...]" | "[外景。拉斯维加斯城市(库存)- 夜晚]\n[外景。阿伯内西住宅 - 车道 -- 夜晚]\n(路灯柱上的灯 [...]" | 1,613 |
如我们所见,编码超过 192 个 token 可以带来显著的性能提升:
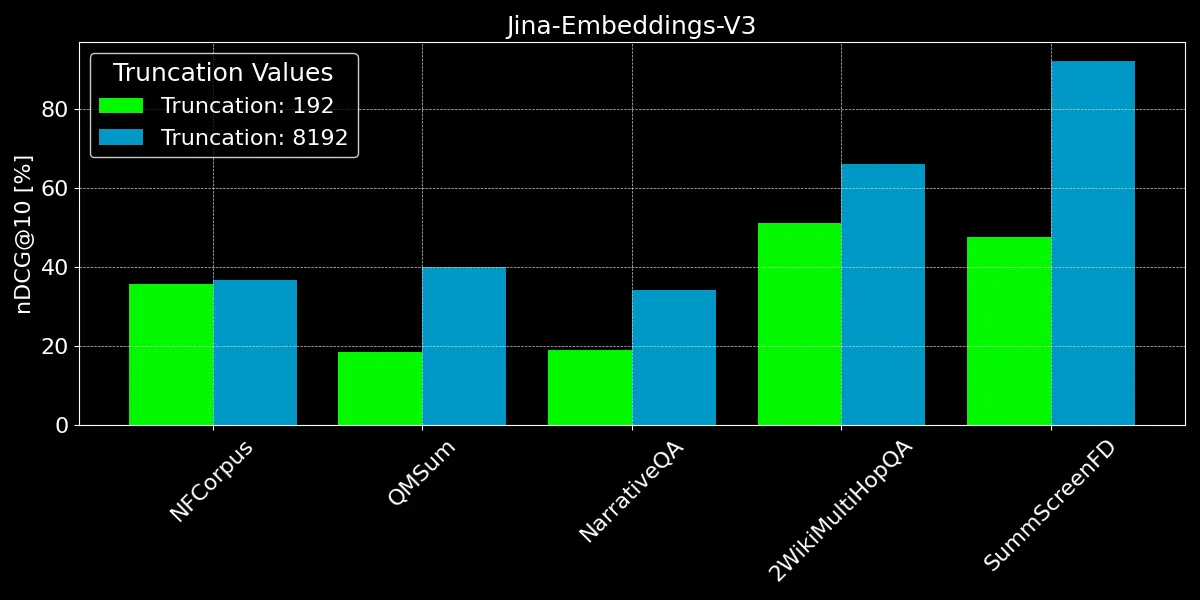
然而,在某些数据集上,我们看到的改进幅度比其他数据集更大:
- 对于 NFCorpus,截断几乎没有影响。这是因为标题和摘要就在文档的开头,而这些内容与典型的用户搜索词高度相关。无论是否截断,最相关的数据都在 token 限制范围内。
- QMSum 和 NarrativeQA 被视为"阅读理解"任务,用户通常在文本中搜索特定事实。这些事实往往散布在文档的各个细节中,可能会超出 192-token 的截断限制。例如,在 NarrativeQA 文档《Percival Keene》中,"谁是偷了 Percival 午餐的恶霸?"这个问题的答案远远超出了这个限制。同样,在 2WikiMultiHopQA 中,相关信息分散在整个文档中,需要模型浏览和综合多个章节的知识才能有效回答查询。
- SummScreenFD 是一个旨在识别给定摘要对应剧本的任务。由于摘要包含了分散在整个剧本中的信息,编码更多的文本可以提高摘要与正确剧本匹配的准确性。
tag文本分段以提升检索性能
• 分段:在输入文本中检测边界标记,例如句子或固定数量的 token。
• 朴素分块:在编码之前,根据分段标记将文本分成块。
• 后期分块:先编码文档,然后再进行分段(保留块之间的上下文)。
我们可以使用各种方法首先通过分配边界标记对文档进行分段,而不是将整个文档嵌入到一个向量中:

一些常见的方法包括:
- 固定大小分段:文档被分成固定数量的 token,这个数量由嵌入模型的分词器决定。这确保了段落的分词与整个文档的分词相对应(按特定字符数分段可能导致不同的分词结果)。
- 句子分段:文档被分成句子,每个块由 n 个句子组成。
- 语义分段:每个段落对应多个句子,嵌入模型决定连续句子的相似性。具有高嵌入相似度的句子被分配到同一个块中。
为简单起见,我们在本文中使用固定大小分段。
tag使用朴素分块进行文档检索
一旦我们执行了固定大小分段,我们就可以根据这些段落对文档进行朴素分块:
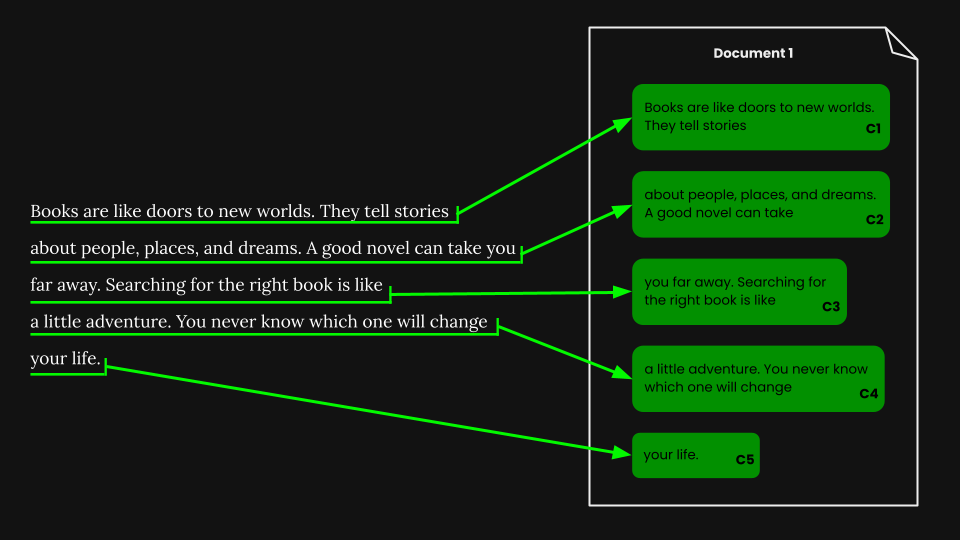
使用 jina-embeddings-v3,我们将每个块编码成准确捕捉其语义的嵌入向量,然后将这些嵌入向量存储在向量数据库中。
在运行时,模型将用户的查询编码为查询向量。我们将其与向量数据库中的块嵌入向量进行比较,找到余弦相似度最高的块,然后将相应的文档返回给用户:
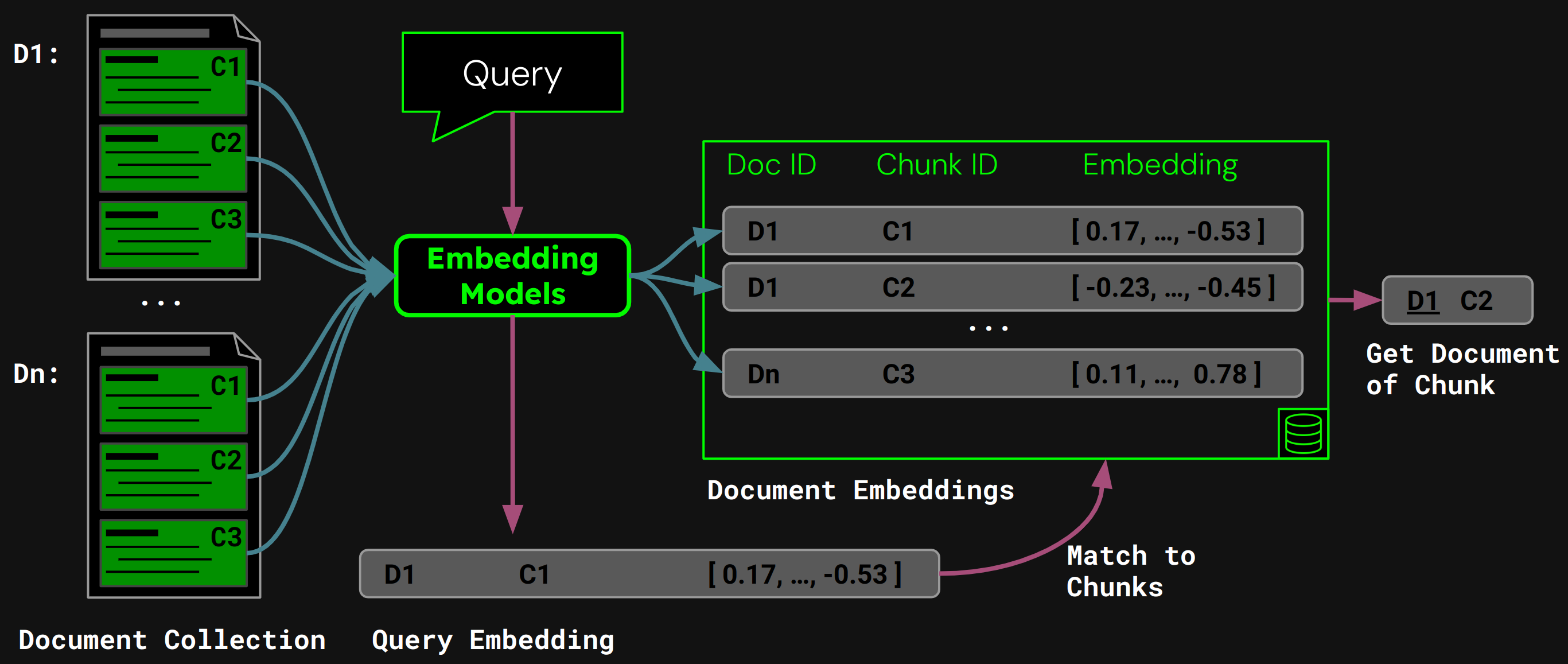
tag朴素分块的问题

虽然朴素分块解决了长上下文 embedding 模型的一些限制,但它也有其缺点:
- 丢失全局视角:在文档检索中,多个小块的 embedding 可能无法捕捉文档的整体主题。这就像只见树木不见森林。
- 缺失上下文问题:如图 6 所示,由于缺少上下文信息,无法准确理解块的内容。
- 效率:更多的块需要更多存储空间并增加检索时间。
tag后期分块解决了上下文问题
后期分块分两个主要步骤工作:
- 首先,利用模型的长上下文能力将整个文档编码为 token embedding。这保留了文档的完整上下文。
- 然后,通过对特定 token embedding 序列进行平均池化来创建块 embedding,这些序列对应于分割过程中识别的边界标记。
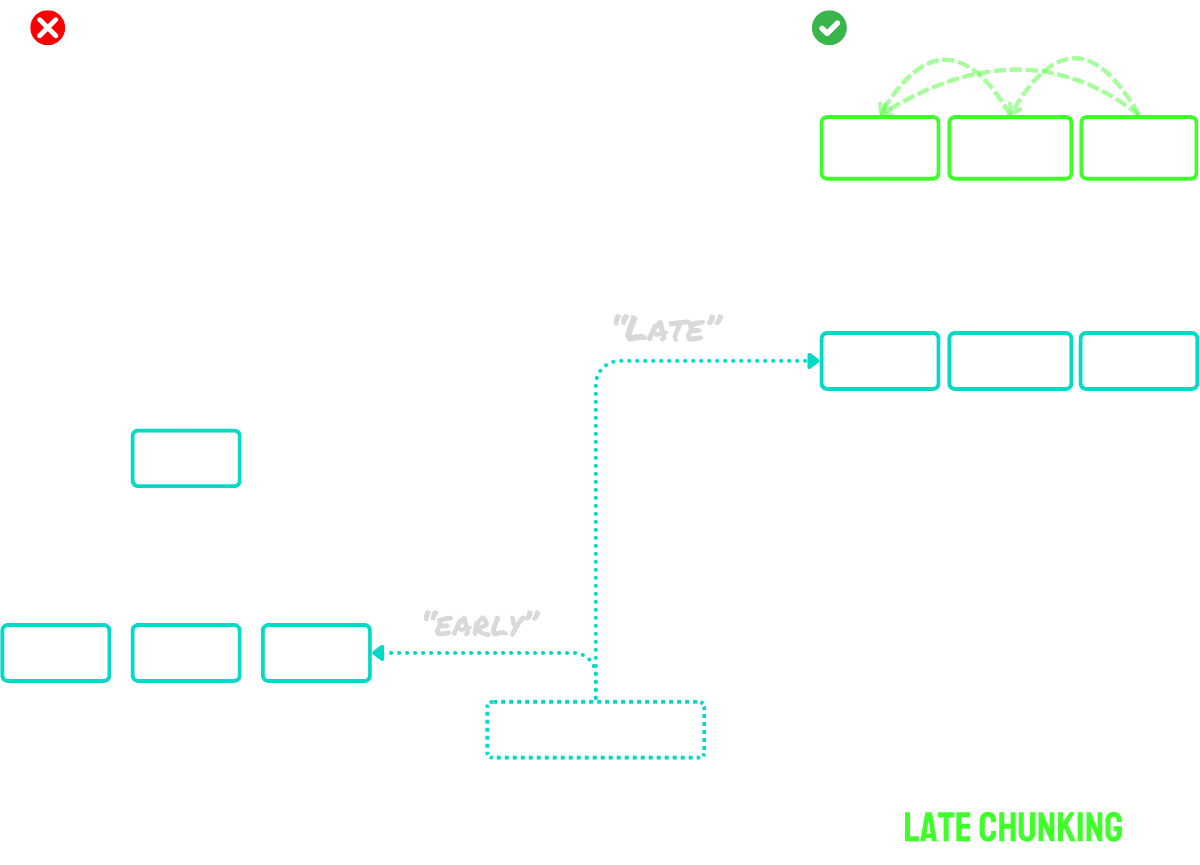
这种方法的主要优势在于 token embedding 是上下文化的——这意味着它们自然地捕捉到了文档其他部分的引用和关系。由于 embedding 过程发生在分块之前,每个块都保留了更广泛的文档上下文意识,解决了朴素分块方法存在的上下文缺失问题。
对于超出模型最大输入长度的文档,我们可以使用"长文本后期分块":
- 首先,我们将文档分割成重叠的"宏块"。每个宏块的大小都在模型的最大上下文长度内(例如 8,192 个 token)。
- 模型处理这些宏块以创建 token embedding。
- 一旦有了 token embedding,我们就继续进行标准后期分块——应用平均池化来创建最终的块 embedding。
这种方法使我们能够处理任意长度的文档,同时保留后期分块的优势。可以将其视为两阶段过程:首先使文档适合模型处理,然后应用常规的后期分块程序。
简而言之:
- 朴素分块:将文档分割成小块,然后分别对每个块进行编码。
- 后期分块:一次性对整个文档进行编码以创建 token embedding,然后基于段落边界对 token embedding 进行池化以创建块 embedding。
- 长文本后期分块:将大型文档分割成适合模型上下文窗口的重叠宏块,对这些块进行编码获取 token embedding,然后正常应用后期分块。
关于这个想法的更详细描述,请查看我们的论文或上述提到的博客文章。
tag分块还是不分块?
我们已经看到长上下文 embedding 通常优于短文本 embedding,并概述了朴素分块和后期分块策略。现在的问题是:分块是否比长上下文 embedding 更好?
为了进行公平比较,我们在开始分块之前将文本值截断到模型的最大序列长度(8,192 个 token)。我们对两种分块方式(朴素分块和后期分块)都使用固定大小的分块,每个段落包含 64 个 token。让我们比较三种场景:
- 不分块:我们将每个文本编码为单个 embedding。这导致与之前实验相同的分数(见图 2),但我们在这里包含它们以便更好地比较。
- 朴素分块:我们对文本进行分割,然后基于边界标记应用朴素分块。
- 后期分块:我们对文本进行分割,然后使用后期分块来确定 embedding。
对于后期分块和朴素分块,我们都使用块检索来确定相关文档(如本文前面图 5 所示)。
结果显示没有明显的赢家:
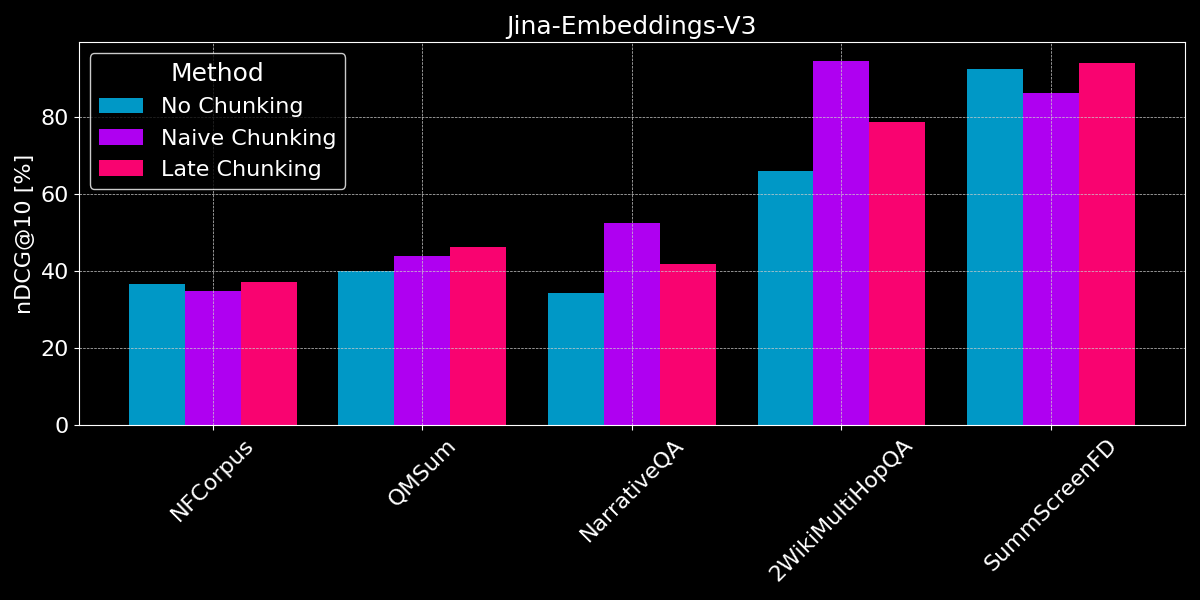
- 对于事实检索,朴素分块表现更好:对于 QMSum、NarrativeQA 和 2WikiMultiHopQA 数据集,模型需要在文档中识别相关段落。在这里,朴素分块明显优于将所有内容编码为单个 embedding,因为可能只有少数几个块包含相关信息,而这些块比整个文档的单个 embedding 能更好地捕捉这些信息。
- 后分块在连贯的文档和相关上下文中效果最佳:对于涵盖连贯主题且用户搜索总体主题而非具体事实的文档(如在 NFCorpus 中),后分块略优于不分块,因为它在文档整体上下文和局部细节之间取得了平衡。然而,虽然后分块通常通过保留上下文表现优于简单分块,但当在包含大量无关信息的文档中搜索孤立事实时,这种优势可能成为负担——就像在 NarrativeQA 和 2WikiMultiHopQA 的性能回退中所看到的那样,额外的上下文反而会造成干扰。
tag分块大小是否有影响?
分块方法的有效性实际上取决于数据集,这突显出内容结构起着关键作用:
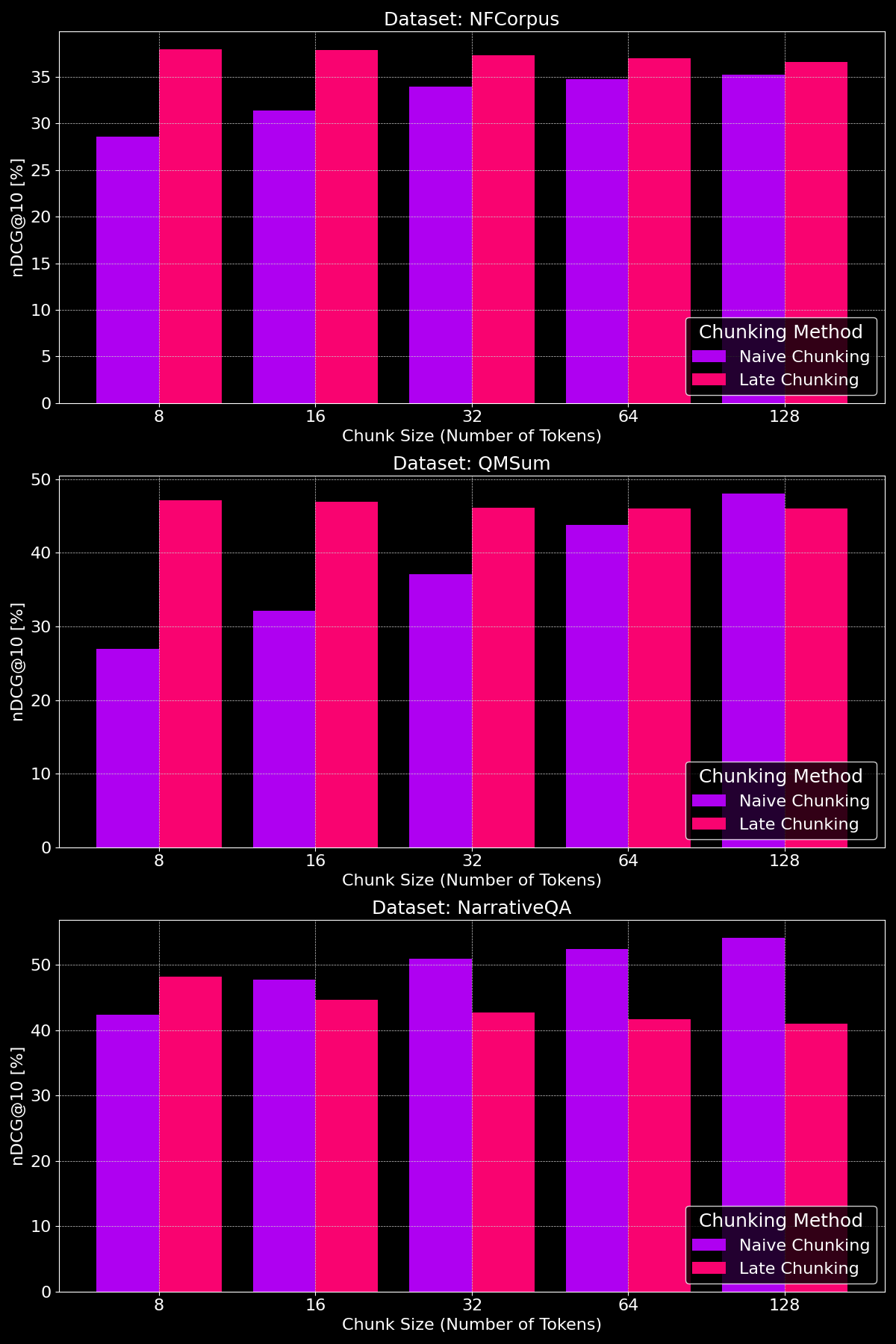
如我们所见,在较小的分块大小下,后分块通常优于简单分块,因为较小的简单分块包含的上下文太少,而较小的后分块保留了整个文档的上下文,使其在语义上更有意义。例外是 NarrativeQA 数据集,其中存在太多无关的上下文,导致后分块表现落后。在较大的分块大小下,由于上下文增加,简单分块显示出明显的改进(有时甚至超过后分块),而后分块的性能则逐渐下降。
tag要点:何时使用什么?
在这篇文章中,我们研究了不同类型的文档检索任务,以更好地理解何时使用分段以及何时后分块有帮助。那么,我们学到了什么?
tag何时应该使用长上下文嵌入?
一般来说,在嵌入模型的输入中包含尽可能多的文档文本不会损害检索准确性。然而,长上下文嵌入模型往往关注文档开头,因为它们包含标题和介绍等对判断相关性更重要的内容,但模型可能会忽略文档中间的内容。
tag何时应该使用简单分块?
当文档涵盖多个方面,或用户查询针对文档中的特定信息时,分块通常可以提高检索性能。
最终,分段决策取决于各种因素,比如是否需要向用户显示部分文本(例如 Google 在搜索结果预览中展示相关段落),这使得分段成为必需,或者计算和内存的限制,由于增加了检索开销和资源使用,分段可能较不利。
tag何时应该使用后分块?
通过在创建分块之前编码完整文档,后分块解决了由于缺少上下文导致文本段落失去意义的问题。这在连贯的文档中特别有效,因为每个部分都与整体相关。我们的实验表明,后分块在将文本分成较小块时特别有效,正如我们在论文中所示。然而,有一个注意事项:如果文档的各个部分之间互不相关,包含这种更广泛的上下文实际上可能会降低检索性能,因为它会为嵌入添加噪音。
tag结论
在长上下文嵌入、简单分块和后分块之间的选择取决于你的检索任务的具体要求。长上下文嵌入对于具有一般查询的连贯文档很有价值,而分块在用户寻找文档中特定事实或信息的情况下表现出色。后分块通过在较小段落中保持上下文连贯性进一步提升检索效果。最终,理解你的数据和检索目标将指导最佳方法,在准确性、效率和上下文相关性之间取得平衡。
如果你正在探索这些策略,可以考虑尝试 jina-embeddings-v3——其先进的长上下文能力、后分块和灵活性使其成为各种检索场景的绝佳选择。

