


最近,LAION AI 的创始人 Christoph Schuhmann 分享了一个关于文本嵌入模型的有趣观察:
当句子中的词语被随机打乱时,其文本嵌入与原始句子的余弦相似度仍然保持着出人意料的高值。
例如,让我们看两个句子:Berlin is the capital of Germany 和 the Germany Berlin is capital of。尽管第二个句子毫无意义,但文本嵌入模型却难以区分它们。使用 jina-embeddings-v3,这两个句子的余弦相似度高达 0.9295。
词序并不是嵌入模型唯一不够敏感的方面。语法变换可以彻底改变句子的含义,但对嵌入距离的影响却很小。例如,She ate dinner before watching the movie 和 She watched the movie before eating dinner 的余弦相似度为 0.9833,尽管它们描述的动作顺序完全相反。
如果没有特殊训练,否定词的一致性嵌入也是出了名的困难 — This is a useful model 和 This is not a useful model 在嵌入空间中看起来几乎一样。通常,将文本中的词替换为同类词,比如把"today"改成"yesterday",或改变动词时态,对嵌入的影响也不如预期的那么大。
这带来了严重的问题。考虑两个搜索查询:Flight from Berlin to Amsterdam 和 Flight from Amsterdam to Berlin。它们的嵌入几乎完全相同,jina-embeddings-v3 给出的余弦相似度为 0.9884。对于旅行搜索或物流等实际应用来说,这个缺陷是致命的。
在本文中,我们将探讨嵌入模型面临的挑战,研究它们在词序和词选择方面持续存在的问题。我们分析了各种语言类别中的关键失效模式——包括方向性、时间性、因果关系、比较和否定语境——同时探索提升模型性能的策略。
tag为什么打乱的句子会有惊人的相近余弦分数?
起初,我们认为这可能与模型如何组合词义有关 - 它为每个词(我们上面例子中的每个句子有 6-7 个词)创建一个嵌入,然后通过平均池化将这些嵌入平均在一起。这意味着最终的嵌入几乎不包含词序信息。平均值无论值的顺序如何都是相同的。
然而,即使是使用 CLS 池化的模型(通过查看特殊的第一个词来理解整个句子,理应对词序更敏感)也存在同样的问题。例如,bge-1.5-base-en 对句子 Berlin is the capital of Germany 和 the Germany Berlin is capital of 仍给出 0.9304 的余弦相似度分数。
这指向了嵌入模型训练方式的一个局限。虽然语言模型在预训练期间最初学习了句子结构,但在对比训练(创建嵌入模型的过程)中似乎失去了部分这种理解。
tag文本长度和词序如何影响嵌入相似度?
为什么模型一开始就难以处理词序?首先想到的是文本的长度(以标记计)。当文本被送入编码函数时,模型首先生成标记嵌入列表(即,每个标记化的词都有一个专门的向量表示其含义),然后对它们取平均值。
为了了解文本长度和词序如何影响嵌入相似度,我们生成了一个包含 180 个不同长度合成句子的数据集,长度分别为 3、5、10、15、20 和 30 个标记。我们还随机打乱了每个句子的标记来形成变体:

以下是一些例子:
| 长度(标记) | 原始句子 | 打乱的句子 |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
我们将使用我们自己的 jina-embeddings-v3 模型和开源模型 bge-base-en-v1.5 对数据集进行编码,然后计算原始句子和打乱句子之间的余弦相似度:
| 长度(标记) | 平均余弦相似度 | 余弦相似度标准差 |
|---|---|---|
| 3 | 0.947 | 0.053 |
| 5 | 0.909 | 0.052 |
| 10 | 0.924 | 0.031 |
| 15 | 0.918 | 0.019 |
| 20 | 0.899 | 0.021 |
| 30 | 0.874 | 0.025 |
现在我们可以生成一个箱线图,这使得余弦相似度的趋势更加清晰:
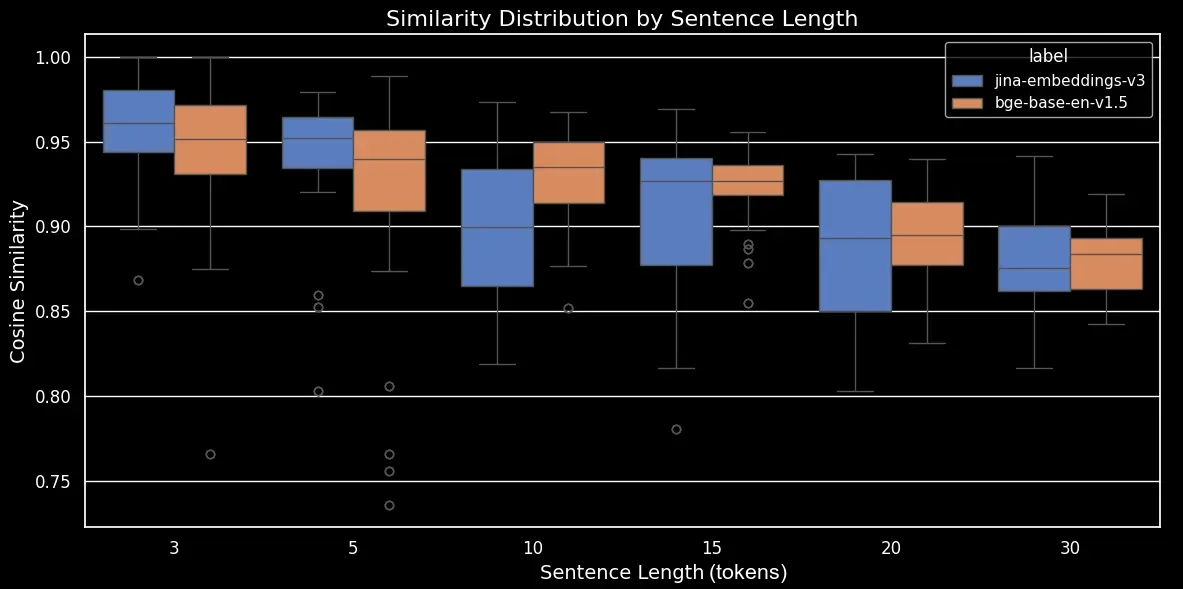
bge-base-en-1.5(未微调)的打乱句子按句子长度的相似度分布正如我们所见,嵌入的平均余弦相似度存在明显的线性关系。文本越长,原始句子和随机打乱句子之间的平均余弦相似度分数越低。这很可能是由于"词位移"造成的,即词在随机打乱后离开原始位置的距离。在较短的文本中,标记能够被打乱到的"位置"simply 更少,因此不能移动太远,而较长的文本有更多的潜在排列组合,词可以移动更远的距离。
如下图所示(余弦相似度与平均词位移关系图),文本越长,词位移越大:
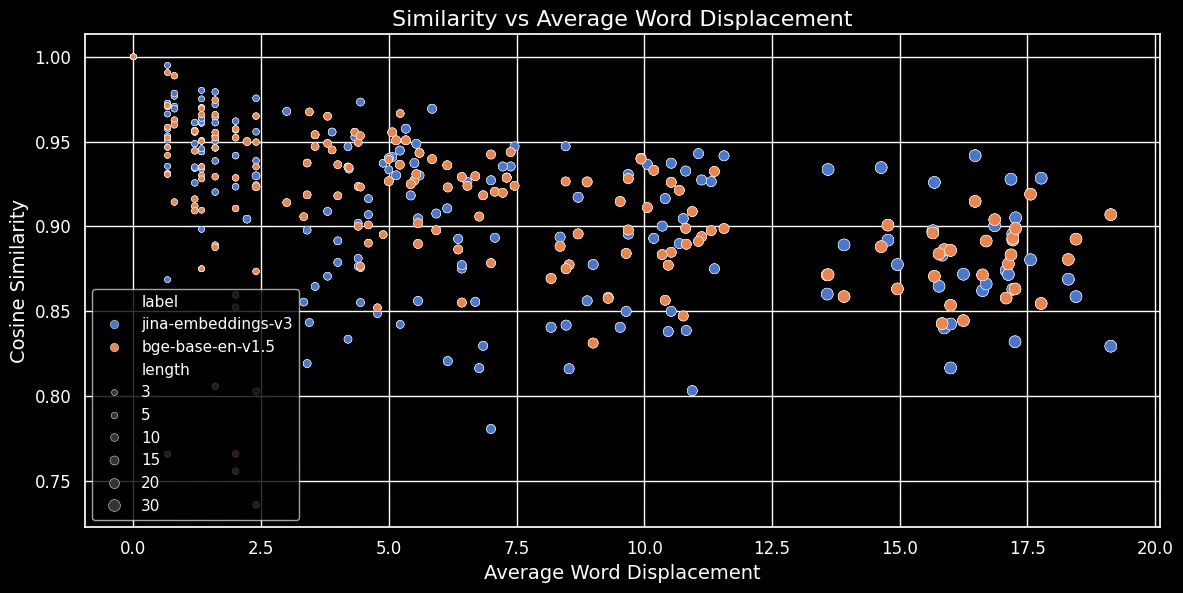
Token 嵌入依赖于局部上下文,即最接近它们的词。在短文本中,重新排列词不会大幅改变上下文。然而,对于较长的文本,一个词可能会被移到离其原始上下文很远的位置,这可能会显著改变其 token 嵌入。因此,打乱较长文本中的词会产生比短文本更远的嵌入距离。上图显示,无论是使用均值池化的 jina-embeddings-v3,还是使用 CLS 池化的 bge-base-en-v1.5,都遵循相同的规律:打乱较长的文本并使词位移更远会导致更小的相似度分数。
tag更大的模型能解决这个问题吗?
通常,当我们面对这类问题时,一个常见的策略是使用更大的模型。但更大的文本嵌入模型真的能更有效地捕捉词序信息吗?根据文本嵌入模型的扩展定律(在我们的 jina-embeddings-v3 发布文章中提到),更大的模型通常提供更好的性能:
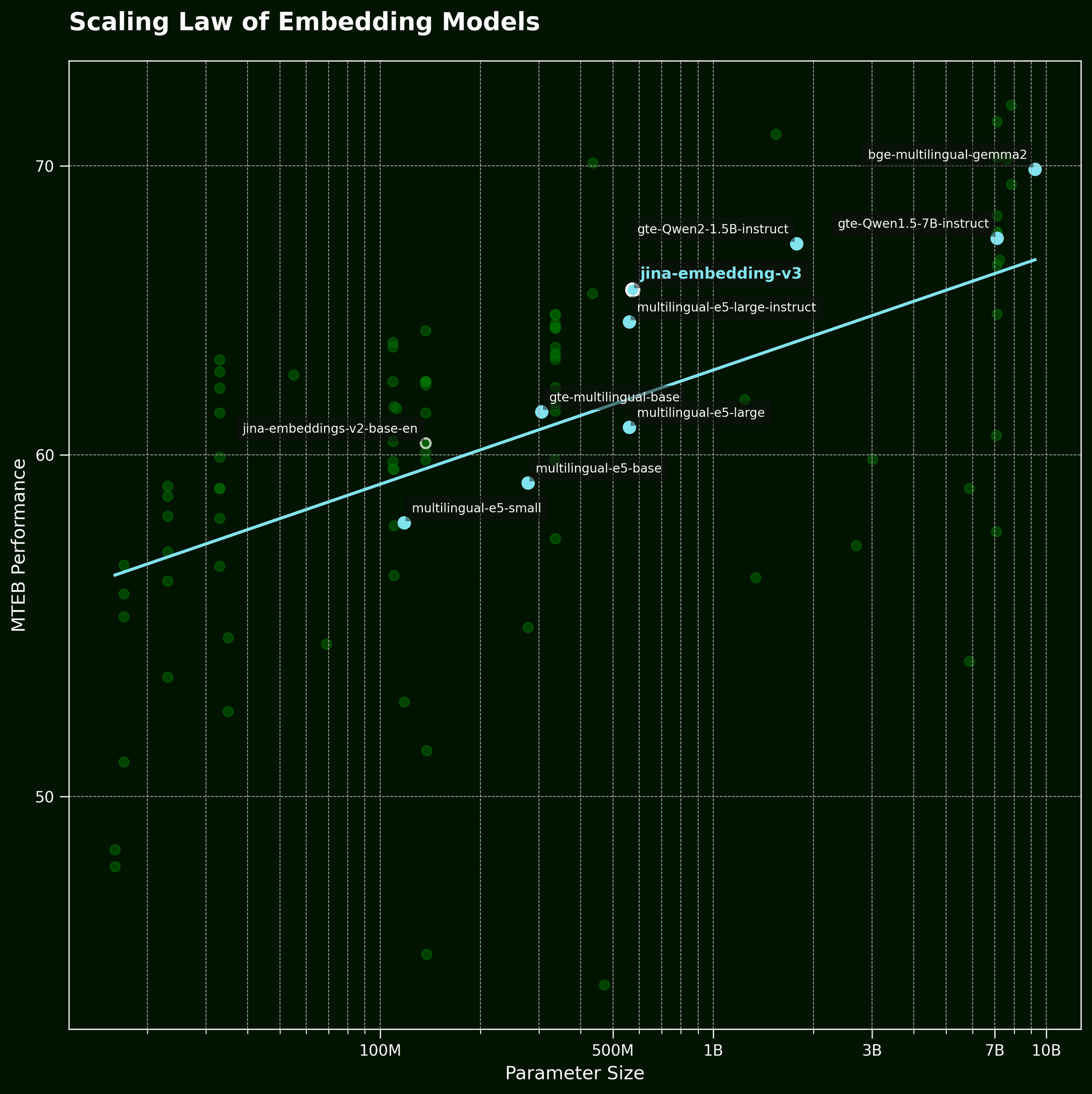
但更大的模型真的能更有效地捕捉词序信息吗?我们测试了 BGE 模型的三种变体:bge-small-en-v1.5、bge-base-en-v1.5 和 bge-large-en-v1.5,参数量分别为 3300 万、1.1 亿和 3.35 亿。
我们将使用与之前相同的 180 个句子,但不考虑长度信息。我们将使用这三个模型变体对原始句子及其随机打乱后的句子进行编码,并绘制平均余弦相似度:
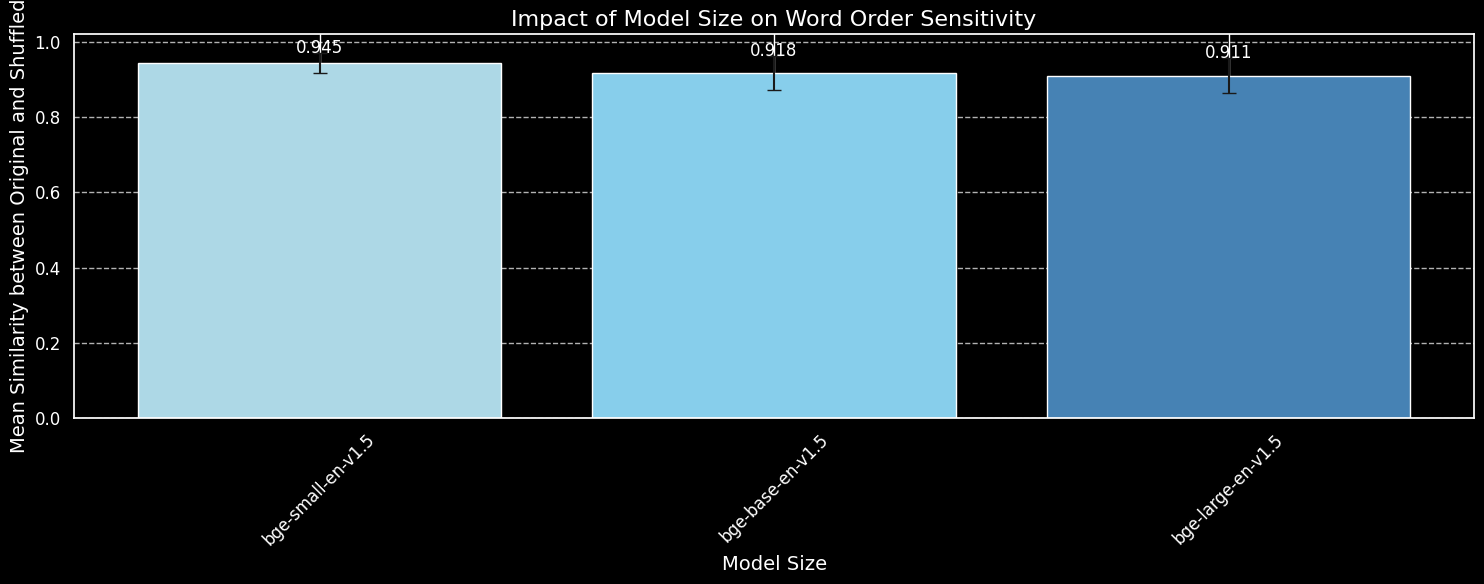
bge-small-en-v1.5、bge-base-en-v1.5和 bge-large-en-v1.5的模型大小对词序敏感度的影响。虽然我们可以看到更大的模型对词序变化更敏感,但差异很小。即使是大得多的 bge-large-en-v1.5 在区分打乱和未打乱的句子方面也仅仅略微更好一些。其他因素在决定嵌入模型对词序重排的敏感度方面也起着作用,特别是训练方案的差异。此外,余弦相似度是衡量模型区分能力的一个很有限的工具。然而,我们可以看到模型大小并不是一个主要考虑因素。我们不能简单地通过增大模型来解决这个问题。
tag现实世界中的词序和词选择
jina-embeddings-v2(不是我们最新的 jina-embeddings-v3 模型),因为 v2 要小得多,因此在我们的本地 GPU 上实验更快,其参数量为 1.37 亿,而 v3 为 5.8 亿。正如我们在引言中提到的,词序并不是嵌入模型唯一面临的挑战。在现实世界中,更现实的挑战是关于词的选择。有很多方式可以改变句子中的词——而这些改变在嵌入中并没有得到很好的反映。我们可以把"她从巴黎飞到东京"改成"她从东京开车到巴黎",但嵌入仍然保持相似。我们已经将这些改变划分为几个类别:
| 类别 | 示例 - 左 | 示例 - 右 | 余弦相似度 (jina) |
|---|---|---|---|
| 方向性 | She flew from Paris to Tokyo | She drove from Tokyo to Paris | 0.9439 |
| 时间性 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 |
| 因果关系 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 |
| 比较关系 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 |
| 否定关系 | He is standing by the table | He is standing far from the table | 0.9116 |
上表展示了一系列文本嵌入模型在捕捉细微词语变化方面失败的"失败案例"。这符合我们的预期:文本嵌入模型缺乏推理能力。例如,模型并不理解"from"和"to"之间的关系。文本嵌入模型执行语义匹配,语义通常在词元级别捕获,然后在池化后压缩成单个密集向量。相比之下,在万亿词元规模的更大数据集上训练的 LLM(自回归模型)开始展现出推理的涌现能力。
这让我们思考,我们能否通过使用三元组进行对比学习来微调嵌入模型,使查询和正样本更接近,同时推开查询和负样本?

例如,"Flight from Amsterdam to Berlin"可以被视为"Flight from Berlin to Amsterdam"的负面对。事实上,在 jina-embeddings-v1 技术报告(Michael Guenther 等人)中,我们已经小规模地解决了这个问题:我们在一个由大型语言模型生成的包含 10,000 个示例的否定数据集上微调了 jina-embeddings-v1 模型。

上述报告中的结果令人鼓舞:
我们观察到,在所有模型尺寸中,在三元组数据(包括我们的否定训练数据集)上进行微调都显著提高了性能,特别是在 HardNegation 任务上。
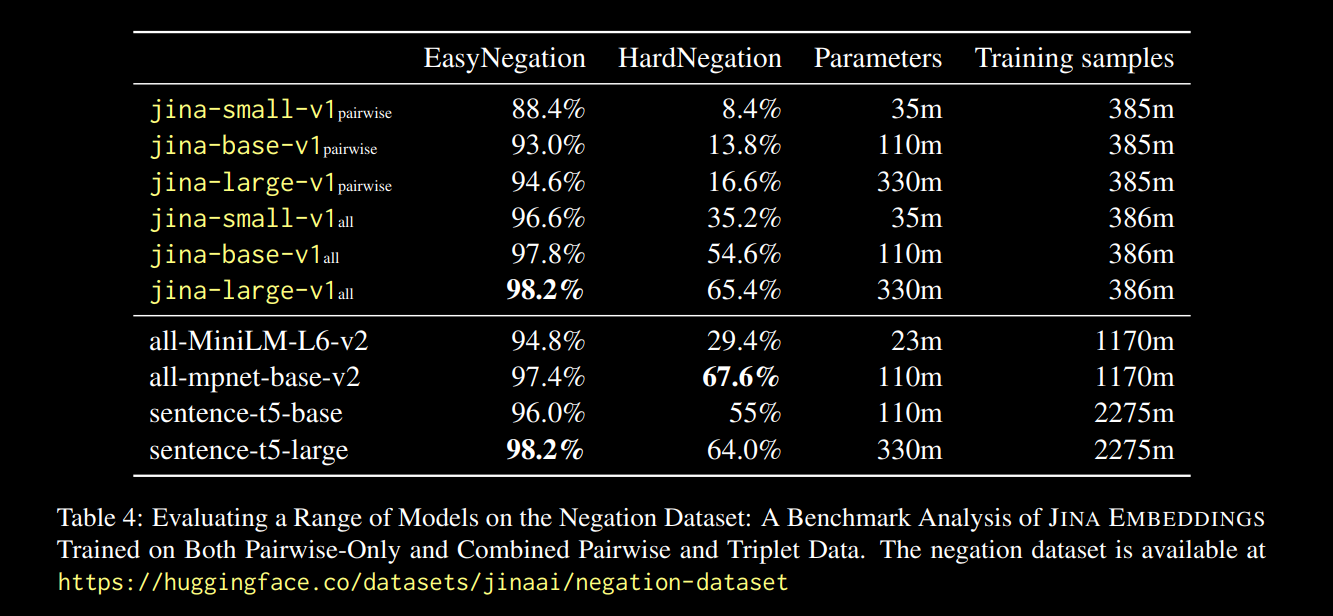
jina-embeddings 模型在配对训练和组合三元组/配对训练下的 EasyNegation 和 HardNegation 分数。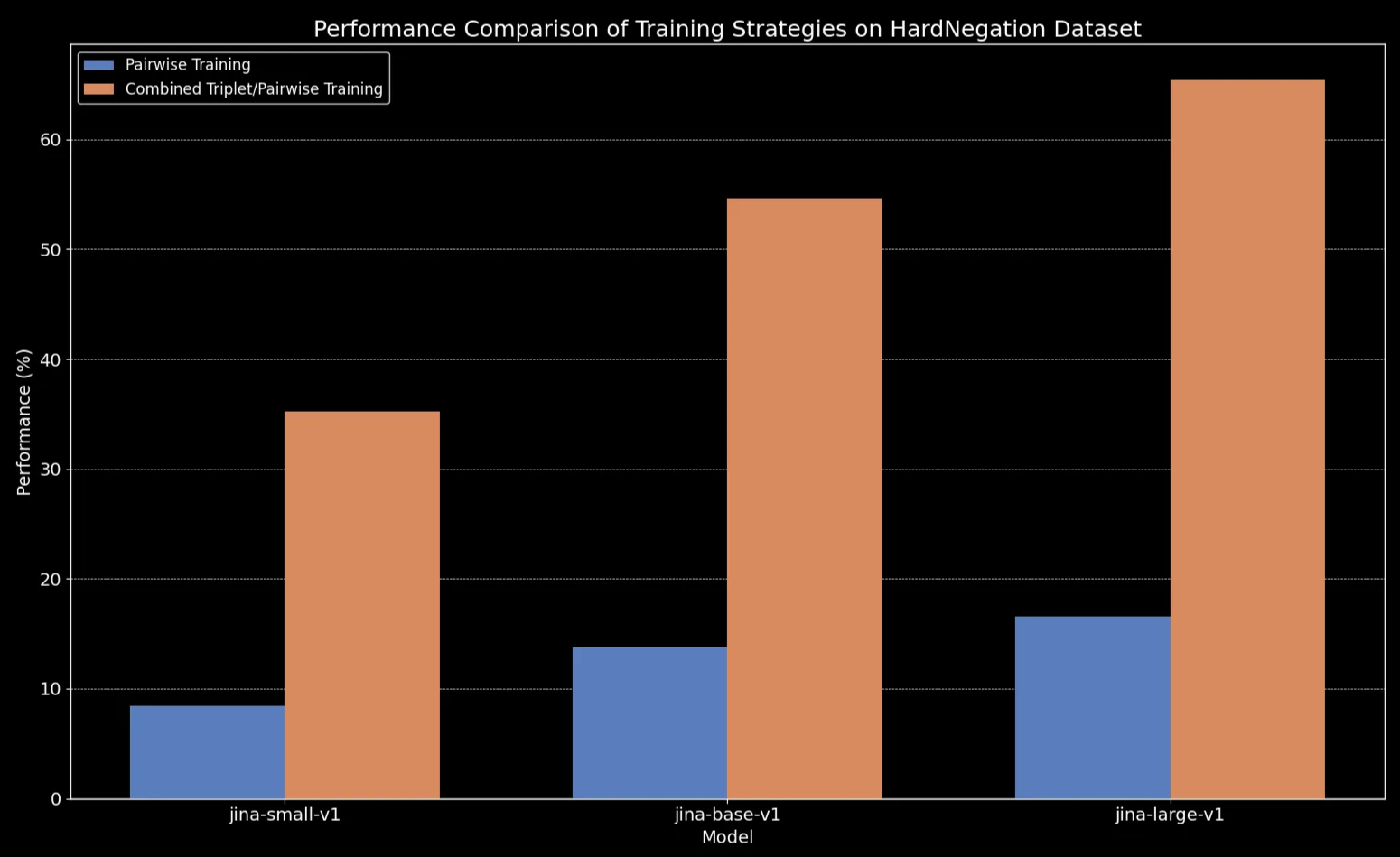
jina-embeddings 训练策略的性能比较。tag使用精选数据集微调文本嵌入模型
在前面的部分,我们探讨了关于文本嵌入的几个关键观察:
- 较短的文本更容易在捕捉词序方面出错。
- 增加文本嵌入模型的规模并不一定能改善词序理解。
- 对比学习可能为这些问题提供潜在的解决方案。
基于这些认识,我们在否定和词序数据集(总共约 11,000 个训练样本)上微调了 jina-embeddings-v2-base-en 和 bge-base-en-1.5:


为了帮助评估微调效果,我们生成了一个包含 1,000 个三元组的数据集,每个三元组包含一个 query、positive (pos) 和 negative (neg) 案例:

以下是一个示例行:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
这些三元组设计用于覆盖各种失败案例,包括由于词序变化导致的方向性、时间性和因果性意义变化。
现在我们可以在三个不同的评估集上评估模型:
- 180 个合成句子集(来自本文前面部分)的随机打乱。
- 5 个手动检查的示例(来自上面方向性/因果性等表格)。
- 来自我们刚刚生成的三元组数据集的 94 个精选三元组。
以下是微调前后打乱句子的差异:
| 句子长度(词元数) | 余弦相似度均值(jina) |
余弦相似度均值(jina-ft) |
余弦相似度均值(bge) |
余弦相似度均值(bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
结果似乎很明显:尽管微调过程只花了五分钟,我们在随机打乱句子的数据集上看到了显著的性能提升:
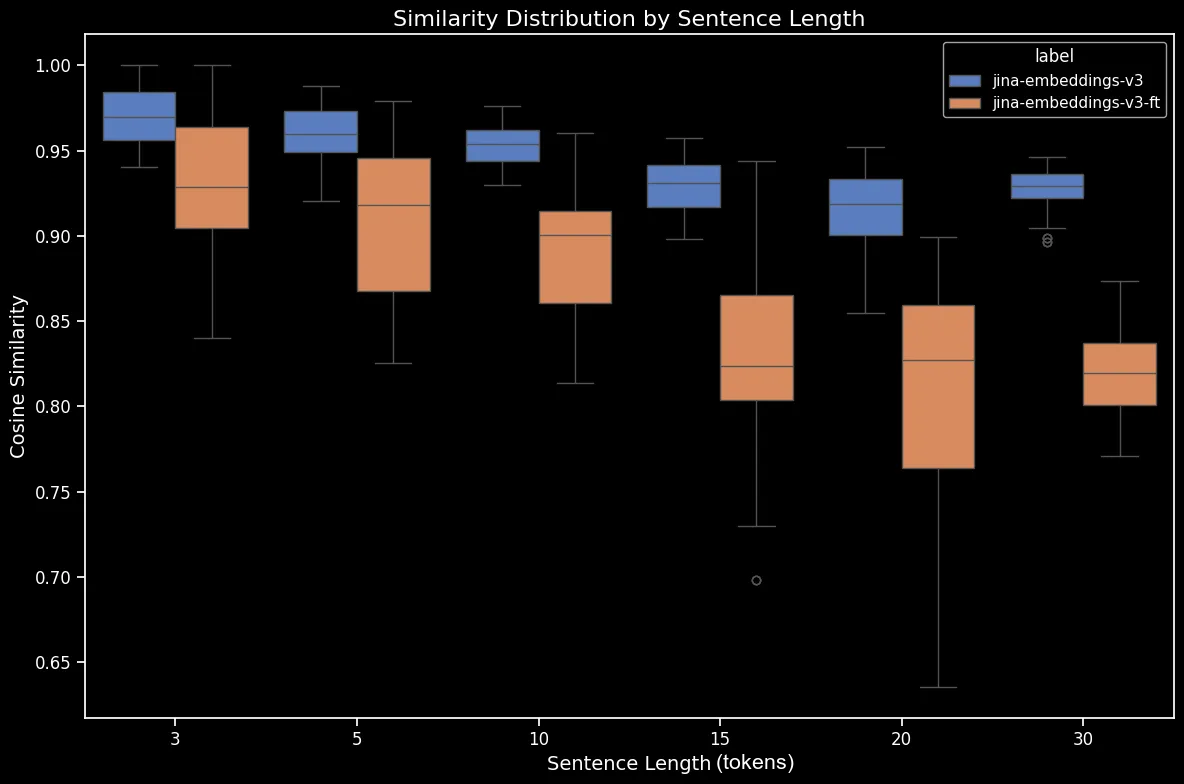
bge-base-en-1.5(经过微调)对打乱句子的相似度分布。我们在方向性、时序、因果和比较性案例上也看到了提升。模型表现出显著的性能提升,这反映在平均余弦相似度的下降上。最大的性能提升出现在否定案例上,这是因为我们的微调数据集包含了 10,000 个否定训练样例。
| 类别 | 示例 - 左 | 示例 - 右 | 平均余弦相似度 (jina) |
平均余弦相似度 (jina-ft) |
平均余弦相似度 (bge) |
平均余弦相似度 (bge-ft) |
|---|---|---|---|---|---|---|
| 方向性 | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| 时序 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| 因果 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| 比较 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| 否定 | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tag结论
在这篇文章中,我们深入探讨了文本嵌入模型面临的挑战,特别是它们在有效处理词序方面的困难。具体来说,我们识别出了五种主要的失败类型:方向性、时序、因果、比较和否定。这些是词序真正重要的查询类型,如果你的使用场景涉及其中任何一种,了解这些模型的局限性是很有价值的。
我们还进行了一个快速实验,将以否定为重点的数据集扩展到覆盖所有五种失败类别。结果令人鼓舞:通过精心选择的"难否定样例"进行微调,使模型更好地识别哪些项目应该归类在一起,哪些不应该。话虽如此,还有更多工作要做。未来的步骤包括深入研究数据集的大小和质量如何影响性能。





