

在实验 ColPali 风格模型时,我们的一位工程师使用最近发布的 jina-clip-v2 模型创建了一个可视化。他映射了给定图像-文本对之间的 token 嵌入和图像块嵌入的相似度,创建了热力图叠加层,产生了一些有趣的视觉洞察。

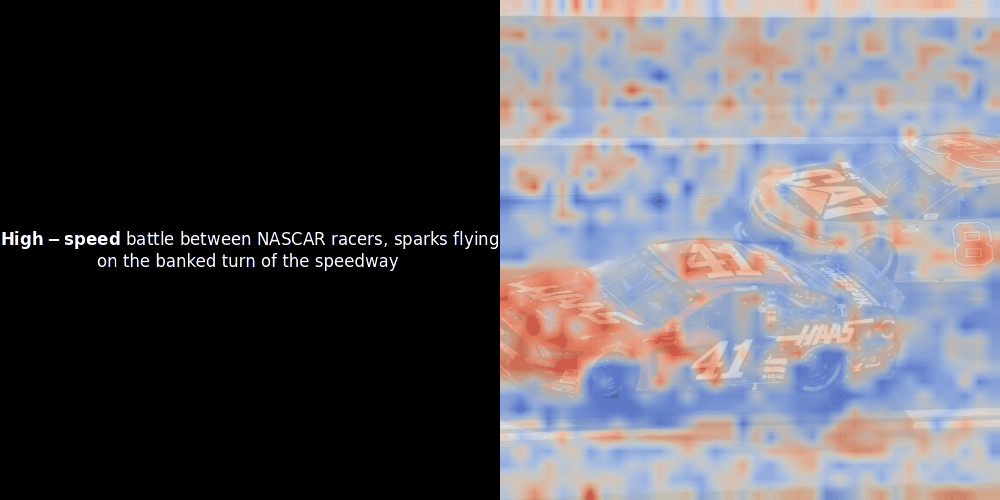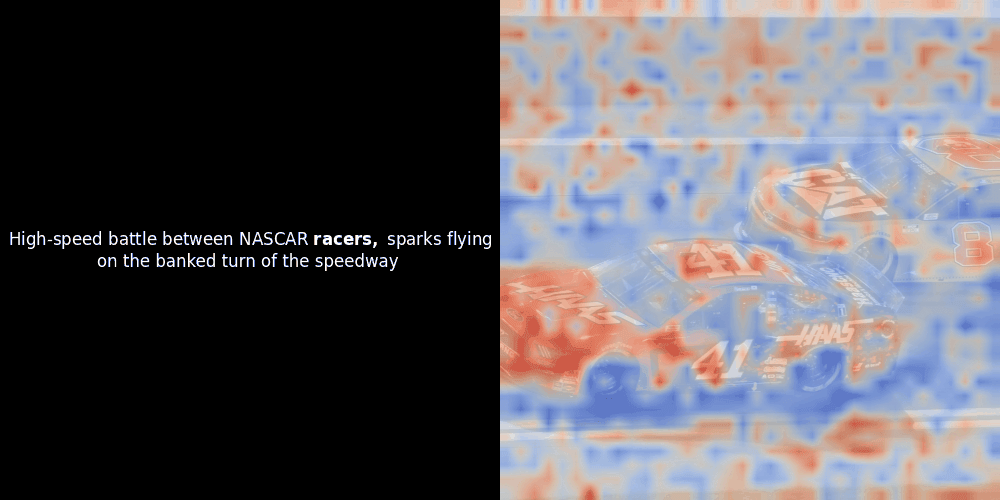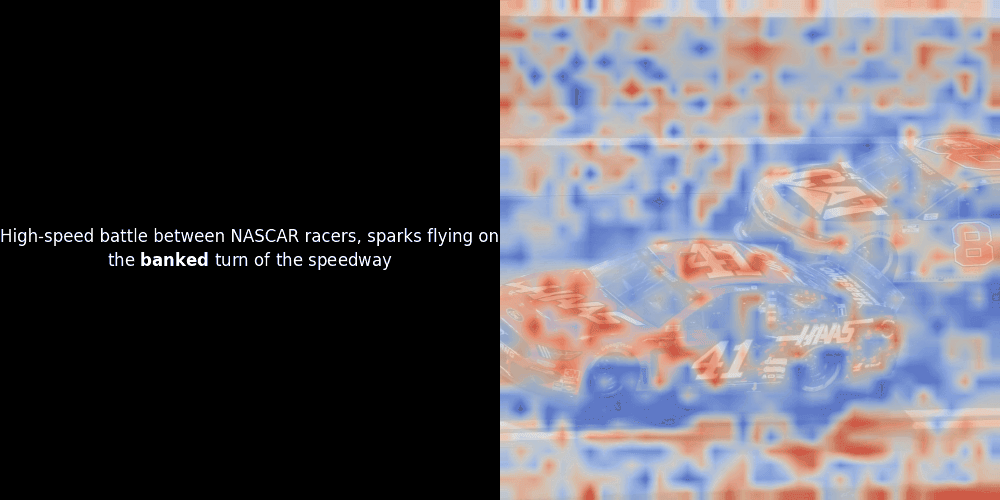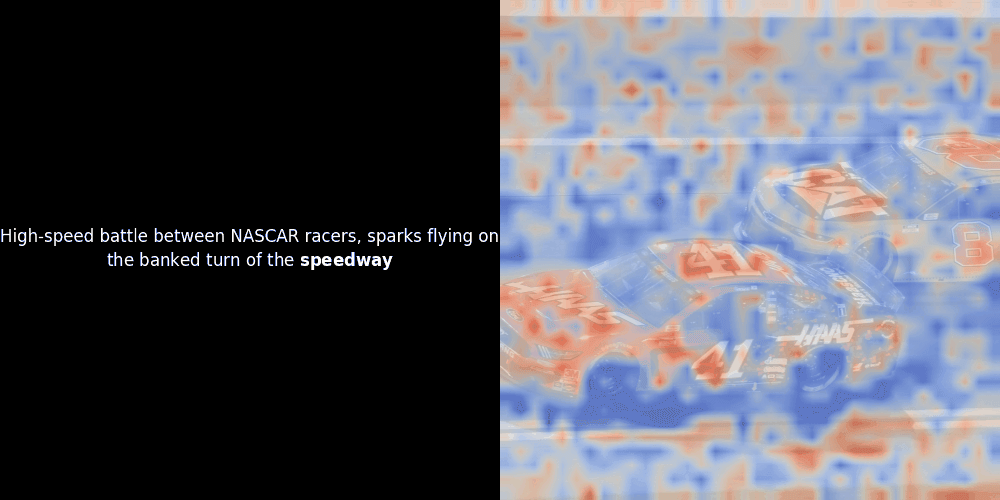
不幸的是,这只是一个启发式可视化——而不是一个明确或有保证的机制。虽然类 CLIP 的全局对比对齐可能(而且经常会)偶然地在图像块和 token 之间创建粗略的局部对齐,但这是一个意外的副作用,而不是模型的刻意目标。让我解释原因。
tag理解代码

让我们从高层次分析代码在做什么。注意,默认情况下 jina-clip-v2 实际上并没有暴露任何用于访问 token 级别或图像块级别嵌入的 API——这个可视化需要一些后期修补才能工作。
计算词级嵌入
通过设置 model.text_model.output_tokens = True,调用 text_model(x=...,)[1] 将返回一个形状为 (batch_size, seq_len, embed_dim) 的第二个元素作为 token 嵌入。它接收一个输入句子,用 Jina CLIP tokenizer 进行分词,然后通过平均相应的 token 嵌入将子词 token 重新组合成"词"。它通过检查 token 字符串是否以 _ 字符开头(在基于 SentencePiece 的分词器中很常见)来检测新词的开始。它生成一个词级嵌入列表和一个词列表(所以"Dog"是一个嵌入,"and"是一个嵌入,等等)。
计算图像块级嵌入
对于图像塔,vision_model(..., return_all_features=True) 将返回形状为 (batch_size, n_patches+1, embed_dim) 的张量,其中第一个 token 是 [CLS] token。从中,代码提取每个图像块的嵌入(即视觉 transformer 的图像块 token)。然后将这些图像块嵌入重塑为二维网格,patch_side × patch_side,然后上采样以匹配原始图像分辨率。
可视化词-图像块相似度
相似度计算和随后的热力图生成是标准的"后验"可解释性技术:你选择一个文本嵌入,计算它与每个图像块嵌入的余弦相似度,然后生成一个热力图,显示哪些图像块与该特定 token 嵌入的相似度最高。最后,它遍历句子中的每个 token,在左侧以粗体突出显示该 token,并在右侧的原始图像上叠加基于相似度的热力图。所有帧被编译成一个动态 GIF。
tag这是有意义的可解释性吗?
从纯代码的角度来看,是的,逻辑是连贯的,会为每个 token 生成热力图。你会得到一系列显示图像块相似度的帧,所以脚本"确实做到了它说要做的事情"。
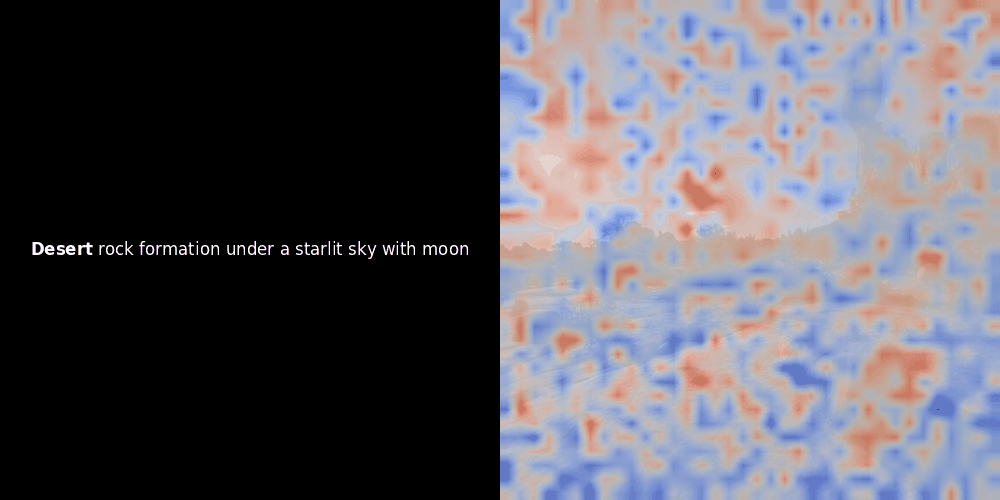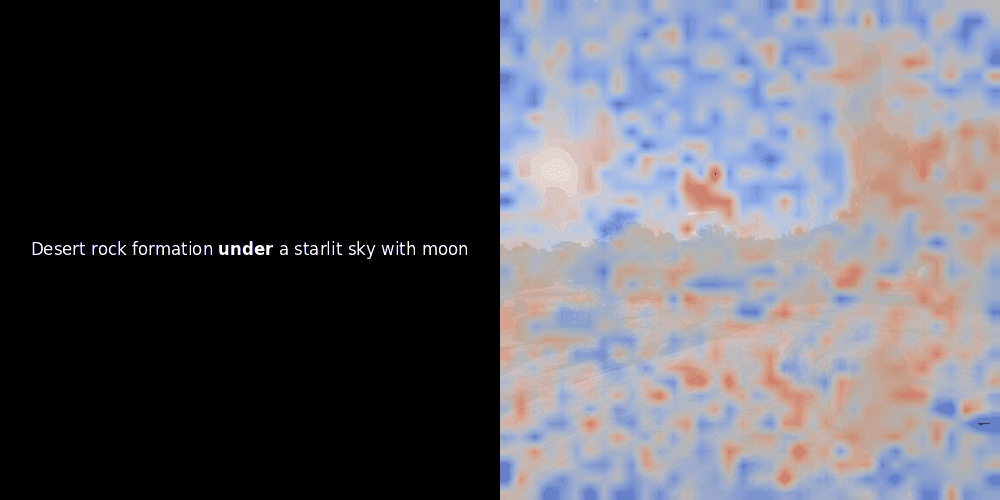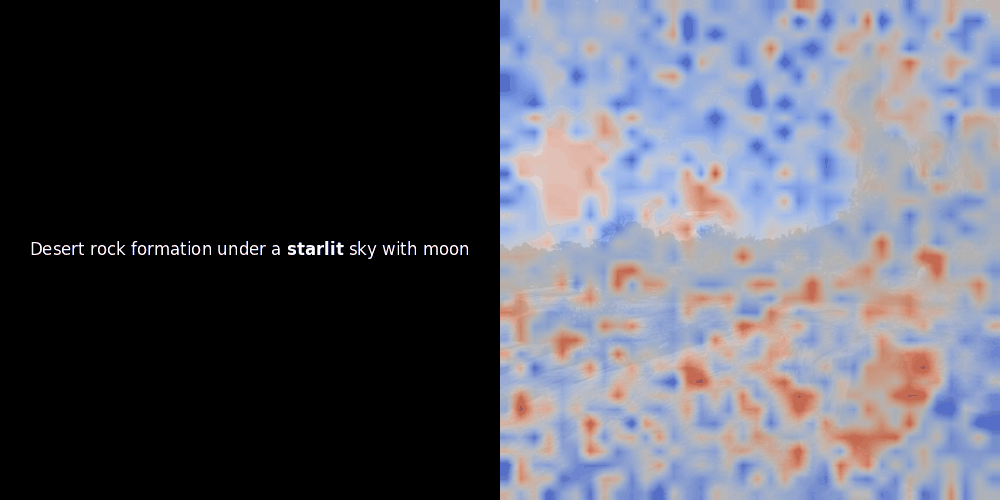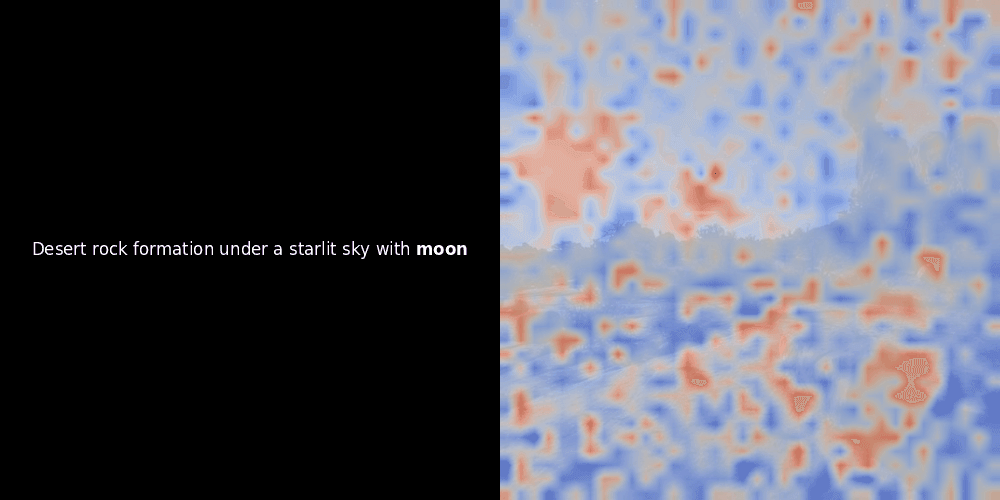

看上面的例子,我们可以看到像 moon 和 branches 这样的词似乎与原始图像中对应的视觉块对齐得很好。但这里的关键问题是:这是有意义的对齐,还是我们仅仅看到了一个幸运的巧合?
这是一个更深层次的问题。要理解其中的注意事项,回想一下 CLIP 是如何训练的:

- CLIP 使用整个图像和整段文本之间的全局对比对齐。在训练过程中,图像编码器生成单个向量(池化表示),文本编码器生成另一个单个向量;CLIP 被训练成使这些向量在匹配的文本-图像对中匹配,在其他情况下不匹配。
- 在"图像块 X 对应于 token Y"级别上没有显式监督。模型并没有被直接训练来突出显示"图像的这个区域是狗,那个区域是猫"等。相反,它被教导整个图像表示应该与整个文本表示匹配。
- 因为 CLIP 的架构在图像端使用 Vision Transformer,在文本端使用文本 transformer——两者形成独立的编码器——所以没有本地对齐图像块和 token 的交叉注意力模块。相反,你在每个塔中得到的是纯粹的自注意力,加上最终的全局图像或文本嵌入投影。
简而言之,这是一个启发式可视化。任何给定的图像块嵌入可能与特定 token 嵌入接近或远离,这在某种程度上是自然涌现的。它更像是一个后验可解释性技巧,而不是模型的稳健或官方"注意力"。
tag为什么可能会出现局部对齐?
那么为什么我们有时会发现词-图像块级别的局部对齐呢?事情是这样的:尽管 CLIP 是在全局图像-文本对比目标上训练的,但它仍然使用自注意力(在基于 ViT 的图像编码器中)和 transformer 层(用于文本)。在这些自注意力层中,图像表示的不同部分可以相互交互,就像文本表示中的词一样。通过在海量图像-文本数据集上的训练,模型自然地发展出内部潜在结构,帮助它将整体图像与其对应的文本描述匹配。

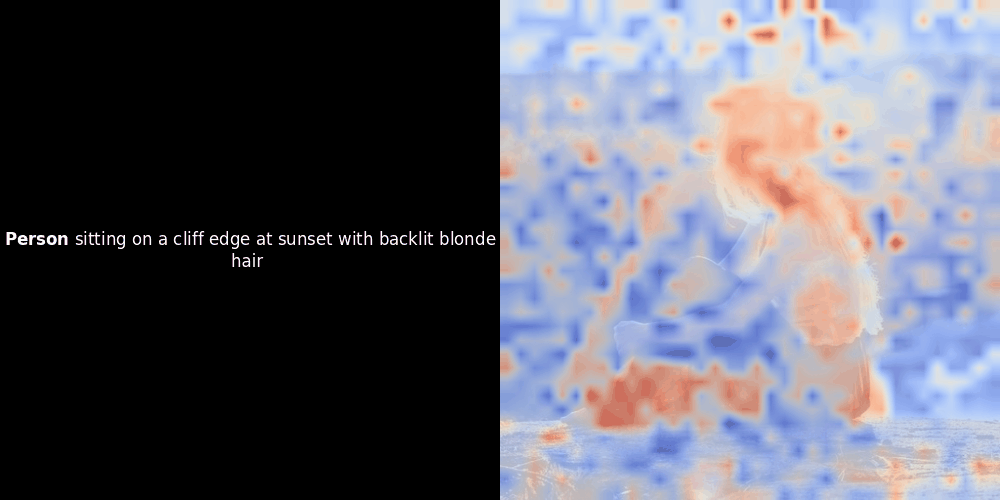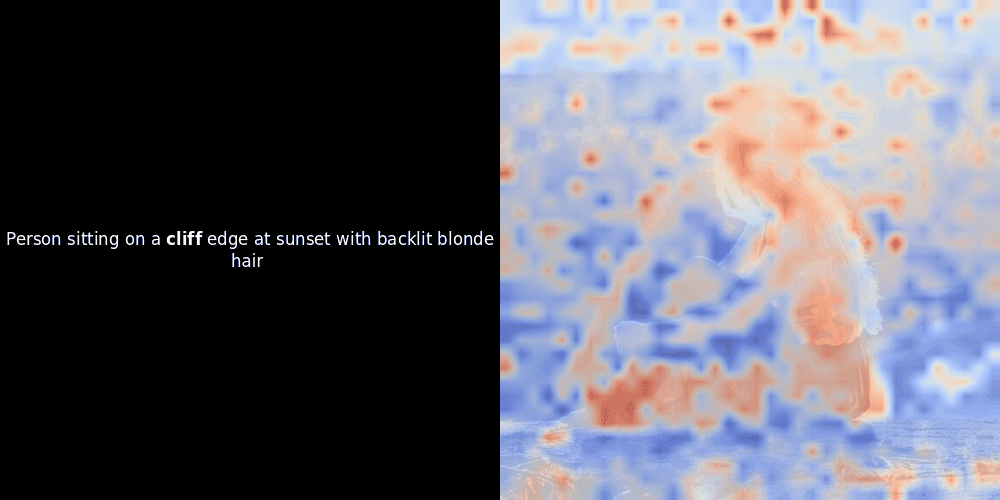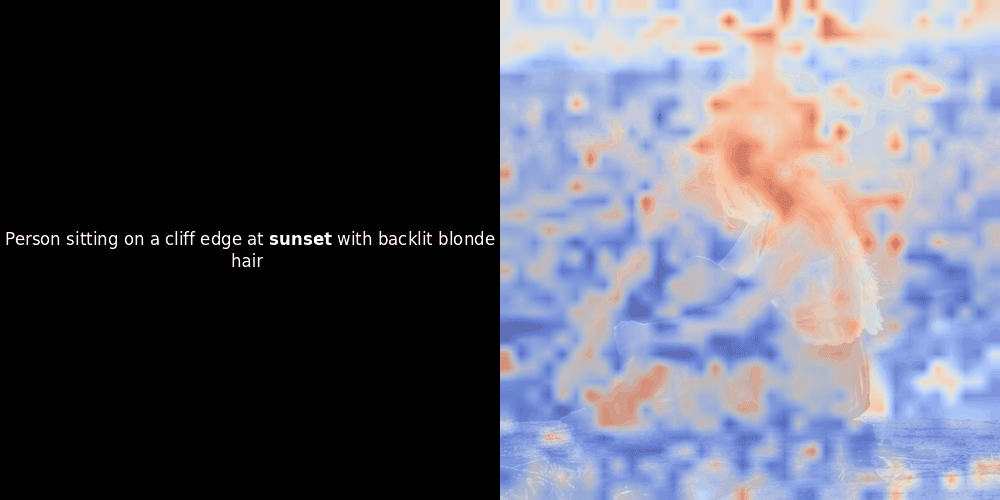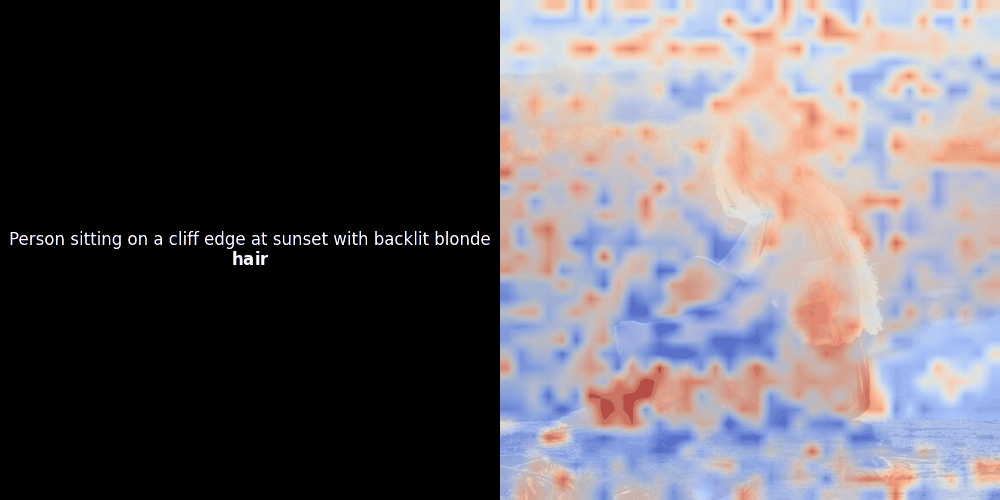
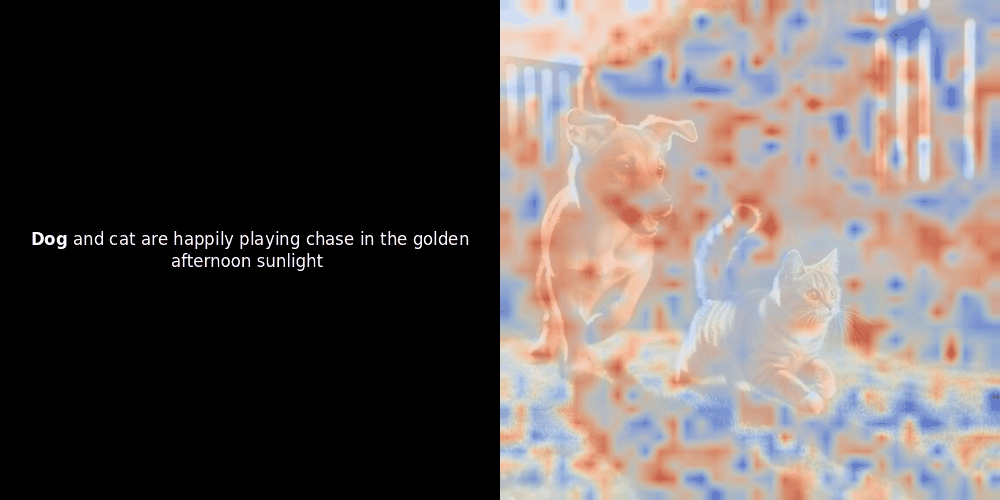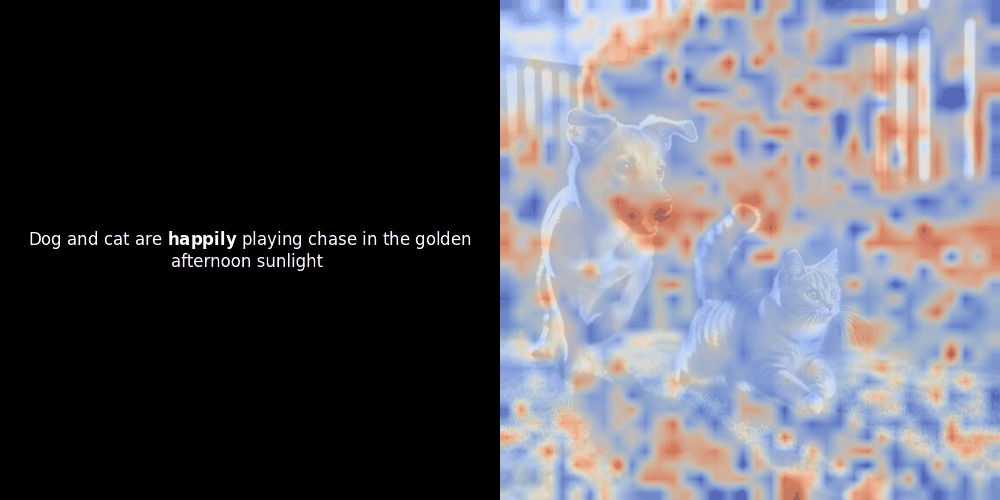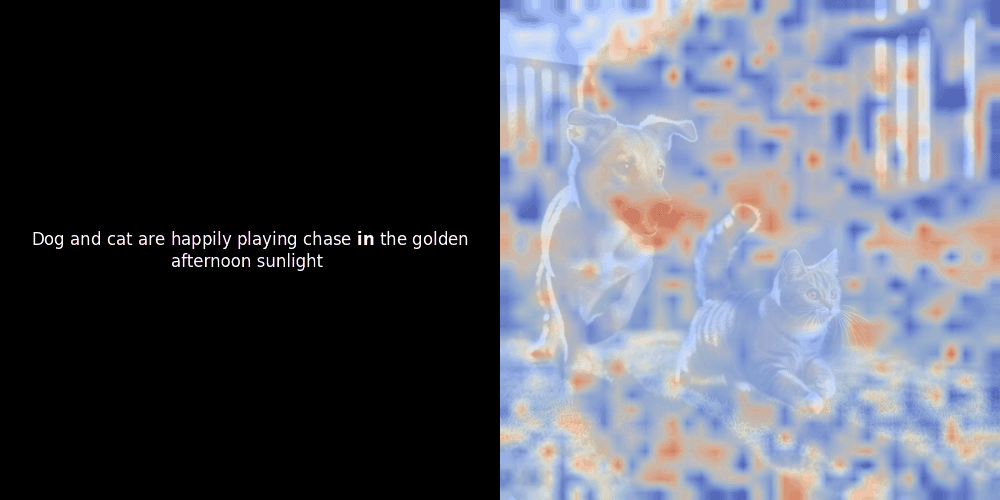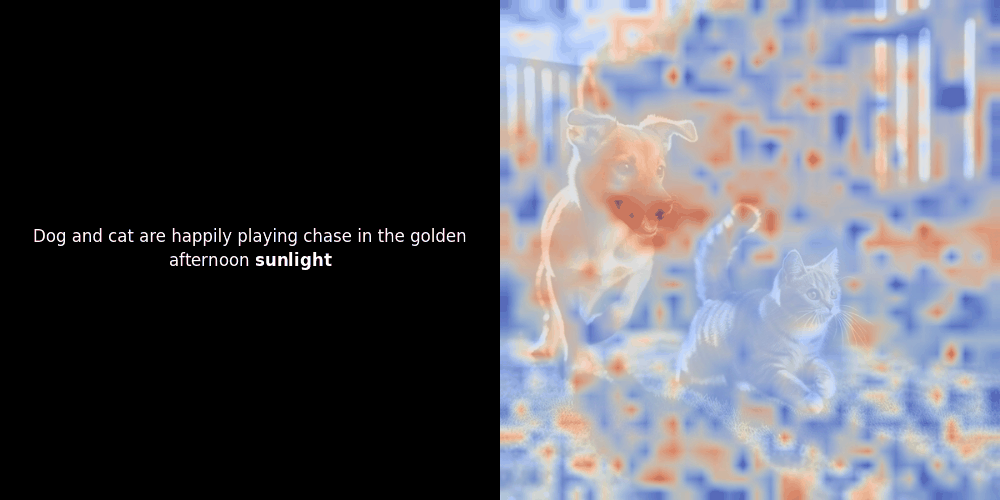
局部对齐可能在这些潜在表示中出现,至少有两个原因:
- 共现模式:如果模型看到许多"狗"旁边的"猫"的图像(通常带有这些词的标签或描述),它可以学习大致对应于这些概念的潜在特征。因此,"狗"的嵌入可能会接近描绘狗形状或纹理的局部图像块。这在图像块级别不是显式监督的,而是从狗图像/文本对的重复关联中涌现出来的。
- Self-attention:在 Vision Transformers 中,图像块之间会相互关注。显著的图像块(比如狗的脸)最终可能会得到一个一致的潜在"特征",因为模型试图为整个场景生成一个全局准确的表示。如果这有助于最小化整体对比损失,这种特征就会得到加强。
tag理论分析
CLIP 的对比学习目标是最大化匹配的图文对之间的余弦相似度,同时最小化不匹配对之间的相似度。假设文本和图像编码器分别产生 token 和图像块嵌入:
全局相似度可以表示为局部相似度的聚合:
当特定的 token-patch 对在训练数据中经常共同出现时,模型通过累积梯度更新来加强它们的相似度:
,其中 是共同出现的次数。这导致 显著增加,促进这些对的局部对齐更加紧密。然而,对比损失会在所有 token-patch 对之间分配梯度更新,限制了特定对的更新强度:
这防止了单个 token-patch 相似度的显著加强。
tag结论
CLIP 的 token-patch 可视化利用了文本和图像表示之间偶然的、自发的对齐。这种对齐虽然很有趣,但源于 CLIP 的全局对比训练,缺乏精确可靠可解释性所需的结构稳健性。由此产生的可视化结果经常表现出噪声和不一致性,限制了其在深入解释应用中的实用性。

像 ColBERT 和 ColPali 这样的后期交互模型通过在架构上嵌入明确的、细粒度的对齐来解决这些限制,实现文本 token 和图像块之间的对齐。通过独立处理不同模态并在后期阶段执行有针对性的相似度计算,这些模型确保每个文本 token 都能与相关的图像区域建立有意义的关联。





