


语义嵌入是现代 AI 模型的核心,包括聊天机器人和 AI 艺术模型。它们有时对用户是隐藏的,但它们一直存在,就在表面之下。
嵌入理论只有两个部分:
- 事物 —— AI 模型外部的事物,如文本和图像 —— 由 AI 模型根据这些事物的数据创建的向量来表示。
- AI 模型外部事物之间的关系由这些向量之间的空间关系来表示。我们专门训练 AI 模型来创建以这种方式工作的向量。
当我们制作图像-文本多模态模型时,我们训练模型使图片的嵌入和描述或与这些图片相关的文本的嵌入相对接近。这两个向量所代表的事物 —— 图像和文本 —— 之间的语义相似性反映在两个向量之间的空间关系中。
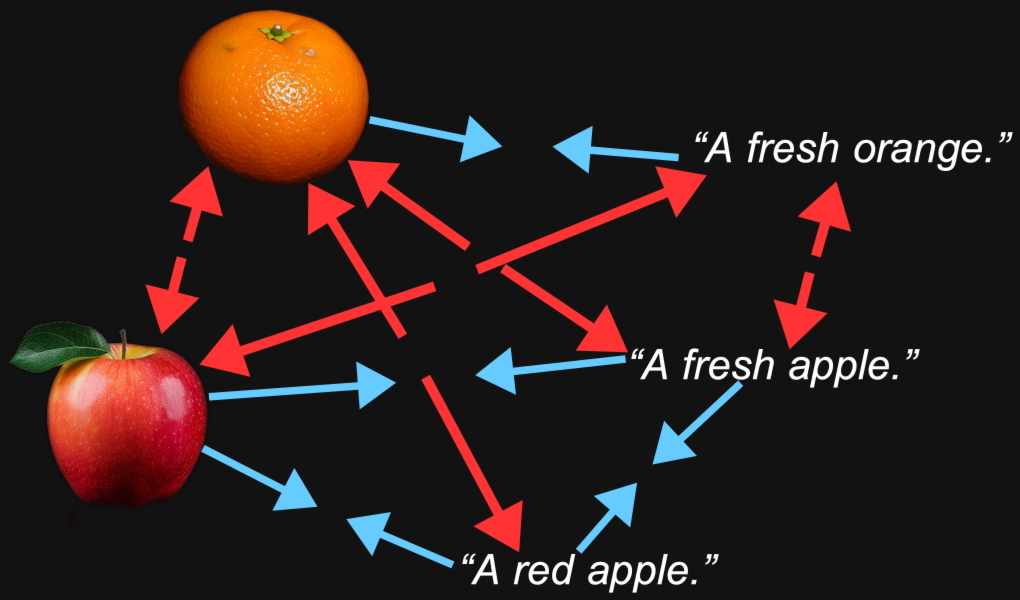
例如,我们可以合理地预期,一个橙子的图像的嵌入向量与"一个新鲜的橙子"这个文本的距离,会比同一个图像与"一个新鲜的苹果"这个文本的距离更近。
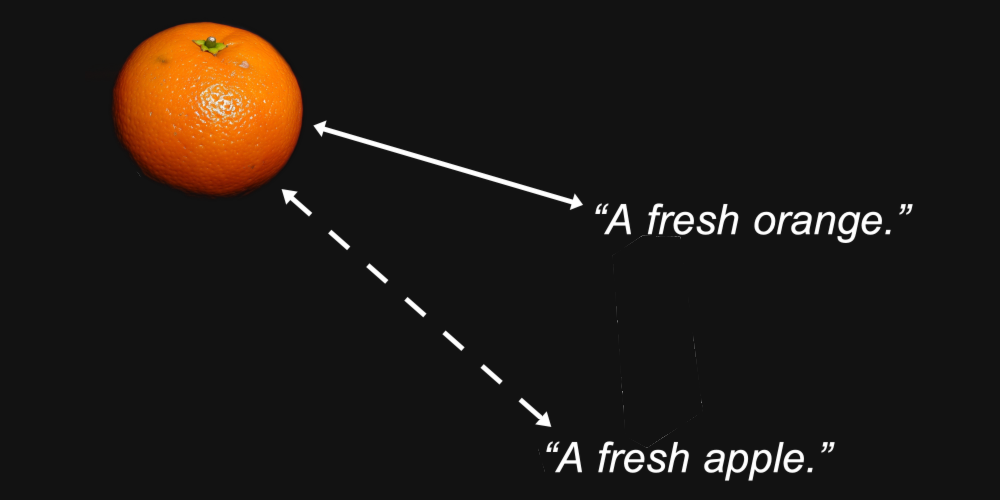
这就是嵌入模型的目的:生成能够在它们之间的距离中保持我们关心的特征 —— 比如图像中描绘的或文本中命名的水果类型 —— 的表示。
但多模态引入了其他情况。我们可能发现,一张橙子的图片与一张苹果的图片的距离,比它与"一个新鲜的橙子"这个文本的距离更近,而"一个新鲜的苹果"这个文本与另一个文本的距离,比它与苹果图像的距离更近。
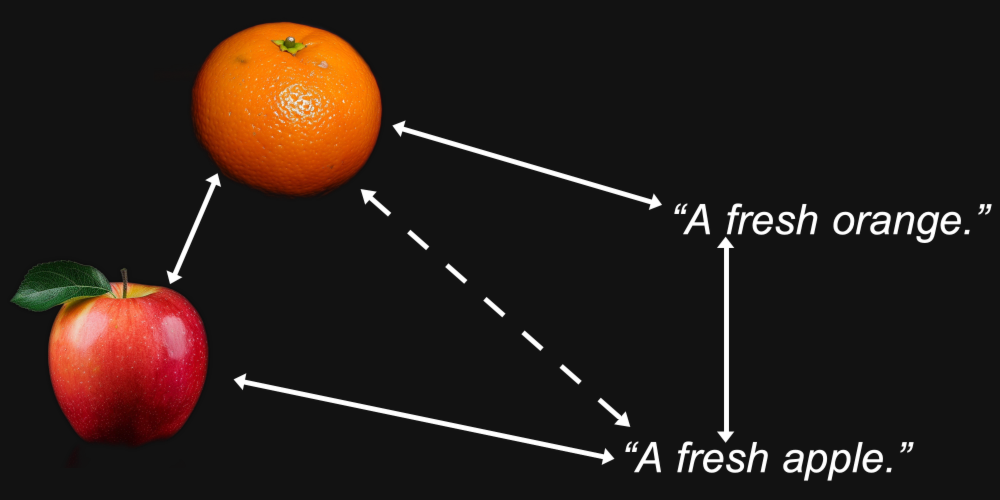
事实证明,这正是多模态模型中发生的情况,包括 Jina AI 自己的 Jina CLIP 模型(jina-clip-v1)。
为了测试这一点,我们从 Flickr8k 测试集中抽取了 1,000 对文本-图像对。每对包含五个说明文本(所以严格来说不是一对)和一张图片,所有五个文本都描述同一张图片。
例如,以下图片(Flickr8k 数据集中的 1245022983_fb329886dd.jpg):

它的五个说明文本:
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
我们使用 Jina CLIP 对图像和文本进行嵌入,然后:
- 比较图像嵌入与其说明文本嵌入之间的余弦相似度。
- 取描述同一图像的所有五个说明文本的嵌入,并比较它们之间的余弦相似度。
结果显示出一个令人惊讶的巨大差距,如图 1 所示:
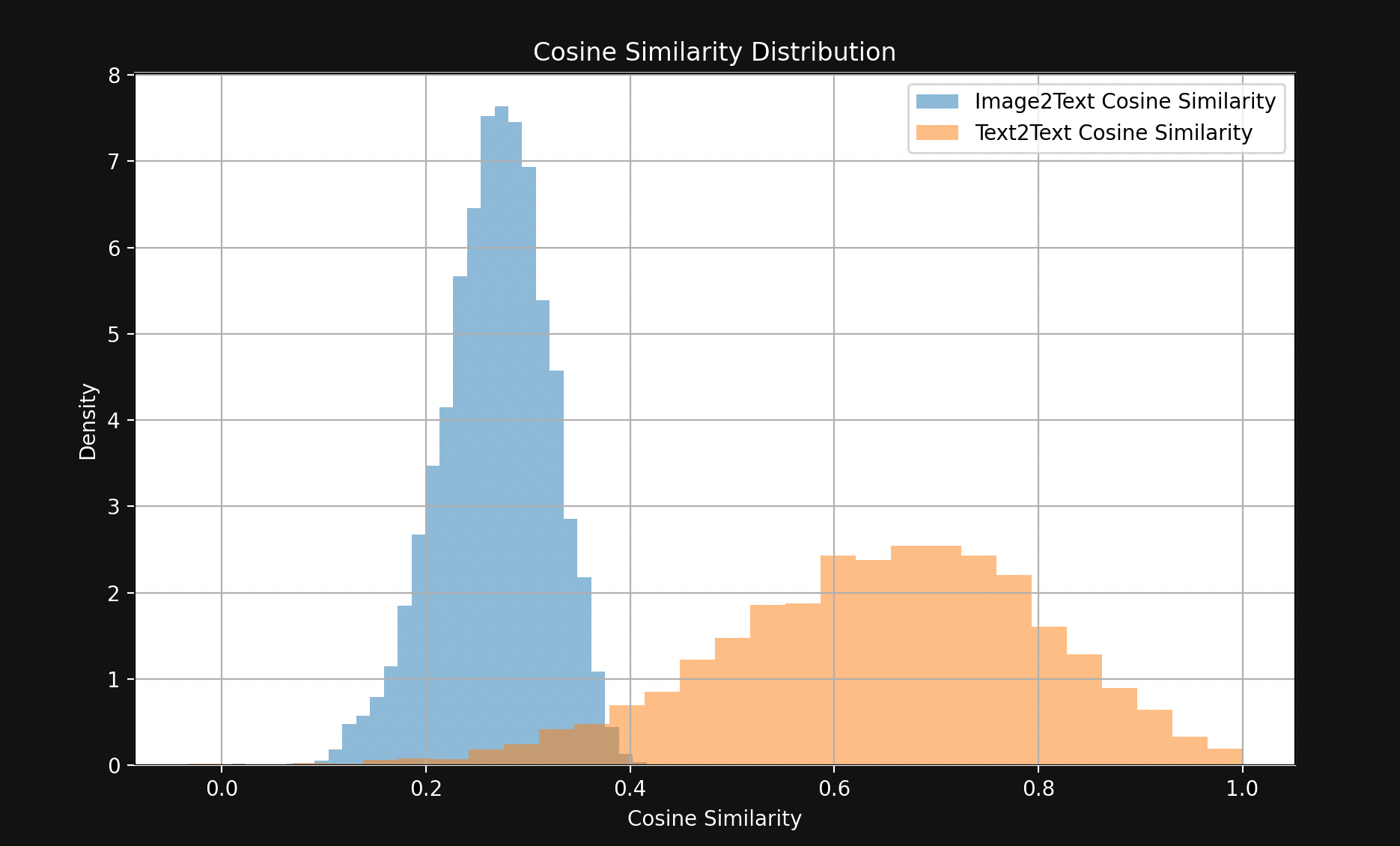
除了少数例外,匹配的文本对之间的距离比匹配的图像-文本对更近。这强烈表明 Jina CLIP 是在嵌入空间的一个部分编码文本,而在另一个相对较远的、基本上不相交的部分编码图像。文本和图片之间的这个空间就是多模态差距。

多模态嵌入模型不仅编码我们关心的语义信息:它们还编码了输入的媒体类型。根据 Jina CLIP,一张图片并不如俗话说的那样值千言万语。它包含了任何数量的文字都永远无法真正等同的内容。它在没有经过专门训练的情况下,就把输入媒体类型编码到了其嵌入的语义中。
这一现象在论文《Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning》[Liang et al., 2022]中被研究过,该论文将其称为"模态差距"。模态差距是指在嵌入空间中,一种媒体的输入与另一种媒体的输入之间的空间分离。尽管模型并未有意训练出这种差距,但它们在多模态模型中普遍存在。
我们对 Jina CLIP 中模态差距的研究很大程度上基于 Liang et al. [2022]。
tag模态差距从何而来?
Liang et al. [2022] 确定了模态差距背后的三个主要来源:
- 他们称之为"锥形效应"的初始化偏差。
- 训练过程中温度(随机性)的降低,使得"解除学习"这种偏差变得非常困难。
- 对比学习程序,这在多模态模型中被广泛使用,无意中加强了这种差距。
我们将逐一讨论这些问题。
tag锥形效应
使用 CLIP 或 CLIP 风格架构构建的模型实际上是两个独立的嵌入模型相互连接。对于图像-文本多模态模型来说,这意味着一个用于编码文本的模型,和一个完全独立的用于编码图像的模型,如下图所示。
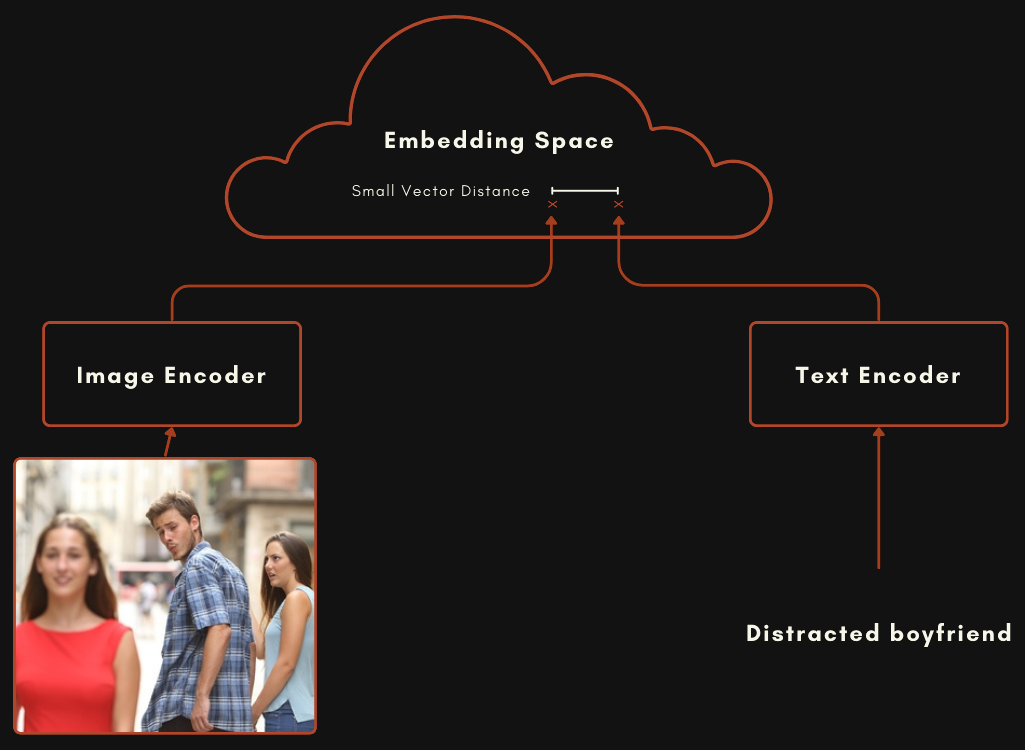
这两个模型经过训练,使得当文本能很好地描述图像时,图像嵌入和文本嵌入的距离相对较近。
你可以通过随机初始化两个模型的权重,然后将图像和文本对一起输入,从头开始训练以最小化两个输出之间的距离来训练这样的模型。最初的 OpenAI CLIP 模型就是通过这种方式训练的。然而,这需要大量的图像-文本对和大量的计算密集型训练。对于第一个 CLIP 模型,OpenAI 从互联网上有标题的材料中抓取了 4 亿个图像-文本对。
最近的 CLIP 风格模型使用预训练组件。这意味着分别训练每个组件成为一个优秀的单模态嵌入模型,一个用于文本,一个用于图像。然后,这两个模型使用图像-文本对进行进一步的联合训练,这个过程被称为对比调优。使用对齐的图像-文本对来缓慢地"推动"权重,使匹配的文本和图像嵌入更接近,而不匹配的更远离。
这种方法通常需要较少的图像-文本对数据(这些数据获取困难且成本高),以及大量无标题的纯文本和图像(这些更容易获取)。Jina CLIP(jina-clip-v1)就是使用后一种方法训练的。我们使用通用文本数据预训练了一个 JinaBERT v2 模型用于文本编码,并使用预训练的 EVA-02 图像编码器,然后使用各种对比训练技术进行进一步训练,详见 Koukounas et al. [2024]
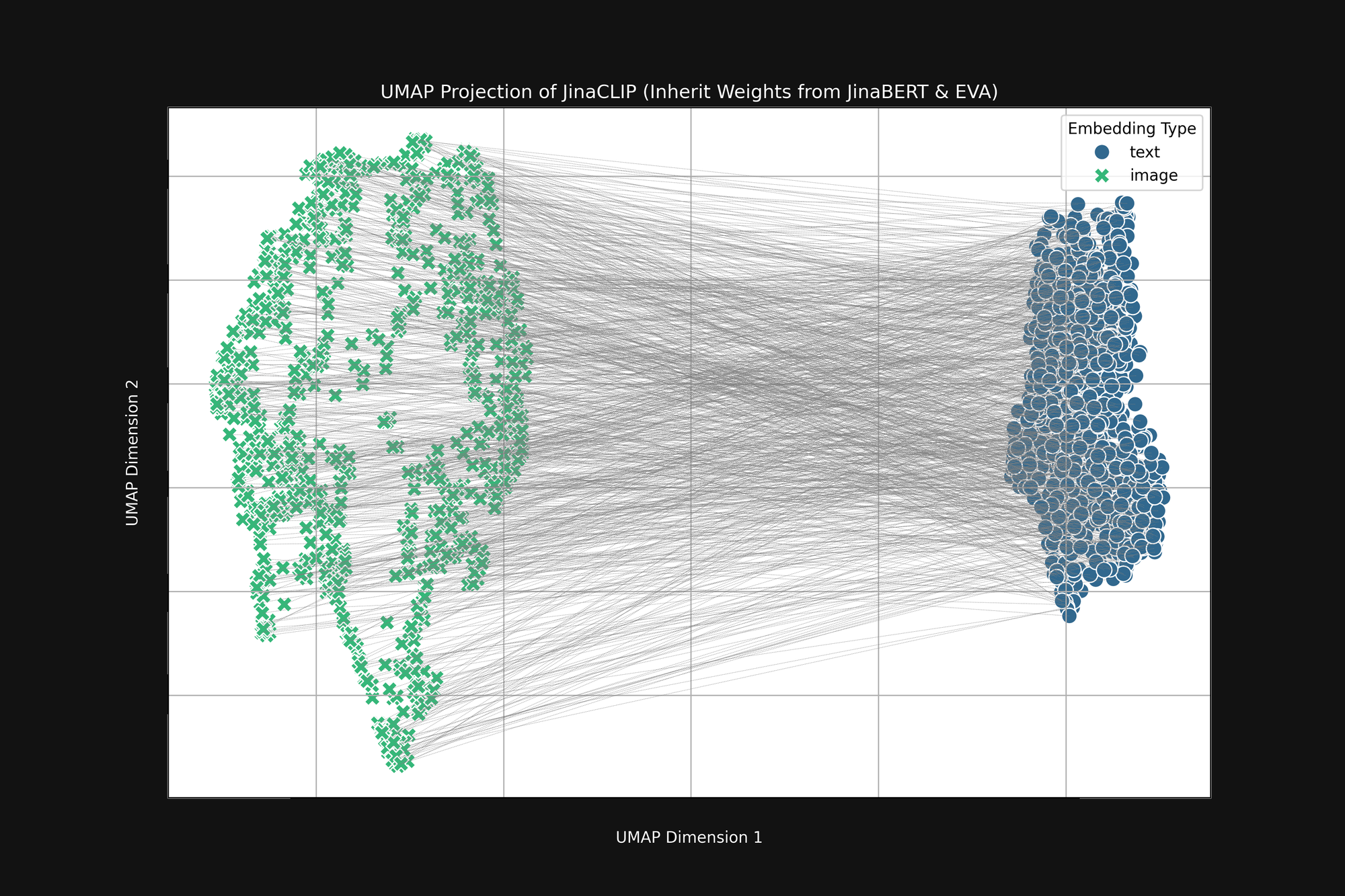
如果我们在使用图像-文本对训练之前查看这两个预训练模型的输出,我们会注意到一些重要的事情。图 2(上图)是使用 UMAP 投影将预训练 EVA-02 编码器产生的图像嵌入和预训练 JinaBERT v2 产生的文本嵌入投影到二维空间,灰色线条表示匹配的图像-文本对。这是在任何跨模态训练之前的状态。
结果是一个类似截断"圆锥"的形状,一端是图像嵌入,另一端是文本嵌入。这个圆锥形状在二维投影中难以完全展现,但你可以在上图中大致看到。所有文本都聚集在嵌入空间的一部分,所有图像聚集在另一部分。如果在训练后,文本仍然与其他文本的相似度高于与匹配图像的相似度,这个初始状态就是一个重要原因。最佳匹配图像到文本、文本到文本、图像到图像的目标完全兼容这种圆锥形状。
模型在"出生"时就带有偏见,而学习过程并没有改变这一点。图 3(下图)是发布的 Jina CLIP 模型在使用图像-文本对完全训练后的相同分析。如果有什么不同的话,多模态差距甚至更加明显。
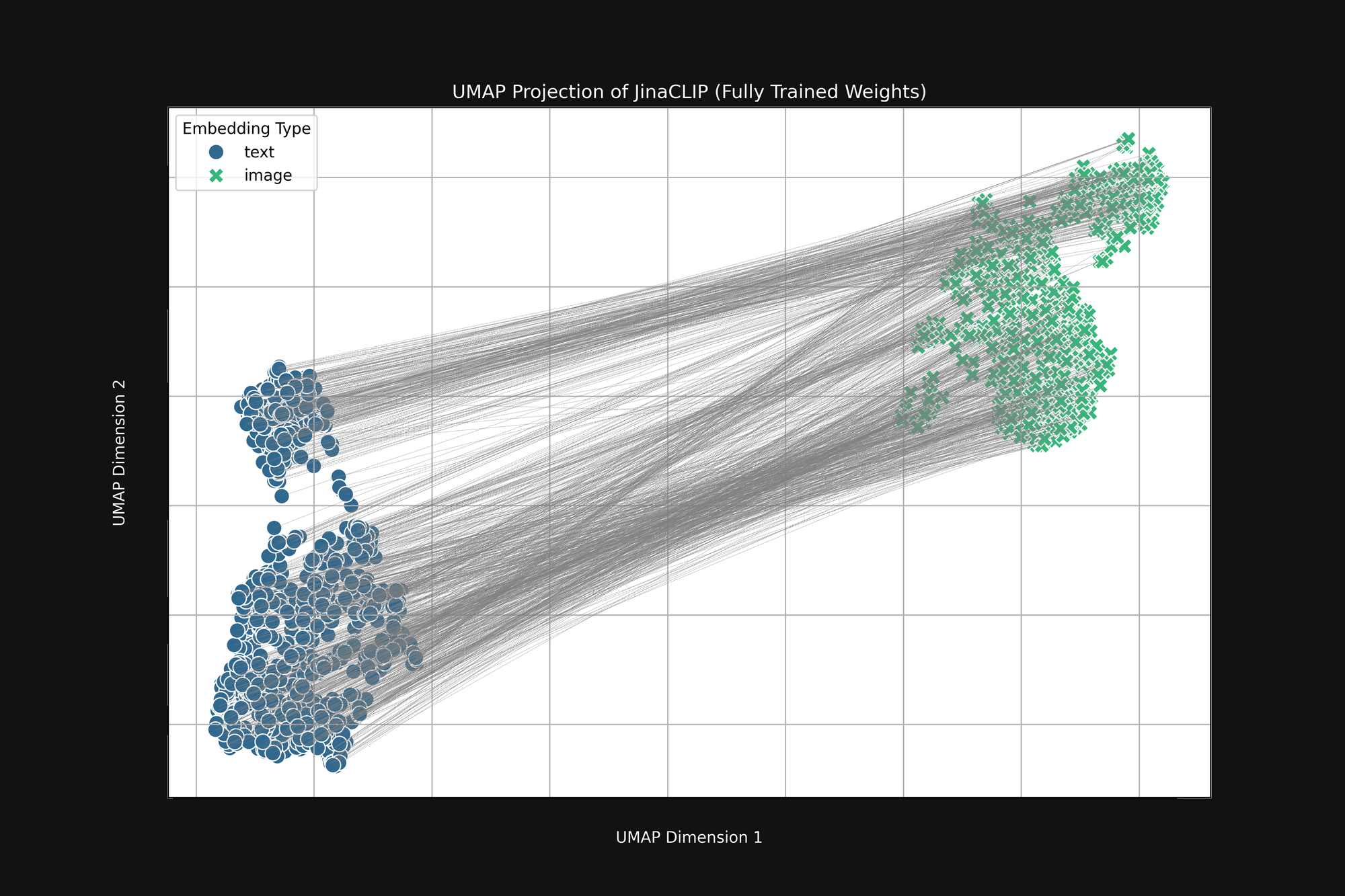
即使经过大量训练,Jina CLIP 仍然将媒介作为信息的一部分进行编码。
使用更昂贵的 OpenAI 方法,采用纯随机初始化,也无法消除这种偏差。我们采用了原始 OpenAI CLIP 架构并完全随机化所有权重,然后进行了与上述相同的分析。结果仍然是一个截断的圆锥形状,如图 4 所示:
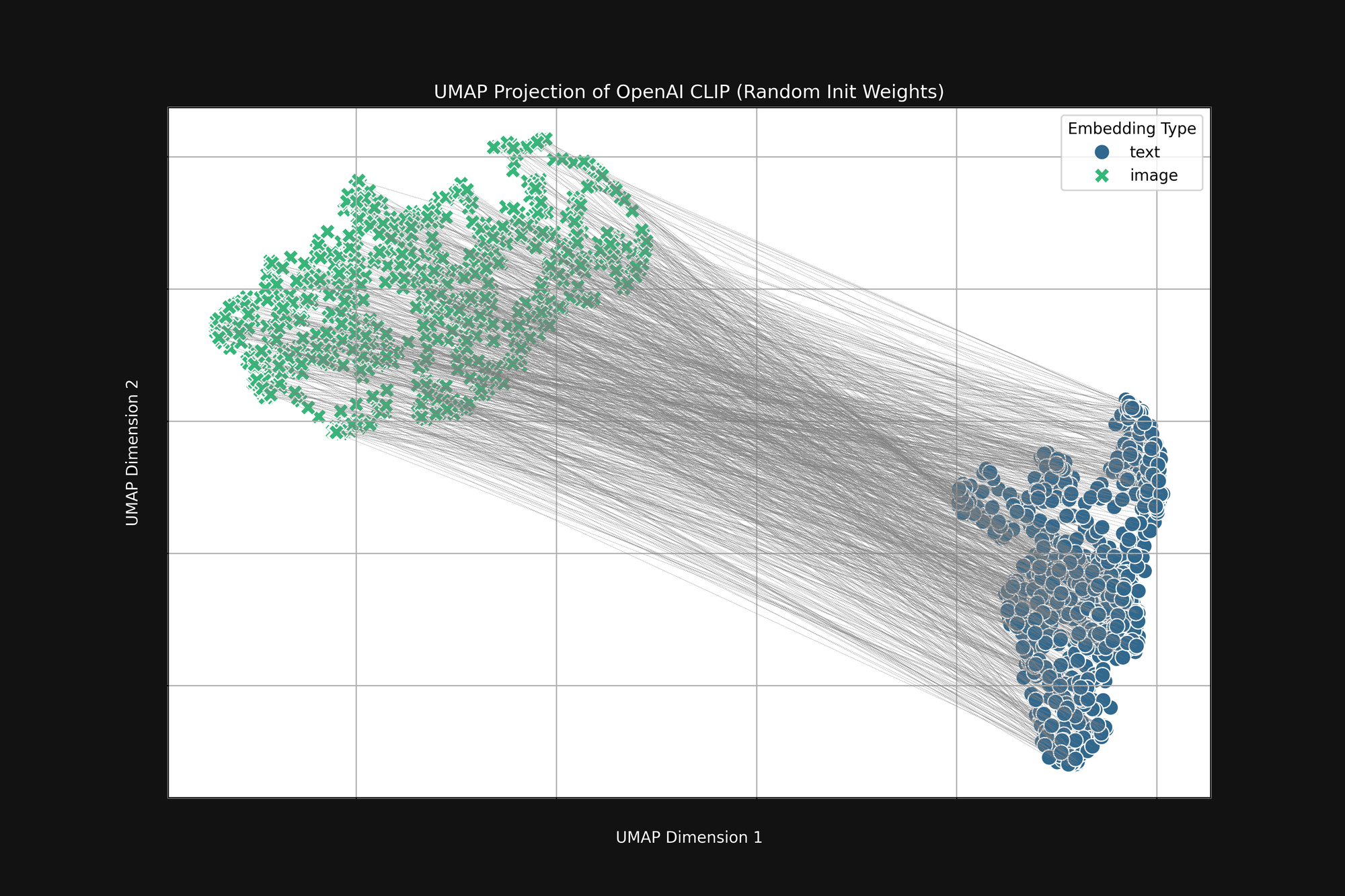
这种偏差是一个结构性问题,可能没有任何解决方案。如果是这样,我们只能寻找在训练过程中纠正或缓解它的方法。
tag训练温度
在 AI 模型训练过程中,我们通常会添加一些随机性。我们计算一批训练样本应该如何改变模型中的权重,然后在实际改变权重之前添加一个小的随机因子。我们把这种随机性的量称为温度,这是类比于我们在热力学中使用随机性的方式。
高温度会使模型快速发生很大的变化,而低温度会减少模型每次看到一些训练数据时可以改变的量。结果是,在高温度下,我们可以预期单个嵌入在嵌入空间中会大幅移动,而在低温度下,它们的移动会慢得多。
训练 AI 模型的最佳实践是以高温度开始,然后逐渐降低。这有助于模型在开始时(当权重要么是随机的,要么离目标还很远时)进行大的学习跳跃,然后让它更稳定地学习细节。
Jina CLIP 图像-文本对训练从 0.07 的温度开始(这是一个相对较高的温度),然后在训练过程中指数级降低到 0.01,如下面图 5 所示,这是温度与训练步骤的关系图:
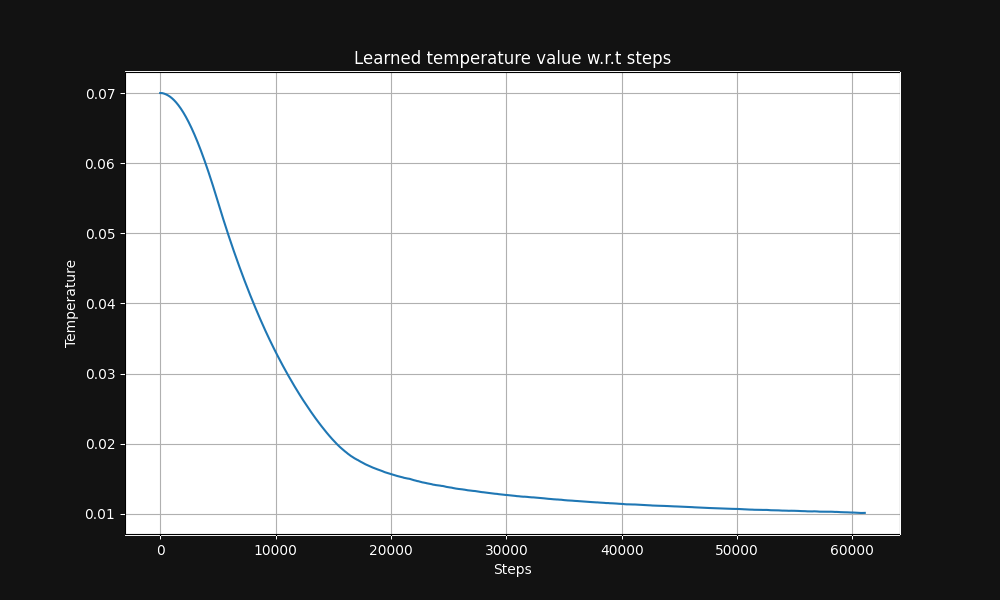
我们想知道提高温度——增加随机性——是否会减少圆锥效应,使图像嵌入和文本嵌入整体上更接近。因此,我们用固定的 0.1 温度(一个很高的值)重新训练了 Jina CLIP。在每个训练轮次之后,我们检查图像-文本对和文本-文本对之间的距离分布,就像图 1 中那样。结果如下图 6 所示:
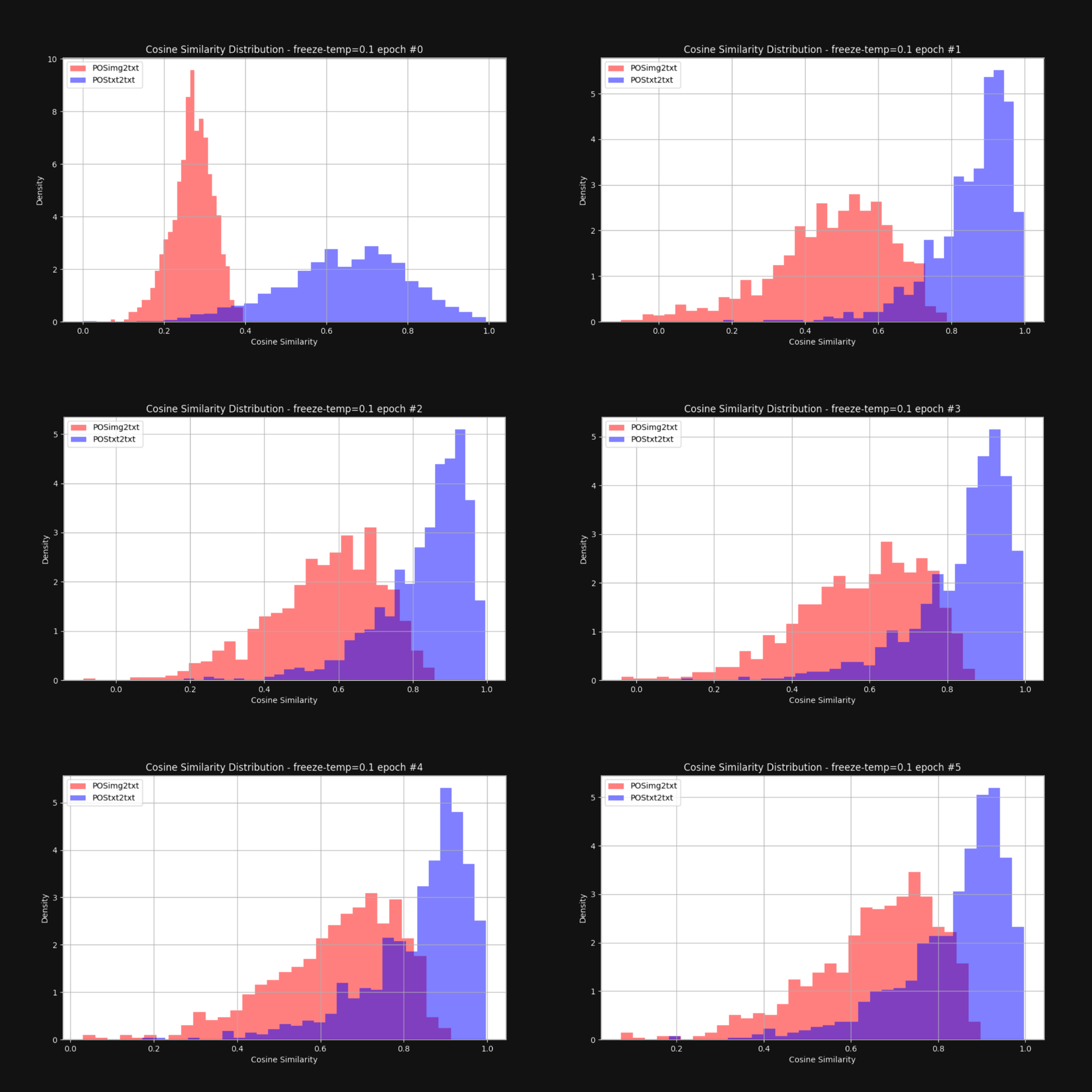
如你所见,保持高温确实能显著缩小多模态差距。在训练过程中允许嵌入向量有较大的移动空间,这对克服初始嵌入分布的偏差有很大帮助。
然而,这也是有代价的。我们还使用了六种不同的检索测试来测试模型性能:三个文本-文本检索测试和三个文本-图像检索测试,数据来自 MS-COCO、Flickr8k 和 Flickr30k 数据集。在所有测试中,我们都看到性能在训练初期急剧下降,然后才非常缓慢地上升,如图 7 所示:
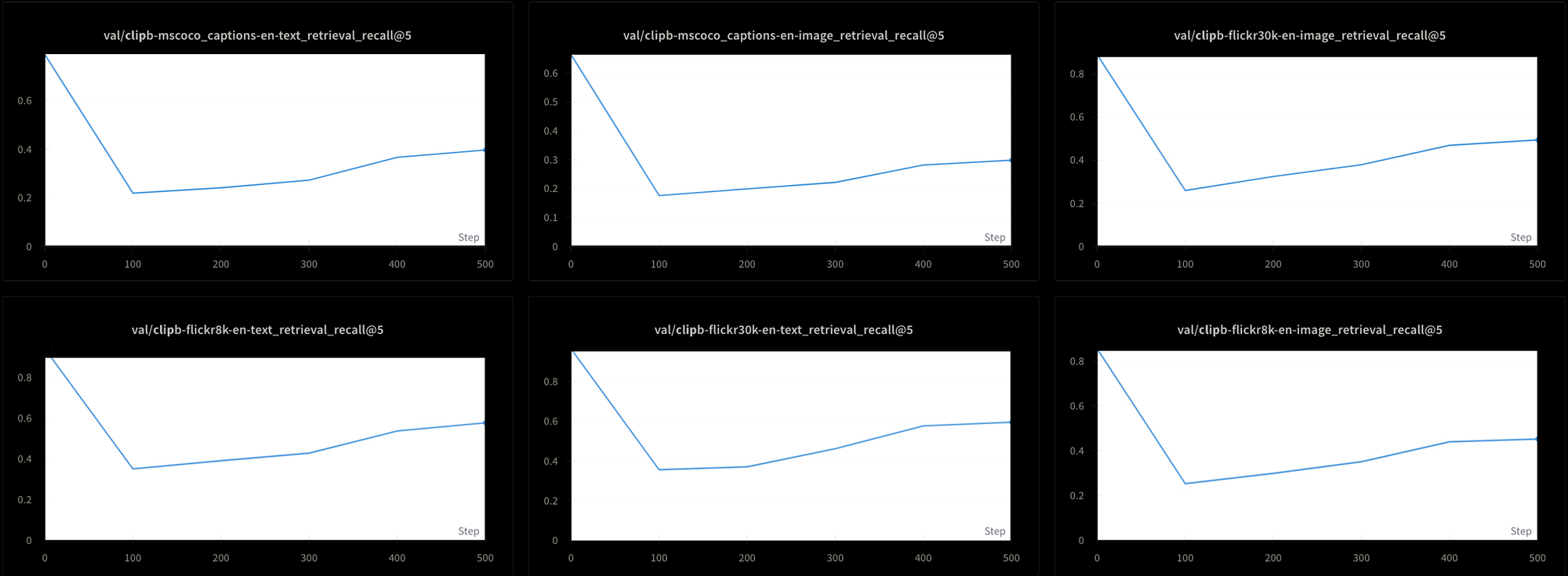
使用这种持续的高温来训练像 Jina CLIP 这样的模型可能会非常耗时且昂贵。尽管理论上可行,但这并不是一个实用的解决方案。
tag对比学习和假负样本问题
Liang 等人 [2022] 还发现,标准的对比学习实践——我们用来训练 CLIP 式多模态模型的机制——倾向于加剧多模态差距。
对比学习从根本上说是一个简单的概念。我们有一个图像嵌入和一个文本嵌入,我们知道它们应该更接近,所以我们在训练过程中调整模型的权重来实现这一点。我们慢慢地调整,每次只调整一小部分,并且根据两个嵌入的距离来调整权重:距离越近意味着调整的幅度越小,反之则越大。
这种技术在不仅要让匹配的嵌入更接近,还要让不匹配的嵌入更远离时效果会更好。我们不仅需要应该在一起的图像-文本对,还需要我们知道应该分开的对。
这带来了一些问题:
- 我们的数据源完全由匹配对组成。没有人会创建一个经过人工验证的不相关文本和图像的数据库,也无法通过网络爬取或其他无监督或半监督技术轻易构建这样的数据库。
- 即使表面上看起来完全不相关的图像-文本对也不一定真的无关。我们没有一个能够客观做出这种负面判断的语义理论。例如,一张猫躺在门廊上的图片与"一个人躺在沙发上"这段文本并不是完全不匹配的。两者都涉及躺在某物上。
理想情况下,我们希望用确定相关和确定不相关的图像-文本对来训练,但显然没有明显的方法来获取已知的不相关对。让人们回答"这句话是否描述了这张图片?"可以期待得到一致的答案。但如果问"这句话是否与这张图片完全无关?"就很难得到一致的答案。
相反,我们通过从训练数据中随机选择图片和文本来获得不相关的图像-文本对,期望它们在实践中几乎总是不匹配的。这在实践中是这样工作的:我们将训练数据分成批次。在训练 Jina CLIP 时,我们使用的批次包含 32,000 个匹配的图像-文本对,但在这个实验中,批次大小只有 16。
下表是从 Flickr8k 中随机抽样的 16 个图像-文本对:
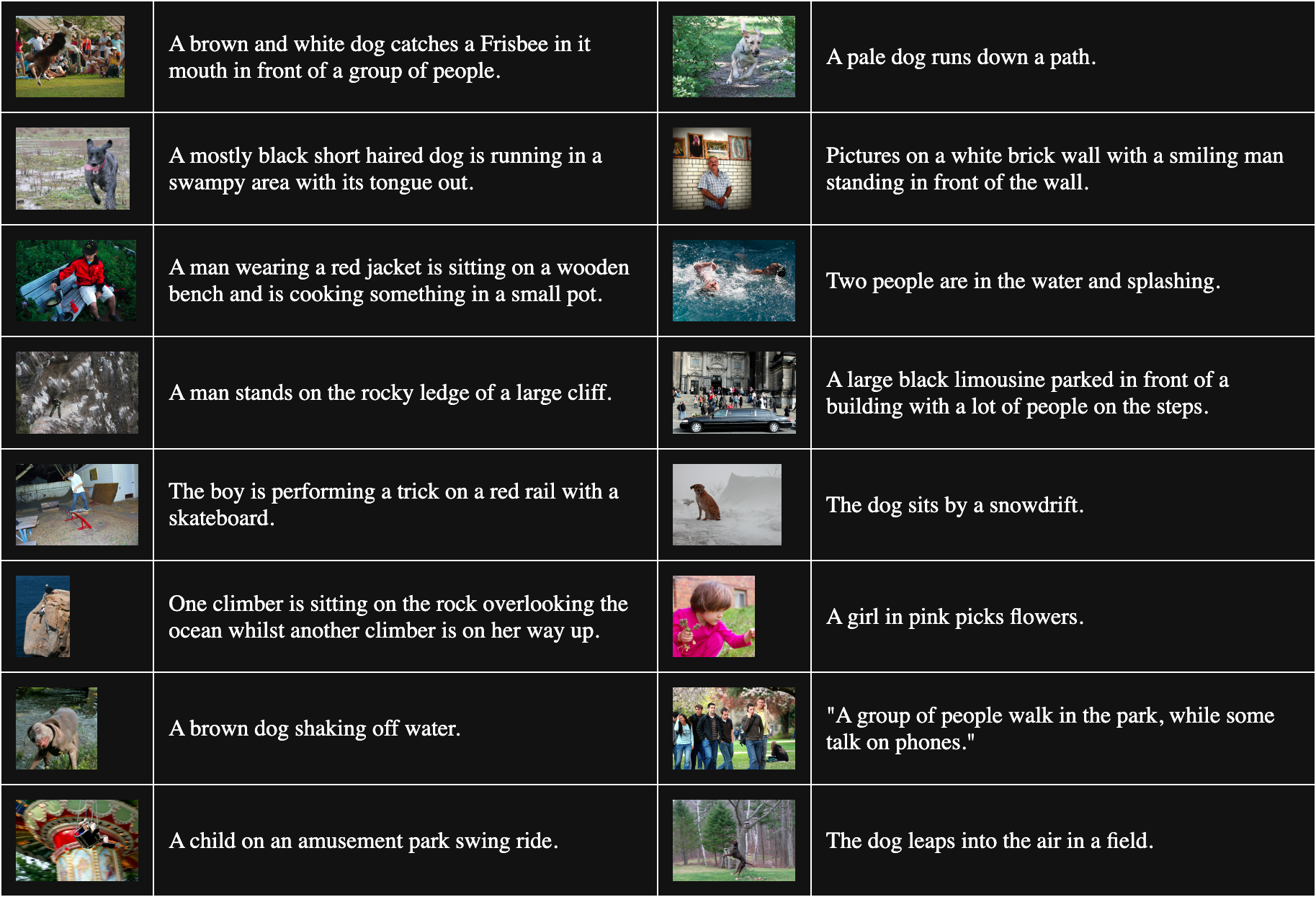
为了获得不匹配的对,我们将批次中的每张图片与除了它匹配的文本之外的所有文本组合。例如,以下是一个不匹配的图像和文本对:

说明:一个穿粉色衣服的女孩在采摘花朵。
但这个程序假设所有与其他图像匹配的文本都是同样糟糕的匹配。这并不总是正确的。例如:

说明:狗坐在雪堆旁边。
虽然这段文字并不完全描述这张图片,但它们都有一个共同点:狗。将这对作为不匹配处理会倾向于将"狗"这个词从任何狗的图像中推远。
Liang 等人 [2022] 表明,这些不完美的不匹配对会推开所有图像和文本。
我们用一个完全随机初始化的 vit-b-32 图像模型和一个同样随机化的 JinaBERT v2 文本模型来验证他们的说法,训练温度设置为恒定的 0.02(一个适中的低温)。我们构建了两组训练数据:
- 一组是从 Flickr8k 中随机抽取的批次,其中不匹配对按上述方法构建。
- 另一组是故意在每个批次中包含同一图像的多个副本,但配以不同的文本。这确保了大量"不匹配"对实际上是相互匹配的。
然后我们用这两组训练数据分别训练了两个模型各一个 epoch,并测量了每个模型在 Flickr8k 数据集中 1,000 个文本-图像对之间的平均余弦距离。用随机批次训练的模型的平均余弦距离为 0.7521,而用大量故意匹配的"不匹配"对训练的模型的平均余弦距离为 0.7840。不正确的"不匹配"对的影响相当显著。考虑到实际的模型训练时间更长,使用的数据更多,我们可以看到这种效应会如何增长并加大整体图像和文本之间的差距。
tag媒介即讯息
加拿大传播理论学家 Marshall McLuhan 在他 1964 年的著作 《理解媒介:人的延伸》中提出了"媒介即讯息"这一短语,强调讯息并非独立存在。它们存在于一个强烈影响其含义的语境中,他著名地宣称,这种语境中最重要的部分之一就是传播媒介的性质。
多模态差异为我们提供了一个独特的机会来研究 AI 模型中一类新兴的语义现象。没有人告诉 Jina CLIP 要对其训练数据的媒介进行编码——它却自行这样做了。即使我们尚未解决多模态模型的这个问题,至少我们对问题的来源有了很好的理论理解。
我们应该假设由于同样的偏差,我们的模型还在编码其他我们尚未发现的内容。例如,我们在多语言嵌入模型中可能存在同样的问题。对两种或更多语言进行联合训练可能会导致语言之间出现同样的差异,特别是因为类似的训练方法被广泛使用。解决这种差异问题可能会产生广泛的影响。
对更广泛模型中初始化偏差的研究可能也会带来新的见解。如果对于嵌入模型来说媒介就是信息,那么谁知道还有什么其他内容在不知不觉中被编码到我们的模型中呢?






