

周日傍晚,你终于点击"发布",将那篇倾注了一整个周末心血的文章发表。每一个词、每一个想法,都是你独一无二的创作。陆陆续续收到一些点赞,虽不是爆款,但这是属于你的作品。
三天后,在刷新闻时,你看到了它:你文章的灵魂换了一个壳!他们重新排列了文字,但你认得出这是你的创作。最糟糕的是,他们的版本却在到处传播,用你的创意偷来的成功在病毒式传播。这不是我们期待的创意经济。
显而易见的解决方案是在作品上署名。但说实话,这也是最容易被删除的。我们能做得更好吗?在本文中,我们将展示一种使用 embedding 模型的水印技术,它既可以签名又能检测原创内容。这不仅仅是另一个搜索/RAG 的老套路 —— 它利用 jina-embeddings-v3 的独特功能,如长文本处理和跨语言对齐,来创建一个强大的认证系统,并允许我们在 LLM 改写甚至翻译等转换过程中保持可靠的内容验证。
tag理解文本水印
数字水印多年来一直是内容保护的基石。当你看到一个带有半透明 logo 的表情包时,你看到的就是最基本的图像水印形式。现代水印技术已经远远超越了简单的视觉叠加 —— 许多水印对人眼来说是不可见的,但机器可以读取。
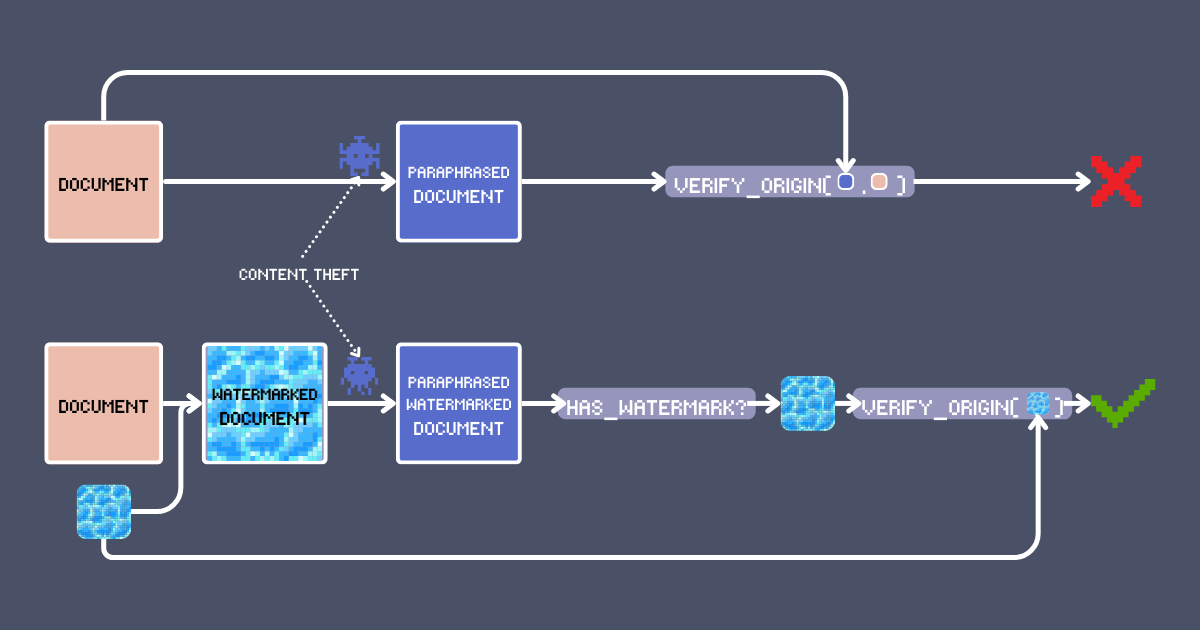
文本水印遵循类似的原则,但在语义空间中运作。与改变像素不同,文本水印以保持原始含义的方式微妙地修改内容,同时嵌入可检测的签名。因此,有效的文本水印的关键要求是:
- 语义保持:带水印的文本应保持其原始含义和可读性,就像视觉水印不应遮挡图像的关键元素一样。
- 不可感知性:水印对人类读者来说应该是无法察觉的,确保他们在内容转换过程中不能有意保留或删除它。
- 机器可检测:虽然水印对人类读者来说可能很微妙,但它应该创建清晰、可测量的模式,使算法能够可靠地识别。
- 变换不变性:任何内容转换(如改写或翻译),无论是有意还是不知道水印存在的,要么应保持水印,要么需要如此实质性的改变以至于从根本上改变原始内容的结构或含义。
tag使用 Embeddings 进行文本水印
让我们使用 embeddings 构建一个文本水印系统。首先,让我们定义该系统的关键组件:
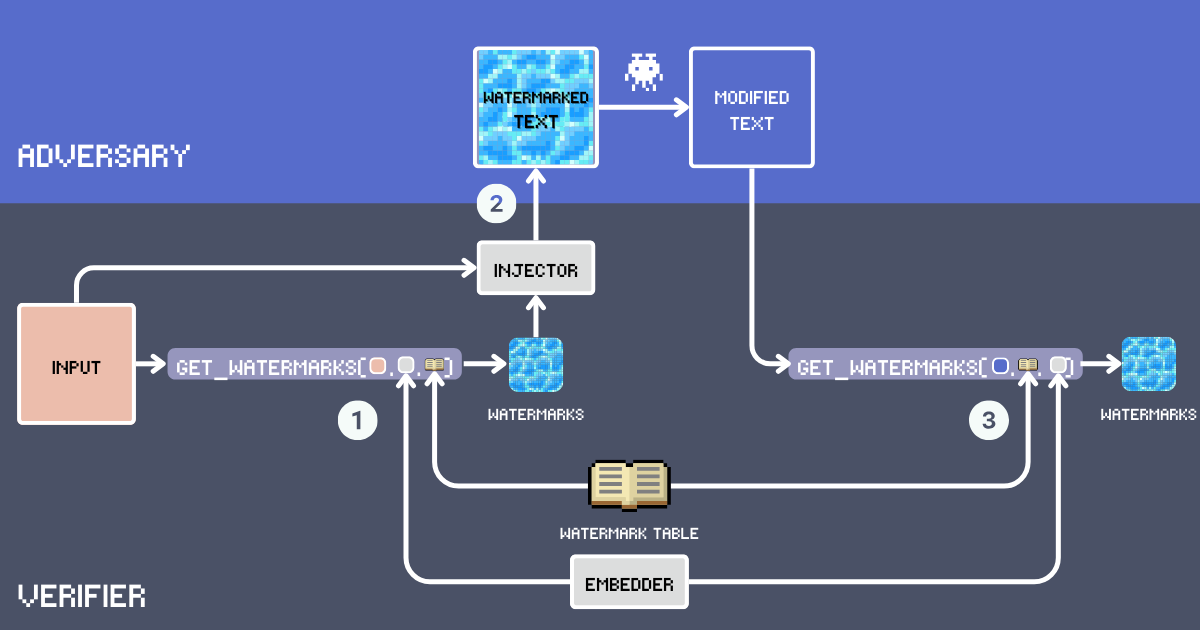
- 输入:需要添加水印的原始文本。
- 水印表:包含候选水印词的秘密词典。为了获得最佳水印效果,这些词应该足够常见以自然地适应各种上下文。词汇表排除了功能词、专有名词和可能显得不合适的罕见词,例如
delve into、embark是好的候选词,而good太过常见。下面,我们将使用高级英语词汇构建我们的 WatermarkTable。 - Embedder:一个 embedding 模型,服务于两个目的:根据
input文本从WatermarkTable中选择语义合适的词,并帮助检测可能被改写的文本中的水印。我们使用 jina-embeddings-v3,因为它能很好地处理超长文本和不同语言。这意味着我们可以为长文档添加水印,即使有人将文本翻译,我们仍然能抓到抄袭者。 - 水印:通过计算输入文本 embedding 和表中 embeddings 的余弦相似度来从水印表中选择的词。词的数量由插入比率决定,通常是输入词数的 12%。
- 注入器:一个遵循指令的 LLM,将水印词整合到输入文本中,同时保持连贯性、事实准确性、自然流畅性,以及水印词在文本中的均匀分布。
- 带水印文本:注入器将水印词插入
input后的输出。 - 攻击者(内容盗窃):试图在不注明出处的情况下重用带水印文本的实体,通常通过改写、翻译或小幅编辑。如今,这简单地意味着使用 LLM 并提示
Paraphrase [text]进行自动重写。 - 修改后的文本:攻击者对带水印文本进行修改后的结果。这就是我们需要检查水印的文本。
tag算法


tag结论
从这些示例中,我们可以看到即使是在这个基本设置下,我们基于 embedding 的水印也表现出相当强的鲁棒性。特别值得注意的是,即使在翻译后,水印仍然可以被检测到。这种跨语言的鲁棒性得益于 jina-embeddings-v3 模型强大的多语言能力;如果没有强大的多语言和跨语言能力,就无法实现这种在翻译过程中的持久性。
有几种方法可以提高这个水印系统的准确性和鲁棒性。首先,可以扩展水印表并仔细构建以确保多样性。这一点很重要,因为更大、更多样化的词汇表能够更好地覆盖语义空间,使得为任何给定文本找到合适的上下文水印变得更容易,同时也减少了重复或明显模式的风险。
可以通过实现更复杂的插入策略来改进 Injector 组件。例如,可以指示它在整个文本中均匀分布水印以保持不可感知性。此外,我们可以采用延迟分块技术为单独的段落或句子生成水印,使 Injector 能够对水印放置做出更细致的决策。这将有助于在最终文本中同时保持整体的不可感知性和语义连贯性。
对于有兴趣深入探索的读者,"POSTMARK: A Robust Blackbox Watermark for Large Language Models"(Chang 等人,EMNLP 2024)提供了一个全面的框架,包括数学公式和大量实验。作者系统地探讨了水印词汇表构建、最佳插入策略以及对各种攻击的鲁棒性。他们还通过自动化和人工评估,深入分析了水印检测和文本质量之间的权衡。





