

对长文档进行分块存在两个问题:首先是确定断点——即如何对文档进行分段。你可能会考虑固定的 token 长度、固定数量的句子,或更高级的技术,如正则表达式或语义分割模型。准确的块边界不仅可以提高搜索结果的可读性,还能确保输入到 LLM 的 RAG 系统中的块是精确和充分的——不多不少。
第二个问题是每个块内的上下文丢失。一旦文档被分段,大多数人的下一个逻辑步骤就是在批处理过程中分别嵌入每个块。然而,这会导致原始文档的全局上下文丢失。许多之前的工作首先解决第一个问题,认为更好的边界检测可以改善语义表示。例如,"语义分块"在嵌入空间中将具有高余弦相似度的句子分组,以最小化语义单元的中断。
从我们的观点来看,这两个问题几乎是正交的,可以分开处理。如果必须要优先处理,我们认为第二个问题更为关键。
| 问题 2:上下文信息 | |||
|---|---|---|---|
| 已保留 | 已丢失 | ||
| 问题 1:断点 | 好 | 理想场景 | 搜索结果差 |
| 差 | 搜索结果好,但结果可能不便于人类阅读或 LLM 推理 | 最坏情况 |
tagLate Chunking 解决上下文丢失
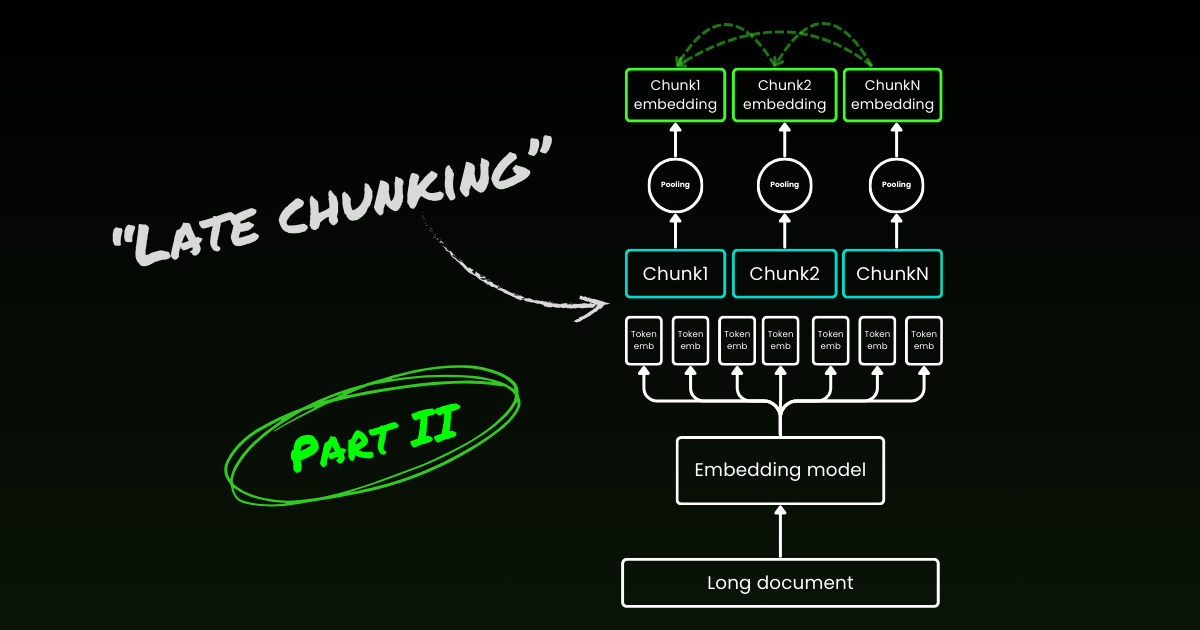
Late chunking 首先解决第二个问题:上下文丢失。它不是关于寻找理想的断点或语义边界。你仍然需要使用正则表达式、启发式方法或其他技术将长文档分割成小块。但是,late chunking 不是在分割后立即嵌入每个块,而是先在一个上下文窗口中编码整个文档(对于 jina-embeddings-v3 是 8192-token)。然后,它根据边界提示对每个块应用平均池化——这就是 late chunking 中"late"的由来。

tagLate Chunking 对糟糕的边界提示具有韧性
真正有趣的是,实验表明 late chunking 消除了对完美语义边界的需求,这部分解决了上述的第一个问题。事实上,应用于固定 token 边界的 late chunking 的表现优于具有语义边界提示的朴素分块。当与 late chunking 配对时,像使用固定长度边界这样的简单分割模型,其性能与高级边界检测算法相当。我们测试了三种不同大小的嵌入模型,结果表明它们在所有测试数据集上都持续受益于 late chunking。也就是说,嵌入模型本身仍然是性能最重要的因素——没有任何一个使用 late chunking 的较弱模型能够超越不使用它的较强模型。

jina-embeddings-v2-small)。作为消融研究的一部分,我们测试了使用不同边界提示(固定 token 长度、句子边界和语义边界)和不同模型(jina-embeddings-v2-small、nomic-v1和 jina-embeddings-v3)的 late chunking。根据它们在 MTEB 上的表现,这三个嵌入模型的排名是:jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3。但是,这个实验的重点不在于评估嵌入模型本身的性能,而是要理解一个更好的嵌入模型如何与迟分技术和边界提示进行互动。关于实验的详细信息,请查看我们的研究论文。| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
需要注意的是,对不良边界具有弹性并不意味着我们可以忽视它们——它们对人类和 LLM 的可读性仍然很重要。我们是这样看待的:在优化分段时(即上述第一个问题),我们可以完全专注于可读性,而不用担心语义/上下文的丢失。迟分技术可以处理好的或坏的断点,所以你只需要关注可读性。
tag迟分技术是双向的
关于迟分技术的另一个常见误解是,它的条件分块嵌入只依赖于前面的分块而不"向前看"。这是不正确的。**迟分技术中的条件依赖实际上是双向的**,而不是单向的。这是因为嵌入模型(一个仅编码器的 transformer)中的注意力矩阵是完全连接的,不像自回归模型中使用的掩码三角矩阵。形式上,分块 的嵌入 ,而不是 ,其中 表示语言模型的分解。这也解释了为什么迟分技术不依赖于精确的边界位置。

tag迟分技术可以被训练
迟分技术不需要对嵌入模型进行额外的训练。它可以应用于任何使用平均池化的长上下文嵌入模型,这使得它对实践者来说非常有吸引力。也就是说,如果你在处理问答或查询-文档检索等任务,通过一些微调仍然可以进一步提高性能。具体来说,训练数据包含以下元组:
- 一个**查询**(例如,问题或搜索词)。
- 一个包含相关信息以回答查询的**文档**。
- 文档内的一个**相关片段**,即直接回答查询的特定文本块。
模型通过将查询与其相关片段配对来训练,使用 InfoNCE 等对比损失函数。这确保相关片段在嵌入空间中与查询紧密对齐,而不相关的片段则被推得更远。因此,模型在生成分块嵌入时学会关注文档中最相关的部分。更多详细信息,请参阅我们的研究论文。
tag迟分技术 vs 上下文检索
在迟分技术推出后不久,Anthropic 引入了一个称为**上下文检索**的独立策略。Anthropic 的方法是一种解决上下文丢失问题的暴力方法,其工作原理如下:
- 每个分块都与完整文档一起发送给 LLM。
- LLM 为每个分块添加相关上下文。
- 这会产生更丰富、更有信息量的嵌入。
在我们看来,这本质上是**上下文丰富化**,其中使用 LLM 将全局上下文显式硬编码到每个分块中,这在**成本**、**时间**和**存储**方面都很昂贵。此外,目前尚不清楚这种方法是否对分块边界具有弹性,因为 LLM 依赖准确且可读的分块来有效丰富上下文。相比之下,如上所示,迟分技术对边界提示具有很强的弹性。由于嵌入大小保持不变,它不需要额外的存储。尽管利用了嵌入模型的完整上下文长度,它仍然比使用 LLM 生成丰富化要快得多。在我们研究论文的定性研究中,我们展示了 Anthropic 的上下文检索与迟分技术表现相似。然而,迟分技术通过利用仅编码器 transformer 的固有机制,提供了一个更底层、更通用和更自然的解决方案。
tag哪些嵌入模型支持迟分技术?
迟分技术并不是 jina-embeddings-v3 或 v2 独有的。它是一种相当通用的方法,可以应用于任何使用平均池化的长上下文嵌入模型。例如,在这篇文章中,我们展示了 nomic-v1 也支持它。我们热烈欢迎所有嵌入提供商在他们的解决方案中实现对迟分技术的支持。
作为模型用户,在评估新的嵌入模型或 API 时,你可以按照以下步骤检查它是否可能支持迟分技术:
- 单一输出:模型/API 是否仅为每个句子生成一个最终的 embedding 而不是词级别的 embeddings?如果是,那它可能就不支持后置分块(尤其是那些网络 API)。
- 长文本支持:模型/API 是否能处理至少 8192 个 tokens 的上下文?如果不能,后置分块就不适用——或者更准确地说,为短上下文模型采用后置分块是没有意义的。如果支持,请确保它在处理长文本时真的表现良好,而不仅仅是声称支持。你通常可以在模型的技术报告中找到这些信息,比如在 LongMTEB 或其他长文本基准测试上的评估结果。
- 平均池化:对于可自托管的模型或提供池化前词级 embeddings 的 API,检查默认的池化方法是否为平均池化。使用 CLS 或最大池化的模型与后置分块不兼容。
总的来说,如果一个 embedding 模型支持长文本且默认使用平均池化,它就可以轻松支持后置分块。查看我们的 GitHub 仓库了解实现细节和更多讨论。
tag结论
那么,什么是后置分块?后置分块是一种使用长文本 embedding 模型生成块级 embeddings 的直接方法。它速度快、对边界提示具有弹性且非常有效。它不是一种启发式方法或过度工程——而是基于对 transformer 机制深入理解的精心设计。
如今,围绕 LLMs 的炒作无可否认。在许多情况下,原本可以由 BERT 等较小模型高效解决的问题,却因为人们对更大、更复杂解决方案的追捧而交给了 LLMs。大型 LLM 提供商推动其模型的更广泛采用,而 embedding 提供商则推广 embeddings,这并不令人意外——他们都在发挥各自的商业优势。但最终,重要的不是炒作,而是行动,是什么真正有效。让社区、行业,最重要的是时间来揭示哪种方法才是真正精简、高效且经得起考验的。
请务必阅读我们的研究论文,我们也鼓励你在各种场景下对后置分块进行基准测试,并与我们分享你的反馈。
