




国际机器学习会议是机器学习和人工智能领域最负盛名的会议之一,今年于 7 月 21 日至 27 日在维也纳举行。

这次会议是为期 7 天的密集学习体验,包含口头报告和与其他研究人员直接交流想法的机会。在强化学习、生命科学 AI、表示学习、多模态模型以及 AI 模型开发核心要素等领域都有大量有趣的工作。特别重要的是关于大语言模型物理学的教程,该教程深入探讨了 LLM 的内部工作原理,并对 LLM 是记忆信息还是运用推理来生成内容这一问题给出了令人信服的答案。
tag我们在 Jina-CLIP-v1 上的工作
我们在"多模态基础模型与具身 AI"研讨会上以海报展示的形式介绍了我们新的多模态模型 jina-clip-v1 背后的工作。
与来自各个领域的国际同行会面并讨论我们的工作让人备受启发。我们的展示获得了许多积极的反馈,很多人对 Jina CLIP 统一多模态和单模态对比学习范式的方式很感兴趣。讨论内容涵盖了从 CLIP 架构的局限性到对其他模态的扩展,以及在肽和蛋白质匹配中的应用等方面。
Michael Günther 展示 Jina CLIP
tag我们的最爱
我们有机会讨论了许多其他研究人员的项目和演示,以下是我们最喜欢的几个:
tag图式规划(PLaG)
许多人都知道"少样本提示"或"思维链提示"。Fangru Lin 在 ICML 上展示了一个更好的新方法:图式规划(PLaG)。
她的想法很简单:给 LLM 的任务被分解成可以并行或顺序解决的子任务。这些子任务形成一个执行图。执行整个图就能解决高层次的任务。
在上面的视频中,Fangru Lin 通过一个易于理解的示例解释了这个方法。请注意,虽然这改进了结果,但当任务复杂度增加时,LLM 仍然会出现严重的性能下降。尽管如此,这仍是朝着正确方向迈出的重要一步,并能带来直接的实践收益。
对我们来说,有趣的是看到她的工作与我们在 Jina AI 的 prompt 应用如此相似。我们已经实现了类似图的 prompt 结构,不过,像她那样动态生成执行图是一个我们将要探索的新方向。
tag使用 XRM 发现环境
这篇论文提出了一个简单的算法,用于发现那些可能导致模型依赖于与标签相关但不能产生准确分类/相关性的特征的训练环境。一个著名的例子是水鸟数据集(参见 arXiv:1911.08731),其中包含了在不同背景下的鸟类照片,这些鸟需要被分类为水鸟或陆鸟。在训练过程中,分类器检测图像中的背景是否显示水域,而不是依赖鸟类本身的特征。这样的模型在背景中没有水的情况下会错误分类水鸟。
为了缓解这种情况,需要检测模型依赖误导性背景特征的样本。这篇论文提出的 XRM 算法就是用来做这件事的。
该算法在训练数据集的两个不同部分训练两个模型。在训练过程中,某些样本的标签会被翻转。具体来说,如果另一个模型(未在相应样本上训练)对样本的分类不同,就会发生这种情况。通过这种方式,鼓励模型依赖虚假相关性。之后,你可以从训练数据中提取那些一个模型预测的标签与真实标签不同的样本。随后,可以使用这些信息来训练更稳健的分类模型,例如使用 Group DRO 算法。
tag将你的 LLM 评估成本降低 140 倍!
没错,你没听错。只用这一个技巧,LLM 评估的成本就可以降低到原来的很小一部分。
核心思想很简单:移除所有测试相同模型能力的评估样本。背后的数学原理不那么直观,但被在海报环节展示工作的 Felipe Maia Polo 解释得很清楚。注意,降低 140 倍的数据适用于流行的 MMLU 数据集(Massive Multitask Language Understanding)。对于你自己的评估数据集,这取决于样本的评估结果之间的相关程度。也许你可以跳过很多样本,或者只能跳过几个。
不妨试一试。我们会持续关注 Jina AI 能够减少多少评估样本。
tag使用多边际匹配间隙对比多重表征
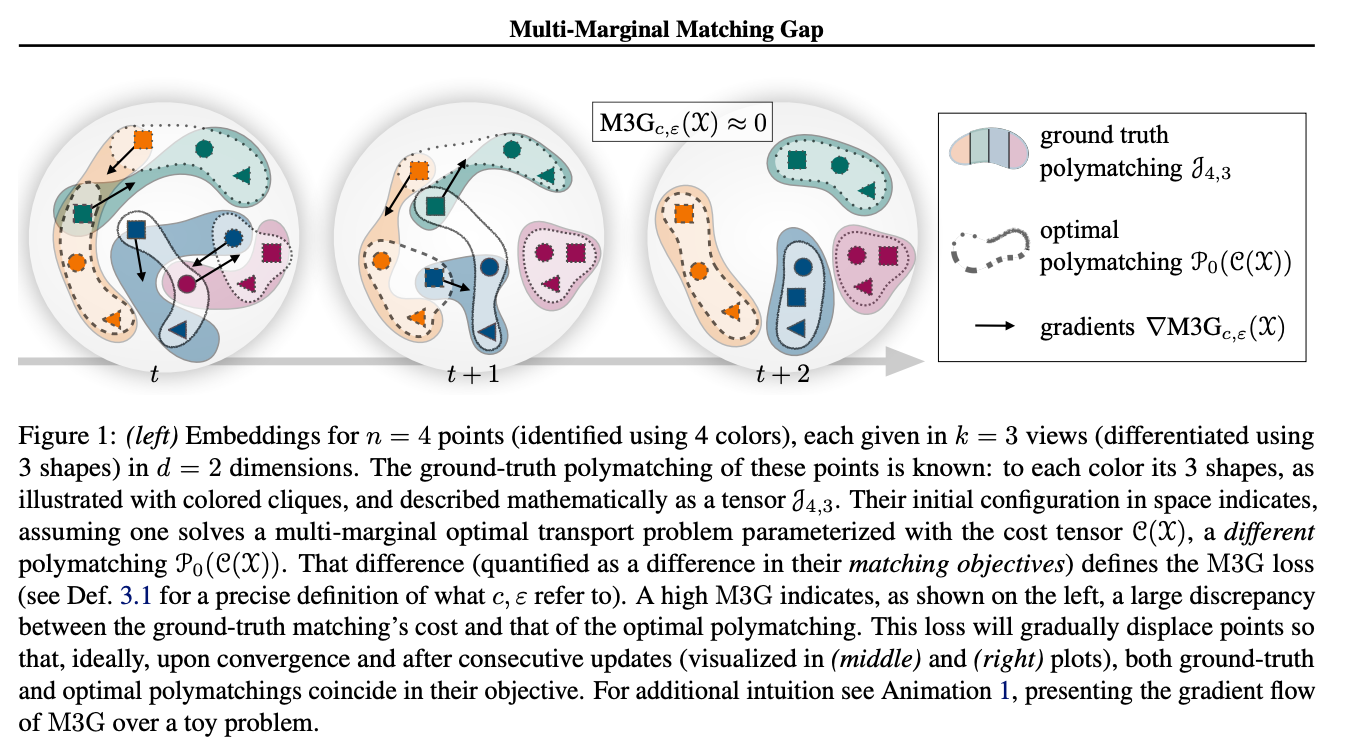
这项工作解决了对比学习中的一个常见挑战:大多数对比损失函数(如 InfoNCE 损失)都是在数据点对之间运作,并测量正样本对之间的距离。为了扩展到大小为 k > 2 的正样本元组,对比学习通常试图将问题简化为多个配对,并累积所有正样本对的成对损失。作者在这里提出了 M3G(多边际匹配间隙)损失,这是 Sinkhorn 算法的一个修改版本,用于解决多边际最优传输问题。这个损失函数可以用于数据集包含大小为 k > 2 的正样本元组的场景,例如,同一对象的 >2 个图像、具有三个或更多模态的多模态问题,或带有三个或更多同一图像增强的 SimCLR 扩展。实验结果表明,这种方法优于将问题简单地归约为配对的方法。
tag不再需要真实标签!
来自 斯坦福大学 的 Zachary Robertson 展示了他关于无需标注数据评估 LLM 的工作。请注意,虽然这是理论性工作,但它对高级 AI 系统的可扩展监督具有巨大潜力。这并不适合普通的 LLM 用户,但如果你从事 LLM 评估工作,这绝对值得关注。我们已经看到可以用这种方式评估 Jina AI 的智能体。一旦我们运行首批实验,我们会分享结果。
tag模型崩塌是否不可避免?通过积累真实和合成数据打破递归诅咒
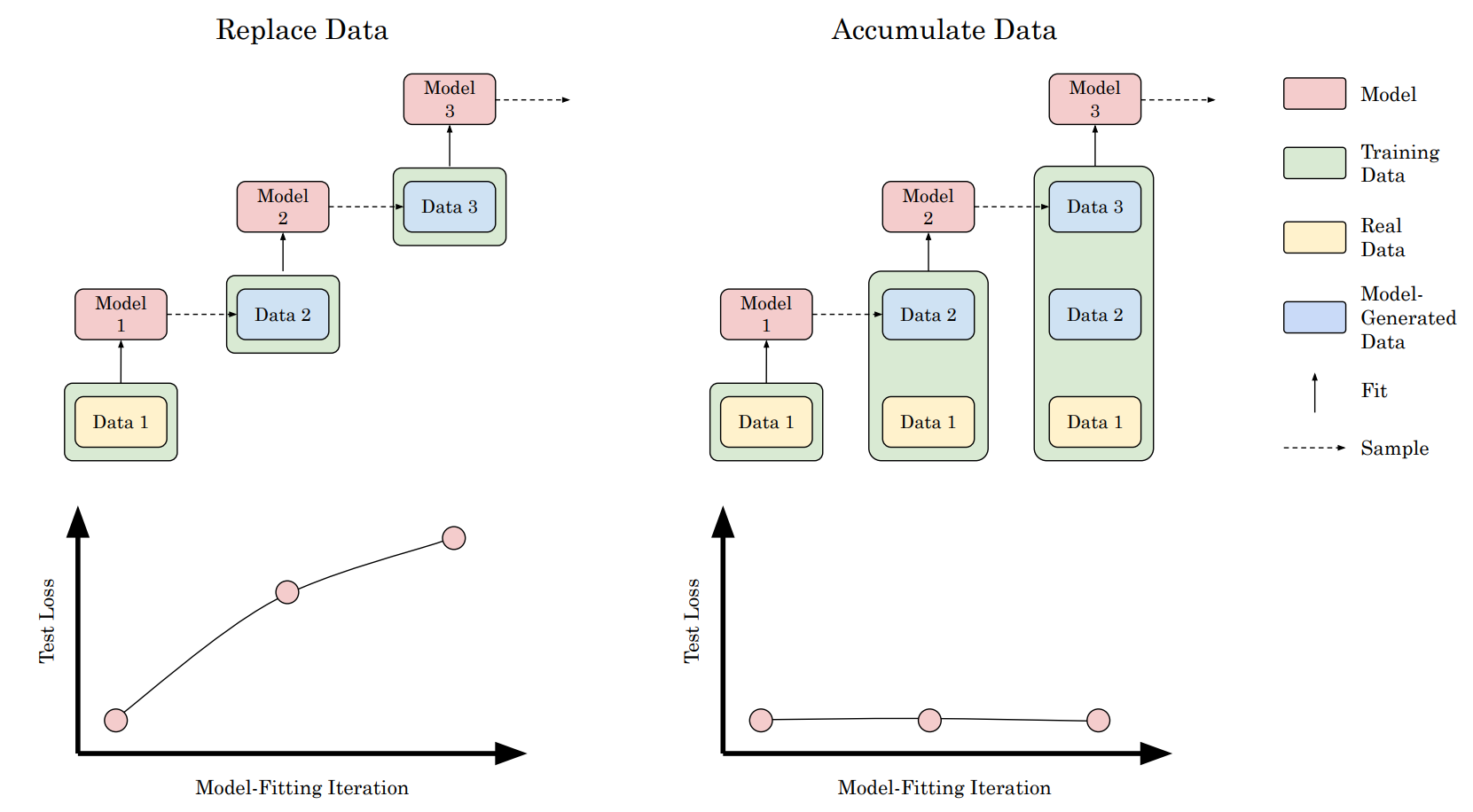
最近多篇文章(如这篇Nature文章)预测,由于训练数据是从网络爬取的并且包含越来越多的合成数据,新训练的模型性能可能会随时间变差。
我们的同事 Scott Martens 也发表了一篇关于模型崩溃的文章,并讨论了合成数据在模型训练中可能有用的情况。

模型训练可能会崩溃,因为训练数据是由模型的早期版本或在相同数据上训练的模型产生的。这篇论文的实验展示了一个略微不同的情况:崩溃只在用合成数据替换真实数据时发生,这是之前实验中所做的。然而,当用额外的合成数据增强真实数据时,并未观察到结果模型性能的变化。这些结果表明类似模型崩溃的情况不会发生。不过,这再次证明,使用额外的合成数据并不能帮助训练出一个普遍优于用于创建这些合成数据点的模型。
tagAI 的脑部手术现在成为可能
假设你想预测某人的职业但不想预测其性别。这项来自 Google Research、ETH Zürich、International Institute of Information Technology Hyderabad (IIITH) 和 Bar-Ilan University 的研究展示了如何使用引导向量和协方差匹配来控制偏差。
tagMagicLens - 基于开放式指令的自监督图像检索

这篇论文介绍了 MagicLens 模型,这是一系列在查询图像 + 指令 + 目标图像三元组上训练的自监督图像检索模型。
作者介绍了一个数据收集/整理流程,该流程从网络收集图像对,并使用 LLM 合成开放式文本指令,这些指令将图像与超越单纯视觉相似性的多样化语义关系联系起来。这个流程用于生成 3670 万个高质量的广泛分布的三元组。然后使用这个数据集来训练一个具有共享参数的简单双编码器架构。视觉和语言编码器的主干网络使用 CoCa 或 CLIP base 和 large 变体进行初始化。引入了单个多头注意力池化器,将两个多模态输入压缩成单个嵌入。MagicLens 的训练目标是使用简单的 InfoNCE 损失,将查询图像和指令对与目标图像和空字符串指令进行对比。作者展示了基于指令的图像检索的评估结果。
tagPrompt Sketching - 提示的新方式
我们给 LLM 提示的方式正在改变。Prompt Sketching 让我们能够给生成模型提供固定约束。不是仅仅提供一个指令并希望模型按你想要的方式执行,而是定义一个完整的模板,强制模型生成你想要的内容。
不要将此与微调后提供结构化 JSON 格式的 LLM 混淆。使用微调方法,模型仍然可以自由生成任何内容。但 Prompt Sketching 不是这样。它为提示工程师提供了一个全新的工具箱,并开辟了需要探索的研究领域。在上面的视频中,Mark Müller 详细解释了这个新范式。
你也可以查看他们的开源项目 LMQL。
tagRepoformer - 用于仓库级代码补全的选择性检索
对于许多查询来说,RAG 并不能真正帮助模型,因为查询要么太简单,要么检索系统找不到相关文档,可能是因为根本没有相关文档。如果模型依赖误导性或缺失的来源,这会导致更长的生成时间和更低的性能。
这篇论文通过使 LLM 能够自我评估检索是否有用来解决这个问题。他们在一个训练用于填充代码模板空白的代码补全模型上展示了这种方法。对于给定的模板,系统首先决定检索结果是否有用,如果有用,则调用检索器。最后,无论是否向提示中添加检索结果,代码 LLM 都会生成缺失的上下文。
tag柏拉图表征假说

柏拉图表征假说认为神经网络模型会倾向于收敛到对世界的共同表征。借鉴柏拉图的形式理论中存在"理想"领域的观点(这种理想以扭曲的形式出现在我们面前,我们只能间接观察),作者声称我们的 AI 模型似乎会收敛到对现实的单一表征,无论训练架构、训练数据甚至输入模态如何。数据规模和模型规模越大,它们的表征似乎越相似。
作者考虑向量表示,并使用核对齐度量来衡量表示对齐程度,特别是使用互近邻度量,该度量计算由两个核 K1 和 K2 所产生的 k 近邻集合的平均交集,并通过 k 进行归一化。这项研究提供了实证证据,表明随着模型和数据集规模的增长以及性能的提升,核之间的对齐程度越来越高。这种对齐甚至可以在比较不同模态的模型时观察到,比如文本模型和图像模型。
tag总结
虽然最初对扩展定律的热情开始减退,但 ICML 2024 展示了大量新的、多样化的、富有创造力的人才已经进入我们的领域,这让我们确信进展远未结束。
我们在 ICML 2024 玩得很开心,你可以打赌我们 2025 年一定会再来 🇨🇦。





