
读取器
将 URL 转换为大模型友好输入,只需在前面添加
r.jina.ai 即可。读取器 API
将 URL 转换为大模型友好输入,只需在前面添加
r.jina.ai 即可。chevron_leftchevron_right
globe_book
使用
r.jina.ai 读取 URL 并获取其内容travel_explore
使用
s.jina.ai 搜索网络并获取 SERPupload
请求
GET
curl "https://r.jina.ai/https://example.com"
ReaderLM v2:从 HTML 到 Markdown 和 JSON 的小型语言模型
ReaderLM-v2 是一个 1.5B 参数语言模型,专门用于 HTML 到 Markdown 的转换和 HTML 到 JSON 的提取。它支持 29 种语言中多达 512K 个词元的文档,准确率比其前身高 20%。


将网络信息输入大模型是打好基础的重要一步,但这可能很有挑战性。最简单的方法是抓取网页并输入原始 HTML。但是,抓取可能很复杂且经常受阻,而且原始 HTML 中充斥着标记和脚本等无关元素。读取器 API 通过从 URL 中提取核心内容并将其转换为干净的、大模型友好的文本来解决这些问题,从而确保为您的Agent和 RAG 系统提供高质量的输入。
原始 HTML
读取器的输出

Reader 可用作 SERP API。它允许您将搜索结果引擎页面背后的内容提供给您的 LLM。只需在您的查询前面添加
https://s.jina.ai/?q=,Reader 就会搜索网络并返回前五个结果及其 URL 和内容,每个结果都以干净、LLM 友好的文本显示。这样,您就可以始终让您的 LLM 保持最新状态,提高其真实性,并减少幻觉。info 请注意,与上面的演示不同,在实践中,您不会在网上搜索原始问题来获取基础。人们经常做的是重写原始问题或使用多跳问题。他们读取检索到的结果,然后生成其他查询以根据需要收集更多信息,然后得出最终答案。

网页上的图片会使用读取器中的视觉语言模型自动添加标题,并在输出中格式化为图片 alt 标签。这为您的下游大模型提供了足够的提示,以将这些图片纳入其推理和总结过程。这意味着您可以询问有关图片的问题,选择特定的图片,甚至将其 URL 转发到更强大的 VLM 进行更深入的分析!
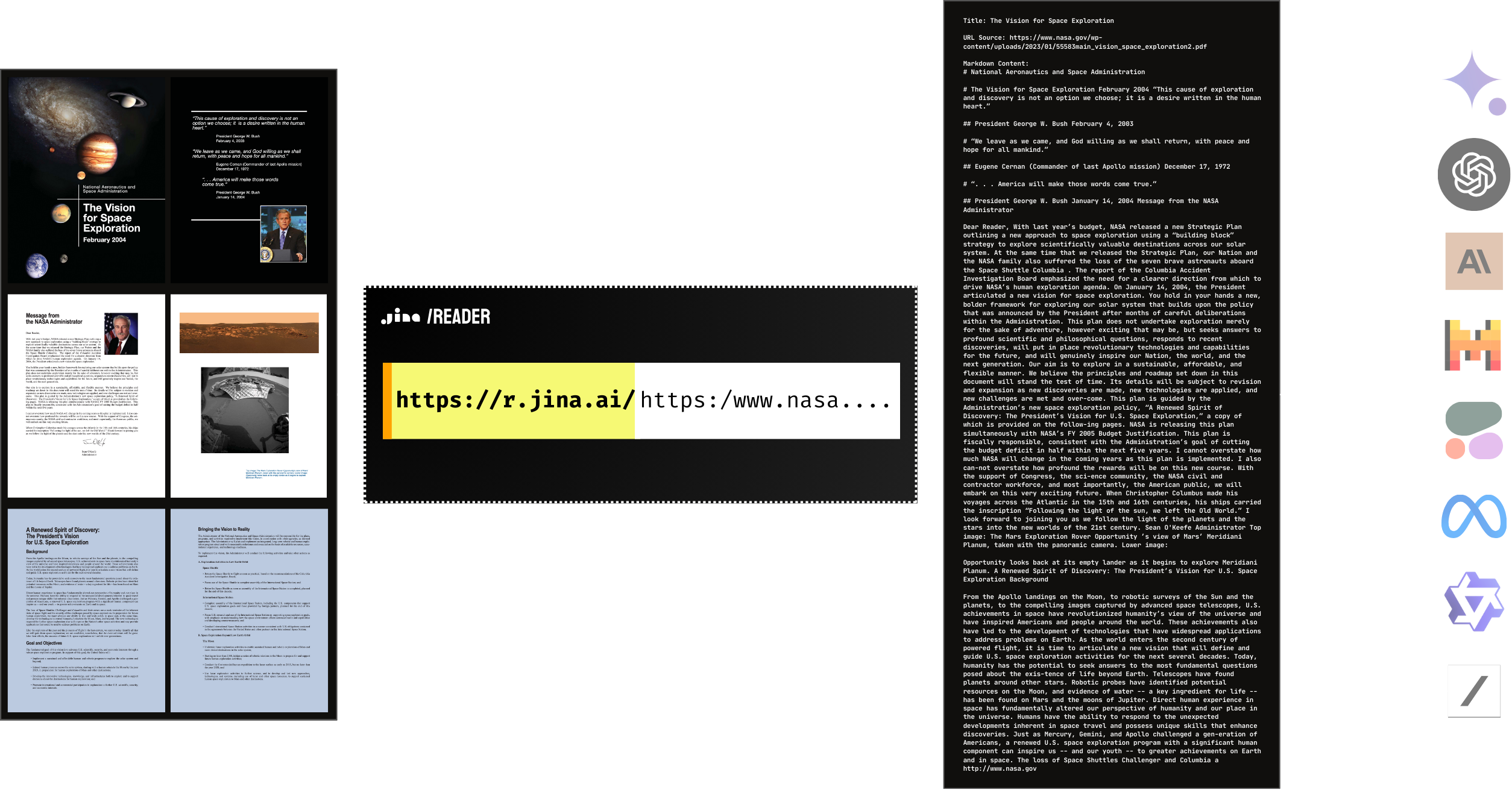
是的,Reader 本身支持 PDF 读取。它兼容大多数 PDF,包括包含大量图片的 PDF,而且速度极快!结合大模型,您可以轻松快速地构建 ChatPDF 或文档分析 AI。
而且它是竟然是免费的!
Reader API 可免费使用,并提供灵活的速率限制和定价。它建立在可扩展的基础架构上,具有高可访问性、并发性和可靠性。我们努力成为您大模型的首选基础解决方案。
速率限制
速率限制通过三种方式跟踪:RPM(每分钟请求数)和TPM(每分钟词元数)。限制按 IP/API 密钥强制执行,当首先达到 RPM 或 TPM 阈值时,将触发限制。当您在请求标头中提供 API 密钥时,我们会按密钥而不是 IP 地址跟踪速率限制。
| 产品 | API端口 | 描述arrow_upward | 无 API 密钥key_off | 使用 API 密钥key | 带有高级 API 密钥key | 平均延迟 | 词元使用计数 | 请求类型 | |
|---|---|---|---|---|---|---|---|---|---|
| 读取器 API | https://r.jina.ai | 将 URL 转换为大模型友好文本 | 20 RPM | 500 RPM | trending_up5000 RPM | 7.9s | 以输出响应中的词元数量为准。 | GET/POST | |
| 读取器 API | https://s.jina.ai | 搜索网络并将结果转换为大模型友好文本 | block | 100 RPM | trending_up1000 RPM | 2.5s | 每个请求都需要固定数量的词元,从 10000 个词元开始 | GET/POST | |
| 深度搜索 | https://deepsearch.jina.ai/v1/chat/completions | 推理、搜索和迭代以找到最佳答案 | block | 50 RPM | 500 RPM | 56.7s | 统计整个过程中词元的总数。 | POST | |
| 向量模型API | https://api.jina.ai/v1/embeddings | 将文本/图片转为定长向量 | block | 500 RPM & 1,000,000 TPM | trending_up2,000 RPM & 5,000,000 TPM | ssid_chart 取决于输入大小 help | 以输入请求中的词元数量为准。 | POST | |
| 重排器 API | https://api.jina.ai/v1/rerank | 按查询对文档进行精排 | block | 500 RPM & 1,000,000 TPM | trending_up2,000 RPM & 5,000,000 TPM | ssid_chart 取决于输入大小 help | 以输入请求中的词元数量为准。 | POST | |
| 分类器 API | https://api.jina.ai/v1/train | 使用训练样本训练分类器 | block | 20 RPM & 200,000 TPM | 60 RPM & 1,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 × 迭代次数 | POST | |
| 分类器 API (少量样本) | https://api.jina.ai/v1/classify | 使用经过训练的少样本分类器对输入进行分类 | block | 20 RPM & 200,000 TPM | 60 RPM & 1,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 | POST | |
| 分类器 API (零样本) | https://api.jina.ai/v1/classify | 使用零样本分类对输入进行分类 | block | 200 RPM & 500,000 TPM | 1,000 RPM & 3,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 加 标签词元 | POST | |
| 切分器 API | https://api.jina.ai/v1/segment | 对长文本进行分词分句 | 20 RPM | 200 RPM | 1,000 RPM | 0.3s | 词元不计算使用量。 | GET/POST |





别慌!每个新的 API 密钥都包含一千万个免费词元!
API价格表
API 定价基于词元使用情况。一个 API 密钥即可访问所有搜索基础产品。

使用Jina 搜索底座API
访问我们所有产品的最简单方法。随时充值词元。
使用更多词元充值此 API 密钥
请输入正确的API密钥进行充值
了解速率限制
速率限制是指每个 IP 地址/API 密钥 (RPM) 在一分钟内可以向 API 发出的最大请求数。请在下面详细了解每个产品和层级的速率限制。
keyboard_arrow_down

使用 读取器 API 的相关费用是多少?
keyboard_arrow_down
读取器 API 如何发挥作用?
keyboard_arrow_down
读取器 API 是开源的吗?
keyboard_arrow_down
读取器 API 的典型延迟是多少?
keyboard_arrow_down
为什么我应该使用 读取器 API 而不是自己抓取页面?
keyboard_arrow_down
读取器 API 是否支持多种语言?
keyboard_arrow_down
如果某个网站屏蔽了 读取器 API,我该怎么办?
keyboard_arrow_down
读取器 API 可以从 PDF 文件中提取内容吗?
keyboard_arrow_down
读取器 API 可以处理来自网页的媒体内容吗?
keyboard_arrow_down
是否可以在本地 HTML 文件上使用 读取器 API?
keyboard_arrow_down
读取器 API 是否缓存内容?
keyboard_arrow_down
我可以使用 读取器API 来访问登录后的内容吗?
keyboard_arrow_down
我可以使用读取器 API 访问 arXiv 上的 PDF 吗?
keyboard_arrow_down
图片标注在读取器中如何发挥作用?
keyboard_arrow_down
读取器的可扩展性如何?我可以在生产中使用它吗?
keyboard_arrow_down
Reader API 的速率限制是多少?
keyboard_arrow_down
什么是 Reader-LM?如何使用它?
keyboard_arrow_down
速率限制
速率限制通过三种方式跟踪:RPM(每分钟请求数)和TPM(每分钟词元数)。限制按 IP/API 密钥强制执行,当首先达到 RPM 或 TPM 阈值时,将触发限制。当您在请求标头中提供 API 密钥时,我们会按密钥而不是 IP 地址跟踪速率限制。
| 产品 | API端口 | 描述arrow_upward | 无 API 密钥key_off | 使用 API 密钥key | 带有高级 API 密钥key | 平均延迟 | 词元使用计数 | 请求类型 | |
|---|---|---|---|---|---|---|---|---|---|
| 读取器 API | https://r.jina.ai | 将 URL 转换为大模型友好文本 | 20 RPM | 500 RPM | trending_up5000 RPM | 7.9s | 以输出响应中的词元数量为准。 | GET/POST | |
| 读取器 API | https://s.jina.ai | 搜索网络并将结果转换为大模型友好文本 | block | 100 RPM | trending_up1000 RPM | 2.5s | 每个请求都需要固定数量的词元,从 10000 个词元开始 | GET/POST | |
| 深度搜索 | https://deepsearch.jina.ai/v1/chat/completions | 推理、搜索和迭代以找到最佳答案 | block | 50 RPM | 500 RPM | 56.7s | 统计整个过程中词元的总数。 | POST | |
| 向量模型API | https://api.jina.ai/v1/embeddings | 将文本/图片转为定长向量 | block | 500 RPM & 1,000,000 TPM | trending_up2,000 RPM & 5,000,000 TPM | ssid_chart 取决于输入大小 help | 以输入请求中的词元数量为准。 | POST | |
| 重排器 API | https://api.jina.ai/v1/rerank | 按查询对文档进行精排 | block | 500 RPM & 1,000,000 TPM | trending_up2,000 RPM & 5,000,000 TPM | ssid_chart 取决于输入大小 help | 以输入请求中的词元数量为准。 | POST | |
| 分类器 API | https://api.jina.ai/v1/train | 使用训练样本训练分类器 | block | 20 RPM & 200,000 TPM | 60 RPM & 1,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 × 迭代次数 | POST | |
| 分类器 API (少量样本) | https://api.jina.ai/v1/classify | 使用经过训练的少样本分类器对输入进行分类 | block | 20 RPM & 200,000 TPM | 60 RPM & 1,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 | POST | |
| 分类器 API (零样本) | https://api.jina.ai/v1/classify | 使用零样本分类对输入进行分类 | block | 200 RPM & 500,000 TPM | 1,000 RPM & 3,000,000 TPM | ssid_chart 取决于输入大小 | 词元计数为:输入词元 加 标签词元 | POST | |
| 切分器 API | https://api.jina.ai/v1/segment | 对长文本进行分词分句 | 20 RPM | 200 RPM | 1,000 RPM | 0.3s | 词元不计算使用量。 | GET/POST |
API相关常见问题
code
我可以对读取器、向量模型、重排器、分类器和微调模型 API 使用相同的 API 密钥吗?
keyboard_arrow_down
code
我可以查看 API 密钥的词元使用情况吗?
keyboard_arrow_down
code
如果我忘记了 API 密钥,该怎么办?
keyboard_arrow_down
code
API 密钥会过期吗?
keyboard_arrow_down
code
我可以在 API 密钥之间转移词元余额吗?
keyboard_arrow_down
code
我可以销毁我的 API 密钥吗?
keyboard_arrow_down
code
为什么有些机型第一次请求比较慢?
keyboard_arrow_down
code
用户输入数据是否用于训练您的模型?
keyboard_arrow_down
与计费相关的常见问题
attach_money
API是根据句子的数量或请求的数量计费吗?
keyboard_arrow_down
attach_money
新用户可以免费试用吗?
keyboard_arrow_down
attach_money
失败的请求是否会扣除词元?
keyboard_arrow_down
attach_money
接受哪些付款方式?
keyboard_arrow_down
attach_money
词元购买后可以开具发票吗?
keyboard_arrow_down
