


繼先前推出傑出的 Embeddings V2 後,我們很高興宣布推出最新的中英雙語文本嵌入模型:jina-embeddings-v2-base-zh。這個新模型繼承了 Jina Embeddings V2 的 8K 字符長度的特點,同時強力支援中文和英文。
jina-embeddings-v2-base-zh 憑藉其卓越的品質和性能脫穎而出,這是通過高品質雙語數據的嚴謹且均衡的預訓練達成的。這種方法有效減少了常見於不平衡多語言數據訓練模型中的偏差。
tag亮點特色
- 雙語模型:此模型可以同時編碼中文和英文文本,允許使用任一語言作為查詢或目標文件。兩種語言中具有相同意義的文本會被映射到相同的嵌入空間,為眾多多語言應用奠定基礎。
- 延伸至 8K 字符長度:我們的模型能夠處理大量文本段落,這項功能超越了大多數其他開源模型的能力。
- 小巧且高效:模型大小為 322MB(1.61 億參數)且輸出維度為 768,我們的模型設計可在無 GPU 的標準電腦硬體上實現高性能,提高了其可用性。
tag在 C-MTEB 上的領先表現
在 Chinese MTEB 排行榜上,我們支援中英雙語的 Jina Embeddings v2 在小於 0.5GB 的模型中脫穎而出。其獨特之處在於擁有 8K 字符長度的能力,這在同類別中是獨一無二的特色。
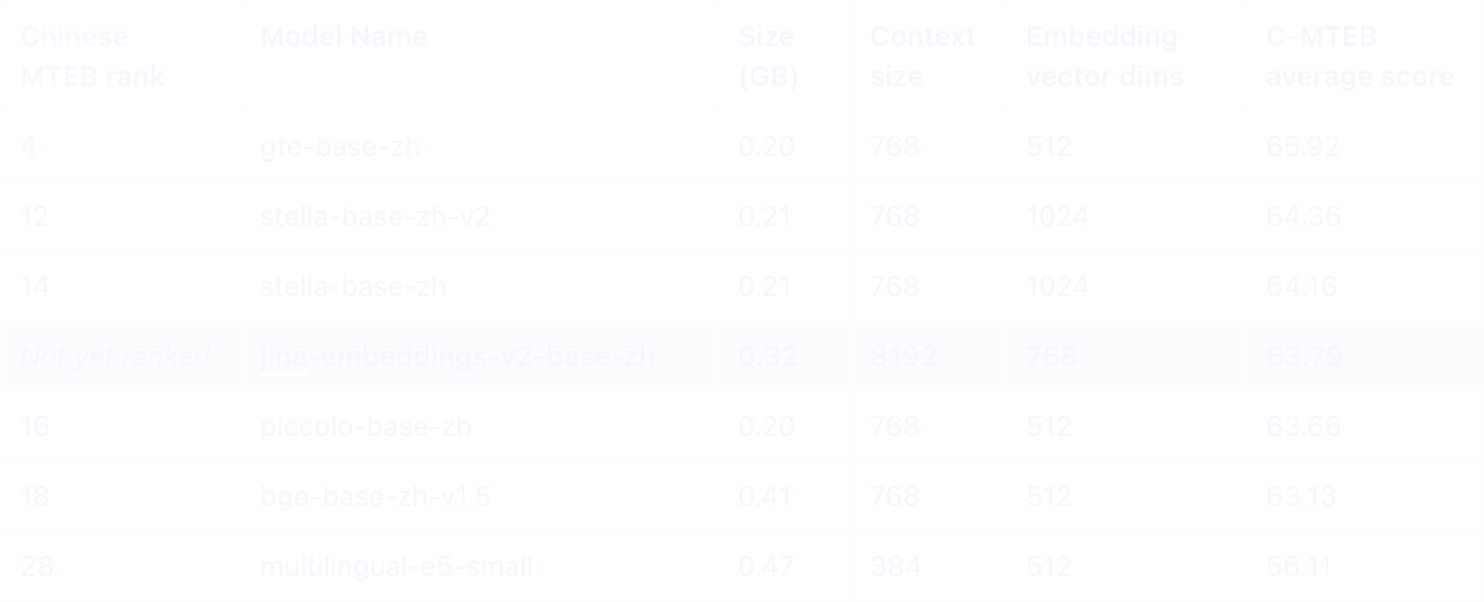
在相近大小的中文模型中,只有 E5 Multilingual 模型和我們的 jina-embeddings-v2-base-zh 提供英文支援,能夠實現有效的跨語言應用。值得注意的是,Jina 在所有涉及中文的類別中都展現出明顯優越的性能。

雖然兩個模型都具有 8K 字符的上下文大小,但 jina-embeddings-v2-base-zh 在性能上明顯優於 OpenAI 的 text-embedding-ada-002,尤其是在涉及中文的任務中。

tag助力中國企業全球擴展
我們的中英嵌入模型是中國企業「出海」的強力工具。它能無縫處理中文文本,提供高品質的嵌入,輕鬆整合到領先的向量數據庫、搜索系統、RAG 應用中。
jina-embeddings-v2-base-zh 特別適合開發針對中英語境的 AI 應用,對於企業的國際擴展至關重要。以下是一些具體使用案例:
- 文檔分析與管理:能夠分析和管理大量文檔,協助國際法律和商務交易。
- AI 驅動的搜尋應用:在多語言環境中提升搜尋功能,讓全球用戶更容易找到中英文的相關資訊。
- 檢索增強型聊天機器人和問答系統:建立高效的雙語客服機器人,改善與全球客戶的互動。
- 自然語言處理應用:包括理解全球市場趨勢的情感分析、國際行銷策略的主題建模,以及管理全球溝通的文本分類。
- 推薦系統:利用中英文數據的見解,為多元化的全球受眾量身定制產品和內容推薦。
透過運用這個模型,中國企業可以有效突破 AI 應用中的語言障礙,提升其全球競爭力和市場觸及率。
tag透過 API 開始使用 jina-embeddings-v2-base-zh
立即通過 Embeddings API 將我們的模型整合到您的工作流程中。只需訪問我們的 Embeddings 入口網站,獲取免費訪問金鑰或充值現有金鑰,然後從下拉選單中選擇 jina-embeddings-v2-base-zh。就是這麼簡單!

tag未來展望:擴展語言支援和 AWS Sagemaker 整合
jina-embeddings-v2-base-zh 即將在 AWS Sagemaker 和 Hugging Face 上提供。



在 Jina AI,我們致力於成為全球使用者可負擔且易於使用的嵌入技術領導者。我們正在積極開發更多多語言產品,專注於主要歐洲和其他國際語言,以擴大我們的覆蓋範圍。敬請期待這些令人興奮的更新,包括與 AWS SageMaker 的整合,我們將持續擴展我們的能力。
tag特別感謝我們的早期測試者
我們非常感謝中國用戶社群中測試預覽版本(jina-embeddings-v2-base-zh-preview)的特選成員。他們的寶貴意見對於提升此次正式版本的性能至關重要。如果您對我們的模型品質有任何觀察或建議,我們誠摯邀請您加入我們的 Discord 伺服器並與我們分享您的想法。您的意見對我們持續改進的過程非常重要。


與 jina-embeddings-v2-base-zh-preview 相比改進的分數分布
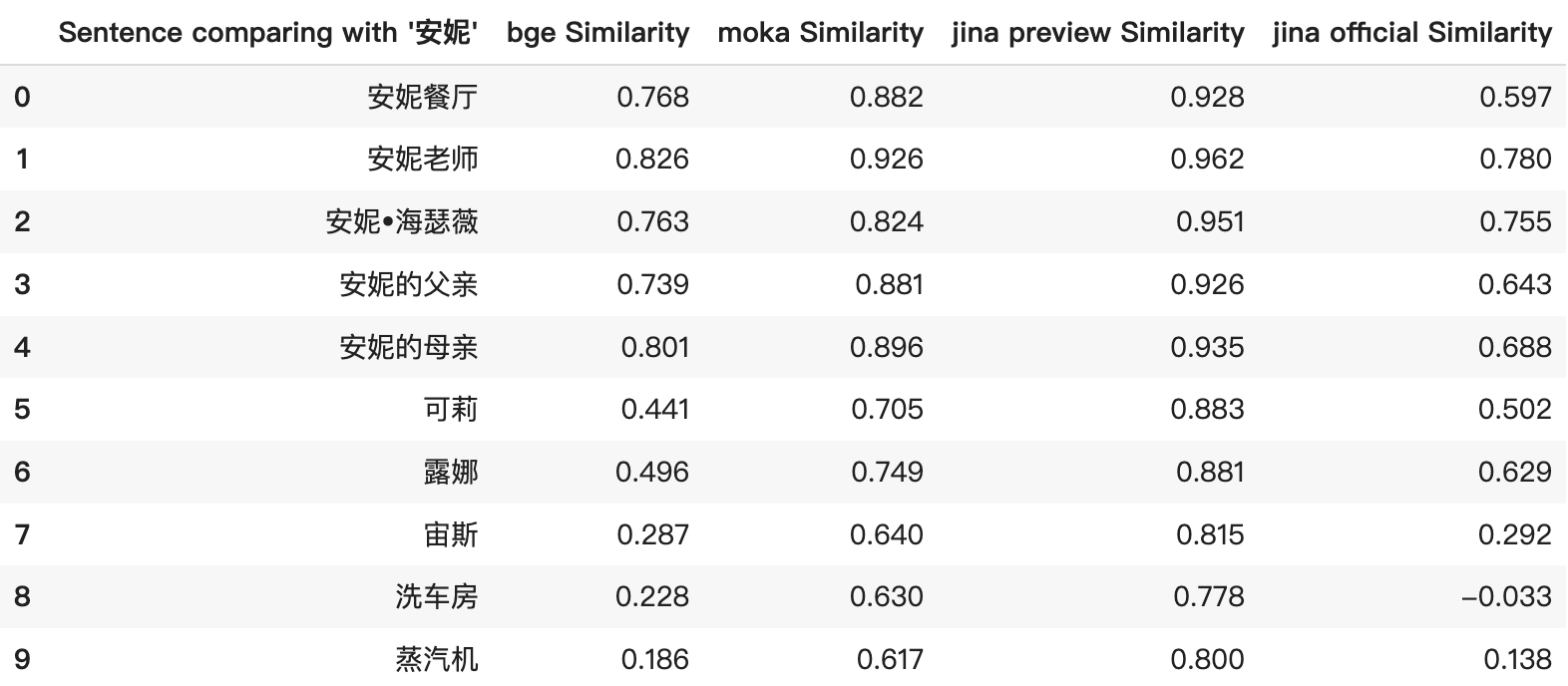
jina-embeddings-v2-base-zh-preview 存在相似度分數過高的問題,即使是不相關的項目也會得到較高的餘弦分數。這一點在下方截圖的前 5 個結果中特別明顯。相似度分數普遍偏高,並未真實反映項目間的關係。例如,「安妮」和「蒸汽機」之間的比較獲得了誤導性的高相似度分數。
在正式發布版本中,我們已經對模型進行了微調,使其產生更加明確和合理的相似度分數,確保更準確地表示項目之間的關係。例如,修訂後的評分現在呈現更廣泛的範圍,為項目間的相對相似度提供更清晰的洞察。
此外,Jina Embeddings 現在是唯一支援 8192 個 tokens 的開源嵌入模型。這一特點突顯了它在處理各種類型數據的能力,從長篇文檔到簡短短語,甚至單個詞彙/名稱,如「安妮」vs「露娜」。
tag中英雙語 8K 向量大模型全新上線,企業拓展國際市場必備!
自從我們的 Embeddings V2 獲得各界好評後,今日,我們推出了全新的中英雙語文本向量大模型:jina-embeddings-v2-base-zh。此模型不僅繼承了 V2 的全部優勢,能夠處理長達八千詞元的文本,更能流暢應對中英文雙語內容,為跨語種的應用插上了翅膀。
jina-embeddings-v2-base-zh 之所以表現卓越,全賴優質的雙語資料集,經過我們嚴格且平衡的預訓練、一階微調和二階微調。這種三步走的訓練範式不僅泛化了模型的雙語能力,更有效地降低了模型偏見,解決了多語言模型時常遭遇到的「不患寡而患不均」的問題。
tag模型特色一覽
特色 1:雙語無縫對接
jina-embeddings-v2-base-zh 模型能夠流暢處理中英文本,無論是作為搜索查詢還是目標文件。中英文本中意義相近的內容都會被映射到相同的向量空間,為多語言應用奠定了堅實基礎。
特色 2:8k Token 超長文本支援
我們的模型支援長達 8K Token 的文本處理,這在開源向量模型中獨樹一幟,在處理更長的文本段落上提供了顯著優勢。
特色 3:高效緊湊的模型結構
jina-embeddings-v2-base-zh 模型以 322MB 的輕巧體積(包含 1.61 億參數),輸出維度為 768,能夠在普通電腦硬體上高效運行,無需依賴 GPU,極大地提升了其實用性和便捷性。
tag模型性能卓越
在 CMTEB 排行榜的激烈競爭中,我們的 Jina Embeddings v2 模型在 0.5GB 以下模型類別中脫穎而出,它不僅支援中英文本,而且能夠處理高達 8K Token 的文本,這一能力在同類模型中實屬罕見。
在同等體積的支援中文的模型中,Multilingual E5 和我們的 jina-embeddings-v2-base-zh 是唯二能夠處理英文的模型,這使得跨語言應用成為可能。
目前,全球範圍內,僅有 OpenAI 的閉源模型 text-embedding-ada-002 和 Jina Embeddings 能夠支援 8k Token 的長文本輸入。而在處理中文任務方面,Jina Embeddings 顯示出了顯著的性能優勢。
tag助力中國企業拓展全球業務
我們的中英雙語向量模型 jina-embeddings-v2-base-zh 是中國企業進軍國際市場的強大夥伴。它能夠無縫處理中英雙語文本,並提供高品質的文本向量表示,還能輕鬆整合到先進的向量資料庫、搜索系統以及 RAG 應用裡。
這款模型特別適合打造適應中英雙語場景的 AI 應用,對於追求全球化發展的企業來說,其價值不可估量。以下是幾個實際應用案例:
- 文件分析與管理:分析和管理海量文件,助力國際法律和商務交易的順利進行。
- AI 驅動搜尋應用:在多語言環境中提升搜尋效能,幫助全球用戶輕鬆找到中英文相關資訊。
- 增強檢索的聊天機器人和問答系統:打造高效的雙語客服機器人,優化與全球客戶的溝通體驗。
- 自然語言處理應用:涵蓋全球市場趨勢分析、國際市場策略的主題建模,以及全球通訊管理的文本分類。
- 推薦系統:利用中英數據洞察,為全球多元化受眾提供個性化的產品和內容推薦。
藉助這款模型,中國企業能夠在 AI 應用領域跨越語言的鴻溝,在全球市場的角逐中佔據先機。
tag輕鬆上手 jina-embeddings-v2-base-zh
想要快速將我們的雙語向量模型融入您的工作流程?只需幾個簡單步驟:訪問 https://jina.ai/embeddings,領取您的免費 API 密鑰或更新現有密鑰,然後在下拉選單中選擇 jina-embeddings-v2-base-zh,您的模型即刻準備就緒,等待您的探索和使用!
tag展望未來:多語言支援與 AWS SageMaker 深度融合
jina-embeddings-v2-base-zh 即將上線 AWS SageMaker 和 HuggingFace,為用戶提供更加便捷的服務。
我們正積極推進多語言向量模型,特別是歐洲及其他國際語言的支援,來滿足全球用戶的多樣化需求。敬請期待我們即將推出的激動人心的更新,包括與 AWS SageMaker 的深度整合,我們將持續深化和拓寬服務範圍。
tag致謝:感謝早期測試者的寶貴貢獻
我們衷心感謝參與 jina-embeddings-v2-base-zh-preview 測試的中國社群朋友們。你們的寶貴意見對優化我們的模型起到了重要作用。如果您在使用過程中有任何建議或想法,歡迎隨時向我們提出。您的每一條回饋都是我們持續進步的動力。
正式版解決了預覽版的分數膨脹問題
與之前的預覽版模型相比,正式版模型提供了更加分散且合理的相似度評分。在預覽版的測試中,我們的模型曾顯示出相似度評分的通貨膨脹現象,即便是完全不相關的詞彙,比如「安妮」和「蒸汽機」,也會獲得很高的餘弦相似度。而在正式版中,我們優化了模型,以確保相似度評分更為合理,從而更準確地反映內容之間的關係。
此外,Jina Embeddings 現在支援高達 8192 Token 的文本處理,無論是長篇大論還是簡短語句,甚至是單個詞彙或名字(如「安妮」與「露娜」的比較),都能展現出其處理各種類型數據的強大能力。這一改進不僅提升了模型的準確性,也增強了其在處理多樣化數據時的靈活性和實用性。
