

AI 模型長期以來的問題之一是神經網路無法解釋它們如何產生輸出結果。這是否真的是人工智能的一個實質問題並不總是很清楚。當我們要求人類解釋他們的推理過程時,他們通常會進行合理化解釋,而且通常完全不知道自己在這麼做,給出最合理的解釋,但卻沒有任何跡象顯示他們腦中真正發生了什麼。
我們已經知道如何讓 AI 模型做出合理的回答。也許人工智能在這方面比我們願意承認的更像人類。
五十年前,美國哲學家 Thomas Nagel 寫了一篇影響深遠的論文《What Is It Like To Be A Bat?》。他認為作為一隻蝙蝠必定有其獨特的體驗:以蝙蝠的方式看世界,以蝙蝠的方式感知存在。然而,根據 Nagel 的觀點,即使我們知道關於蝙蝠大腦、蝙蝠感官和蝙蝠身體如何運作的所有可知事實,我們仍然不會知道作為一隻蝙蝠是什麼感覺。
AI 可解釋性也是同樣的問題。我們知道關於給定 AI 模型的所有事實。它只是一系列矩陣中排列的有限精度數字。我們可以輕易地驗證每個模型輸出都是正確算術的結果,但這些信息作為解釋是毫無用處的。
對於這個問題,無論是對 AI 還是對人類都沒有通用的解決方案。然而,ColBERT 架構,特別是當它作為重排序器使用"延遲交互"時,使您能夠從模型中獲得有意義的洞察,了解為什麼它在特定情況下會給出特定結果。
本文將向您展示延遲交互如何實現可解釋性,使用的是 Jina-ColBERT 模型 jina-colbert-v1-en 和 Matplotlib Python 庫。
tagColBERT 簡介
ColBERT 是在 Khattab & Zaharia (2020) 中提出的,作為對 Google 在 2018 年首次提出的 BERT 模型的擴展。Jina AI 的 Jina-ColBERT 模型借鑒了這項工作和後來在 Santhanam, et al. (2021) 中提出的 ColBERT v2 架構。ColBERT 風格的模型可以用來創建嵌入,但當用作重排序模型時它們有一些額外的特性。主要優勢是"延遲交互",這是一種與標準嵌入模型不同的語義文本相似性問題構建方式。
tag嵌入模型
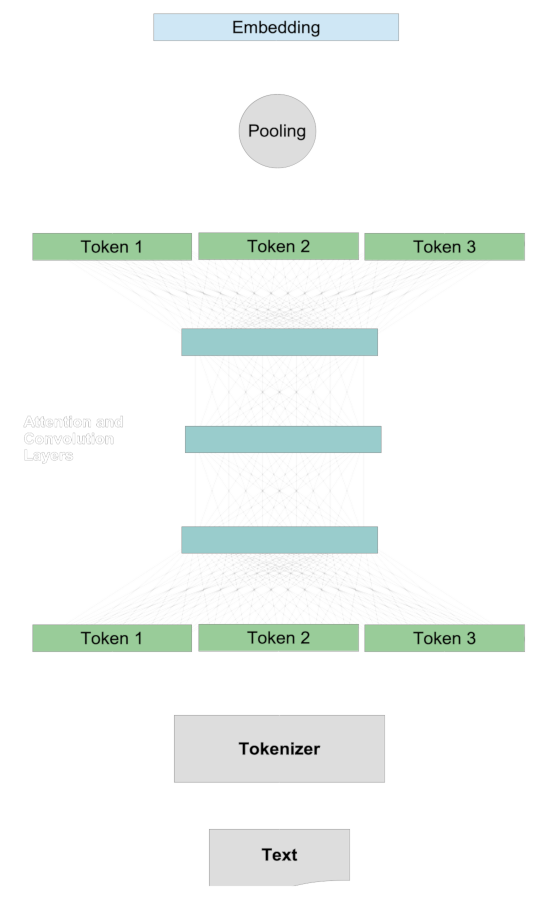
在傳統的嵌入模型中,我們通過為兩個文本生成代表性向量(稱為"嵌入")來比較它們,然後通過餘弦或漢明距離等距離度量來比較這些嵌入。量化兩個文本的語義相似性通常遵循一個共同的程序。
首先,我們為兩個文本分別創建嵌入。對於任何一個文本:
- 分詞器將文本分解成大約詞大小的塊。
- 每個標記映射到一個向量。
- 標記向量通過注意力系統和卷積層相互作用,將上下文信息添加到每個標記的表示中。
- 池化層將這些修改後的標記向量轉換為單個嵌入向量。
然後,當每個文本都有了嵌入,我們就使用餘弦度量或漢明距離來比較它們。
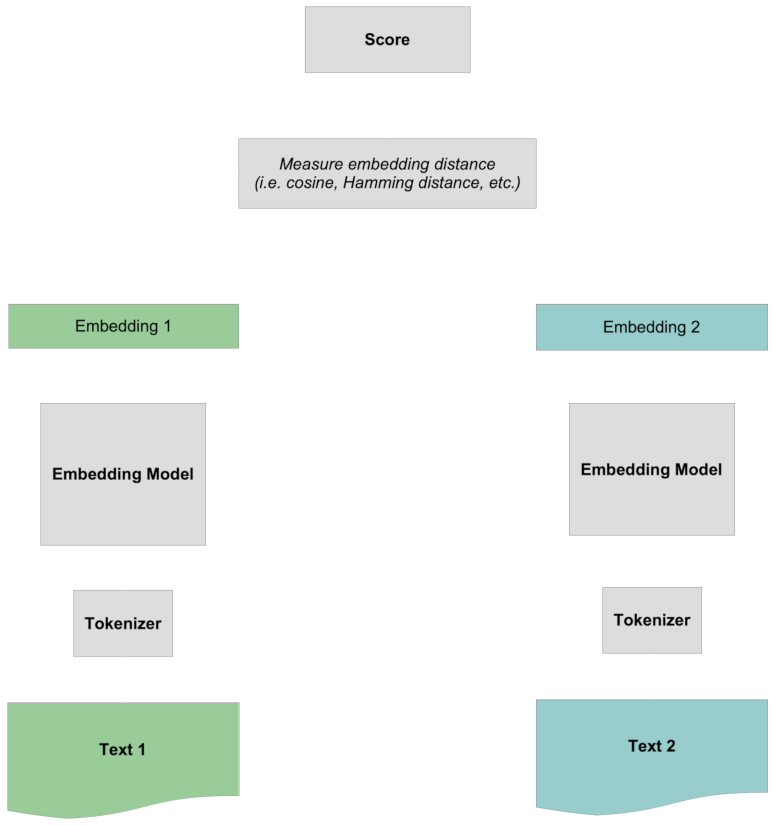
評分通過比較兩個完整的嵌入來進行,而不包含任何關於標記的具體信息。所有標記之間的交互都是"早期的",因為它發生在兩個文本相互比較之前。
tag重排序模型
重排序模型的工作方式不同。
首先,它不是為任何文本創建嵌入,而是取一個稱為"查詢"的文本,和一組我們稱為"目標文檔"的其他文本,然後根據查詢文本對每個目標文檔進行評分。這些數字不是標準化的,也不像比較嵌入,但它們是可排序的。根據模型,相對於查詢得分最高的目標文檔是與查詢在語義上最相關的文本。
讓我們使用 Jina Reranker API 和 Python 來具體看看這是如何用 jina-colbert-v1-en 重排序模型工作的。
以下代碼也在一個筆記本中,你可以下載或在 Google Colab 中運行。
你應該首先在你的 Python 環境中安裝最新版本的 requests 庫。你可以使用以下命令:
pip install requests -U
接下來,訪問 Jina Reranker API 頁面並獲取一個免費的 API 令牌,可用於處理多達一百萬個標記的文本。從頁面底部複製 API 令牌密鑰,如下所示:
我們將使用以下查詢文本:
- "Elephants eat 150 kg of food per day."
並將此查詢與三個文本進行比較:
- "Elephants eat 150 kg of food per day."
- "Every day, the average elephant consumes roughly 150 kg of plants."
- "The rain in Spain falls mainly on the plain."
第一個文檔與查詢完全相同,第二個是第一個的改寫,最後一個文本則完全無關。
使用以下 Python 代碼獲取分數,將您的 Jina Reranker API 令牌分配給變量 jina_api_key:
import requests
url = "<https://api.jina.ai/v1/rerank>"
jina_api_key = "<YOUR JINA RERANKER API TOKEN HERE>"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {jina_api_key}"
}
data = {
"model": "jina-colbert-v1-en",
"query": "Elephants eat 150 kg of food per day.",
"documents": [
"Elephants eat 150 kg of food per day.",
"Every day, the average elephant consumes roughly 150 kg of food.",
"The rain in Spain falls mainly on the plain.",
],
"top_n": 3
}
response = requests.post(url, headers=headers, json=data)
for item in response.json()['results']:
print(f"{item['relevance_score']} : {item['document']['text']}")
在 Python 文件或筆記本中運行此代碼應該產生以下結果:
11.15625 : Elephants eat 150 kg of food per day.
9.6328125 : Every day, the average elephant consumes roughly 150 kg of food.
1.568359375 : The rain in Spain falls mainly on the plain.
正如我們所預期的,完全匹配的文本得分最高,改寫的文本得分第二高,而完全無關的文本得分則低得多。
tag使用 ColBERT 進行評分
ColBERT 重排序與基於嵌入的評分不同的地方在於,兩個文本的標記在評分過程中會相互比較。兩個文本永遠不會有它們自己的嵌入。
首先,我們使用與嵌入模型相同的架構為每個標記創建包含文本上下文信息的新表示。然後,我們將查詢中的每個標記與文檔中的每個標記進行比較。
對於查詢中的每個標記,我們識別文檔中與之有最強交互的標記,並對這些交互分數進行求和來計算最終的數值。
這種互動是「後期的」:當我們比較兩段文字時,文字之間的 token 會相互作用。但請記住,「後期」互動並不排除「早期」互動。被比較的 token 向量對已經包含了它們特定上下文的資訊。
這種後期互動架構保留了 token 層級的資訊,即使這些資訊是與上下文相關的。這使我們能夠部分看到 ColBERT 模型如何計算其分數,因為我們可以識別哪些上下文化 token 對對最終分數有所貢獻。
tag使用熱力圖解釋排名
熱力圖是一種視覺化技術,有助於觀察 Jina-ColBERT 在建立分數時的運作情況。在這一節中,我們將使用 seaborn 和 matplotlib 函式庫來建立來自 jina-colbert-v1-en 後期互動層的熱力圖,展示查詢 token 如何與目標文本 token 互動。
tag設定
我們已經建立了一個 Python 函式庫檔案,其中包含訪問 jina-colbert-v1-en 模型並使用 seaborn、matplotlib 和 Pillow 來建立熱力圖的程式碼。你可以直接從 GitHub 下載這個函式庫,或者在你自己的系統上使用提供的 notebook,或在 Google Colab 上使用。
首先,安裝所需套件。你需要在你的 Python 環境中安裝最新版本的 requests 函式庫。如果你還沒有安裝,請執行:
pip install requests -U
然後,安裝核心函式庫:
pip install matplotlib seaborn torch Pillow
接下來,從 GitHub 下載 jina_colbert_heatmaps.py。你可以通過瀏覽器下載,或者如果安裝了 wget,可以在命令行中執行:
wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/heatmaps/jina_colbert_heatmaps.py
在函式庫準備就緒後,我們只需要為本文的其餘部分聲明一個函數:
from jina_colbert_heatmaps import JinaColbertHeatmapMaker
def create_heatmap(query, document, figsize=None):
heat_map_maker = JinaColbertHeatmapMaker(jina_api_key=jina_api_key)
# get token embeddings for the query
query_emb = heat_map_maker.embed(query, is_query=True)
# get token embeddings for the target document
document_emb = heat_map_maker.embed(document, is_query=False)
return heat_map_maker.compute_heatmap(document_emb[0], query_emb[0], figsize)
tag結果
現在我們可以建立熱力圖了,讓我們建立幾個並看看它們告訴我們什麼。
在 Python 中執行以下命令:
create_heatmap("Elephants eat 150 kg of food per day.", "Elephants eat 150 kg of food per day.")結果將是一個如下所示的熱力圖:
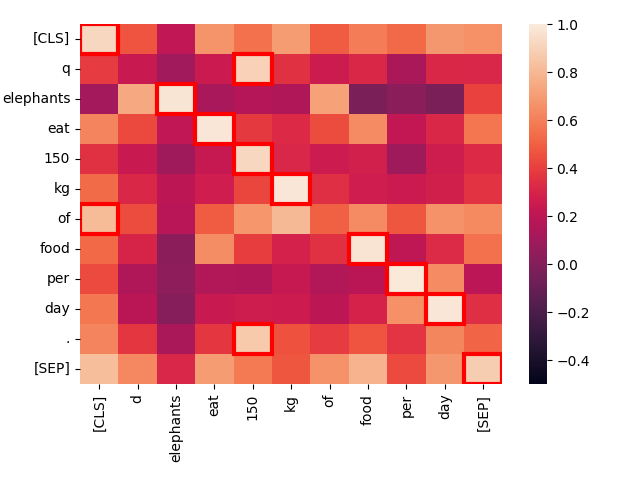
這是當我們比較兩個相同文本時的 token 對之間的激活水平熱力圖。每個方格顯示了來自每個文本的兩個 token 之間的互動。額外的 token [CLS] 和 [SEP] 分別表示文本的開始和結束,q 和 d 分別在查詢和目標文檔的 [CLS] token 之後插入。這允許模型考慮 token 與文本開始和結束之間的互動,同時也使 token 表示能夠對它們是在查詢中還是在目標中敏感。
方格越亮,兩個 token 之間的互動就越多,這表示它們在語義上相關。每個 token 對的互動分數範圍是 -1.0 到 1.0。紅框突出顯示的方格是計入最終分數的方格:對於查詢中的每個 token,其與任何文檔 token 的最高互動水平就是計算的值。
最佳匹配 — 最亮的點 — 和紅框標記的最大值幾乎都恰好在對角線上,並且它們有非常強的互動。唯一的例外是「技術性」token [CLS]、q 和 d,以及英語中攜帶很少獨立資訊的高頻「停用詞」"of"。
讓我們看一個結構相似的句子 —「Cats eat 50 g of food per day.」— 看看其中的 token 如何互動:
create_heatmap("Elephants eat 150 kg of food per day.", "Cats eat 50 g of food per day.")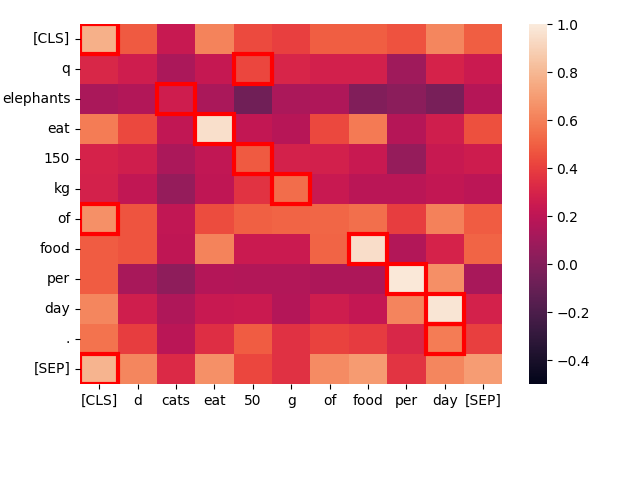
再次,最佳匹配主要在對角線上,因為單詞經常相同,且句子結構幾乎相同。即使是「cats」和「elephants」也因為它們的共同上下文而匹配,儘管匹配程度不是很高。
上下文越不相似,匹配就越差。考慮文本「Employees eat at the company canteen.」
create_heatmap("Elephants eat 150 kg of food per day.", "Employees eat at the company canteen.")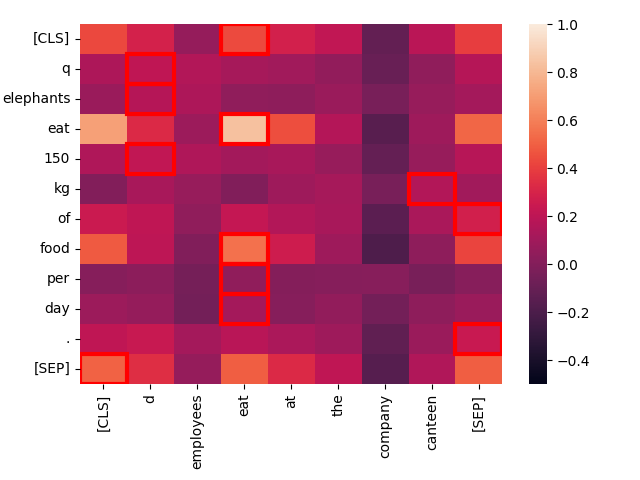
雖然結構相似,但這裡唯一強匹配是兩個「eat」之間。就主題而言,這些是很不同的句子,即使它們的結構高度平行。
通過查看紅框方格中顏色的深淺,我們可以看出模型如何將它們排序為「Elephants eat 150 kg of food per day」的匹配,jina-colbert-v1-en 確認了這種直覺:
| Score | Text |
|---|---|
| 11.15625 | Elephants eat 150 kg of food per day. |
| 8.3671875 | Cats eat 50 g of food per day. |
| 3.734375 | Employees eat at the company canteen. |
現在,讓我們將「Elephants eat 150 kg of food per day.」與一個本質上意思相同但表達不同的句子進行比較:「Every day, the average elephant consumes roughly 150 kg of food.」
create_heatmap("Elephants eat 150 kg of food per day.", "Every day, the average elephant consumes roughly 150 kg of food.")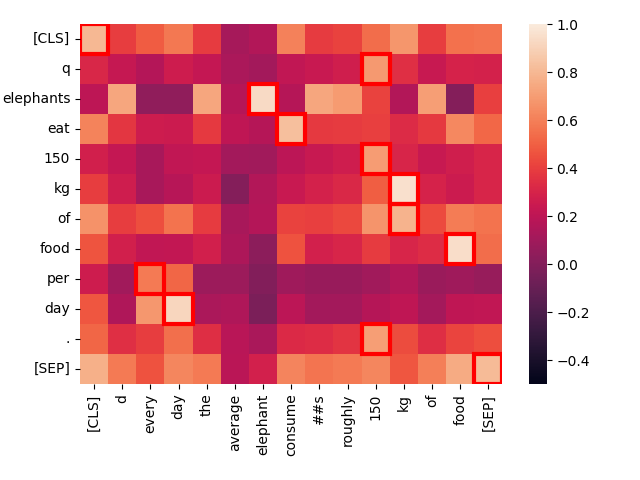
請注意,第一句中的 "eat" 和第二句中的 "consume" 之間存在強烈的關聯。儘管詞彙不同,但 Jina-ColBERT 仍能識別出它們的共同含義。
此外,"every day" 與 "per day" 高度匹配,儘管它們在句子中的位置完全不同。只有低價值詞 "of" 顯示異常的不匹配。
現在,讓我們將同樣的查詢與一個完全無關的文本進行比較:"The rain in Spain falls mainly on the plain."
create_heatmap("Elephants eat 150 kg of food per day.", "The rain in Spain falls mainly on the plain.")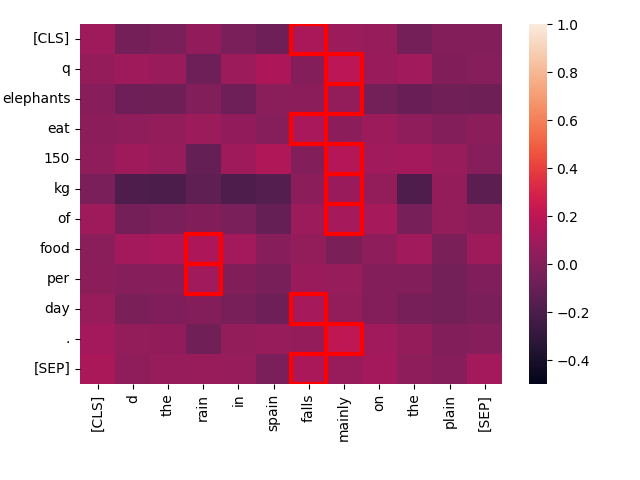
你可以看到,這對文本的"最佳匹配"互動得分要低得多,且兩段文本中的任何詞之間幾乎沒有互動。從直覺上來說,與"Every day, the average elephant consumes roughly 150 kg of food"相比,這個分數應該較低,jina-colbert-v1-en的結果也印證了這一點:
| Score | Text |
|---|---|
| 9.6328125 | Every day, the average elephant consumes roughly 150 kg of food. |
| 1.568359375 | The rain in Spain falls mainly on the plain. |
tag長文本
這些是用於展示 ColBERT 式重排序模型工作原理的示例。在信息檢索場景中,例如檢索增強生成,查詢通常是短文本,而匹配的候選文檔往往較長,經常與模型的輸入上下文窗口一樣長。
Jina-ColBERT 模型都支持 8192 個 token 的輸入上下文,相當於大約 16 頁標準的單倍行距文本。
我們也可以為這些非對稱情況生成熱力圖。例如,讓我們看看印度象維基百科頁面的第一部分:
要查看傳遞給 jina-colbert-v1-en 的純文本版本,請點擊此連結。
這段文本有 364 個詞,所以我們的熱力圖不會呈現正方形:
create_heatmap("Elephants eat 150 kg of food per day.", wikipedia_elephants, figsize=(50,7))
我們看到 "elephants" 在文本中多處匹配。在一篇關於大象的文本中,這並不令人驚訝。但我們也可以看到一個互動更強的區域:
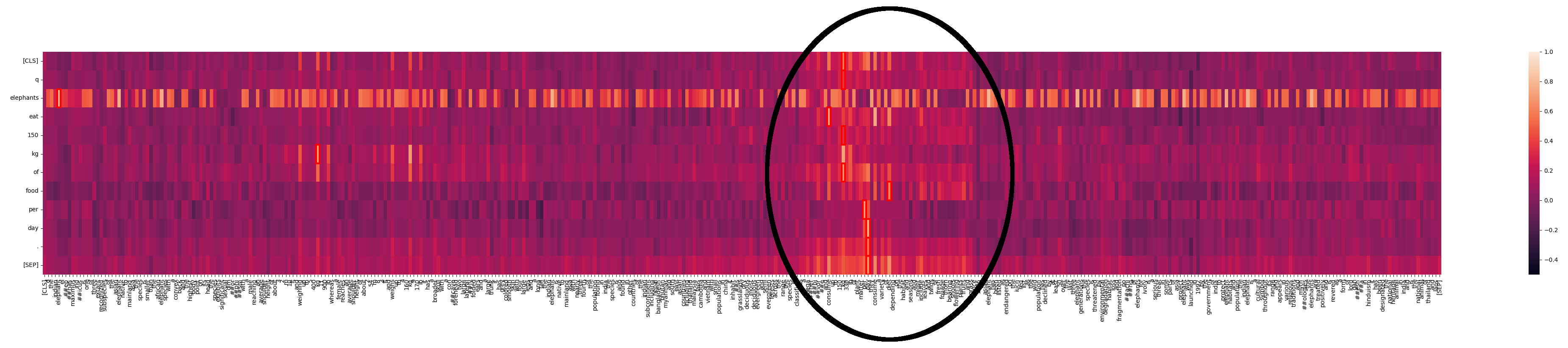
這裡發生了什麼?使用 Jina-ColBERT,我們可以找到長文本中對應的部分。這是第二段的第四句話:
這個物種被歸類為巨型草食動物,每天可消耗高達 150 公斤(330 磅)的植物。
這重述了查詢文本中的相同信息。如果我們只看這句話的熱力圖,就能看到強匹配:
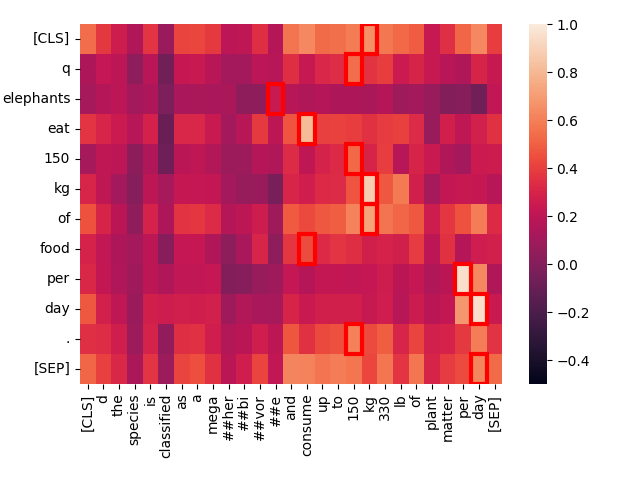
Jina-ColBERT 讓你能夠準確看到長文本中哪些區域導致它與查詢匹配。這不僅有助於更好的調試,還能提供更好的可解釋性。看到匹配是如何形成的並不需要太複雜的理解。
tag使用 Jina-ColBERT 解釋 AI 結果
嵌入是現代 AI 的核心技術。我們幾乎所有的工作都基於這樣的理念:輸入數據中的複雜、可學習關係可以在高維空間的幾何中表達。然而,對於普通人來說,要理解數千到數百萬維度的空間關係是非常困難的。
ColBERT 是對這種抽象層次的一個回歸。它不是解釋 AI 模型行為問題的完整答案,但它直接指出了哪些數據部分導致了我們的結果。
有時候,AI 必須是一個黑盒子。執行所有重要運算的巨大矩陣太大,任何人都無法完全理解。但 ColBERT 架構為這個黑盒子投入一些光明,展示了更多的可能性。
Jina-ColBERT 模型目前只提供英文版(jina-colbert-v1-en),但更多語言和使用場景正在開發中。這系列模型不僅能執行最先進的信息檢索,還能告訴你為什麼它們會匹配某些內容,這展示了 Jina AI 致力於使 AI 技術既易於使用又實用的承諾。





