


深夜,一名警察發現一個醉漢在街燈下爬來爬去。醉漢告訴警察他在找錢包。當警察問他是否確定錢包是在這裡掉的時候,那人回答說他更可能是把錢包掉在街對面。困惑的警察問道:那你為什麼要在這裡找?醉漢解釋說:因為這裡的光線比較好。
David H. Friedman,為什麼科學研究經常是錯的:路燈效應,Discover 雜誌,2010 年 12 月
基準測試是現代機器學習實踐的核心組成部分,並且已經存在了一段時間,但它們存在一個非常嚴重的問題:我們無法判斷我們的基準測試是否衡量了任何有用的東西。
這是一個大問題,本文將介紹解決方案的一部分:AIR-Bench。這個與北京智源人工智能研究院的聯合項目是一種旨在提高基準測試品質和實用性的新型 AI 評估方法。


tag路燈效應
科學和運營研究非常強調測量,但測量並不是一件簡單的事情。在健康研究中,你可能想知道某種藥物或治療是否使接受者更健康、壽命更長,或者以某種方式改善了他們的狀況。但健康和生活品質的改善很難直接測量,而且可能需要數十年才能知道某種治療是否延長了某人的壽命。
因此研究人員使用替代指標。在健康研究中,可能是體能、疼痛減輕、血壓降低或其他容易測量的變量。健康研究的問題之一是,替代指標可能並不能真正反映你希望藥物或治療帶來的更好的健康結果。
測量是對你關心的有用事物的替代。你可能無法測量那個事物,所以你測量其他東西,你能測量的東西,你有理由相信這些測量與你真正關心的有用事物相關。
關注測量是 20 世紀運營研究的一個重大發展,它產生了一些深遠而積極的影響。全面品質管理是一套被認為是日本在 1980 年代崛起為經濟強國的理論,幾乎完全是關於對替代變量的持續測量並在此基礎上優化實踐。
但關注測量會帶來一些已知的重大問題:
- 當你根據測量做出決策時,這個測量可能不再是一個好的替代指標。
- 經常有些方法可以誇大測量結果而不會帶來任何改進,這可能導致作弊或認為你通過做一些無助於改進的事情在取得進步。
有些人認為大多數醫學研究可能是錯誤的,部分原因就是這個問題。可以測量的東西與實際目標之間的脫節是美國越戰災難被引用的原因之一。
這有時被稱為"路燈效應",就像本文開頭的故事一樣,醉漢不是在他丟失東西的地方尋找,而是在光線更好的地方尋找。替代測量就像在有光的地方尋找,因為我們想看的東西那裡沒有光。
在更專業的文獻中,"路燈效應"通常與古德哈特定律相關聯,這源於英國經濟學家Charles Goodhart對撒切爾政府的批評,該政府非常重視繁榮的替代指標。古德哈特定律有幾種表述,但以下是最廣為人知的:
當一個測量指標成為目標時,它就不再是一個好的測量指標[...]
Keith Hoskins,1996 年《可追責性的可怕想法》:將人們納入物件的測量中。
在 AI 領域,一個著名的例子是機器翻譯研究中使用的 BLEU 指標。BLEU 是 2001 年在 IBM 開發的一種自動評估機器翻譯系統的方法,它是 00 年代機器翻譯蓬勃發展的關鍵因素。一旦可以輕鬆地為你的系統打分,你就可以努力改進它。而 BLEU 分數也持續提高。到了 2010 年,如果一篇機器翻譯的研究論文沒有超過最先進的 BLEU 分數,幾乎不可能被期刊或會議接受,不管這篇論文有多創新,或者它在處理其他系統處理不好的特定問題時表現如何。
進入會議最容易的方法是找到一些微小的方式來調整模型參數,獲得比 Google Translate 高一點點的 BLEU 分數,然後提交。這些結果本質上是沒用的。只要給它一些新的文本來翻譯就會發現,它們很少比最先進的系統更好,而且經常更糟。
不是用 BLEU 來評估機器翻譯的進展,而是獲得更好的 BLEU 分數成了目標。一旦發生這種情況,它就不再是評估進展的有用方法。
tag我們的 AI 基準測試是好的替代指標嗎?
最廣泛使用的 embedding 模型基準是 MTEB 測試集,它包含 56 個具體測試。這些測試按類別分類並全部平均,產生特定類別的分數。在撰寫本文時,MTEB 排行榜的頂部看起來是這樣的:
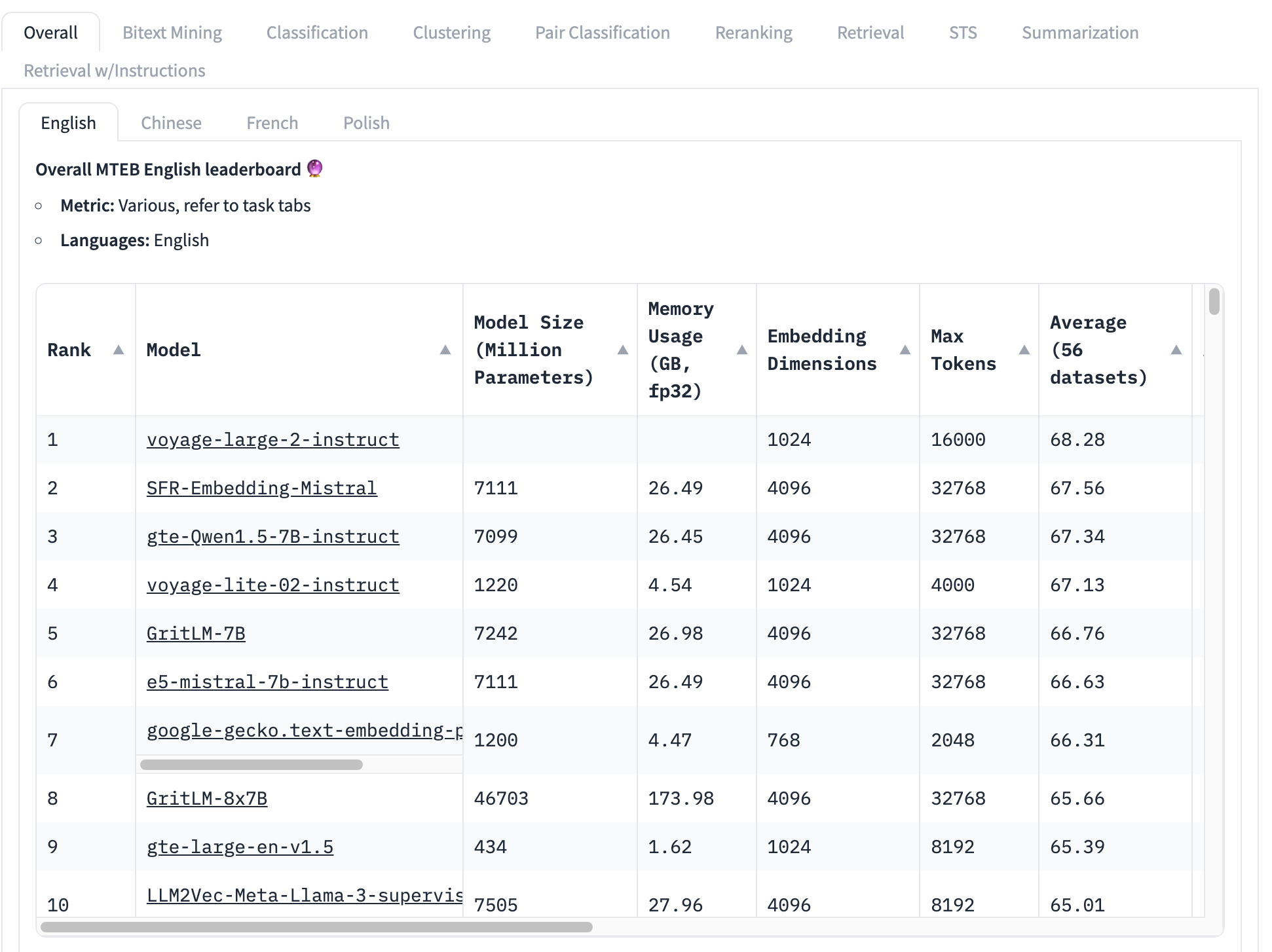
排名最高的 embedding 模型的總平均分數為 68.28,第二高的是 67.56。從這個表格看,很難知道這是否是一個巨大的差異。如果這是一個小差異,那麼其他因素可能比哪個模型得分最高更重要:
- 模型大小:模型有不同的大小,反映了不同的計算資源需求。小型模型運行更快、使用更少的記憶體,並且需要較少昂貴的硬體。在這個前 10 名列表中,我們看到模型大小從 4.34 億參數到超過 460 億參數不等 — 相差 100 倍!
- Embedding 大小:Embedding 維度各不相同。較小的維度使 embedding 向量使用更少的記憶體和儲存空間,並使向量比較(embeddings 的核心用途)更快。在這個列表中,我們看到 embedding 維度從 768 到 4096 不等 — 只相差 5 倍,但在構建商業應用時仍然很重要。
- 上下文輸入窗口大小:上下文窗口的大小和品質都有所不同,從 2048 個 token 到 32768 個不等。此外,不同的模型使用不同的位置編碼和輸入管理方法,這可能會造成偏向輸入的特定部分。
簡而言之,總平均分數是一個非常不完整的方式來決定哪個 embedding 模型是最好的。
即使我們查看特定任務的分數,比如下面的檢索分數,我們也面臨同樣的問題。無論模型在這組測試中的分數如何,都無法知道哪些模型會在你特定的獨特用例中表現最好。
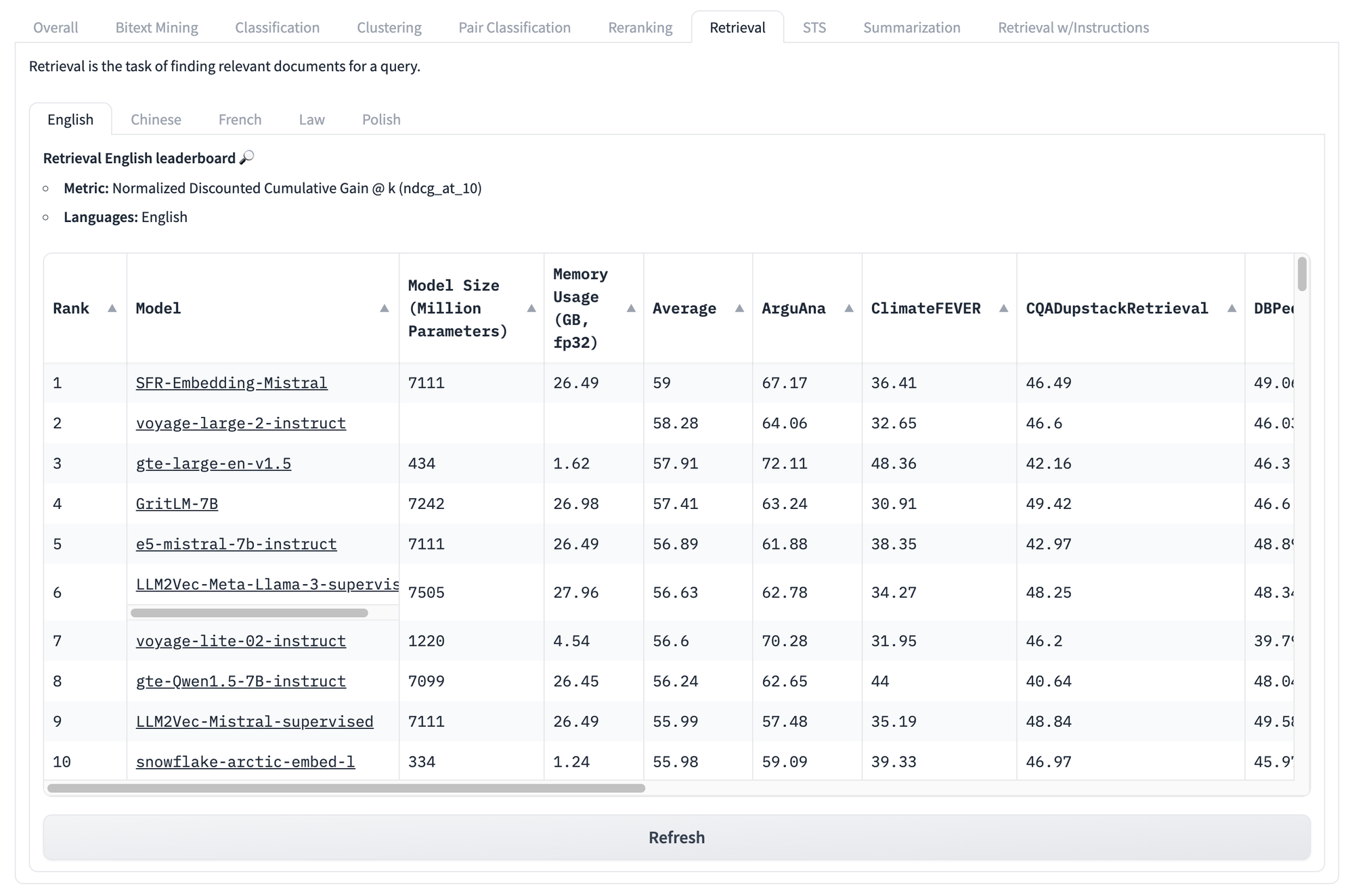
但這些基準測試的問題還不僅止於此。
古德哈特定律的主要洞見是,任何指標都可能被操縱,即使並非刻意為之。例如,MTEB 基準測試包含來自公共來源的數據,這些數據很可能已經存在於您的訓練數據中。除非您特意嘗試從訓練中移除基準測試數據,否則您的基準分數在統計上將是不可靠的。
這個問題沒有簡單而全面的解決方案。基準測試只是一種代理指標,我們永遠無法確定它是否真正反映了我們想要知道但無法直接測量的內容。
但我們確實看到了 AI 基準測試存在的三個核心問題,這些問題是可以緩解的:
- 基準測試本質上是固定的:使用相同的任務和相同的文本。
- 基準測試過於通用:對真實場景的參考價值有限。
- 基準測試缺乏靈活性:無法適應多樣化的使用場景。
AI 創造了這樣的問題,但有時也能提供解決方案。我們相信可以使用 AI 模型來解決這些問題,至少在 AI 基準測試方面是如此。
tag使用 AI 來基準測試 AI:AIR-Bench
AIR-Bench 是開源的,並採用 MIT 授權。您可以從其 GitHub 倉庫查看或下載程式碼。
 AIR-Bench
AIR-Benchtag它有什麼功能?
AIR-Bench 為 AI 基準測試帶來了一些重要特性:
- 針對檢索和 RAG 應用的專業化
這個基準測試專注於實際的資訊檢索應用和檢索增強生成管道。 - 領域和語言的靈活性
AIR 讓從特定領域數據或其他語言,甚至從您自己的特定任務數據中創建基準測試變得更加容易。 - 自動數據生成
AIR-Bench 生成測試數據,且數據集會定期更新,降低數據洩漏的風險。
tagHuggingFace 上的 AIR-Bench 排行榜
我們正在運營一個排行榜,類似於 MTEB 的排行榜,用於當前發布的 AIR-Bench 生成任務。我們將定期重新生成基準測試、添加新的基準測試,並擴大對更多 AI 模型的覆蓋範圍。

tag它是如何工作的?
AIR 方法的核心洞見是我們可以使用大型語言模型(LLM)來生成新的文本和新的任務,這些內容不可能存在於任何訓練集中。
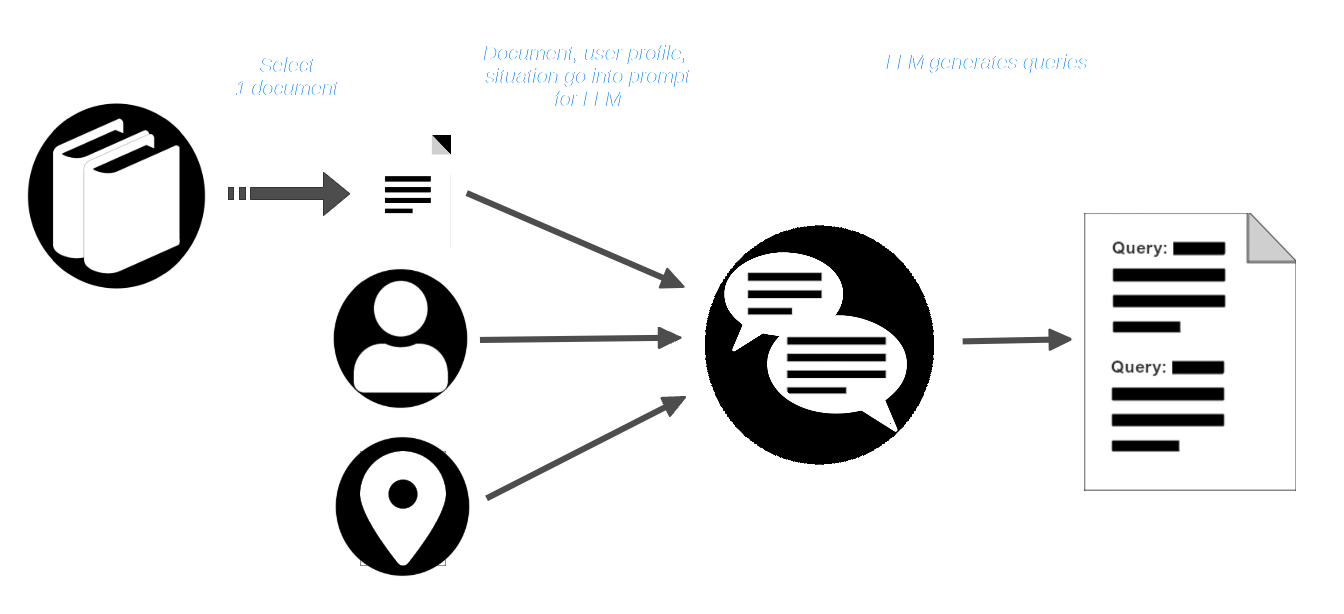
AIR-Bench 利用 LLM 的創造能力,讓它們模擬一個場景。使用者選擇一個文檔集合 — 可能是一個真實的集合,且可能是某些模型訓練數據的一部分 — 然後想像一個具有特定角色的用戶,以及他們需要使用該文檔庫的情境。

然後,使用者從文檔庫中選擇一個文檔,並將其與用戶檔案和情境描述一起傳遞給 LLM。LLM 被提示創建適合該用戶和情境的查詢,這些查詢應該能找到該文檔。
AIR-Bench 管道接著使用文檔和查詢來提示 LLM,並生成與提供的文檔相似但不應匹配查詢的合成文檔。
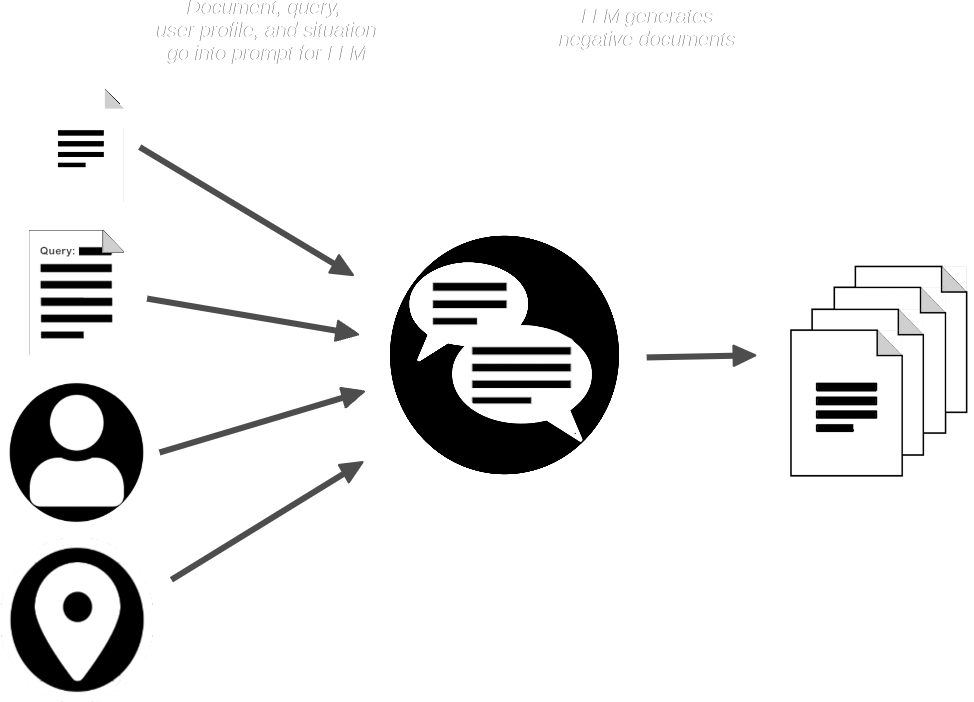
現在我們有了:
- 一組查詢
- 每個查詢對應的真實匹配文檔
- 一小組預期不匹配的合成文檔
AIR-Bench 將合成文檔與真實文檔集合合併,然後使用一個或多個嵌入和重排序模型來驗證查詢是否應該能夠檢索到匹配的文檔。它還使用 LLM 來驗證每個查詢是否與它應該檢索的文檔相關。
要了解更多關於這個以 AI 為中心的生成和質量控制過程的詳細信息,請閱讀 AIR-Bench GitHub 倉庫中的數據生成文檔。
AIR-Bench結果產生了一組高質量的查詢-匹配配對和一個用於運行它們的半合成數據集。即使原始真實文檔集構成了其訓練的一部分,添加的合成文檔和查詢本身都是全新的、前所未見的數據,這些是它之前無法學習到的。
tag特定領域基準測試和基於現實的測試
合成查詢和文檔可以防止基準數據洩漏到訓練中,同時也很大程度上解決了泛用基準測試的問題。
通過為 LLM 提供選定的數據、使用者配置文件和場景,AIR-Bench 可以非常輕鬆地為特定使用案例構建基準測試。此外,通過為特定類型的使用者和使用場景構建查詢,AIR-Bench 可以產生比傳統基準測試更貼近真實世界使用情況的測試查詢。LLM 有限的創造力和想像力可能無法完全匹配真實世界的場景,但比起研究人員可用數據製作的靜態測試數據集來說,這是更好的選擇。
作為這種靈活性的附加優勢,AIR-Bench 支援 GPT-4 支援的所有語言。
此外,AIR-Bench 特別聚焦於實際的 AI 資訊檢索,這是 embedding 模型最廣泛的應用。它不為其他類型的任務(如聚類或分類)提供評分。
tagAIR-Bench 發行版
AIR-Bench 可以通過其 GitHub 倉庫下載、使用和修改。
AIR-BenchAIR-Bench 支援兩種基準測試:
- 基於評估特定查詢相關文檔正確檢索的資訊檢索任務。
- 模擬檢索增強生成管道中資訊檢索部分的「長文檔」任務。
我們還預先生成了一組基準測試,包括英文和中文,以及生成這些測試的腳本,作為如何使用 AIR-Bench 的實際範例。這些測試使用了一組現成的數據。
例如,對於6,738,498 個英文維基百科頁面的選集,我們生成了 1,727 個查詢,匹配 4,260 個文檔,並額外生成了 7,882 個合成的非匹配但相似的文檔。我們為八個英語數據集和六個中文數據集提供常規資訊檢索基準測試。對於「長文檔」任務,我們提供了十五個基準測試,全部為英文。
要查看完整列表和更多詳細信息,請訪問 GitHub 上 AIR-Bench 倉庫中的可用任務頁面。
AIR-Benchtag參與其中
AIR-Benchmark 被設計為 Search Foundations 社群的工具,讓活躍用戶可以創建更適合其需求的基準測試。當您的測試能為您的使用案例提供資訊時,這也能幫助我們更好地了解您的需求,從而開發出更符合您需求的產品。
