


多模態搜尋結合了文字和圖像,提供流暢的搜尋體驗,這要歸功於像是 OpenAI 的 CLIP 這樣的模型。這些模型有效地橋接了視覺和文字資料之間的差距,讓我們能夠將圖像與相關文字互相連結。
雖然 CLIP 和類似的模型功能強大,但它們也有明顯的限制,特別是在處理較長的文字或複雜的文字關係時。這就是 jina-clip-v1 出現的原因。
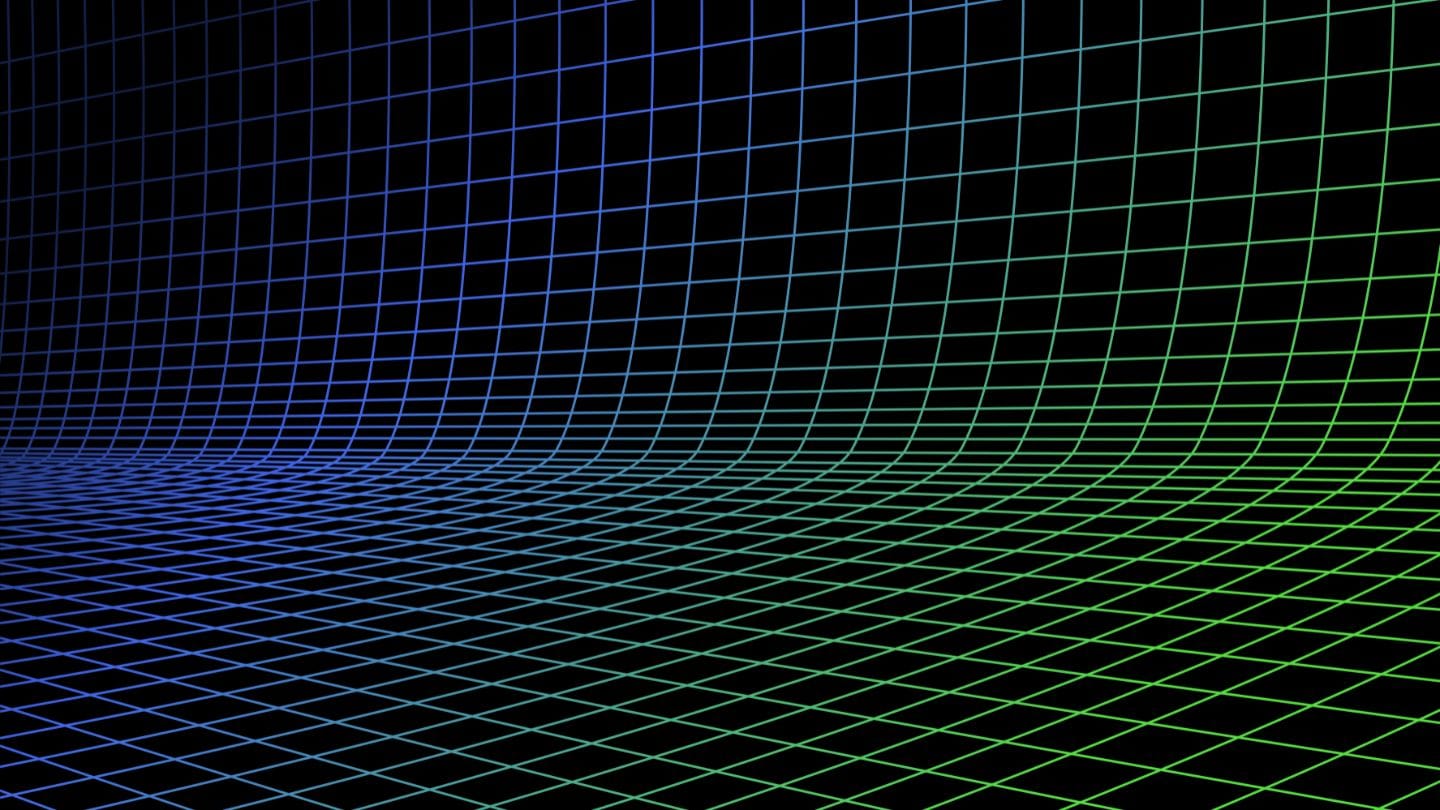
jina-clip-v1 的設計就是為了解決這些挑戰,它提供了更好的文字理解能力,同時保持強大的文字-圖像匹配功能。它為使用這兩種模態的應用程式提供了更精簡的解決方案,簡化了搜尋過程,消除了在文字和圖像之間切換不同模型的需求。
在這篇文章中,我們將探討 jina-clip-v1 為多模態搜尋應用帶來的優勢,透過實驗展示它如何通過整合文字和圖像嵌入來提升結果的準確度和多樣性。
tag什麼是 CLIP?
CLIP(Contrastive Language–Image Pretraining)是由 OpenAI 開發的 AI 模型架構,通過學習聯合表示來連接文字和圖像。CLIP 本質上是將文字模型和圖像模型結合在一起——它將兩種類型的輸入轉換到共同的嵌入空間中,使相似的文字和圖像被放置在相近的位置。CLIP 是在龐大的圖像-文字配對數據集上訓練的,使其能夠理解視覺和文字內容之間的關係。這使它能夠在不同領域中良好地泛化,在零樣本學習場景中(如生成圖像說明或圖像檢索)非常有效。
自 CLIP 發布以來,其他模型如 SigLiP、LiT 和 EvaCLIP 都在其基礎上進行了擴展,改進了訓練效率、擴展性和多模態理解等方面。這些模型通常利用更大的數據集、改進的架構和更複雜的訓練技術來推進圖像-語言模型的發展。
雖然 CLIP 可以單獨處理文字,但它有顯著的限制。首先,它只針對短文字說明進行訓練,而不是長文本,最多只能處理約 77 個字。其次,CLIP 擅長連接文字和圖像,但在比較文字與文字時表現較差,例如無法很好地識別 a crimson fruit 和 a red apple 可能指的是同一物品。這正是專門的文字模型(如 jina-embeddings-v3)擅長的領域。
這些限制使同時涉及文字和圖像的搜尋任務變得複雜,例如,在一個"購買相似款"的線上商店中,用戶可以使用文字或圖片來搜尋時尚產品。在為產品建立索引時,你需要多次處理每個產品——一次處理圖像、一次處理文字,還要再用一個特定的文字模型處理一次。同樣,當用戶搜尋產品時,你的系統需要至少搜尋兩次才能找到文字和圖像的目標:
tag如何使用 jina-clip-v1 解決 CLIP 的缺點
為了克服 CLIP 的限制,我們創建了 jina-clip-v1,使其能夠理解更長的文字,並更有效地將文字查詢與文字和圖像匹配。是什麼讓 jina-clip-v1 如此特別?首先,它使用更智能的文字理解模型(JinaBERT),幫助它理解更長和更複雜的文字(如產品描述),而不僅僅是短標題(如產品名稱)。其次,我們訓練 jina-clip-v1 同時擅長兩件事:將文字與圖像匹配,以及將文字與其他文字匹配。
使用 OpenAI CLIP 時情況並非如此:無論是在索引還是查詢時,你都需要調用兩個模型(CLIP 用於圖像和短文字如標題,另一個文字嵌入模型用於較長的文字如描述)。這不僅增加了開銷,還降低了搜尋速度,而搜尋本應該是非常快速的操作。jina-clip-v1 用一個模型就完成了所有這些工作,而且不會犧牲速度:

這種統一的方法開啟了早期模型難以實現的新可能性,潛在地重塑了我們處理搜尋的方式。在這篇文章中,我們進行了兩個實驗:
- 通過結合文字和圖像搜尋來改善搜尋結果:我們能否結合 jina-clip-v1 對文字和圖像的理解?當我們混合這兩種理解方式時會發生什麼?添加視覺資訊是否會改變我們的搜尋結果?簡而言之,如果我們同時使用文字和圖像進行搜尋,是否能得到更好的結果?
- 使用圖像來增加搜尋結果的多樣性:大多數搜尋引擎都致力於最大化文字匹配。但我們能否使用 jina-clip-v1 的圖像理解作為"視覺隨機排序"?不僅僅顯示最相關的結果,我們還可以包含視覺上多樣化的結果。這不是為了找到更多相關的結果,而是為了展示更廣泛的視角,即使它們的相關性較低。通過這樣做,我們可能會發現我們之前沒有想到的主題方面。例如,在時尚搜尋的情境中,如果用戶搜尋"多彩雞尾酒裙",他們是希望看到所有看起來相似的結果(即非常接近的匹配),還是想要更多樣化的選擇(通過視覺隨機排序)?
這兩種方法在各種用戶可能使用文字或圖像搜尋的場景中都很有價值,例如電子商務、媒體、藝術設計、醫學影像等領域。
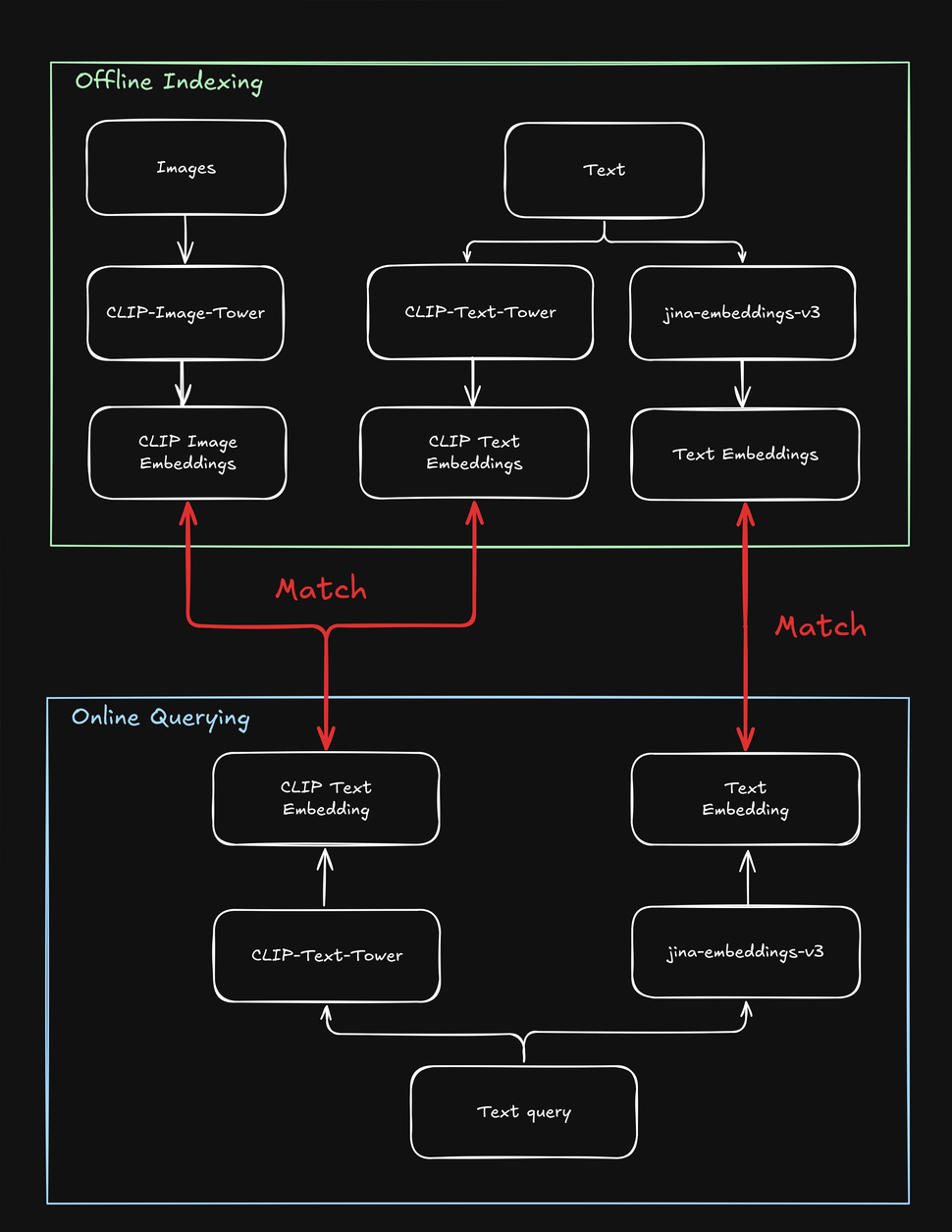
tag平均文字和圖像嵌入以獲得超越平均的表現
當用戶提交查詢(通常是文字字串)時,我們可以使用 jina-clip-v1 的文字塔來將查詢編碼為文字嵌入。jina-clip-v1 的強大之處在於它能夠在相同的語意空間中對齊文字到文字和文字到圖像的信號,從而理解文字和圖像。
如果我們通過平均每個產品的預索引文字和圖像嵌入來結合它們,是否可以改善檢索結果?
這創建了一個同時包含文字資訊(例如產品描述)和視覺資訊(例如產品圖片)的單一表示。然後我們可以使用文字查詢嵌入來搜尋這些混合表示。這會如何影響我們的搜尋結果?
為了找出答案,我們使用了 Fashion200k 數據集,這是一個專門為時尚圖像檢索和跨模態理解任務創建的大規模數據集。它包含超過 20 萬張時尚商品圖像,如服裝、鞋子和配飾,以及相應的產品描述和元數據。
 xthan
xthan我們將每個項目進一步分類為廣義類別(例如 dress)和細分類別(例如 knit midi dress)。
tag分析三種檢索方法
為了了解平均文本和圖像嵌入是否能產生更好的檢索結果,我們實驗了三種搜尋類型,每種都使用文本字串(例如 red dress)作為查詢:
- 查詢到描述使用文本嵌入:基於文本嵌入搜尋產品描述。
- 查詢到圖像使用跨模態搜尋:基於圖像嵌入搜尋產品圖片。
- 查詢到平均嵌入:搜尋產品描述和產品圖片的平均嵌入。
我們首先對整個數據集建立索引,然後隨機生成 1,000 個查詢來評估性能。我們將每個查詢編碼為文本嵌入,並根據上述方法分別進行匹配。我們通過返回產品的類別與輸入查詢的匹配程度來衡量準確性。
當我們使用查詢 multicolor henley t-shirt dress 時,查詢到描述搜尋在前 5 個結果中達到最高精確度,但排名最後三位的連衣裙在視覺上完全相同。這並不理想,因為有效的搜尋應該在相關性和多樣性之間取得平衡,以更好地吸引用戶注意力。

查詢到圖像跨模態搜尋使用相同的查詢,採取了相反的方法,呈現出高度多樣化的連衣裙集合。雖然它在五個結果中有兩個匹配正確的廣義類別,但沒有任何一個匹配細分類別。

平均文本和圖像嵌入搜尋產生了最佳結果:五個結果全部匹配廣義類別,其中兩個匹配細分類別。此外,視覺重複的項目被消除,提供了更多樣化的選擇。使用文本嵌入來搜尋平均文本和圖像嵌入似乎在保持搜尋質量的同時,還結合了視覺線索,產生更多樣化和更全面的結果。

tag擴大規模:使用更多查詢進行評估
為了確認這種方法在更大規模上是否有效,我們繼續對更多廣義和細分類別進行實驗。我們進行了多次迭代,每次檢索不同數量的結果("k 值")。
在廣義和細分類別中,查詢到平均嵌入在所有 k 值(10、20、50、100)下都持續達到最高精確度。這表明結合文本和圖像嵌入能提供最準確的相關項目檢索結果,無論類別是廣義還是特定的:

| k | Search Type | Broad Category Precision (cosine similarity) | Fine-grained Category Precision (cosine similarity) |
|---|---|---|---|
| 10 | Query to Description | 0.9026 | 0.2314 |
| 10 | Query to Image | 0.7614 | 0.2037 |
| 10 | Query to Avg Embedding | 0.9230 | 0.2711 |
| 20 | Query to Description | 0.9150 | 0.2316 |
| 20 | Query to Image | 0.7523 | 0.1964 |
| 20 | Query to Avg Embedding | 0.9229 | 0.2631 |
| 50 | Query to Description | 0.9134 | 0.2254 |
| 50 | Query to Image | 0.7418 | 0.1750 |
| 50 | Query to Avg Embedding | 0.9226 | 0.2390 |
| 100 | Query to Description | 0.9092 | 0.2139 |
| 100 | Query to Image | 0.7258 | 0.1675 |
| 100 | Query to Avg Embedding | 0.9150 | 0.2286 |
- 使用文本嵌入的查詢到描述在兩個類別中都表現良好,但略遜於平均嵌入方法。這表明純文本描述能提供有價值的資訊,特別是對於像"dress"這樣的廣義類別,但可能缺乏識別細分類別(例如區分不同類型的連衣裙)所需的細節。
- 使用跨模態搜尋的查詢到圖像在兩個類別中的精確度始終最低。這表明雖然視覺特徵可以幫助識別廣義類別,但在捕捉特定時尚項目的細分區別方面較不有效。純粹依靠視覺特徵來區分細分類別的挑戰特別明顯,因為視覺差異可能很微妙,需要文本提供的額外上下文。
- 總的來說,結合文本和視覺資訊(通過平均嵌入)在廣義和細分時尚檢索任務中都達到了高精確度。文本描述扮演重要角色,特別是在識別廣義類別方面,而單純使用圖像在兩種情況下都較不有效。
總的來說,廣義類別的精確度比細分類別高得多,主要是因為廣義類別(如 dress)在數據集中的表示比細分類別(如 henley dress)更多,這很自然,因為後者是前者的子集。本質上,廣義類別比細分類別更容易概括。在時尚範例之外,識別某物一般是鳥類相對容易,但要識別它是天堂鳥就難得多。
另一個值得注意的點是,文本查詢中的資訊更容易與其他文本(如產品名稱或描述)匹配,而不是視覺特徵。因此,如果使用文本作為輸入,文本比圖像更可能成為輸出。通過在索引中結合圖像和文本(通過平均嵌入),我們獲得了最佳結果。
tag用文本檢索結果;用圖像讓結果多樣化
在前一節中,我們提到了視覺重複搜尋結果的問題。在搜尋中,精確度本身並不總是足夠的。在許多情況下,維持一個簡潔但高度相關且多樣化的排序列表更有效,特別是當使用者的查詢不明確時(例如,如果使用者搜尋black jacket —— 他們指的是黑色機車夾克、飛行夾克、西裝外套,還是其他類型?)。
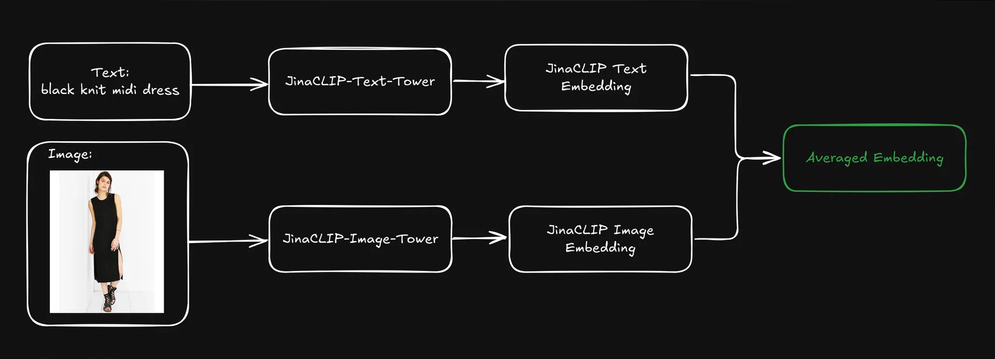
現在,與其利用 jina-clip-v1 的跨模態能力,讓我們使用其文字塔(text tower)的文字嵌入來進行初步文字搜尋,然後將圖像塔(image tower)的圖像嵌入作為「視覺重排序器」來讓搜尋結果更多樣化。以下圖表說明了這個過程:
- 首先,基於文字嵌入檢索出前 k 個搜尋結果。
- 對於每個頂部搜尋結果,提取視覺特徵並使用圖像嵌入進行聚類。
- 透過從每個聚類中選取一個項目來重新排序搜尋結果,並向用戶呈現多樣化的列表。
在檢索出前五十個結果後,我們對圖像嵌入應用了輕量級的 k-means 聚類(k=5),然後從每個聚類中選取項目。由於我們使用查詢對產品類別作為度量標準,類別精確度與 Query-to-Description 的表現保持一致。然而,經過基於圖像的多樣化處理後,排序結果開始涵蓋更多不同方面(如面料、剪裁和圖案)。以下是先前多色亨利領 T 恤裙的範例:

現在讓我們看看多樣化如何影響搜尋結果,使用文字嵌入搜尋並結合圖像嵌入作為多樣化重排序器:

排序結果源自文字搜尋,但在前五個示例中開始涵蓋更多不同的「面向」。這達到了類似於平均嵌入的效果,但無需實際進行平均。
然而,這確實需要付出代價:我們必須在檢索前 k 個結果後應用額外的聚類步驟,這會增加幾毫秒的時間,具體取決於初始排名的大小。此外,確定 k-means 聚類的 k 值需要一些啟發式猜測。這就是我們為了改善結果多樣性所需付出的代價!
tag結論
jina-clip-v1 通過在單一高效模型中統一文字和圖像模態,有效地彌合了文字和圖像搜尋之間的差距。我們的實驗表明,其處理更長、更複雜的文字輸入以及圖像的能力,與傳統 CLIP 模型相比,提供了更優越的搜尋性能。
我們的測試涵蓋了各種方法,包括文字與描述匹配、圖像匹配和平均嵌入。結果一致表明,結合文字和圖像嵌入產生了最佳效果,同時提高了準確性和搜尋結果的多樣性。我們還發現,使用圖像嵌入作為「視覺重排序器」可以在保持相關性的同時提高結果的多樣性。
這些進步對於用戶使用文字描述和圖像進行搜尋的真實應用場景有重要影響。通過同時理解這兩種類型的數據,jina-clip-v1 簡化了搜尋流程,提供更相關的結果,並實現更多樣化的產品推薦。這種統一的搜尋功能不僅限於電子商務,還能惠及媒體資產管理、數位圖書館和視覺內容策展,使跨不同格式的相關內容更容易被發現。
雖然 jina-clip-v1 目前僅支援英語,但我們正在開發 jina-clip-v2。承襲 jina-embeddings-v3 和 jina-colbert-v2 的發展,這個新版本將是支援 89 種語言的最先進多語言多模態檢索器。這次升級將為不同市場和行業的搜尋與檢索任務開啟新的可能性,使其成為電子商務、媒體等全球應用的更強大嵌入模型。





