




在多語言模型中,其中一個主要挑戰是「語言差距」— 一種不同語言中相同意思的短語沒有如預期般緊密對齊或聚集的現象。理想情況下,一種語言的文本與另一種語言的等效文本應該有相似的表示 — 也就是說,它們的嵌入向量應該非常接近 — 從而讓跨語言應用能夠在不同語言的文本上以相同方式運作。然而,模型往往會微妙地表示文本的語言,造成「語言差距」,導致跨語言性能不理想。
在這篇文章中,我們將探討這種語言差距以及它如何影響文本嵌入模型的性能。我們使用 jina-xlm-roberta 模型和最新的 jina-embeddings-v3 進行了實驗,評估同一語言中釋義以及不同語言對之間翻譯的語義對齊情況。這些實驗揭示了在不同訓練條件下,具有相似或相同含義的短語如何聚集在一起。

我們還實驗了改善跨語言語義對齊的訓練技術,特別是在對比學習過程中引入平行多語言數據。在本文中,我們將分享我們的見解和結果。
tag多語言模型訓練創造和減少語言差距
文本嵌入模型的訓練通常包含兩個主要部分的多階段過程:
- 遮罩語言建模(MLM):預訓練通常涉及大量文本,其中一些標記被隨機遮罩。模型被訓練來預測這些被遮罩的標記。這個程序教導模型學習訓練數據中的語言模式,包括可能來自語法、詞彙語義和語用現實世界限制的標記之間的選擇依賴關係。
- 對比學習:在預訓練之後,模型會使用經過策劃或半策劃的數據進行進一步訓練,使語義相似的文本的嵌入向量更接近,並(可選地)將不相似的文本推得更遠。這種訓練可以使用已知或至少可靠估計的語義相似度的文本對、三元組甚至群組。它可能有幾個子階段,這部分過程有多種訓練策略,新的研究經常發表,目前尚未就最佳方法達成共識。
要理解語言差距是如何產生的以及如何縮小它,我們需要了解這兩個階段的作用。
tag遮罩語言預訓練
文本嵌入模型的一些跨語言能力是在預訓練期間獲得的。
同源詞和借用詞使模型能夠從大量文本數據中學習一些跨語言語義對齊。例如,英文單詞 banana 和法文單詞 banane(以及德文 Banane)在拼寫上足夠相似且使用頻繁,使得嵌入模型可以學習到看起來像「banan-」的詞在不同語言中有相似的分佈模式。它可以利用這些信息來學習,在某種程度上,其他跨語言間看起來不相同的詞也有相似的含義,甚至可以理解一些語法結構是如何被翻譯的。
然而,這種學習是在沒有明確訓練的情況下發生的。
我們測試了 jina-xlm-roberta 模型(jina-embeddings-v3 的預訓練骨幹)來看它在遮罩語言預訓練中學習跨語言等效性的程度如何。我們繪製了一組英語句子翻譯成德語、荷蘭語、簡體中文和日語的二維 UMAP 句子表示。結果如下圖所示:
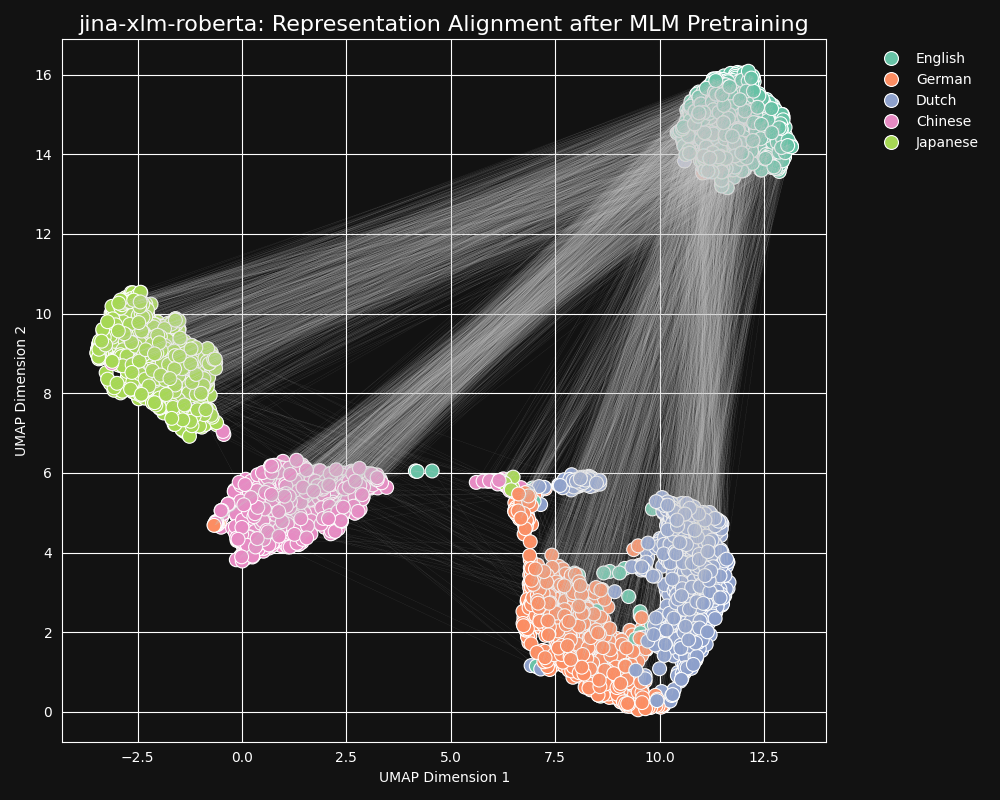
這些句子在
jina-xlm-roberta 嵌入空間中強烈傾向於形成特定語言的聚類,儘管在這個投影中你可以看到一些可能是二維投影副作用的離群值。你可以看到預訓練已經非常強烈地將同一語言的句子嵌入聚集在一起。這是一個將高維空間分佈投影到二維的結果,所以德語句子與其英語原文的翻譯仍有可能是最接近的。但它確實表明,英語句子的嵌入可能比起語義完全相同或幾乎相同的德語句子,更接近另一個英語句子。
還要注意德語和荷蘭語形成的聚類比其他語言對更接近。對於這兩種相對密切相關的語言來說,這並不令人驚訝。德語和荷蘭語的相似程度有時甚至可以部分互相理解。
日語和中文也似乎比其他語言更接近。雖然它們之間的關係不同,但書面日語通常使用漢字(漢字),中文稱為「漢字」。日語與中文共享大多數這些書面字符,兩種語言都有許多由一個或多個漢字組成的共同詞彙。從 MLM 的角度來看,這與荷蘭語和德語之間的可見相似性是相同的。
我們可以通過只看兩種語言的兩個句子,以更簡單的方式看到這種「語言差距」:

由於 MLM 似乎自然地按語言將文本聚集在一起,「my dog is blue」和「my cat is red」被聚集在一起,遠離它們的德語對應詞。與先前部落格文章中討論的「模態差距」不同,我們認為這源於語言之間的表面相似性和差異性:相似的拼寫、印刷中相同字符序列的使用,以及可能在形態和句法結構上的相似性 — 常見的詞序和構詞方式。
簡而言之,無論模型在 MLM 預訓練中學習跨語言等效性的程度如何,這都不足以克服按語言聚集文本的強烈偏差。這留下了一個巨大的語言差距。
tag對比學習
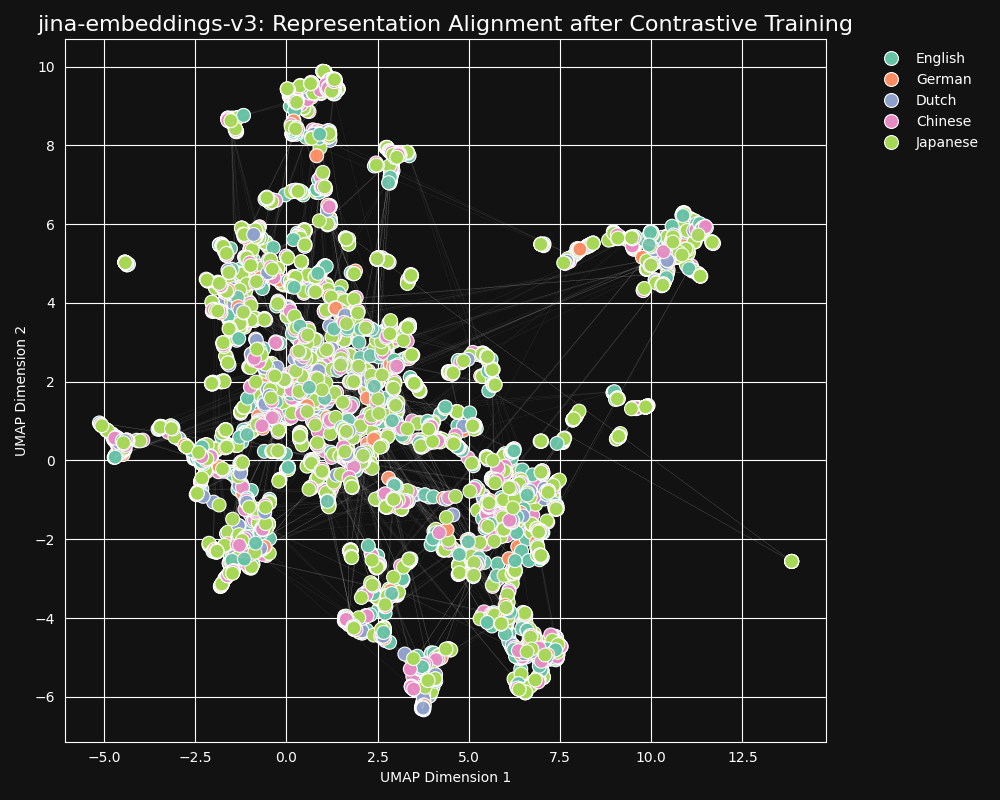
理想情況下,我們希望嵌入模型對語言無差別,只在其嵌入中編碼一般含義。在這樣的模型中,我們將看不到按語言聚集的情況,也不會有語言差距。一種語言的句子應該與其良好的翻譯非常接近,而與其他意思不同的句子相距較遠,即使是同一語言,如下圖所示:

MLM 預訓練無法實現這一點,所以我們使用額外的對比學習技術來改善嵌入中的語義表示。
對比學習涉及使用已知在含義上相似或不同的文本對,以及其中一對比另一對更相似的三元組。在訓練過程中調整權重以反映文本對和三元組之間的這種已知關係。
我們的對比學習數據集中包含 30 種語言,但 97% 的對和三元組都是在單一語言中,只有 3% 涉及跨語言對或三元組。但這 3% 足以產生戲劇性的結果:嵌入顯示很少語言聚集,且語義相似的文本會產生接近的嵌入,無論它們的語言如何,這在 jina-embeddings-v3 的 UMAP 投影中可以看到。
為了確認這一點,我們在 STS17 資料集上測量了 jina-xlm-roberta 和 jina-embeddings-v3 生成的表示之間的 Spearman 相關性。
下表顯示了不同語言翻譯文本的語義相似性排名之間的 Spearman 相關性。我們取一組英語句子,然後測量它們的 embeddings 與特定參考句子的 embedding 之間的相似度,並按照從最相似到最不相似的順序排序。然後我們將所有這些句子翻譯成另一種語言並重複排序過程。在理想的跨語言 embedding 模型中,這兩個有序列表應該相同,Spearman 相關性應為 1.0。
下面的圖表和表格顯示了我們使用 jina-xlm-roberta 和 jina-embeddings-v3 比較英語與 STS17 基準中其他六種語言的結果。
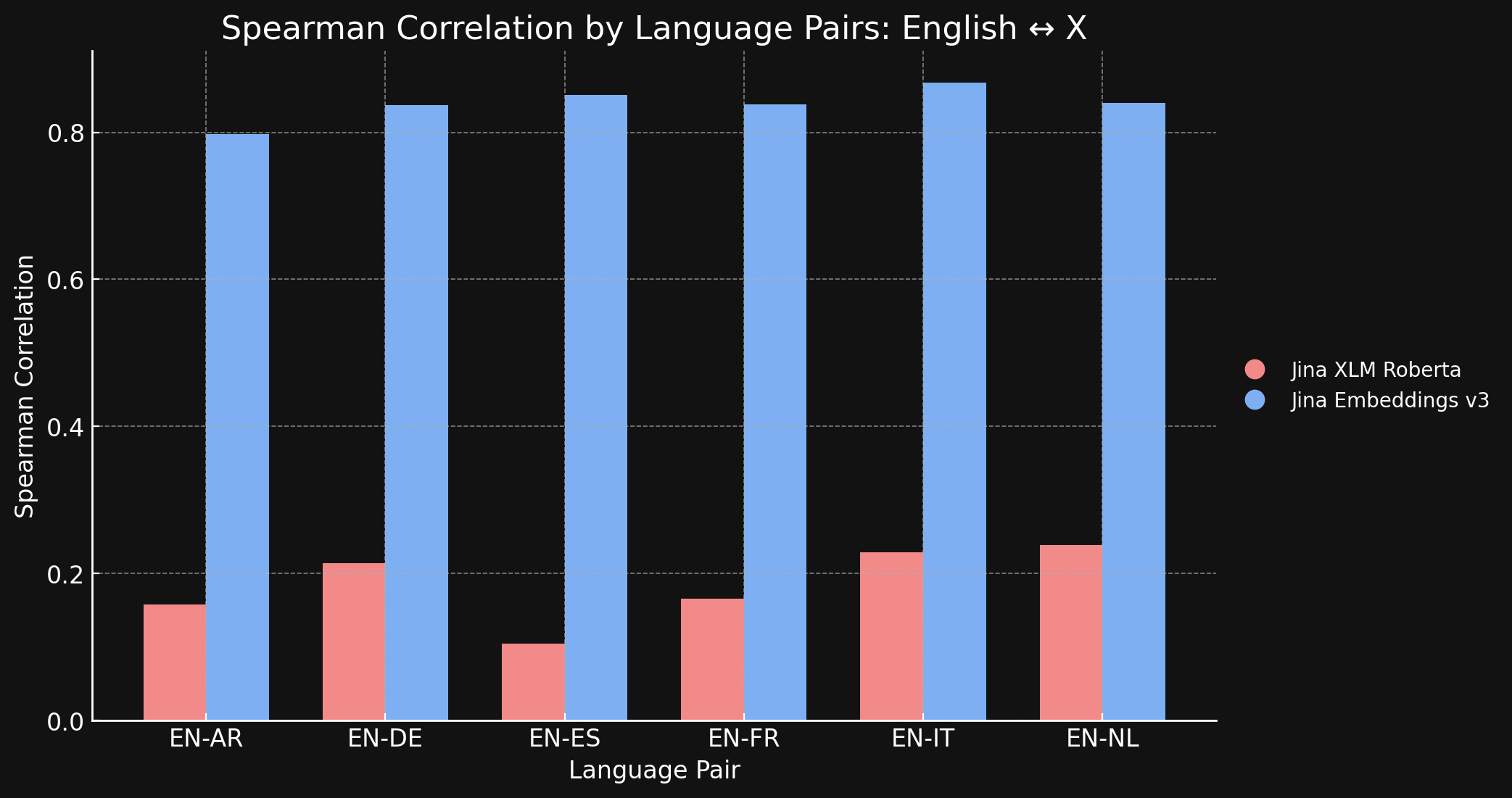
| Task | jina-xlm-roberta |
jina-embeddings-v3 |
|---|---|---|
| English ↔ Arabic | 0.1581 | 0.7977 |
| English ↔ German | 0.2136 | 0.8366 |
| English ↔ Spanish | 0.1049 | 0.8509 |
| English ↔ French | 0.1659 | 0.8378 |
| English ↔ Italian | 0.2293 | 0.8674 |
| English ↔ Dutch | 0.2387 | 0.8398 |
你可以看到對比學習與原始預訓練相比帶來了巨大的差異。儘管在訓練組合中只有 3% 的跨語言數據,jina-embeddings-v3 模型已經學會了足夠的跨語言語義,幾乎消除了它在預訓練中獲得的語言差距。
tag英語對比世界:其他語言能否在對齊方面保持同步?
我們在 89 種語言上訓練了 jina-embeddings-v3,特別關注 30 種使用非常廣泛的書面語言。儘管我們努力建立大規模的多語言訓練語料庫,英語仍然佔我們在對比訓練中使用的數據的近一半。其他語言,包括那些有大量文本材料可用的廣泛使用的全球語言,相比訓練集中龐大的英語數據而言,仍然相對代表性不足。
考慮到英語的這種主導地位,英語表示是否比其他語言的表示更加對齊?為了探索這一點,我們進行了一項後續實驗。
我們建立了一個數據集 parallel-sentences,包含 1,000 對英語文本,一個"錨點"和一個"正例",其中正例文本在邏輯上蘊含於錨點文本。

例如下表中的第一行。這些句子在意義上並不完全相同,但它們具有相容的含義。它們以信息豐富的方式描述了相同的情況。
然後,我們使用 GPT-4 將這些句對翻譯成五種語言:德語、荷蘭語、簡體中文、繁體中文和日語。最後,我們手動檢查以確保質量。
| Language | Anchor | Positive |
|---|---|---|
| English | Two young girls are playing outside in a non-urban environment. | Two girls are playing outside. |
| German | Zwei junge Mädchen spielen draußen in einer nicht urbanen Umgebung. | Zwei Mädchen spielen draußen. |
| Dutch | Twee jonge meisjes spelen buiten in een niet-stedelijke omgeving. | Twee meisjes spelen buiten. |
| Chinese (Simplified) | 两个年轻女孩在非城市环境中玩耍。 | 两个女孩在外面玩。 |
| Chinese (Traditional) | 兩個年輕女孩在非城市環境中玩耍。 | 兩個女孩在外面玩。 |
| Japanese | 2人の若い女の子が都市環境ではない場所で遊んでいます。 | 二人の少女が外で遊んでいます。 |
然後,我們使用 jina-embeddings-v3 對每對文本進行編碼,並計算它們之間的餘弦相似度。下面的圖表和表格顯示了每種語言的餘弦相似度分數分布和平均相似度:
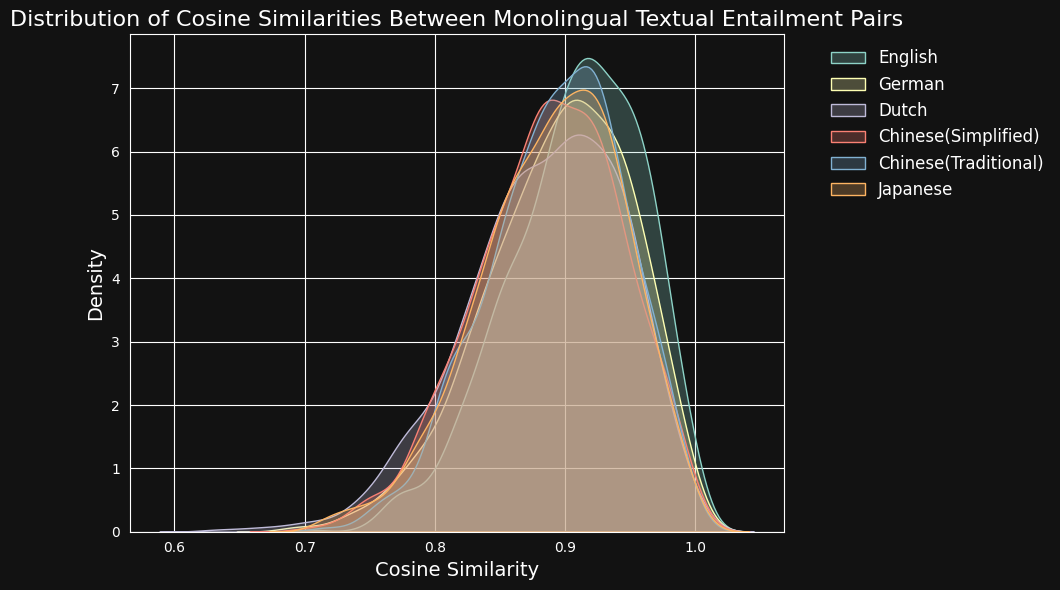
| Language | Average Cosine Similarity |
|---|---|
| English | 0.9078 |
| German | 0.8949 |
| Dutch | 0.8844 |
| Chinese (Simplified) | 0.8876 |
| Chinese (Traditional) | 0.8933 |
| Japanese | 0.8895 |
儘管英語在訓練數據中占主導地位,jina-embeddings-v3 在德語、荷蘭語、日語和兩種形式的中文中識別語義相似性的能力與英語相當。
tag打破語言障礙:超越英語的跨語言對齊
跨語言表示對齊的研究通常著重於包含英語的語言對。這種關注點在理論上可能會掩蓋真實的情況。模型可能只是優化將所有內容儘可能地貼近其英語對應項,而沒有檢驗其他語言對是否得到適當支援。
為了探索這一點,我們使用 parallel-sentences 資料集進行了一些實驗,重點關注超越英語雙語對的跨語言對齊。
下表顯示了不同語言對之間等效文本(即源自相同英語文本的翻譯)的餘弦相似度分佈。理想情況下,所有語言對的餘弦值應為 1 — 即完全相同的語義嵌入。實際上,這種情況不可能發生,但我們期望一個好的模型在翻譯對之間有很高的餘弦值。
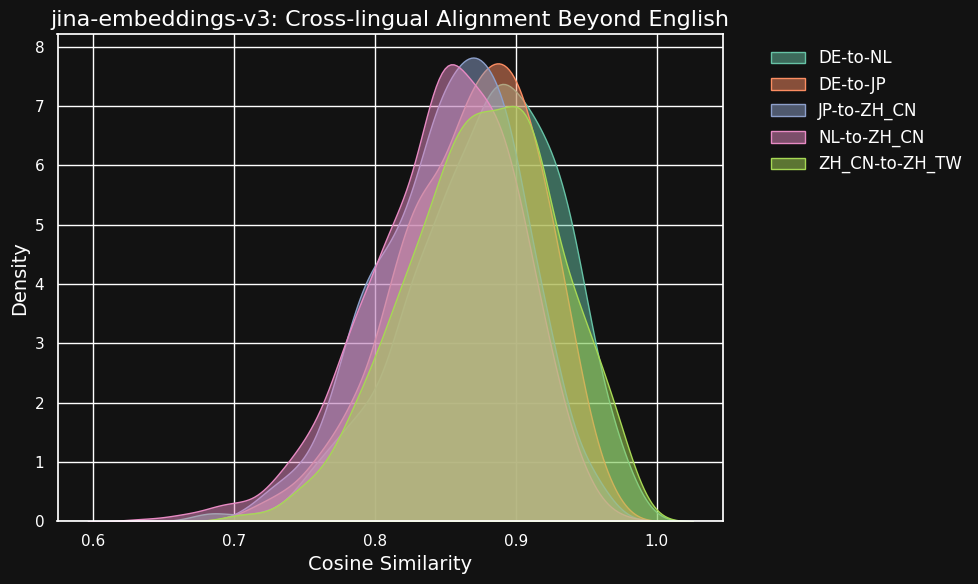
| Language Pair | Average Cosine Similarity |
|---|---|
| German ↔ Dutch | 0.8779 |
| German ↔ Japanese | 0.8664 |
| Chinese (Simplified) ↔ Japanese | 0.8534 |
| Dutch ↔ Chinese (Simplified) | 0.8479 |
| Chinese (Simplified) ↔ Chinese (Traditional) | 0.8758 |
雖然不同語言之間的相似度得分比同一語言中相容文本的得分略低,但仍然非常高。荷蘭語/德語翻譯之間的餘弦相似度幾乎與德語中相容文本之間的相似度一樣高。
這可能並不令人驚訝,因為德語和荷蘭語是非常相似的語言。同樣,這裡測試的兩種中文變體實際上並不是兩種不同的語言,只是同一語言的不同風格形式。但你可以看到,即使是像荷蘭語和中文或德語和日語這樣非常不同的語言對,在語義等效的文本之間仍然表現出很強的相似性。
我們考慮到這些非常高的相似值可能是使用 ChatGPT 作為翻譯器的副作用。為了測試這一點,我們下載了人工翻譯的 TED Talks 英語和德語字幕,並檢查對齊的翻譯句子是否具有相同的高相關性。
結果比我們的機器翻譯數據更強,如下圖所示。
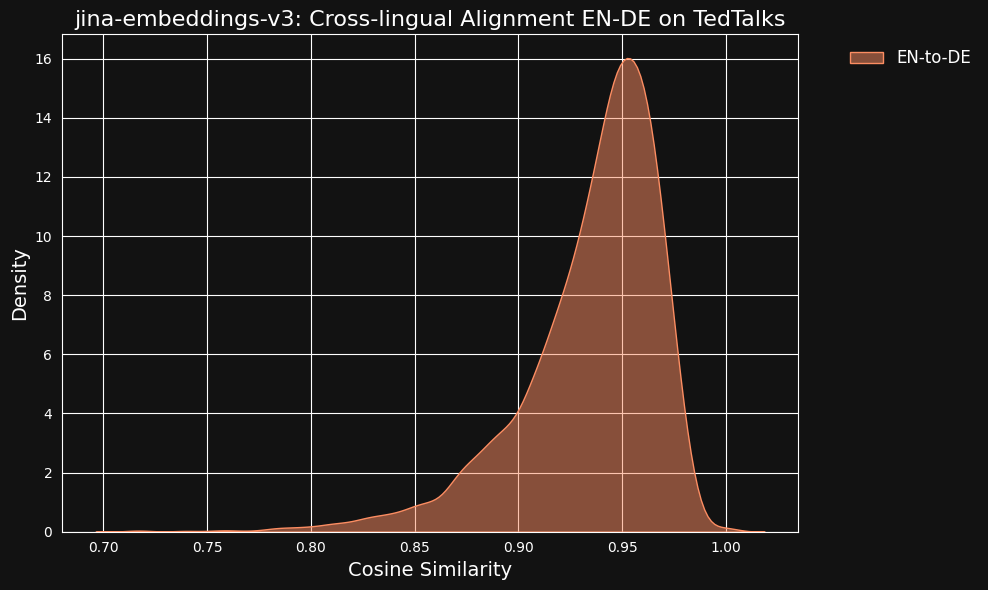
tag跨語言資料對跨語言對齊的貢獻有多大?
語言差距的消失和跨語言性能的高水準似乎與訓練資料中明確的跨語言部分(僅 3%)不成比例。只有 3% 的對比訓練資料明確教導模型如何在語言之間進行對齊。
因此我們進行了一項測試,以查看跨語言是否有任何貢獻。
完全重新訓練不包含任何跨語言資料的 jina-embeddings-v3 對於一個小實驗來說成本太高,所以我們從 Hugging Face 下載了 xlm-roberta-base 模型,並使用我們訓練 jina-embeddings-v3 時使用的部分資料進行對比學習。我們專門調整了跨語言資料的數量以測試兩種情況:一種完全沒有跨語言資料,另一種有 20% 的語言對是跨語言的。下表顯示了訓練的元參數:
| Backbone | % Cross-Language | Learning Rate | Loss Function | Temperature |
xlm-roberta-base without X-language data | 0% | 5e-4 | InfoNCE | 0.05 |
xlm-roberta-base with X-language data | 20% | 5e-4 | InfoNCE | 0.05 |
然後,我們使用來自 MTEB 的 STS17 和 STS22 基準測試以及斯皮爾曼相關係數評估了兩個模型的跨語言性能。結果如下:
tagSTS17
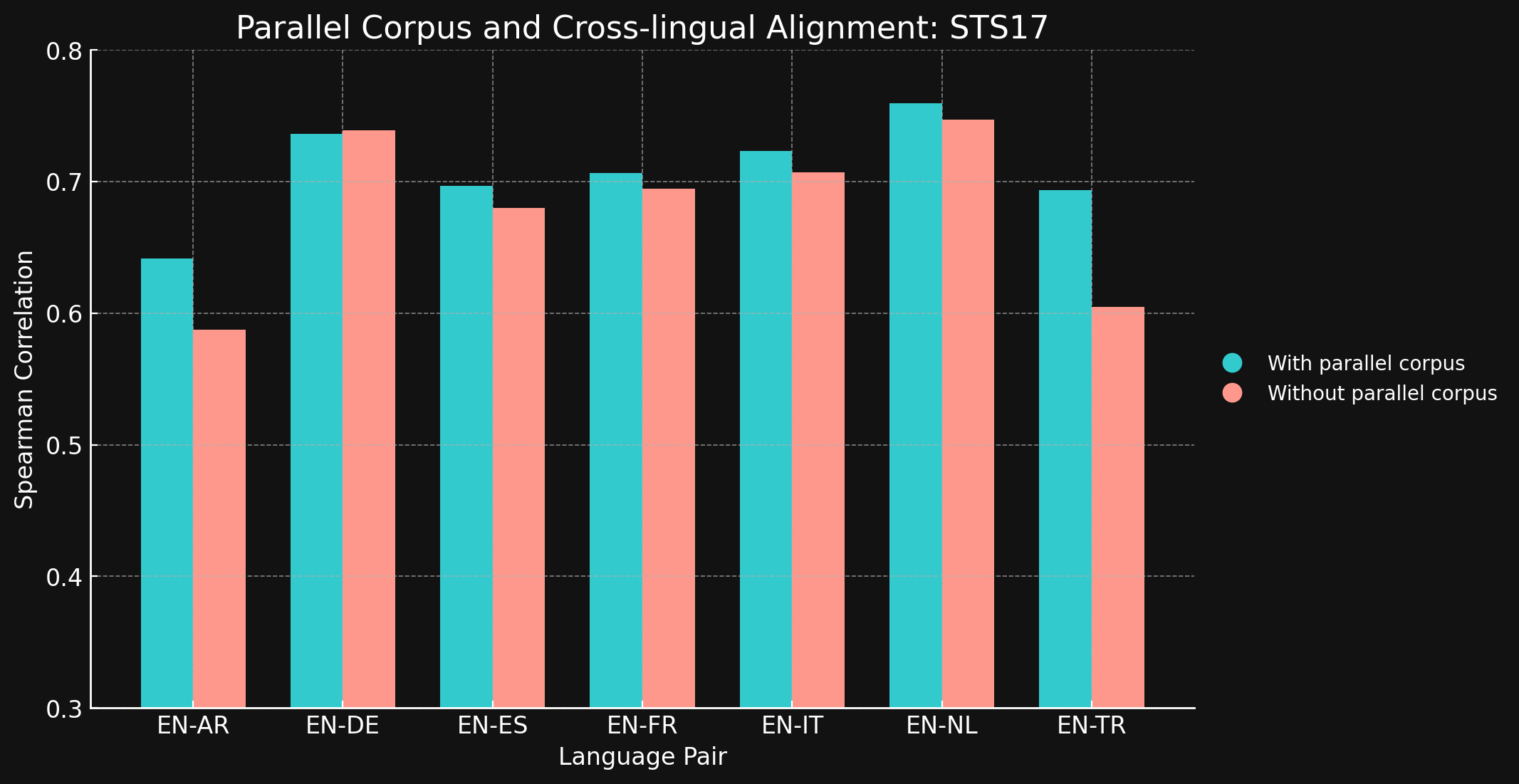
| Language Pair | With parallel corpora | Without parallel corpora |
| English ↔ Arabic | 0.6418 | 0.5875 |
| English ↔ German | 0.7364 | 0.7390 |
| English ↔ Spanish | 0.6968 | 0.6799 |
| English ↔ French | 0.7066 | 0.6944 |
| English ↔ Italian | 0.7232 | 0.7070 |
| English ↔ Dutch | 0.7597 | 0.7468 |
| English ↔ Turkish | 0.6933 | 0.6050 |
tagSTS22
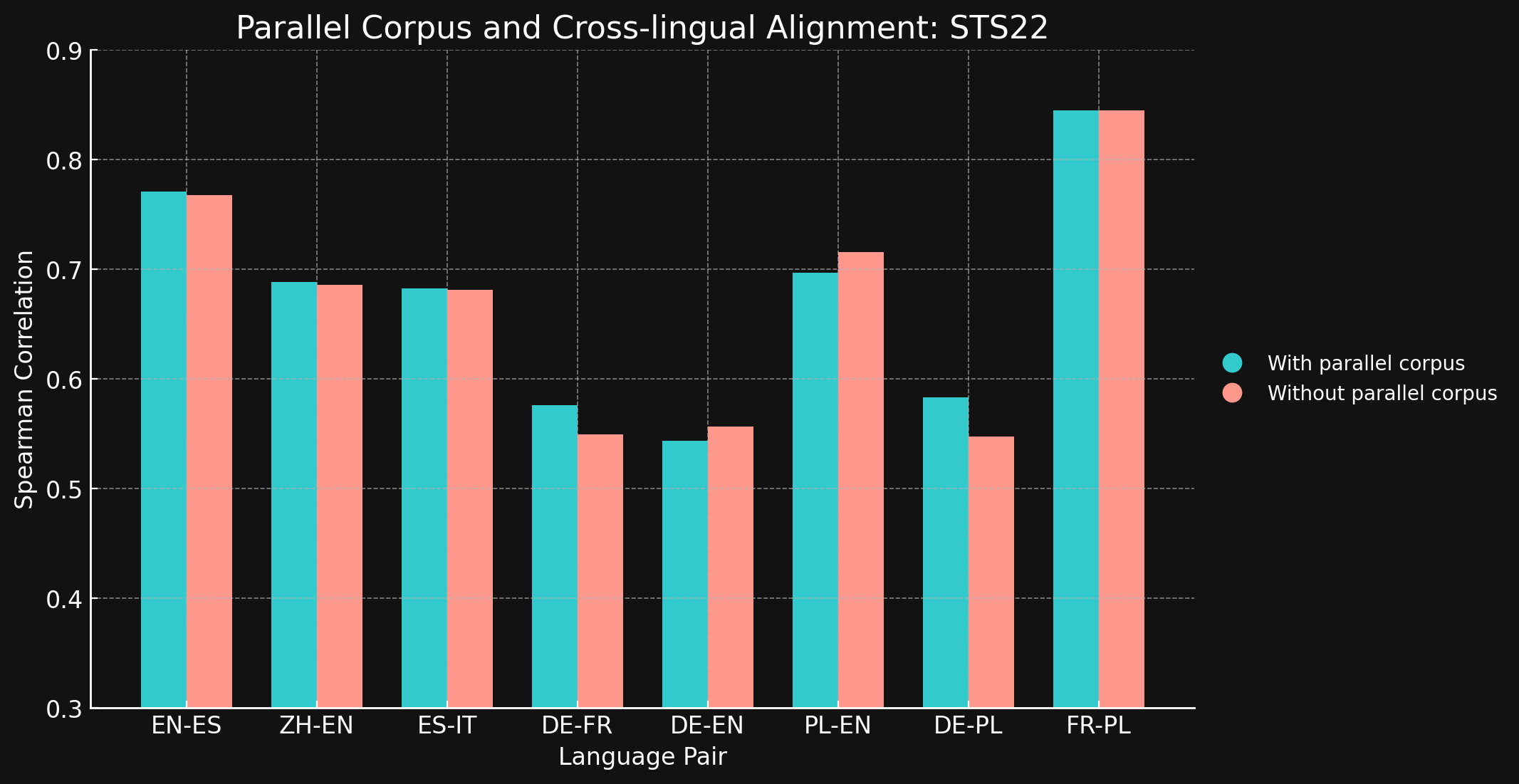
| 語言對 | 使用平行語料庫 | 不使用平行語料庫 |
| English ↔ Spanish | 0.7710 | 0.7675 |
| Simplified Chinese ↔ English | 0.6885 | 0.6860 |
| Spanish ↔ Italian | 0.6829 | 0.6814 |
| German ↔ French | 0.5763 | 0.5496 |
| German ↔ English | 0.5439 | 0.5566 |
| Polish ↔ English | 0.6966 | 0.7156 |
| German ↔ English | 0.5832 | 0.5478 |
| French ↔ Polish | 0.8451 | 0.8451 |
令我們驚訝的是,對於我們測試的大多數語言對來說,跨語言訓練數據幾乎沒有帶來任何改進。雖然無法確定在使用更大數據集的完整訓練模型中是否依然如此,但這確實證明了顯式的跨語言訓練並沒有增加太多價值。
不過,需要注意的是 STS17 包含了英語/阿拉伯語和英語/土耳其語對。這兩種語言在我們的訓練數據中的代表性都相對較低。我們使用的 XML-RoBERTa 模型在預訓練數據中,阿拉伯語僅佔 2.25%,土耳其語僅佔 2.32%,遠低於我們測試的其他語言。在這個實驗中使用的小型對比學習數據集中,阿拉伯語僅佔 1.7%,土耳其語僅佔 1.8%。
這兩個語言對是測試中唯一使用跨語言數據訓練能夠產生明顯差異的語言對。我們認為,對於在訓練數據中代表性較低的語言,顯式跨語言數據可能更有效,但在得出結論之前需要進行更多探索。跨語言數據在對比訓練中的作用和效果是 Jina AI 正在積極研究的領域。
tag結論
傳統的語言預訓練方法(如遮蔽語言建模)會留下"語言差距",導致不同語言中語義相似的文本無法像應有的那樣緊密對齊。我們已經證明,Jina Embeddings 的對比學習方案在減少或甚至消除這種差距方面非常有效。
為什麼這種方法有效,其原因尚不完全清楚。我們在對比訓練中使用了顯式的跨語言文本對,但數量很少,而且它們在確保高質量跨語言結果方面實際發揮了多大作用還不清楚。我們嘗試在更受控的條件下展示明確效果,但並未得到明確的結果。
然而,很明顯 jina-embeddings-v3 已經克服了預訓練中的語言差距,使其成為多語言應用的強大工具。它已經可以用於任何需要跨多種語言保持相同強大性能的任務。
您可以通過我們的 Embeddings API(提供一百萬個免費 token)或通過 AWS 或 Azure 使用 jina-embeddings-v3。如果您想在這些平台之外或在公司內部使用它,請記住它是在 CC BY-NC 4.0 許可下授權的。如果您對商業使用感興趣,請聯繫我們。
