



近期關於 AI 公司掠奪網路上所有資料的危險性,以及他們是否有「許可」這樣做的議題引發了廣泛討論。我們稍後會討論「許可」這個問題 —— 我們用引號標示這個詞是有原因的。但當開放網路已被掏空、內容提供者都鎖上了大門、幾乎沒有新資料可供抓取時,這對 LLM 意味著什麼?
tagAI 爬蟲的危險性
AI 公司將網際網路當作隨意取用的資料自助餐,完全不顧及基本禮儀。看看 Runway 違反 YouTube 服務條款抓取影片來訓練他們的模型,Anthropic 每天對 iFixit 發出一百萬次請求,以及 紐約時報因版權作品的使用而起訴 OpenAI 和 Microsoft。
試圖在 robots.txt 或服務條款中阻止爬蟲其實毫無意義。不在意規則的爬蟲依然會爬取,而較為謹慎的反而會被擋住。爬蟲根本沒有遵守規則的動機。我們可以從 Data Provenance Initiative 最近的一篇論文中看到這種情況:
這不只是一個抽象的問題 —— iFixit 損失了金錢並耗費 DevOps 資源。ReadTheDocs 在一個月內因為濫用性爬蟲產生超過 5,000 美元的頻寬費用,單日流量甚至達到近 10 TB。如果你經營一個網站並遇到不遵守規則的爬蟲,這可能會導致網站無法運作。
那麼,網站該怎麼辦?如果 AI 公司不遵守規則,可以預期付費牆會增加,免費內容會減少。開放網路已不復存在。剩下的只有付費模式。
tag爬取是否合法?
爬取有問題嗎?有。它合法嗎?也是。網路爬取在美國、歐盟、日本、韓國和加拿大都是合法的。似乎沒有任何國家有專門針對這種行為的法律,但世界各地的法院普遍認同,使用自動化方式訪問任何人都可以看到的網站,並製作其內容的私人副本是合法的。
有人認為,在網頁上或 robots.txt 檔案中放置某些聲明,就可以禁止爬取或其他合法使用其網站及內容的行為。這其實並不管用。這類聲明沒有法律效力,而 robots.txt 只是一個 IETF 慣例,沒有法律約束力。如果沒有某種確認行為,至少要點擊標示「我接受服務條款」的按鈕,你無法對網站訪客施加條件,即使有了這樣的確認,這些條件 通常也無法在法律上執行。
 Joshua J. Kaufman
Joshua J. Kaufman然而,雖然爬取是合法的,但仍有一些限制:
- 可能降低他人使用網站體驗的行為,如爬蟲過於頻繁或速度過快,在極端情況下可能會面臨民事甚至刑事後果。
- 許多國家都有法律將未經授權的電腦存取行為定為犯罪。如果網站的某些部分明顯不是供一般大眾訪問的,爬取這些內容可能是違法的。
- 許多國家都有法律規定,規避反複製技術是違法的。如果網站採取措施防止你下載某些內容,你強行爬取可能觸法。
- 具有明確服務條款,且要求你確認接受的網站可以禁止爬取,如果你這樣做他們可以提起訴訟,但結果不一定。
在美國,沒有明確的爬取相關法律,但試圖利用 1986 年的 電腦詐欺和濫用法案 來禁止它的做法都失敗了,最近一次是 2019 年第九巡迴法院的 hiQ Labs 訴 LinkedIn 案。美國法律很複雜,有許多法院制定的區分標準,以及州和聯邦巡迴法院的管轄系統,這意味著除非最高法院做出裁決,否則不一定是最終定案。(有時即使最高法院裁決也不是最終的。)
歐盟也沒有特定的爬取法律,但這一直是一個普遍且未受挑戰的做法。2019 年歐盟版權指令中的文本和數據挖掘條款強烈暗示爬取通常是合法的。
最大的法律問題不在於爬取行為本身,而是爬取之後的使用。你爬取的網路資料仍受版權保護。你可以保留個人副本,但如果沒有相關許可,不能重新發布或轉售,否則可能會遇到法律問題。
大規模網路爬取幾乎總是意味著複製各種資料保護和隱私法律中定義的「個人資料」。歐洲 GDPR(一般資料保護條例)將「個人資料」定義為:
任何與已識別或可識別的自然人(「資料主體」)相關的資訊;可識別的自然人是指可以直接或間接地被識別的人,特別是通過參考諸如姓名、身份證號碼、位置資料、線上識別碼,或該自然人的一個或多個與其身體、生理、基因、心理、經濟、文化或社會身份有關的特定因素;
[GDPR,第 4.1 條]
如果你擁有任何居住在歐盟或在歐盟境內活動的人的個人資料,你就需要承擔 GDPR 下的法律責任。其範圍如此廣泛,以至於你應該假設這適用於任何大型資料收集。不管是你收集的還是別人收集的資料,只要你現在擁有它,你就要對它負責。如果你不履行 GDPR 義務,無論你住在哪個國家或資料儲存或處理在哪裡,歐盟都可以懲罰你。
加拿大的 PIPEDA(個人資訊保護和電子文件法)類似於 GDPR。日本的 APPI(個人資訊保護法)涵蓋了許多相同的領域。英國在離開歐盟時將 GDPR 的大部分要素納入其國內法律,除非後來修改,否則這些法律仍然有效。
美國在聯邦層面沒有類似的資料保護法,但 CCPA(加州消費者隱私法)與 GDPR 有類似的條款,適用於擁有加州人民或活動相關資料的情況。
大多數發達國家都有資料保護法,至少在某些方面限制你對從網路收集的大量資料的使用。世界各地大多數與爬取有關的法律訴訟都是關於資料如何使用,而不是如何收集。
所以,網路爬取幾乎總是合法的。複雜的是接下來的事情。
tag使用爬取資料訓練 AI 是否合法?
可能是的。
在幾乎所有實際情況下,網路爬取都會包含受版權保護的內容。真正的問題是:未經所有者許可,你能使用受版權保護的內容來訓練 AI 嗎?
有許多個別的法律問題尚未完全解決,但:
- 在歐洲,2019 年歐盟版權指令第 4 條似乎使其合法化,但有一些限制條件。
- 在日本,2018 年修訂的著作權法第 30 條第 4 項被解釋為允許在未經許可的情況下使用受版權保護的作品來訓練 AI。
- 在美國,目前沒有法律明確規範這種情況,但多年來人們一直認為對受版權保護材料進行統計分析是合法的,即使最終產品用於商業用途。雖然 Authors Guild, Inc. v. Google, Inc. 和 Authors Guild, Inc. v. HathiTrust 這兩個訴訟案件並未特別針對 AI,但它們大大擴展了美國法律下「合理使用」的範圍,很難看出 AI 訓練如何會是非法的。美國法律系統並未給出明確答案,目前有幾個案例正在法院審理中以測試這一結論。
一些較小的司法管轄區也已確定這是合法的,據我所知,迄今為止還沒有任何地方認定這是非法的。
歐洲版權法允許受版權保護的數據所有者通過「適當方式」表明限制其作品用於 AI 訓練。目前還沒有關於他們應該如何做到這一點的指導。
日本版權法限制使用受版權保護的材料,如果這種使用可能「不合理地損害版權所有者的利益」。這通常表明,版權持有人必須證明特定的 AI 模型如何降低了他們作品的經濟價值才能提出訴訟。
我們應該注意到,Google、Microsoft、OpenAI、Adobe 和 Shutterstock 已承諾為使用其生成式 AI 產品而面臨版權法律挑戰的用戶提供賠償保證。這強烈表明他們的律師認為他們的做法在美國法律下是合法的。
tag貪婪抓取對 AI 的影響
AI 抓取熱潮正在將網路變成數位狂野西部。這些爬蟲將 robots.txt 視為無物,用無盡的請求轟炸像 iFixit 這樣的網站。這不僅令人煩惱 - 還可能破壞網路運作,迫使我們重新思考開放互聯網如何運作。或者在不久的將來可能無法運作。僅從經濟和社會角度來看,有許多事情可能會改變:
信任崩潰:這場 AI 饕餮盛宴可能導致網路的大規模信任崩潰。想像一個未來,每個網站都用懷疑的眼光迎接你,在你瀏覽內容之前必須證明你是人類。我們談論的是更多的驗證碼、更多的登入牆、更多的「點選所有交通號誌」測試。這就像試圖進入一家地下酒吧,但不是需要秘密密碼,而是需要說服門衛你不是一台非常聰明的機器。
人工內容減少:內容創作者已經對自己的作品被盜用感到警惕,開始設防。我們可能會看到付費牆、會員專屬區域和內容鎖定的激增。自由瀏覽和學習的日子可能會成為一種懷舊的記憶,就像撥號上網的聲音或 AIM 離線留言一樣。如果普通人都無法訪問,那麼流氓爬蟲就更難進入。
法律案例:可能需要數年甚至數十年才能解決所有與 AI 相關的法律問題。我們已經有了互聯網大約三十年,但今天仍有一些法律問題懸而未決。無論你是對是錯,如果你無法承擔花費數年時間在法庭上找出什麼是允許的什麼是不允許的,你就有需要擔心的事。
小魚破產,大魚更肥:這種抓取狂熱不僅令人煩惱 - 還給網路基礎設施帶來真實的壓力。處理 AI 引起的流量堵塞的網站可能需要升級到更強大的服務器,這並不便宜。較小的網站和有趣的興趣項目可能會因為成本而退出遊戲,留給我們的是一個由那些足夠強大能夠度過風暴或與 AI 公司簽訂授權協議的大玩家主導的網路(和 LLM 訓練數據)。這是一種「富者生存」的場景,可能會使互聯網(和 LLM 知識)變得不那麼多樣化和有趣。通過關閉免費獲取數據的大門,他們可以向 AI 公司收取入場費,或者直接授權給出價最高的競標者。沒有錢?門衛會請你離開。
tagAI 生成的數據能否來救場?
數據搶奪不僅在撼動網站 - 還在為潛在的 AI 知識乾旱做準備。隨著開放網路拉起吊橋,AI 模型將面臨優質新數據匱乏的困境。
這種數據稀缺可能導致 AI 出現嚴重的視野狹隘問題。沒有穩定的新信息流入,AI 模型可能會變成過時知識的回聲室。想像一下問 AI 關於時事的問題,得到的答案聽起來像是去年的 - 或更糟,來自一個事實度假的平行宇宙。
如果人工生成的數據被鎖起來,公司仍然需要從某個地方獲得他們的訓練數據。一個例子是合成數據:由 LLM 創建用來訓練其他 LLM 的數據。這包括廣泛使用的技術,如模型蒸餾和生成訓練數據以補償偏見。

使用合成數據意味著不必為獲取人工生成的數據授權而費盡周折,而這正變得越來越困難。它也有助於平衡 - 互聯網上的很多數據並不能代表真實世界的多樣性。生成合成數據可以幫助使模型更能代表現實(或有時不能)。最後,對於健康和法律用例,合成數據消除了需要對數據進行淨化以刪除個人身份信息的需求。
然而,另一面是未來的模型也將被訓練在你真的不希望用來訓練它們的 AI 生成數據上,即「劣質內容」:低質量的 AI 生成數據,比如一個曾經備受喜愛的科技博客現在以其前員工的名義發布低價值的 AI 生成文章,AI 生成的不太可能的菜譜,如慢燉莫希托和香腸冰淇淋,或者蝦子耶穌接管 Facebook。
由於這比製作優質的手工內容要便宜和容易得多,它正在迅速淹沒互聯網。
根據我們今天看到的情況,AI 生成的內容正在超過可用的人工生成內容。GPT-5 將(部分)基於 GPT-4 創建的數據進行訓練。然後,GPT-6 將基於 GPT-5 創建的數據進行訓練。如此循環往復。
tag模型崩潰及如何避免
使用自己的輸出作為輸入對人類和 LLM 都不好。即使你對使用多少合成數據以及使用什麼類型的數據非常謹慎,你也不能保證你的模型不會變得更差。
對於生成式 AI 模型整體而言,輸出質量和多樣性的下降在實驗中是可測量的,而且發生得相當快。圖像生成模型在幾代之後就會出現異常,而在一篇論文中,一個在維基百科數據上訓練的大語言模型,最初能對提示給出連貫且準確的回應,到了訓練自己輸出的第九代時,就只能重複回應「tailed jackrabbits」這個詞了。
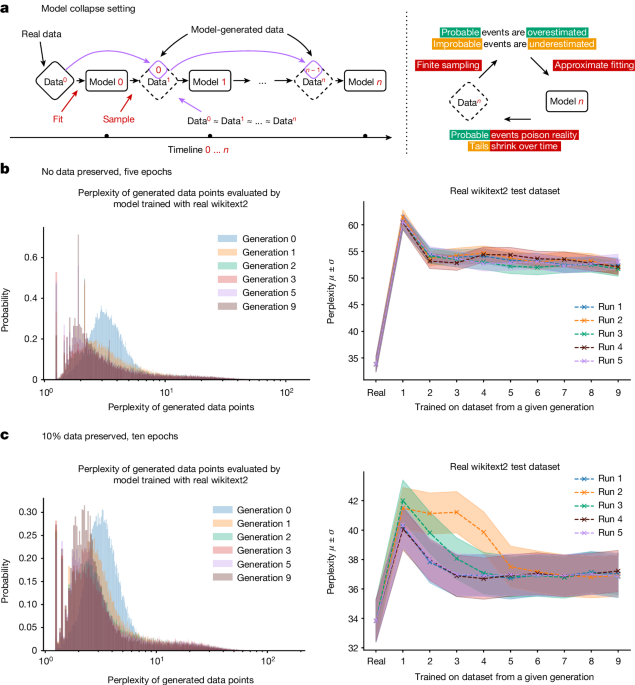
這很容易解釋:AI 模型是其訓練數據的近似。用 AI 模型輸出訓練的 AI 模型是近似的近似。在每個訓練週期中,近似值與「真實」現實世界數據之間的差異會越來越大。
我們稱之為「模型崩潰」。
隨著 AI 生成的數據變得越來越普遍,從互聯網抓取數據來訓練新模型可能會降低模型性能。我們有理由認為,只要真實的人類製作的數據量不減少,我們的模型就不會變得更糟,但也不會變得更好。然而,如果我們無法將 AI 製作的數據與人類製作的數據分離,它們將需要更長時間來訓練。新模型的製作成本會更高,但效果卻沒有提升。
這裡的諷刺意味很濃。AI 對數據的貪婪需求可能會導致數據饑荒。模型自噬失調就像 AI 的瘋牛病:就像餵食牛肉廢料給牛導致了一種新型的寄生性腦部疾病,用越來越多的 AI 輸出來訓練 AI 會導致毀滅性的精神病理。
好消息是 AI 無法取代人類,因為它需要我們的數據。壞消息是它可能會通過破壞自己的數據來源來阻礙自身的成長。
為了避免這種可預見的 AI 知識饑荒,我們需要重新思考如何訓練和使用 AI 模型。我們已經看到了像檢索增強生成這樣的解決方案,它試圖避免使用 AI 模型作為事實信息的來源,而是將它們視為評估和重組外部信息源的工具。另一條前進的道路是通過專業化,我們將模型調整為執行特定類別的任務,使用聚焦於狹窄領域的精選訓練數據。我們可以用專業 AI 取代號稱通用的模型(如 ChatGPT):LawLLM、MedLLM、MyLittlePonyLLM 等。
還有其他可能性,很難說研究人員會發現什麼新技術。也許有更好的方法來生成合成數據,或者有方法從更少的數據中獲得更好的模型。但是沒有保證更多的研究就能解決問題。
最終,這個挑戰可能會迫使 AI 社群變得更有創造力。畢竟,需求是發明之母,而一個數據匱乏的 AI 世界可能會激發一些真正創新的解決方案。誰知道呢?AI 的下一個重大突破可能不是來自更多的數據,而是來自於弄清楚如何用更少的數據做更多的事。
tag如果只有大公司能負擔得起抓取數據,會發生什麼?
對於今天的許多人來說,互聯網就是 Facebook、Instagram 和 X,通過他們手中握著的黑色玻璃矩形來瀏覽。它是同質化的、「安全的」,並由決定你看到什麼(和誰)以及看不到什麼的守門人(通過政策和他們的算法)控制。
以前並不是這樣的。就在幾十年前,我們有用戶生成的博客、獨立網站和更多內容。在八十年代,有數十種競爭的操作系統和硬體標準。但到了 2010 年代,Apple 和 Microsoft 已經勝出,開始了同質化的趨勢。
我們在網頁瀏覽器、智能手機和社交媒體網站上看到了同樣的情況。我們從新想法和多樣性的爆發開始,然後大玩家壟斷了局面,使其他人難以參與競爭。
話雖如此,儘管那些玩家確實擁有壟斷地位,一些小玩家還是偷偷溜了進來。(例如 Linux 和 Firefox)。不過「弱者崛起」這種事在 LLM 領域不太可能發生。當小玩家缺乏獲取多樣化和最新訓練數據的財力時,他們就無法創建高質量的模型。沒有這些,他們如何維持業務?
即使更廣泛的網絡在緊縮,巨頭們仍有資源讓他們的 AI 模型持續獲取新鮮信息。同時,較小的玩家和初創公司只能在數據桶底部搜刮,努力用陳舊的殘渣餵養他們的算法。這種知識差距可能會滾雪球式擴大。隨著數據富豪在洞察力和能力上變得更富有,數據貧困者可能會進一步落後,他們的 AI 日復一日變得過時且缺乏競爭力。這不僅關乎誰擁有最閃亮的 AI 玩具 - 而是關乎誰能塑造技術、商業,甚至我們獲取信息的方式的未來。我們正在面對一個未來,少數科技巨頭可能掌握著最先進 AI 王國的鑰匙,而其他人則被困在數字黑暗時代中窺視。
考慮到有這麼多可授權的優質內容,不太可能會有一家大公司獨攬所有授權,就像早期的 Netflix 那樣。還記得嗎?你只需訂閱一個服務就能看到你夢想中的所有節目。如今,節目分散在 Hulu、Netflix、Disney+ 和不知道現在叫什麼名字的 HBO Max 上。有時候你喜歡的節目可能會憑空消失。這可能就是 LLM 的未來:Google 優先訪問 Reddit,而OpenAI 獲得訪問 Financial Times 的權限。iFixit?那些數據就這樣消失了,只是作為一些塵封的嵌入存在,再也不會更新。與其說是一個模型統治所有,我們可能會看到能力的分散和變化,因為授權權利在 AI 供應商之間來回切換。
tag結論
不論我們喜歡與否,抓取資料的行為將會持續存在。內容提供者已經在建立障礙以限制存取,只向那些能夠負擔授權內容的人開放。這嚴重限制了任何一個 LLM 可以學習的資源,同時,較小的公司也因為無法負擔高額內容的競價而被排除在外,剩下的資源則被科技巨頭的 LLM 瓜分。這就像是 Netflix 之後的串流媒體世界重演,只是這次爭奪的是知識。
當可用的人類產生資料在減少的同時,AI 生成的「垃圾內容」卻在激增。用這些內容來訓練模型可能導致改進速度放緩,甚至模型崩潰。唯一的解決方法是跳出框架思考——這正是新創公司憑藉其創新和顛覆文化最擅長的。然而,那些只授權給大公司的資料,恰恰是這些新創公司賴以生存的命脈。
通過限制對資料的公平存取,這些超級企業不僅扼殺了競爭——他們也正在扼殺 AI 本身的未來,扼殺那些可能帶領我們超越這個潛在數位黑暗時代的創新。
AI 革命不是未來,AI 就是現在。用 William Gibson 的話來說:「未來已經來臨,只是分配不均。」而且這種分配不均可能會變得更加嚴重。
