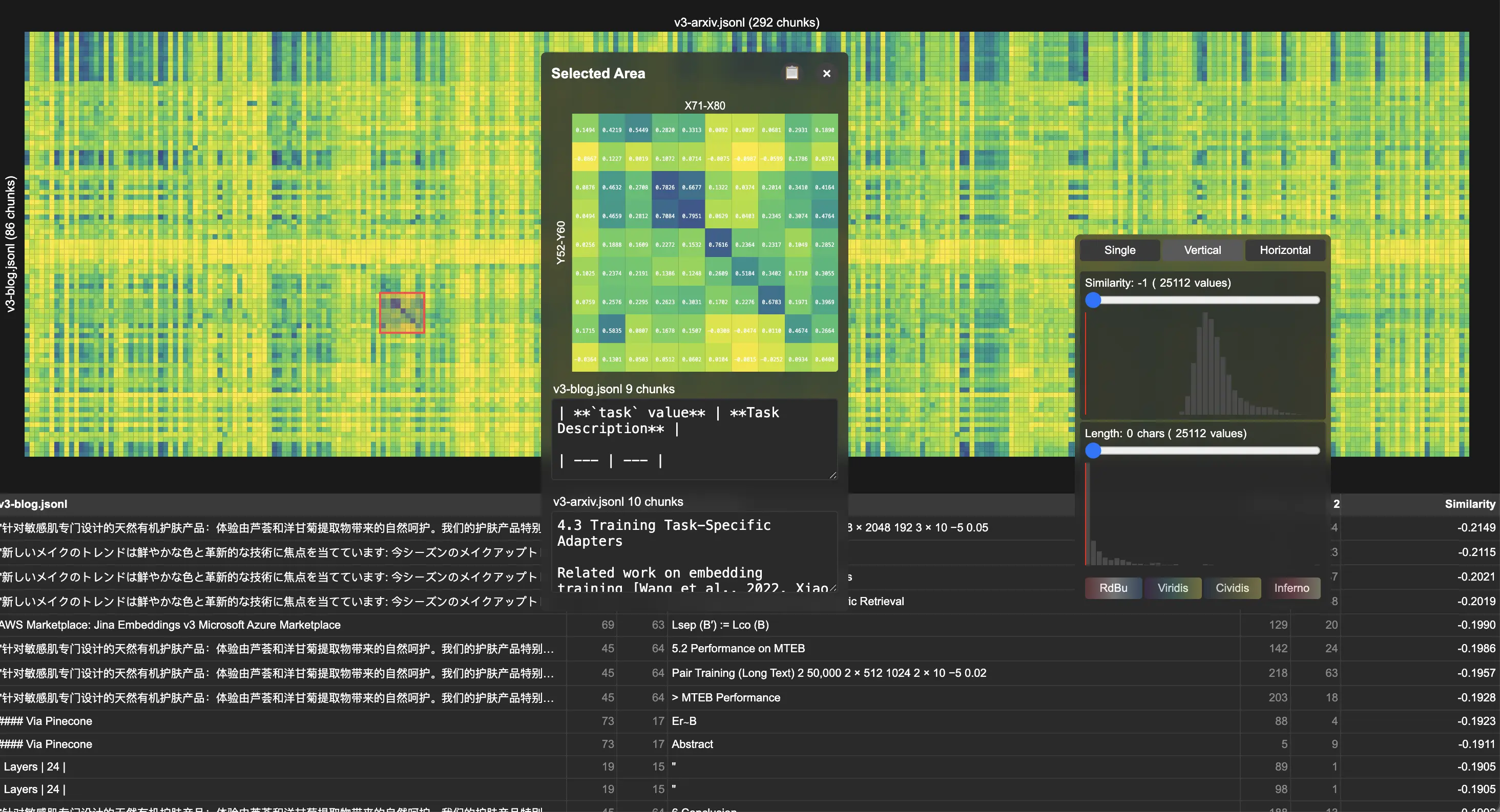


人們問我們一個有趣的問題:「你們如何檢查 向量模型 (Embeddings) 的氛圍 (vibe-check)?」 當然,有 MTEB 可以在公開基準上進行嚴肅和量化的評估,但是對於開放領域或新問題,您該怎麼辦? 今天,我們想分享一個我們用於除錯和視覺化的小型內部工具。 您可以將其稱為我們的氛圍測試工具包。 我們稱它為 Correlations,它在 GitHub 上是開源的。
tag設計
Correlations 產生互動式熱圖,其中每個單元格顯示兩個片段之間的餘弦相似度,無論它們是來自相同或不同文件集合、模態、超參數還是模型。 它支援多種互動:
- 懸停檢查:個別單元格對的原始文字/圖像和相似度分數
- 區域選擇:互動式區域選擇,用於專注分析相似度模式
- 閾值過濾:相似度分數和文字長度過濾器,以減少雜訊
該工具透過兩階段管道運作:
npm run embed:使用具有可配置分塊策略(換行符、標點符號、基於字元或正則表達式模式)的 Jina 向量模型 (Embeddings) APInpm run corr:基於瀏覽器的 UI,提供具有即時互動性的相關性熱圖
若要開始使用:
npm install
export JINA_API_KEY=your_jina_key_here
npm run embed -- https://jina.ai/news/jina-embeddings-v3-a-frontier-multilingual-embedding-model -o v3-blog.jsonl -t retrieval.query
npm run embed -- https://arxiv.org/pdf/2409.10173 -o v3-arxiv.jsonl -t retrieval.passage
npm run corr -- v3-blog.jsonl v3-arxiv.jsonlJINA_API_KEY 用於在必要時從 URL 嵌入和讀取內容,當然支援從本機文字檔案讀取。 您也可以攜帶自己的 向量模型 (Embeddings),並執行 npm run corr 僅用於視覺化,在這種情況下,您不需要 JINA_API_KEY。 該工具支援自相關分析(在單個集合中)和互相關分析(在兩個集合之間)。
tag使用案例
tag內容去重和對齊分析
我們透過分析我們的 jina-embeddings-v3 出版物來展示該工具的實用性。 透過比較學術論文和版本說明,視覺化顯示相關性熱圖中不同的對角線模式,表明文件之間存在強烈的區塊到區塊對齊。 詳細檢查顯示了系統的內容重用,尤其是在描述 LoRA 任務類型的技術章節中。
tag引用和參考驗證
該工具證明對於驗證 檢索增強生成 (retrieval-augmented generation) 系統中的引用準確性非常有用,在這種系統中,驗證檢索到的段落是否確實支持生成的聲明至關重要。 基於相似性的分析是一種強大且直觀的工具,用於探索大型資料集,例如,透過按相似性對項目進行分組來揭示模式。
tag分塊策略探索
透過檢視不同方法如何影響文本片段內和片段之間的語義連貫性,可以評估延遲分塊和其他分段策略。視覺化有助於識別延遲分塊效應和最佳分塊邊界,方法是揭示與語義結構一致的相似性模式。
tag跨模態分析
該工具不僅支援文本,還透過 jina-clip-v2 支援圖像向量模型 (Embeddings),從而能夠分析多模態應用程式的文本-圖像相關模式。
tag向量模型視覺化相關研究
當使用高維向量模型 (Embeddings) 時,可解釋性的挑戰尤其嚴峻。向量模型視覺化技術的發展日新月異,不同的方法可以分為:
- 基於降維 (Dimensionality Reduction-Based):使用 PCA、t-SNE、UMAP 等傳統方法,將高維空間投影到 2D/3D
- 基於互動探索 (Interactive Exploration-Based):Parallax 和 TextEssence 等工具,可直接操作和探索
- 特定領域的解決方案 (Domain-Specific Solutions):適用於生物資料的 Clustergrammer 等專用工具
- 直接相似性視覺化 (Direct Similarity Visualization):我們的方法和類似的熱圖方法,可保留完整的關係資訊
| 方法 | 途徑 | 使用案例 |
|---|---|---|
| Correlations | 直接成對相似性熱圖 | 文本相似性除錯、對齊分析 |
| Embedding Projector | PCA、t-SNE 和自訂線性投影 | 互動式視覺化和解釋 |
| Parallax | 用於語義探索的代數公式 | 理解語義關係 |
| TextEssence | 比較語料庫分析 | 歷時分析、語料庫比較 |
| Nomic Atlas | 基於雲端的可擴展視覺化 | 大規模資料集、協作 |
| Clustergrammer | 具有聚類的互動式熱圖 | 高維生物資料 |
| t-SNE | 非線性聚類視覺化 | 模型除錯、混淆識別 |
| UMAP | 局部和全域結構保留 | 中大型資料集、一般分析 |
| PCA | 線性降維 | 初步探索、基準比較 |
tag逐點方法的局限性
現有的視覺化工具主要側重於 2D 空間中的逐點表示,這可能會遺失有關成對關係的重要資訊。此外,大多數工具都是為單個向量模型 (Embedding) 空間分析而設計,而不是為不同來源、模態 (modalities) 或向量模型策略 (embedding strategies)(例如,開啟與關閉延遲分塊)之間的比較評估而設計。
例如,我們最近在 Jina 遇到了兩個使用案例。第一個涉及DeepSearch 中的交叉檢查引文,我們需要將產生的報告與參考資料中的原始摘錄進行比對。第二個是多模態檢索,我們需要在新的未標記資料上驗證圖像-文本和圖像-圖像對齊。在這兩種情況下,我們都需要探索兩個向量模型 (Embeddings) 集合之間的關係。因此,我們使用 Correlations 來了解比對的對齊程度,並驗證最高相關性是否始終對應於正確的比對。
tag結論
除了氛圍檢查之外,correlations 還可以提供對語義關係的更深入見解。作為起點,可以從相關矩陣中提取幾個關鍵統計資訊:
- 矩陣密度 (Matrix Density):高於指定閾值的相關性比例,表示整體語義凝聚力
- 特徵值分佈 (Eigenvalue Distribution):主成分分析揭示了相似性結構中的主導模式
- 矩陣秩 (Matrix Rank):表示相似性關係的有效維度
- 條件數 (Condition Number):衡量數值穩定性和潛在的多重共線性問題
進階分析也可能涉及提取代表連貫語義區域的有意義的子矩陣。從 n 階實矩陣中提取 k 階最大和主子矩陣是一個典型的組合最佳化問題,可以識別相關性最高的片段。






