
最近我研究了 DSPy,這是由 Stanford NLP 團隊開發的前沿框架,旨在以演算法方式優化語言模型 (LM) 的提示詞。在過去三天裡,我對 DSPy 有了一些初步印象和寶貴見解。需要注意的是,我的觀察並非要取代 DSPy 的官方文件。事實上,我強烈建議在閱讀這篇文章之前,至少先閱讀一遍他們的文件和 README。我在這裡的討論反映了我花了幾天時間探索其功能後的初步理解。還有一些進階功能,如 DSPy Assertions、Typed Predictor 和 LM weights tuning,我還沒有深入探索。
 stanfordnlp
stanfordnlp儘管我在 Jina AI 的背景主要集中在搜尋基礎架構上,我對 DSPy 的興趣並不是直接由其在檢索增強生成(RAG)方面的潛力所驅動。相反,我對利用 DSPy 進行自動提示詞調優來解決一些生成任務的可能性感到興趣。
如果你是 DSPy 的新手並尋找易於入門的起點,或者你已經熟悉該框架但覺得官方文件令人困惑或難以理解,這篇文章就是為你而寫的。我也選擇不嚴格遵循 DSPy 的慣用語法,因為這可能會讓新手感到困難。讓我們深入探討吧。
tag我喜歡 DSPy 的地方
tagDSPy 閉環了提示詞工程的循環
DSPy 最令我興奮的是它如何閉環提示詞工程的循環,將原本手動、手工打造的過程轉變為結構化、明確定義的機器學習工作流程:即準備數據集、定義模型、訓練、評估和測試。在我看來,這是 DSPy 最具革命性的方面。
在灣區旅行並與許多專注於 LLM 評估的創業公司創始人交談時,我經常聽到關於指標、幻覺、可觀察性和合規性的討論。然而,這些對話往往沒有進展到關鍵的下一步:有了這些指標之後,我們該怎麼做?調整提示詞中的措辭,希望某些神奇的詞語(例如「我奶奶快死了」)能提升我們的指標,這能被視為一種策略性的方法嗎?這個問題一直沒有得到許多 LLM 評估創業公司的解答,我也無法解決——直到我發現了 DSPy。DSPy 引入了一種清晰的、程式化的方法來基於特定指標優化提示詞,甚至可以優化整個 LLM 管道,包括提示詞和 LLM 權重。
LangChain 的 CEO Harrison 和前 OpenAI 開發者關係主管 Logan 都在Unsupervised Learning Podcast 中表示,2024 年將是 LLM 評估的關鍵一年。正因如此,我認為 DSPy 值得比現在更多的關注,因為 DSPy 提供了這個拼圖中缺失的關鍵部分。
tagDSPy 將邏輯從文字表示中分離
DSPy 令我印象深刻的另一個方面是,它將提示詞工程轉化為一個可重現且與 LLM 無關的模組。為了實現這一點,它將邏輯從提示詞中抽離出來,在邏輯和文字表示之間創建了明確的關注點分離,如下圖所示。
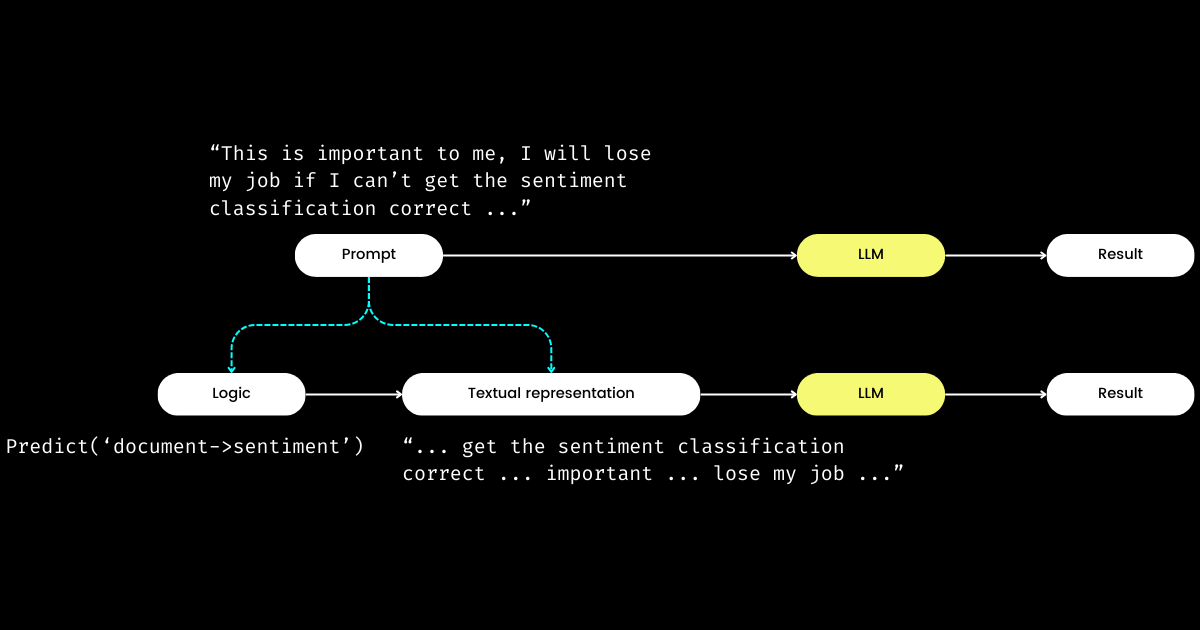
dspy.Module)和其文字表示。邏輯是不可變的、可重現的、可測試的且與 LLM 無關。文字表示只是邏輯的結果。DSPy 將邏輯視為不可變、可測試和與 LLM 無關的「原因」,而文字表示僅僅是其「結果」的概念,最初可能令人困惑。尤其是在普遍認為「程式語言的未來是自然語言」的背景下。在接受「提示詞工程是未來」這個想法的同時,當遇到 DSPy 的設計理念時,人們可能會感到困惑。與簡化的期望相反,DSPy 引入了一系列模組和簽名語法,似乎將自然語言提示回退到了 C 程式設計的複雜程度!
但為什麼要採用這種方法?我的理解是,提示詞程式設計的核心是邏輯,而溝通則是一個放大器,可能增強或減弱其效果。"Do sentiment classification" 代表核心邏輯,而像 "Follow these demonstrations or I will fire you" 這樣的短語只是溝通它的一種方式。就像現實生活中的互動一樣,無法完成任務通常不是因為邏輯有誤,而是因為溝通出了問題。這解釋了為什麼許多人,特別是非母語者,覺得提示詞工程具有挑戰性。我觀察到公司中一些非常有能力的軟體工程師在提示詞工程方面掙扎,並不是因為他們缺乏邏輯,而是因為他們無法「說出那種感覺」。通過將邏輯與提示詞分離,DSPy 通過 dspy.Module 實現了邏輯的確定性程式設計,使開發者能夠像在傳統工程中一樣專注於邏輯,而不受所使用的 LLM 影響。
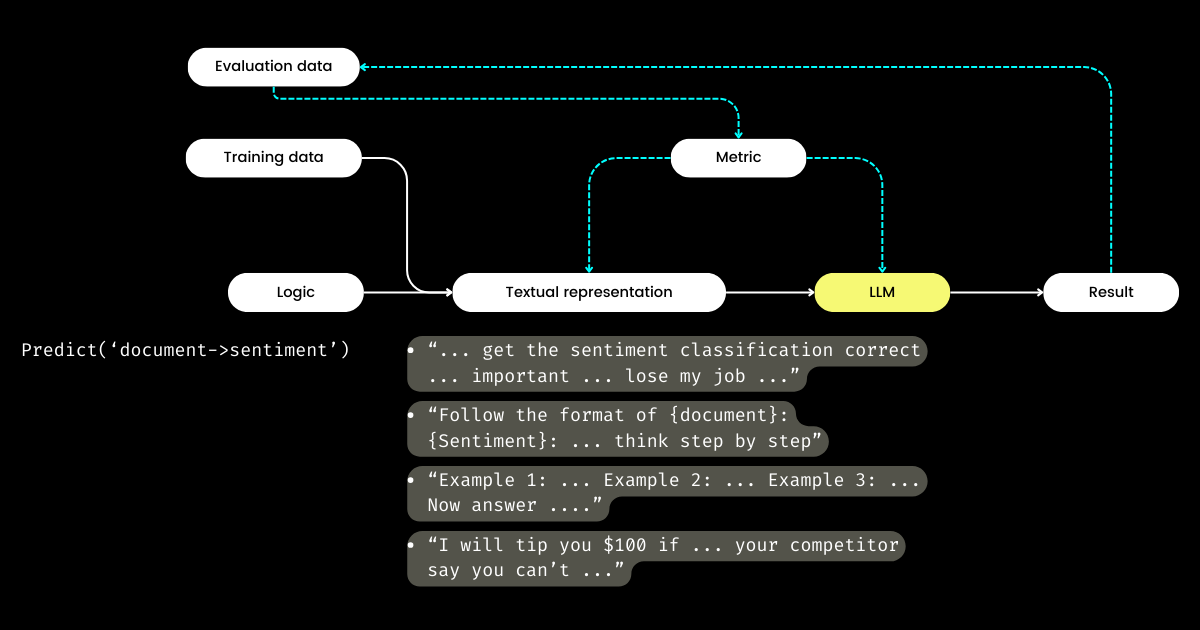
那麼,如果開發者專注於邏輯,誰來管理文字表示呢?DSPy 承擔了這個角色,利用你的資料和評估指標來改進文字表示——從確定敘述重點到優化提示,以及選擇好的示例。更令人驚訝的是,DSPy 甚至可以使用評估指標來微調 LLM 權重!
對我來說,DSPy 的主要貢獻——閉環提示詞工程的訓練和評估循環,以及將邏輯從文字表示中分離——突顯了它對 LLM/Agent 系統的潛在重要性。這無疑是一個雄心勃勃的願景,但絕對是必要的!
tag我認為 DSPy 可以改進的地方
首先,DSPy 對新手來說有很陡的學習曲線,這是由於它的慣用語。像 signature、module、program、teleprompter、optimization 和 compile 這樣的術語可能會令人感到不知所措。即使對於那些精通提示詞工程的人來說,在 DSPy 中導航這些概念也可能是一個具有挑戰性的迷宮。
這種複雜性讓我想起了使用 Jina 1.0 的經歷,當時我們引入了一系列概念如 chunk、document、driver、executor、pea、pod、querylang 和 flow(我們甚至設計了可愛的貼紙來幫助用戶記住!)。






這些早期概念大多在後來的 Jina 重構中被移除。如今,只有 Executor、Document 和 Flow 倖存於「大清洗」。我們在 Jina 3.0 中確實新增了一個概念 Deployment,所以算是扯平了。🤷
這個問題不僅存在於 DSPy 或 Jina;回想 TensorFlow 從 0.x 到 1.x 版本間引入的眾多概念和抽象。我認為這個問題經常出現在軟體框架的早期階段,當時為了確保最大程度的準確性和可重現性,往往直接將學術概念反映在程式碼庫中。然而,並非所有用戶都重視這種細緻的抽象,有些人偏好簡單的單行指令,有些則需要更大的靈活性。我在 2020 年的一篇部落格文章中詳細討論了軟體框架中的抽象問題,有興趣的讀者可以參考。


其次,DSPy 的文檔在一致性方面有時顯得不足。像是 module 和 program、teleprompter 和 optimizer,或是 optimize 和 compile(有時也被稱為 training 或 bootstrapping)等術語被交替使用,增加了混亂。因此,我最初使用 DSPy 時花了很多時間來理解它具體 optimizes 什麼,以及 bootstrapping 過程到底是什麼。
儘管存在這些障礙,當你深入研究 DSPy 並重新閱讀文檔時,你可能會經歷一些頓悟的時刻,開始理解它的獨特術語與 PyTorch 等框架中熟悉的概念之間的聯繫。但是,DSPy 無疑在未來版本中有改進的空間,特別是在讓那些沒有 PyTorch 背景的提示工程師更容易上手方面。
tagDSPy 新手常見的障礙
在下面的章節中,我整理了一份最初讓我在學習 DSPy 時感到困惑的問題清單。我希望分享這些見解能幫助其他學習者解決類似的挑戰。
tag什麼是 teleprompter、optimization 和 compile?DSPy 究竟在優化什麼?
在 DSPy 中,"Teleprompters" 是優化器(看起來 @lateinteraction 正在更新文檔和代碼以clarify 這一點)。compile 函數是這個優化器的核心,類似於調用 optimizer.optimize()。可以將其視為 DSPy 中的訓練過程。這個 compile() 過程旨在調優:
- 少樣本示範,
- 指令,
- LLM 的權重
然而,大多數 DSPy 入門教程不會深入探討權重和指令調優,這就引出了下一個問題。
tagDSPy 中的 bootstrap 是什麼?
Bootstrap 指的是為少樣本情境學習自動生成示範的過程,這是 compile() 過程(即我上面提到的優化/訓練)的重要組成部分。這些少樣本示範是從用戶提供的標註數據中生成的;一個示範通常包括輸入、輸出、推理過程(例如在思維鏈中),以及中間輸入和輸出(用於多階段提示)。當然,高質量的少樣本示範對於輸出質量至關重要。為此,DSPy 允許用戶定義度量函數來確保只選擇符合特定標準的示範,這就引出了下一個問題。
tag什麼是 DSPy 度量函數?
通過實際使用 DSPy 的經驗,我認為度量函數需要比目前文檔中更多的關注。DSPy 中的度量函數在評估和訓練階段都扮演著重要角色,因為它的隱式特性(由 trace=None 控制),它也同時作為「損失」函數:
def keywords_match_jaccard_metric(example, pred, trace=None):
# Jaccard similarity between example keywords and predicted keywords
A = set(normalize_text(example.keywords).split())
B = set(normalize_text(pred.keywords).split())
j = len(A & B) / len(A | B)
if trace is not None:
# act as a "loss" function
return j
return j > 0.8 # act as evaluation這種方法與傳統機器學習有顯著不同,在傳統機器學習中,損失函數通常是連續且可微的(例如 hinge/MSE),而評估指標可能完全不同且是離散的(例如 NDCG)。在 DSPy 中,評估和損失函數在度量函數中是統一的,它可以是離散的,且大多數情況下返回布爾值。度量函數甚至可以整合 LLM!在下面的例子中,我使用 LLM 實現了一個模糊匹配,用於判斷預測值和標準答案在數量級上是否相似,例如「100 萬美元」和「$1M」會返回 true。
class Assess(dspy.Signature):
"""Assess the if the prediction is in the same magnitude to the gold answer."""
gold_answer = dspy.InputField(desc='number, could be in natural language')
prediction = dspy.InputField(desc='number, could be in natural language')
assessment = dspy.OutputField(desc='yes or no, focus on the number magnitude, not the unit or exact value or wording')
def same_magnitude_correct(example, pred, trace=None):
return dspy.Predict(Assess)(gold_answer=example.answer, prediction=pred.answer).assessment.lower() == 'yes'度量函數雖然很強大,但它顯著影響了 DSPy 的使用體驗,不僅決定了最終的品質評估,還會影響優化的結果。設計良好的度量函數可以導致優化的 prompts,而設計不當的度量函數則可能導致優化失敗。當用 DSPy 處理新問題時,你可能會發現在設計邏輯(即 DSPy.Module)和度量函數上花費的時間差不多。對新手來說,這種需要同時關注邏輯和度量的雙重焦點可能會令人卻步。
tag"Bootstrapped 0 full traces after 20 examples in round 0" 這是什麼意思?
這個在 compile() 過程中悄悄出現的訊息值得你高度關注,因為它本質上意味著優化/編譯失敗了,你得到的 prompt 並不比簡單的 few-shot 更好。哪裡出錯了?我總結了一些幫助你在遇到這種訊息時除錯 DSPy 程式的提示:
你的度量函數不正確
在 BootstrapFewShot(metric=your_metric) 中使用的函數 your_metric 是否正確實作?進行一些單元測試。your_metric 是否有返回 True,還是總是返回 False?注意,返回 True 很重要,因為這是 DSPy 判斷 bootstrapped 範例為"成功"的標準。如果你將每個評估都返回 True,那麼每個範例在 bootstrapping 中都會被視為"成功"!當然,這並不理想,但這就是你如何調整度量函數的嚴格程度來改變 "Bootstrapped 0 full traces" 的結果。注意,雖然 DSPy 文檔中提到度量也可以返回標量值,但在查看底層程式碼後,我不建議新手這麼做。
你的邏輯(DSPy.Module)不正確
如果度量函數是正確的,那麼你需要檢查你的邏輯 dspy.Module 是否正確實作。首先,確認每個步驟的 DSPy signature 是否正確指定。像 dspy.Predict('question->answer') 這樣的內聯 signatures 很容易使用,但為了品質考量,我強烈建議使用基於類別的 signatures。具體來說,為類別添加一些描述性的文檔字串,填寫 InputField 和 OutputField 的描述欄位—這些都為語言模型提供了關於每個欄位的提示。下面我實作了兩個用於解決費米問題的多階段 DSPy.Module,一個使用內聯 signature,一個使用基於類別的 signature。
class FermiSolver(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict('question -> initial_guess')
self.step2 = dspy.Predict('question, initial_guess -> calculated_estimation')
self.step3 = dspy.Predict('question, initial_guess, calculated_estimation -> variables_and_formulae')
self.step4 = dspy.ReAct('question, initial_guess, calculated_estimation, variables_and_formulae -> gathering_data')
self.step5 = dspy.Predict('question, initial_guess, calculated_estimation, variables_and_formulae, gathering_data -> answer')
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5僅使用內聯 signature 的費米問題求解器
class FermiStep1(dspy.Signature):
question = dspy.InputField(desc='Fermi problems involve the use of estimation and reasoning')
initial_guess = dspy.OutputField(desc='Have a guess – don't do any calculations yet')
class FermiStep2(FermiStep1):
initial_guess = dspy.InputField(desc='Have a guess – don't do any calculations yet')
calculated_estimation = dspy.OutputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
class FermiStep3(FermiStep2):
calculated_estimation = dspy.InputField(desc='List the information you'll need to solve the problem and make some estimations of the values')
variables_and_formulae = dspy.OutputField(desc='Write a formula or procedure to solve your problem')
class FermiStep4(FermiStep3):
variables_and_formulae = dspy.InputField(desc='Write a formula or procedure to solve your problem')
gathering_data = dspy.OutputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
class FermiStep5(FermiStep4):
gathering_data = dspy.InputField(desc='Research, measure, collect data and use your formula. Find the smallest and greatest values possible')
answer = dspy.OutputField(desc='the final answer, must be a numerical value')
class FermiSolver2(dspy.Module):
def __init__(self):
super().__init__()
self.step1 = dspy.Predict(FermiStep1)
self.step2 = dspy.Predict(FermiStep2)
self.step3 = dspy.Predict(FermiStep3)
self.step4 = dspy.Predict(FermiStep4)
self.step5 = dspy.Predict(FermiStep5)
def forward(self, q):
step1 = self.step1(question=q)
step2 = self.step2(question=q, initial_guess=step1.initial_guess)
step3 = self.step3(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation)
step4 = self.step4(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae)
step5 = self.step5(question=q, initial_guess=step1.initial_guess, calculated_estimation=step2.calculated_estimation, variables_and_formulae=step3.variables_and_formulae, gathering_data=step4.gathering_data)
return step5使用基於類別的 signature 並對每個欄位有更全面描述的費米問題求解器。
另外,檢查 def forward(self, ) 部分。對於多階段的 Modules,確保上一步的輸出(或像在 FermiSolver 中的所有輸出)都作為輸入傳遞給下一步。
你的問題太難了
如果度量和模組都看起來正確,那麼可能你的問題太具挑戰性,而你實作的邏輯不足以解決它。因此,DSPy 發現以你的邏輯和度量函數無法 bootstrap 任何示例。在這種情況下,你可以考慮以下選項:
- 使用更強大的 LM。例如,將學生的 LM 從
gpt-35-turbo-instruct替換為gpt-4-turbo,使用更強大的 LM 作為老師。這通常相當有效。畢竟,更強大的模型意味著更好的 prompts 理解能力。 - 改進你的邏輯。在你的
dspy.Module中添加或替換一些步驟為更複雜的步驟。例如,將Predict替換為ChainOfThoughtProgramOfThought,添加Retrieval步驟。 - 添加更多訓練範例。如果 20 個範例不夠,那就瞄準 100 個!你可以期望有一個範例通過度量檢查並被
BootstrapFewShot選中。 - 重新構思問題。通常,當問題表述不正確時,問題就會變得無法解決。但如果你換個角度看問題,事情可能會變得更簡單和明顯。
在實踐中,這個過程涉及試錯的結合。例如,我處理了一個特別具有挑戰性的問題:根據兩到三個關鍵字生成類似 Google Material Design 圖標的 SVG 圖標。我的初始策略是使用一個簡單的 DSPy.Module,它使用 dspy.ChainOfThought('keywords -> svg'),並配合一個度量函數來評估生成的 SVG 和真實 Material Design SVG 之間的視覺相似度,類似於 pHash 演算法。我從 20 個訓練範例開始,但在第一輪後,我得到了 "Bootstrapped 0 full traces after 20 examples in round 0",表示優化失敗。通過將數據集增加到 100 個範例,修改我的模組以包含多個階段,並調整度量函數的閾值,我最終實現了 2 個 bootstrapped 示例並成功獲得了一些優化的 prompts。





