

在當今時代,準確地搜尋程式碼和文件比以往更加重要。我們很興奮地推出我們最新的程式碼領域嵌入模型:jina-embeddings-v2-base-code。這個新的開源程式語言嵌入模型旨在改善開發者與程式碼及文件的互動方式。它支援英語和 30 種熱門程式語言,是目前唯一能處理長達 8,192 個輸入標記的同類開源模型。jina-embeddings-v2-base-code 現已在 HuggingFace 上以 Apache 2.0 授權釋出,並可透過我們的 Embedding API 免費使用。
造訪 Embedding API 並從下拉清單中選擇 jina-embeddings-v2-base-code。免費享有 100 萬個標記。
tag為何開發程式碼嵌入模型?
開發者經常需要在龐大的程式碼庫中尋找特定功能或了解某些程序是如何實作的,而不是單純找錯誤。這項任務常常耗時費力,有時就像大海撈針。雖然整合開發環境(IDE)透過提供自動化搜尋資訊的工具和功能,大幅改善了這個過程,但仍有進一步提升的空間,而這正是我們的嵌入模型發揮作用之處。
tagjina-embeddings-v2-base-code 的使用案例
透過整合 AI 驅動的搜尋功能,我們不僅增強了 IDE 中現有的功能,更徹底改變了開發者與程式碼庫互動的方式。這項技術超越了簡單的文字搜尋,提供了能理解查詢意圖的語義理解,從而大幅減少程式碼審查、單元測試和整體品質管理所需的時間和精力。
增強的程式碼導航
- 查詢格式:用自然語言描述您要搜尋的功能或程式碼片段。
- 檢索結果格式:相關的程式碼檔案或片段,其中實作了所描述的功能,並附有指向程式碼特定部分的註釋或亮點標示。
精簡的程式碼審查
- 查詢格式:描述您想要在程式碼庫中審查的程式設計概念或模式。
- 檢索結果格式:符合所描述概念、模式或最佳實踐的程式碼片段或 pull request 清單,使審查者能專注於需要改進的關鍵領域。
自動化文件協助
- 查詢格式:需要文件說明或解釋的程式碼片段。
- 檢索結果格式:建議的文件字串或文件條目,說明程式碼的功能、參數和返回類型,使維護最新且全面的文件變得更容易。
透過解決這些特定的使用案例,jina-embeddings-v2-base-code 不僅提升了開發體驗,還促進了更具協作性和效率的編程環境。
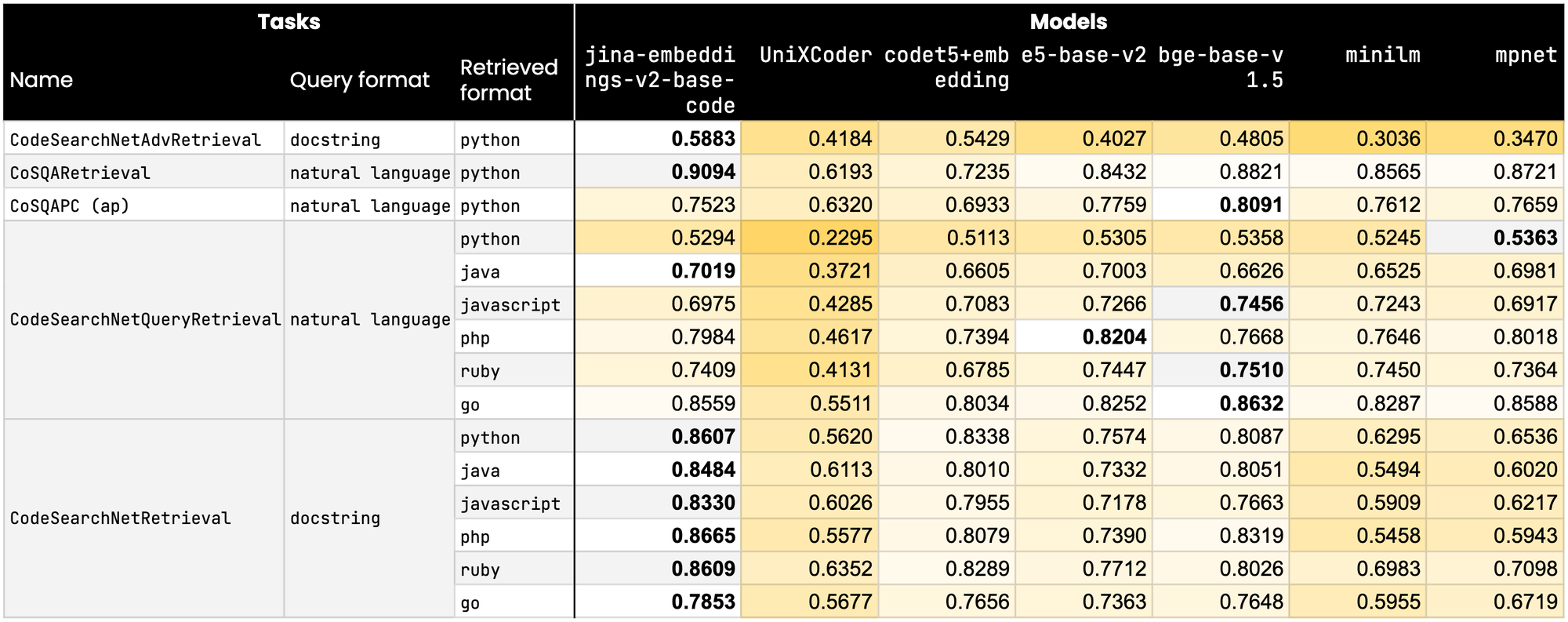
tag性能基準測試
在精確度和準確度至關重要的領域中,jina-embeddings-v2-base-code 在十五個關鍵的 CodeNetSearch 基準測試中,有九項領先於競爭對手。此外,我們的模型在其餘基準測試中也保持著極具競爭力的分數。與包括 Microsoft 和 Salesforce 等科技巨頭在內的最接近競爭對手相比,jina-embeddings-v2-base-code 不僅排名更高,還展現了其優越的設計和能力。
tag模型特點
- 最先進的性能:我們對卓越的承諾反映在 Jina Embedding 模型的性能上,這些模型在與其他開源產品的基準測試中始終名列前茅,甚至超越了 Microsoft 和 Salesforce 的模型。
- 小巧但強大:在 AI 領域,效率是關鍵。jina-embeddings-v2-base-code 擁有 1.61 億個參數(未量化前為 307MB),專為效率而設計,在不犧牲功能的情況下提供高速性能和成本節約。
- 延伸的上下文能力:能夠處理多達 8192 個標記的能力,使其可以處理大型函數和眾多物件檔案,提供的理解深度和上下文遠超過只能支援幾百個標記的模型的限制。
- 多語言支援:為了實現多功能性,我們的模型訓練涵蓋了 30 種程式語言和框架,重點強調六種最受歡迎的語言:Python、JavaScript、Java、PHP、Go 和 Ruby。這種廣泛的覆蓋確保 jina-embeddings-v2-base-code 能滿足程式開發社群的多樣化需求。
- RAG 整合實現無縫程式碼生成:該模型與 RAG 的相容性以及與程式碼生成模型的整合,不僅能從一般知識生成程式碼,還能讀取相關的 API 和文件,實現高效準確的自動程式碼整合。
tag無縫 API 整合
jina-embeddings-v2-base-code 的設計注重易於整合,支援主要的向量資料庫如 MongoDB、Qdrant 和 Weaviate,以及 Haystack 和 LlamaIndex 等框架。這確保開發人員可以輕鬆地將我們的模型整合到他們現有的系統中,利用其功能來增強程式碼檢索和文件處理。
我們重視您對 jina-embeddings-v2-base-code 的意見回饋。歡迎加入我們的社群頻道,提供反饋並了解我們的最新進展。讓我們一起打造更強大、更包容的 AI 未來。




