


在我們之前的文章中,我們探討了分塊的挑戰並介紹了後期分塊的概念,這有助於減少嵌入塊時的上下文損失。在本文中,我們將聚焦於另一個挑戰:尋找最佳斷點。雖然我們的後期分塊策略已證實對於不佳的邊界相當有彈性,但這並不意味著我們可以忽視它們—它們對於人類和 LLM 的可讀性仍然很重要。我們的觀點是:在確定斷點時,我們現在可以完全專注於可讀性,而不用擔心語義或上下文的損失。後期分塊可以處理好的和不好的斷點,所以可讀性成為你的主要考慮因素。
基於這一點,我們訓練了三個專門設計用於分割長文檔的小型語言模型,同時保持語義連貫性並處理複雜的內容結構。它們是:

simple-qwen-0.5,基於文檔的結構元素來分割文本。

topic-qwen-0.5,基於文本中的主題來分割文本。

summary-qwen-0.5,為每個片段生成摘要。
在本文中,我們將討論為什麼要開發這個模型,我們如何處理其三個變體,以及它們與 Jina AI 的 Segmenter API 的基準比較。最後,我們將分享我們學到的經驗和對未來的一些想法。
tag分割問題
分割是 RAG 系統的核心元素。我們如何將長文檔分割成連貫、可管理的片段直接影響檢索和生成步驟的質量,影響從答案相關性到摘要質量的所有方面。傳統的分割方法產生了不錯的結果,但也有其局限性。
引用我們之前的文章:
在分割長文檔時,一個關鍵的挑戰是決定在哪裡創建片段。這可以使用固定的 token 長度、固定數量的句子,或更高級的方法如正則表達式和語義分割模型來完成。建立準確的片段邊界至關重要,因為它不僅提高了搜索結果的可讀性,還確保了在 RAG 系統中提供給 LLM 的片段既精確又充分。
雖然後期分塊提高了檢索性能,但在 RAG 應用中,確保每個片段本身都盡可能有意義,而不僅僅是隨機的文本塊,這一點至關重要。LLM 依賴於連貫、結構良好的數據來生成準確的回應。如果片段不完整或缺乏意義,即使有後期分塊的好處,LLM 也可能在上下文和準確性方面遇到困難,影響整體性能。簡而言之,無論你是否使用後期分塊,擁有一個穩固的分割策略對於建立有效的 RAG 系統都是必不可少的(正如你將在後面的基準部分看到的)。
傳統的分割方法,無論是在簡單的邊界(如換行或句子)處斷開,還是使用嚴格的基於 token 的規則,都面臨著相同的限制。這兩種方法都未能考慮到語義邊界,並且在處理模糊的主題時會遇到困難,導致片段破碎。為了解決這些挑戰,我們開發並訓練了一個專門用於分割的小型語言模型,旨在捕捉主題轉換並保持連貫性,同時在各種任務中保持效率和適應性。
tag為什麼選擇小型語言模型?
我們開發了小型語言模型(SLM)來解決我們在使用傳統分割技術時遇到的特定限制,特別是在處理程式碼片段和其他複雜結構(如表格、列表和公式)時。在傳統方法中,通常依賴於 token 計數或嚴格的結構規則,很難維持語義連貫內容的完整性。例如,程式碼片段經常被分割成多個部分,打破了它們的上下文,使下游系統更難理解或準確檢索它們。
通過訓練專門的 SLM,我們旨在創建一個能夠智能識別和保護這些有意義邊界的模型,確保相關元素保持在一起。這不僅提高了 RAG 系統中的檢索質量,還增強了下游任務(如摘要和問答)的效果,在這些任務中,維持連貫和上下文相關的片段至關重要。與傳統分割方法的嚴格邊界相比,SLM 方法提供了一個更適應性強、更具任務特異性的解決方案。
tag訓練 SLM:三種方法
我們訓練了三個版本的 SLM:
simple-qwen-0.5是最簡單的模型,設計用於基於文檔的結構元素識別邊界。其簡單性使其成為基本分割需求的高效解決方案。topic-qwen-0.5受思維鏈推理的啟發,通過識別文本中的主題(如"第二次世界大戰的開始")並使用這些主題來定義片段邊界,將分割提升到了更高的層次。這個模型確保每個片段在主題上保持連貫,非常適合複雜的多主題文檔。初步測試顯示,它在以接近人類直覺的方式分割內容方面表現出色。summary-qwen-0.5不僅識別文本邊界,還為每個片段生成摘要。在 RAG 應用中,特別是對於長文檔問答等任務,摘要片段非常有優勢,儘管在訓練時需要更多的數據。
所有模型只返回片段頭部—每個片段的截斷版本。模型不是生成完整的片段,而是輸出關鍵點或子主題,這通過專注於語義轉換而不是簡單地複製輸入內容來改善邊界檢測和連貫性。在檢索片段時,文檔文本基於這些片段頭部進行分割,並相應地重建完整片段。
tag數據集
我們使用了 wiki727k 數據集,這是一個從維基百科文章中提取的大規模結構化文本片段集合。它包含超過 727,000 個文本部分,每個部分代表維基百科文章的不同部分,如介紹、章節或小節。
 koomri
koomritag資料增強
為了給每個模型變體生成訓練配對,我們使用 GPT-4 來增強我們的資料。對於訓練資料集中的每篇文章,我們發送以下提示:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()我們使用簡單的分割方式從每篇文章生成段落,先在 \\n\\n\\n 處分割,然後在 \\n\\n 處再次分割,以獲得以下內容(以這個關於 Common Gateway Interface 的文章為例):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
然後我們生成了一個包含段落、主題和摘要的 JSON 結構:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Common Gateway Interface in Web Servers",
"The History and Standardization of CGI",
"CGI Scripts for Editing Web Pages",
"Reducing Web Server Overhead in Command Invocation"
],
"summaries": [
"CGI 為網頁伺服器提供了一個執行動態生成網頁程式的標準協議。",
"NCSA 在 1993 年首次定義了 CGI,隨後它成為網頁伺服器的標準,並在 Ken Coar 的主持下正式化為 RFC 3875。",
"本文描述了 CGI 腳本如何透過 HTML 表單處理網頁內容的編輯和保存。",
"本文討論了減少頻繁命令調用所造成的伺服器開銷的技術,包括進程預分叉、使用預編譯的 CGI 程式,以及實現自訂網頁伺服器模組。"
]
}
我們也透過洗牌資料、加入隨機字元/單詞/字母、隨機移除標點符號,並且一律移除換行字元來增加噪聲。
所有這些方法都能在一定程度上幫助開發出一個好的模型 - 但還不夠。為了真正發揮所有潛力,我們需要模型能夠產生連貫的片段而不破壞程式碼片段。為此,我們使用 GPT-4o 生成的程式碼、公式和列表來增強資料集。
tag訓練設置
為了訓練這些模型,我們實施了以下設置:
- 框架:我們使用了 Hugging Face 的
transformers函式庫,並整合了Unsloth來進行模型優化。這對於優化記憶體使用和加速訓練至關重要,使我們能夠有效地使用大型資料集來訓練小型模型。 - 優化器和調度器:我們使用了 AdamW 優化器和線性學習率調度器,並設定預熱步驟,這讓我們能夠在初始訓練階段穩定訓練過程。
- 實驗追蹤:我們使用 Weights & Biases 追蹤所有訓練實驗,並記錄關鍵指標如訓練和驗證損失、學習率變化以及整體模型表現。這種即時追蹤讓我們能夠洞察模型的進展情況,必要時能快速調整以優化學習成果。
tag訓練過程
以 qwen2-0.5b-instruct 作為基礎模型,我們使用 Unsloth 訓練了三種 SLM 變體,每一種都針對不同的分段策略。對於我們的樣本,我們使用訓練對,包含來自 wiki727k 的文章文本,以及根據所訓練的模型產生的 sections、topics 或 summaries(如上述「資料增強」部分所提)。
simple-qwen-0.5:我們使用 10,000 個樣本訓練了 5,000 步的simple-qwen-0.5,實現了快速收斂並能有效檢測文本連貫段落間的邊界。訓練損失為 0.16。topic-qwen-0.5:與simple-qwen-0.5類似,我們使用 10,000 個樣本訓練了 5,000 步的topic-qwen-0.5,達到了 0.45 的訓練損失。summary-qwen-0.5:我們使用 30,000 個樣本訓練了 15,000 步的summary-qwen-0.5。這個模型展現出潛力,但在訓練過程中有較高的損失(0.81),這表明需要更多的資料(大約是原始樣本數量的兩倍)才能發揮其全部潛力。
tag分段結果
以下是每種分段策略的三個連續段落示例,以及 Jina 的 Segmenter API。為了產生這些段落,我們首先使用 Jina Reader 從 Jina AI blog 抓取一篇文章的純文本(包含所有頁面資料,如頁首、頁尾等),然後將其傳遞給每種分段方法。

tagJina Segmenter API
Jina Segmenter API 採用了非常精細的分段方式,通過像 \n、\t 等字元來切分文本,通常會產生非常小的段落。僅看前三個段落,它從網站的導航欄中提取了 search\\n、notifications\\n 和 NEWS\\n,但沒有提取任何與文章內容相關的內容:

再往後,我們終於獲得了一些來自實際部落格文章內容的段落,但每個段落保留的上下文很少:

(為了公平起見,我們展示了比其他模型更多的 Segmenter API 片段,主要是因為若不這樣做,就會只有很少有意義的段落可以展示)
tagsimple-qwen-0.5
simple-qwen-0.5 根據語義結構將部落格文章分解成更長的段落,每個段落都有連貫的含義:
tagtopic-qwen-0.5
topic-qwen-0.5 首先根據文件內容識別主題,然後基於這些主題對文件進行分段:
tagsummary-qwen-0.5
summary-qwen-0.5 識別段落邊界並為每個段落中的內容生成摘要:
tag模型基準測試
為了對我們的模型進行基準測試,我們從 Jina AI 部落格抓取了八篇部落格文章,並使用 GPT-4o 生成了六個問題和標準答案。
我們對這些部落格文章應用了每種分段方法,包括 Jina Segmenter API,然後使用 jina-embeddings-v3 為產生的段落生成嵌入向量,不進行後期分塊或重新排序。

之後,我們分別對每組段落進行索引,並使用 RAG 系統透過先前生成的問題查詢每個索引。
topic-qwen-0.5 和 summary-qwen-0.5 時,我們僅對段落本身建立索引,而非生成的摘要或主題。索引這些額外資料可能會進一步提升效能。為了衡量效能,我們使用 ROUGE-L 評估的 F1 分數,比較每種分段方法索引生成的答案與標準答案,分數越高代表效能越好。
例如,針對問題:"什麼因素影響 jina-embeddings-v2-base-en 模型的數字比較能力?",我們收到以下答案:
tag標準答案(由 GPT-4o 從完整文章生成):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
tagJina Segmenter API(分數:0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
tagsimple-qwen-0.5(分數:0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
tagtopic-qwen-0.5(分數:0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
tagsummary-qwen-0.5(0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5 的分數這麼低?這主要是因為我們問的這個特定問題而產生的偶然結果。如下表所示,
topic-qwen-0.5 的平均 ROUGE 分數是所有分段方法中最高的。我們還評估了每種方法的速度(透過計時生成和嵌入段落所需的時間),並估算了磁碟空間(將嵌入數量乘以 jina-embeddings-v3 中單個 1024 維嵌入的大小)。這使我們能夠評估不同分段策略的準確性和效率。
tag重要發現
在將模型變體相互比較並與 Jina 的 Segmenter API 進行測試後,我們發現新模型確實在所有三種方法中都表現出更好的分數,特別是主題分段:
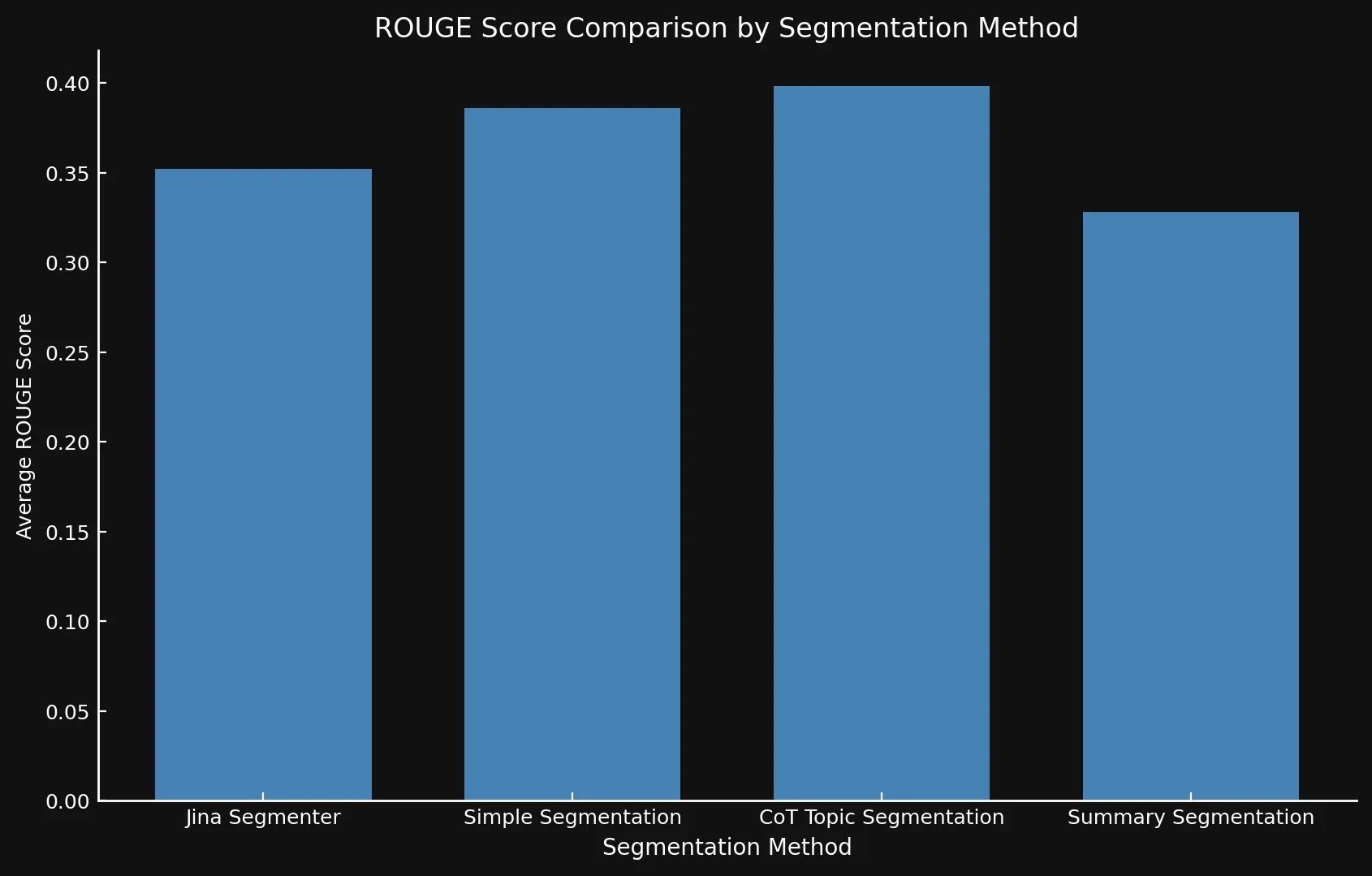
| 分段方法 | 平均 ROUGE 分數 |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 的 ROUGE 分數比 topic-qwen-0.5 低?簡單來說,summary-qwen-0.5 在訓練過程中顯示出較高的損失,表明需要更多訓練才能獲得更好的結果。這可能是未來實驗的主題。不過,使用 jina-embeddings-v3 的延遲分段功能來審查結果會很有趣,因為它增加了段落嵌入的上下文相關性,提供更相關的結果。這可能會成為未來部落格文章的主題。
關於速度,很難將新模型與 Jina Segmenter 進行比較,因為後者是一個 API,而我們是在 Nvidia 3090 GPU 上運行這三個模型。如你所見,Segmenter API 雖然在分段步驟中速度很快,但因為需要為大量段落生成嵌入而很快就被超越了:
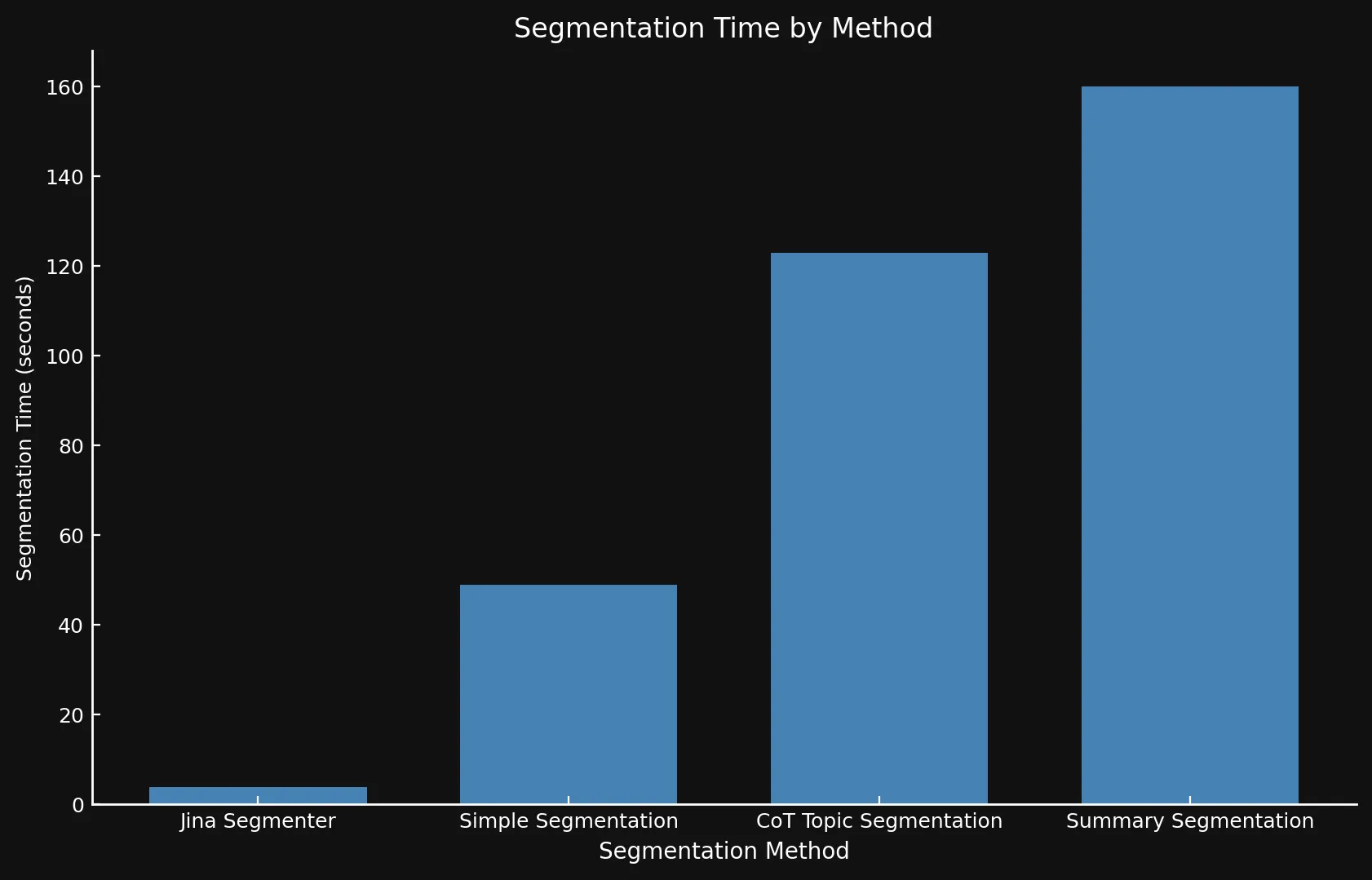
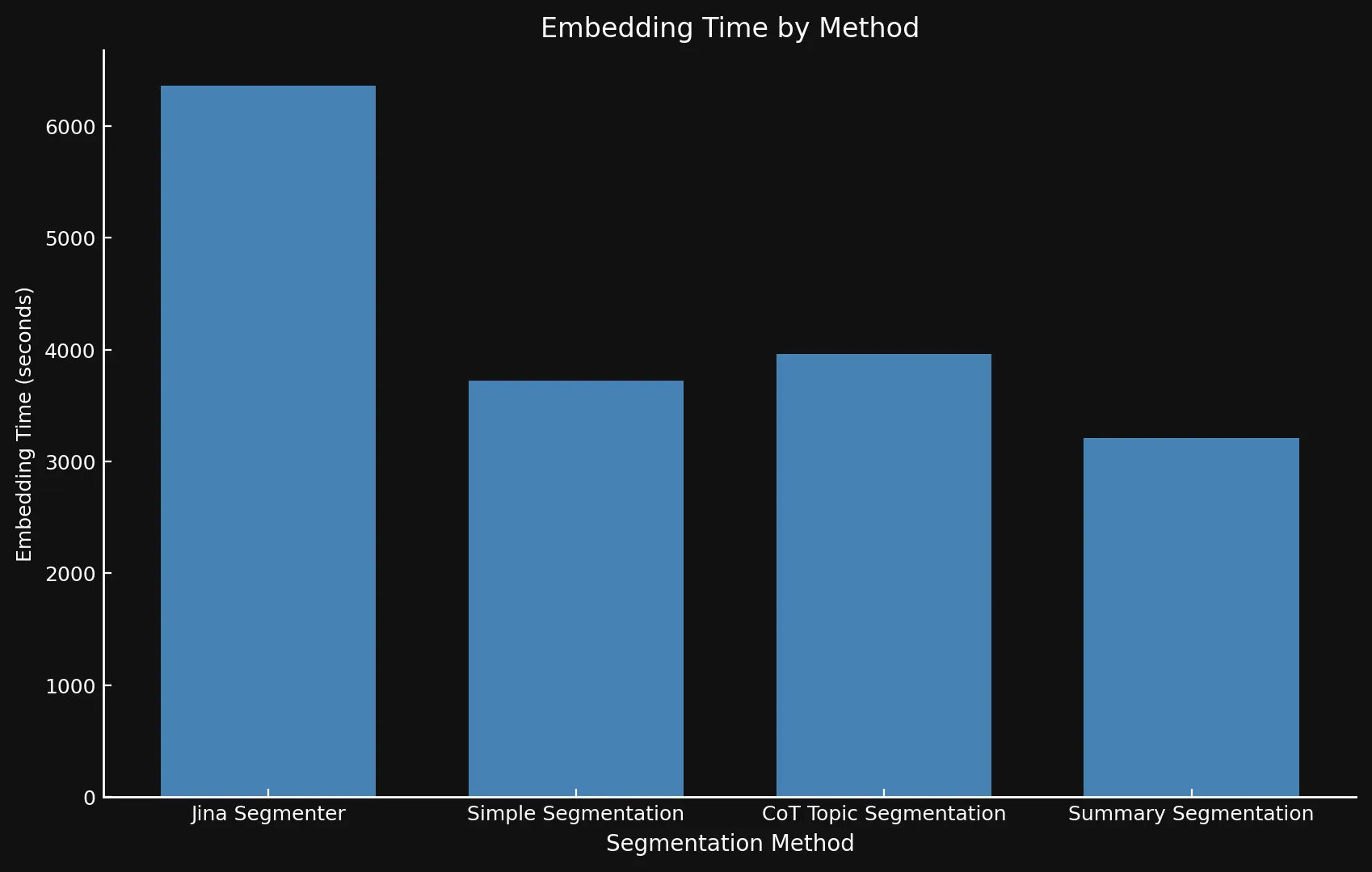
• 我們在兩個圖表中使用不同的 Y 軸,因為用一個圖表或一致的 Y 軸呈現如此不同的時間範圍是不可行的。
• 由於這純粹是一個實驗,我們在生成嵌入時沒有使用批次處理。使用批次處理會大幅加快所有方法的運行速度。
自然地,更多的段落意味著更多的嵌入。而這些嵌入佔用了大量空間:我們測試的八篇部落格文章的嵌入使用 Segmenter API 時佔用超過 21 MB,而摘要分段僅佔用 468 KB。這加上我們模型的較高 ROUGE 分數意味著更少但更好的段落,節省成本並提高效能:
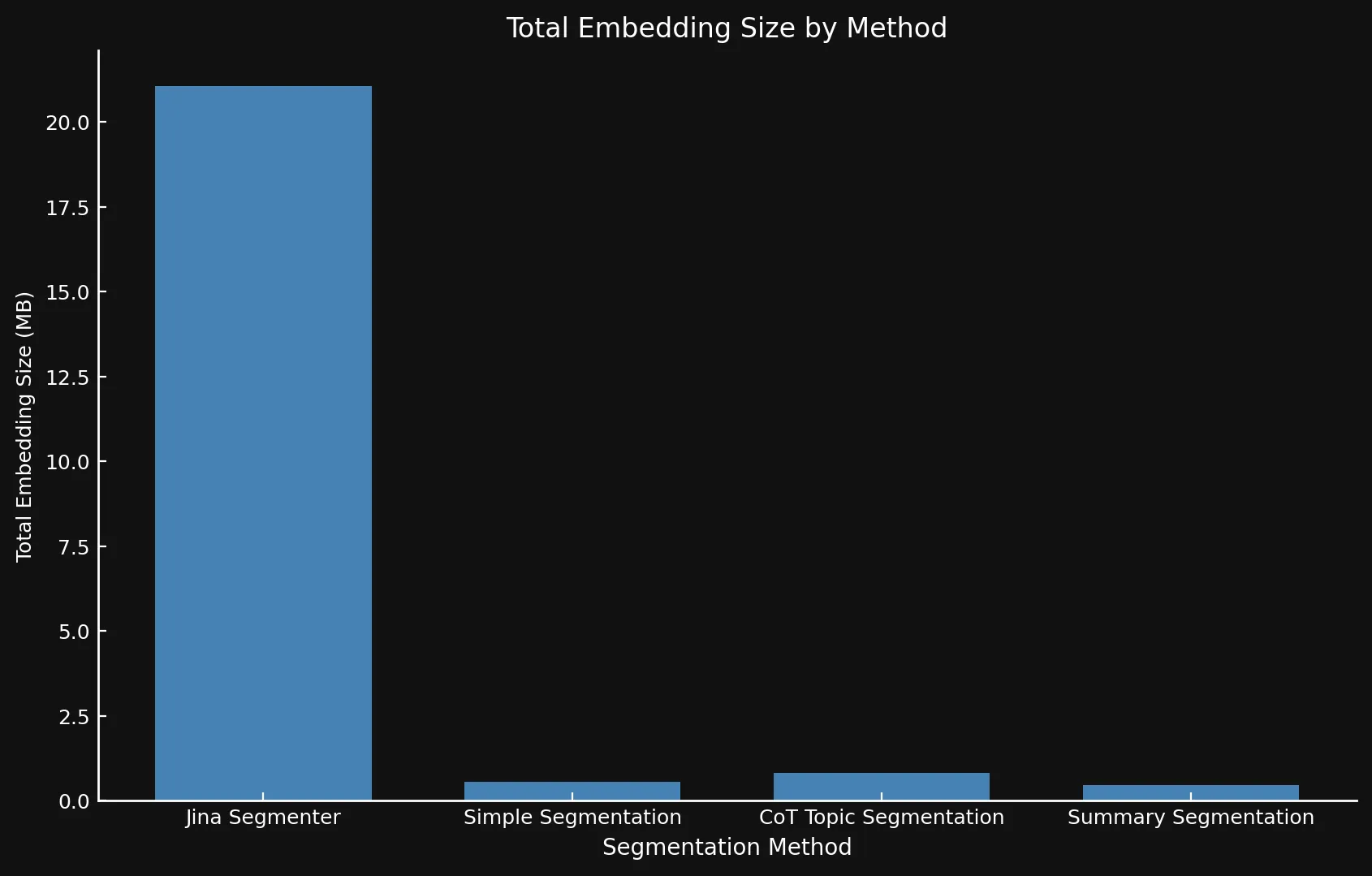
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
tag我們學到了什麼
tag問題定義至關重要
一個關鍵洞察是我們如何構建任務的影響。通過讓模型輸出片段標題,我們通過關注語義轉換而不是簡單地將輸入內容複製粘貼到不同片段中,改善了邊界檢測和連貫性。這也使分段模型更快,因為生成較少的文本讓模型能更快完成任務。
tagLLM 生成的數據很有效
使用 LLM 生成的數據,特別是對於列表、公式和程式碼片段等複雜內容,擴大了模型的訓練集,並改善了其處理不同文檔結構的能力。這使模型在處理各種內容類型時更具適應性,這在處理技術或結構化文檔時是一個關鍵優勢。
tag僅輸出數據整理
通過使用僅輸出的數據整理器,我們確保模型在訓練期間專注於預測目標 token,而不是僅僅從輸入中複製。僅輸出的整理器確保模型從實際目標序列中學習,強調正確的補全或邊界。這種區別通過避免對輸入過度擬合使模型更快收斂,並幫助它在不同數據集間更好地泛化。
tag使用 Unsloth 進行高效訓練
使用 Unsloth,我們簡化了小型語言模型的訓練,成功在 Nvidia 4090 GPU 上運行它。這種優化的流程讓我們能夠訓練出高效能的模型,而無需龐大的計算資源。
tag處理複雜文本
分段模型在處理包含程式碼、表格和列表的複雜文檔方面表現出色,這些通常對傳統方法來說很困難。對於技術內容,像 topic-qwen-0.5 和 summary-qwen-0.5 這樣的複雜策略更有效,有潛力提升下游的 RAG 任務。
tag簡單方法用於更簡單的內容
對於簡單的、敘事驅動的內容,像 Segmenter API 這樣的簡單方法通常就足夠了。高級分段策略可能只在處理更複雜的結構化內容時才需要,這使得根據使用場景可以靈活選擇。
tag下一步
雖然這個實驗主要是作為概念驗證而設計的,但如果我們要進一步擴展它,我們可以做幾項改進。首先,儘管這個特定實驗不太可能繼續,但在更大的數據集上訓練 summary-qwen-0.5—理想情況下是 60,000 個樣本而不是 30,000 個—可能會帶來更理想的性能。此外,改進我們的基準測試流程也會有幫助。我們不會評估 RAG 系統生成的 LLM 答案,而是專注於將檢索的片段直接與真實值進行比較。最後,我們會超越 ROUGE 分數,採用更先進的指標(可能是 ROUGE 和 LLM 評分的組合)來更好地捕捉檢索和分段質量的細微差別。
tag結論
在這個實驗中,我們探索了為特定任務設計的自定義分段模型如何提升 RAG 的性能。通過開發和訓練像 simple-qwen-0.5、topic-qwen-0.5 和 summary-qwen-0.5 這樣的模型,我們解決了傳統分段方法中的關鍵挑戰,特別是在維持語義連貫性和有效處理程式碼片段等複雜內容方面。在測試的模型中,topic-qwen-0.5 持續提供最有意義和上下文相關的分段,尤其是對於多主題文檔。
雖然分段模型為 RAG 系統提供了必要的結構基礎,但它們與後期分塊的功能不同,後者通過維持片段間的上下文關聯性來優化檢索性能。這兩種方法可以互補,但當你需要一種專注於為連貫的、特定任務的生成工作流分割文檔的方法時,分段特別重要。





