

柏林,德國 - 2023 年 1 月 15 日 – 呼應甘迺迪的經典名言「我是柏林人」,在 Jina AI,我們很高興能以自己的方式跨越語言的藩籬。今天,我們很自豪地宣布我們最新的創新:jina-embeddings-v2-base-de,一個德語/英語嵌入模型。這個最先進的雙語模型在語言表示方面邁出了重要的一步,具有 8,192 個 token 的上下文長度。它的與眾不同之處在於其卓越的效率:在僅為可比模型 1/7 大小的情況下,就能達到頂級性能。
對於希望擴展到美國市場的德國企業來說,嵌入模型至關重要。根據 2022 年德美商業展望 (GABO),約三分之一的德國公司在美國產生超過 20% 的全球銷售額和利潤,其中 93% 預期美國銷售額將增長。這一趨勢持續發展,93% 計劃在未來三年增加其公司在美國的投資,85% 預期淨銷售額增長,並且高度關注數位轉型。優質的嵌入模型可以在這種擴張中發揮關鍵作用,通過促進對客戶偏好的更好理解,實現更有效的溝通,並定位具有文化共鳴的產品。
我們的突破對於希望在英語國家實施雙語應用的德國企業特別有利。藉助 jina-embeddings-v2-base-de,我們很期待看到德國公司如何在日益互聯的世界中創新和蓬勃發展。
tag模型亮點
- 最先進的性能:jina-embeddings-v2-base-de 在相關基準測試中持續排名領先,並在同等規模的開源模型中佔據領先地位。
- 雙語模型: 這個模型可以同時編碼德語和英語文本,允許在檢索應用中使用任一語言作為查詢或目標文檔。兩種語言中具有相同含義的文本會被映射到相同的嵌入空間,為多語言應用奠定基礎。
- 擴展的上下文:8192 個 token 的長度使 jina-embeddings-v2-base-de 能夠支援更長的文本和文檔片段,遠超只能一次支援幾百個 token 的模型。
- 緊湊的大小:jina-embeddings-v2-base-de 專為在標準電腦硬體上實現高性能而設計。僅有 1.61 億個參數,整個模型大小為 322MB,可以適配普通電腦的記憶體。嵌入本身為 768 維度,相比許多模型而言是相對較小的向量大小,可為應用節省空間和運行時間。
- 偏差最小化:最新研究 表明,沒有特定語言訓練的多語言模型在嵌入中會顯示出對英語語法結構的強烈偏好。嵌入模型應該是捕捉含義,而不是偏好僅在表面上相似的句子對。
- 無縫整合:Jina Embeddings v2 模型與主要向量數據庫都有原生整合,包括 MongoDB、Qdrant 和 Weaviate,以及 RAG 和 LLM 框架,如 Haystack 和 LlamaIndex。
tag德語自然語言處理的領先性能
我們將 jina-embeddings-v2-base-de 與四個同樣支援德語和英語的知名基準模型進行了對比測試。這些包括:
- 來自 Microsoft 的 Multilingual-E5-large 和 Multilingual-E5-base
- T-Systems 的 Cross English & German RoBERTa for Sentence Embeddings
- Sentence-BERT(
distiluse-base-multilingual-cased-v2)
我們的基準測試包括 英語的 MTEB 任務和我們自己的客製化基準。鑑於缺乏全面的德語嵌入基準測試套件,我們主動開發了自己的套件,靈感來自 MTEB。我們很自豪在此與您分享我們的發現和突破。
 jina-ai
jina-ai
tag體積小巧,結果出眾
jina-embeddings-v2-base-de 展現出卓越的性能,尤其是在德語任務方面。它在體積不到 E5 base 模型三分之一的情況下,表現超越了該模型。此外,它還能與體積是其七倍的 E5 large 模型並駕齊驅,展示了其效率和實力。這種效率使 jina-embeddings-v2-base-de 成為一個突破性的產品,特別是與其他流行的雙語和多語言嵌入模型相比。
tag在德英跨語言檢索中表現出色
我們的模型不僅僅是關於大小和效率;在英德跨語言檢索任務中也是頂級表現者。這在各種關鍵基準測試中得到了證明:
在這些基準測試中的表現,特別是在 MTEB 評估測試中(WikiCLIR 除外),突顯了 jina-embeddings-v2-base-de 在處理複雜雙語任務方面的效能。
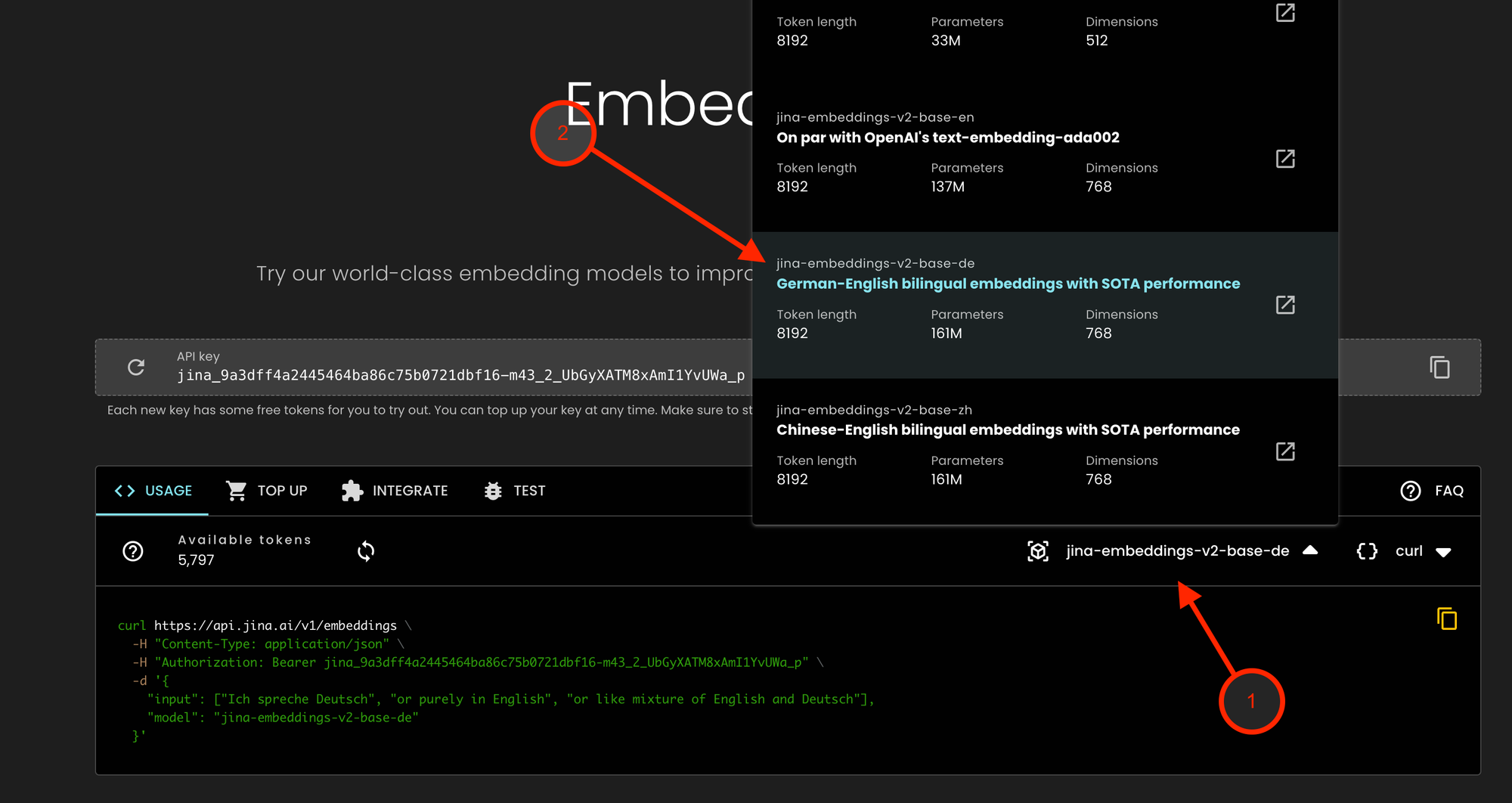
tag獲取 API 存取權限
我們為重視隱私和數據合規的企業用戶提供的服務,包括 jina-embeddings-v2-base-de,可通過 Jina Embeddings API 存取:
- 前往 Jina Embeddings API 並點擊模型下拉選單
- 選擇 jina-embeddings-v2-base-de

我們很快就會在 AWS Sagemaker marketplace 上為 Amazon 雲端用戶提供此模型,並在 HuggingFace 上提供下載。
tagJina 8K Embeddings:多元 AI 應用的基石
Embeddings 對於廣泛的 AI 應用至關重要,包括資訊檢索、數據品質控制、分類和推薦。它們是提升眾多 AI 任務的基礎。
Jina AI 致力於推進 embedding 技術的最新發展,讓我們的核心 AI 組件保持透明、易用,並為重視隱私和數據合規的各類型和規模的企業提供可負擔的價格。除了 jina-embeddings-v2-base-de,Jina AI 還發布了用於中文的最先進 embedding 模型和高性能的英文單語言模型。這是我們讓 AI 技術更具包容性和全球適用性的使命的一部分。
我們重視您的回饋。加入我們的社群頻道,提供反饋並了解我們的最新進展。讓我們一起打造一個更強大、更包容的 AI 未來。


