



開發人員和運維工程師非常重視能夠輕鬆設置、快速啟動,以及後續可以在生產環境中高效部署且無額外麻煩的基礎設施。因此,我們合作夥伴 Milvus 最新推出的輕量級向量數據庫 Milvus Lite,對 Python 開發者來說是一個重要工具,特別是當它與高品質且易用的搜索基礎模型一起使用時,能快速開發搜索應用。
在本文中,我們將通過一個基於虛構公司內部公共頻道聊天記錄構建的 檢索增強生成 (RAG) 應用示例,來描述 Milvus Lite 如何整合 Jina Embeddings v2 和 Jina Reranker v1,以讓員工能夠準確且有幫助地獲得與組織相關問題的答案。
tagMilvus Lite、Jina Embeddings 和 Jina Reranker 概述
Milvus Lite 是領先的向量數據庫 Milvus 的新輕量級版本,現在也作為 Python 庫提供。Milvus Lite 與部署在 Docker 或 Kubernetes 上的 Milvus 共享相同的 API,但可以通過一行 pip 命令輕鬆安裝,無需設置服務器。
通過在 Milvus 的 Python SDK pymilvus 中整合 Jina Embeddings v2 和 Jina Reranker v1,你現在可以使用相同的 Python 客戶端直接在任何 Milvus 部署模式(包括 Milvus Lite)中嵌入文檔。你可以在 pymilvus 的 文檔頁面上找到 Jina Embeddings 和 Reranker 整合的詳細信息。
Jina Embeddings v2 具有 8k 字符的上下文窗口和多語言功能,能夠編碼文本的廣泛語義並確保準確檢索。通過在管道中添加 Jina Reranker v1,你可以通過直接將檢索到的結果與查詢進行交叉編碼來進一步優化結果,實現更深入的上下文理解。
tagMilvus 和 Jina AI 模型實戰
本教程將重點關注一個實際用例:查詢公司的 Slack 聊天歷史記錄,以根據過去的對話回答各種問題。
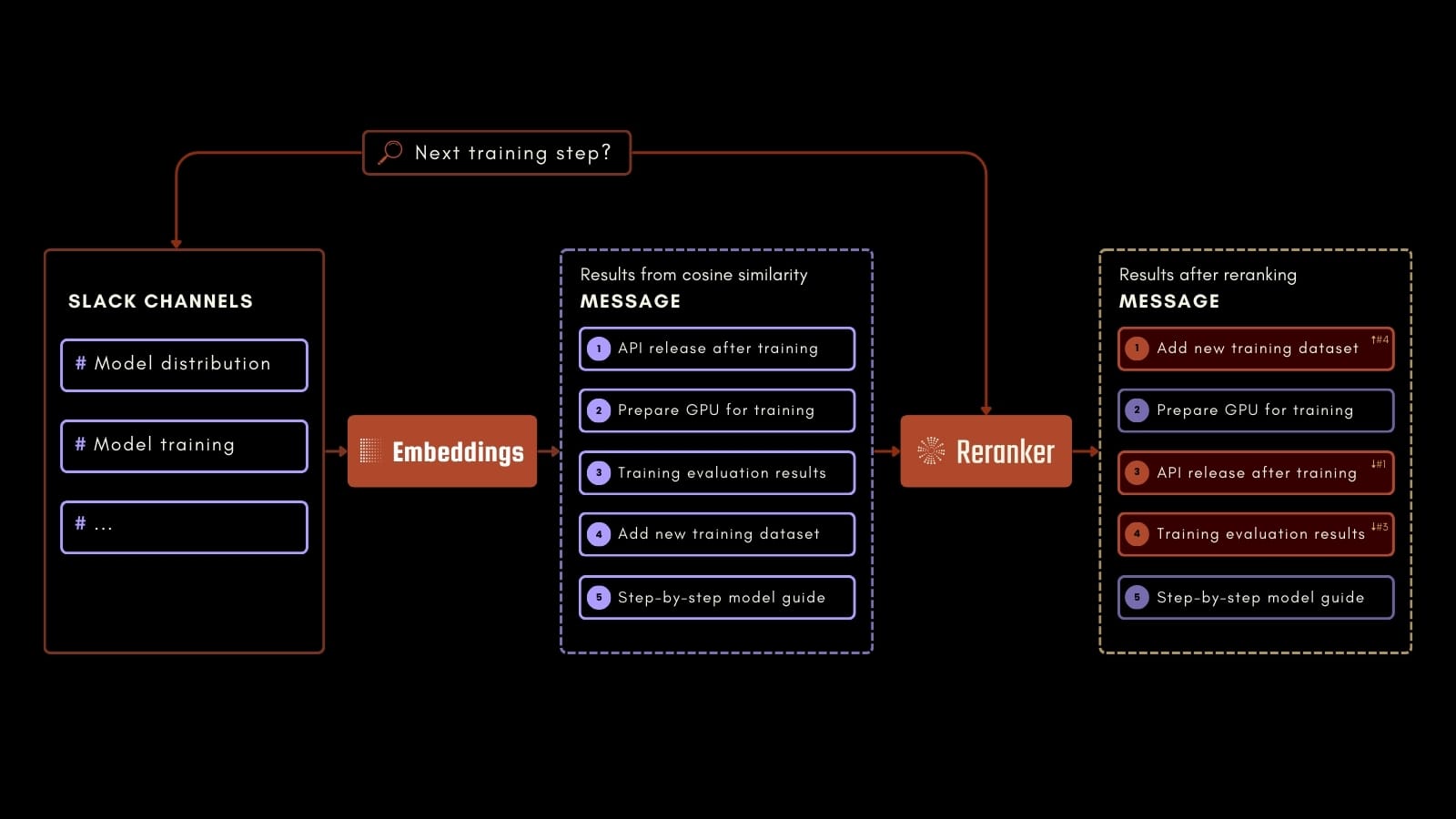
例如,在上面的流程圖中,員工可以詢問 AI 訓練過程中的下一步是什麼。通過使用 Jina Embeddings、Jina Reranker 和 Milvus,我們可以準確地識別記錄在 Slack 消息中的相關信息。這個應用程序可以通過便於訪問過去通信中的寶貴信息來提高工作場所的生產力。
為了生成答案,我們將通過 Langchain 中的 HuggingFace 整合使用 Mixtral 7B Instruct。要使用該模型,你需要一個 HuggingFace 訪問令牌,你可以按照這裡的說明生成。
你可以在 Colab 上跟著做,或者下載 notebook。


tag關於數據集
本教程使用的數據集是用 GPT-4 生成的,旨在複制 Blueprint AI 的 Slack 頻道聊天記錄。Blueprint 是一家虛構的 AI 初創公司,正在開發自己的基礎模型。你可以在這裡下載數據集。
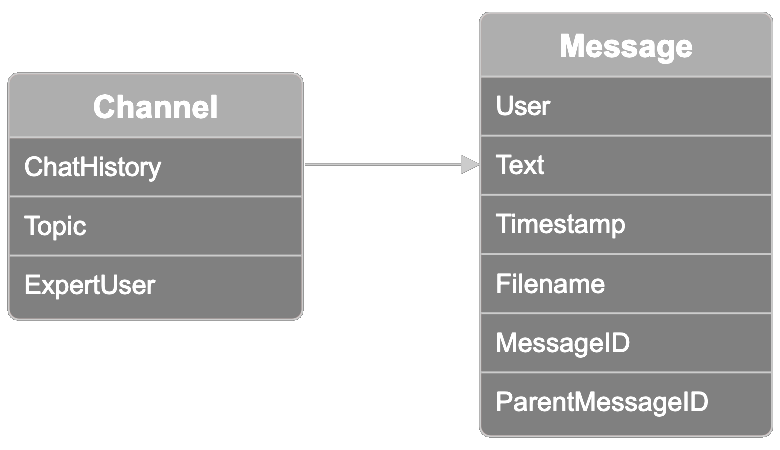
數據按頻道組織,每個頻道代表一組相關的 Slack 對話串。每個頻道都有一個主題標籤,有十個主題選項:模型分發、模型訓練、模型微調、倫理和偏見消除、用戶反饋、銷售、市場營銷、模型入職、創意設計和產品管理。其中一個參與者被稱為"專家用戶"。你可以使用這個欄位來驗證查詢主題最專業用戶的結果,我們將在下面展示如何做到這一點。
每個頻道還包含聊天歷史記錄,每個頻道最多可包含 100 條消息的對話串。數據集中的每條消息都包含以下信息:
- 用戶:發送消息的人
- 消息文本:用戶發送的消息
- 時間戳:消息發送的時間
- 文件名:用戶可能附加到消息的文件名
- 消息 ID
- 父消息 ID:如果消息是在另一條消息產生的對話串中,則顯示該 ID
tag設置環境
首先,安裝所有必要的組件:
pip install -U pymilvus
pip install -U "pymilvus[model]"
pip install langchain
pip install langchain-community
下載數據集:
import os
if not os.path.exists("chat_history.json"):
!wget https://raw.githubusercontent.com/jina-ai/workshops/main/notebooks/embeddings/milvus/chat_history.json在環境變量中設置你的 Jina AI API Key。你可以在這裡生成一個。
import os
import getpass
os.environ["JINAAI_API_KEY"] = getpass.getpass(prompt="Jina AI API Key: ")對你的 Hugging Face Token 也做同樣的操作。你可以在這裡找到如何生成。確保將其設置為 READ 以訪問 Hugging Face Hub。
os.environ["HUGGINGFACEHUB_API_TOKEN"] = getpass.getpass(prompt="Hugging Face Token: ")tag創建 Milvus Collection
創建 Milvus Collection 來索引數據:
from pymilvus import MilvusClient, DataType
# Specify a local file name as uri parameter of MilvusClient to use Milvus Lite
client = MilvusClient("milvus_jina.db")
schema = MilvusClient.create_schema(
auto_id=True,
enable_dynamic_field=True,
)
schema.add_field(field_name="id", datatype=DataType.INT64, description="The Primary Key", is_primary=True)
schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, description="The Embedding Vector", dim=768)
index_params = client.prepare_index_params()
index_params.add_index(field_name="embedding", metric_type="COSINE", index_type="AUTOINDEX")
client.create_collection(collection_name="milvus_jina", schema=schema, index_params=index_params)tag準備資料
解析聊天歷史並提取元數據:
import json
with open("chat_history.json", "r", encoding="utf-8") as file:
chat_data = json.load(file)
messages = []
metadatas = []
for channel in chat_data:
chat_history = channel["chat_history"]
chat_topic = channel["topic"]
chat_expert = channel["expert_user"]
for message in chat_history:
text = f"""{message["user"]}: {message["message"]}"""
messages.append(text)
meta = {
"time_stamp": message["time_stamp"],
"file_name": message["file_name"],
"parent_message_nr": message["parent_message_nr"],
"channel": chat_topic,
"expert": True if message["user"] == chat_expert else False
}
metadatas.append(meta)
tag嵌入聊天資料
使用 Jina Embeddings v2 為每條訊息建立嵌入向量,以便檢索相關聊天資訊:
from pymilvus.model.dense import JinaEmbeddingFunction
jina_ef = JinaEmbeddingFunction("jina-embeddings-v2-base-en")
embeddings = jina_ef.encode_documents(messages)tag索引聊天資料
索引訊息、它們的嵌入向量和相關元數據:
collection_data = [{
"message": message,
"embedding": embedding,
"metadata": metadata
} for message, embedding, metadata in zip(messages, embeddings, metadatas)]
data = client.insert(
collection_name="milvus_jina",
data=collection_data
)tag查詢聊天歷史
現在提出一個問題:
query = "Who knows the most about encryption protocols in my team?"現在嵌入查詢並檢索相關訊息。在這裡我們檢索五條最相關的訊息,並使用 Jina Reranker v1 進行重新排序:
from pymilvus.model.reranker import JinaRerankFunction
query_vectors = jina_ef.encode_queries([query])
results = client.search(
collection_name="milvus_jina",
data=query_vectors,
limit=5,
)
results = results[0]
ids = [results[i]["id"] for i in range(len(results))]
results = client.get(
collection_name="milvus_jina",
ids=ids,
output_fields=["id", "message", "metadata"]
)
jina_rf = JinaRerankFunction("jina-reranker-v1-base-en")
documents = [results[i]["message"] for i in range(len(results))]
reranked_documents = jina_rf(query, documents)
reranked_messages = []
for reranked_document in reranked_documents:
idx = reranked_document.index
reranked_messages.append(results[idx])最後,使用 Mixtral 7B Instruct 和重新排序的訊息作為上下文來生成對查詢的回答:
from langchain.prompts import PromptTemplate
from langchain_community.llms import HuggingFaceEndpoint
llm = HuggingFaceEndpoint(repo_id="mistralai/Mixtral-8x7B-Instruct-v0.1")
prompt = """<s>[INST] Context information is below.\\n
It includes the five most relevant messages to the query, sorted based on their relevance to the query.\\n
---------------------\\n
{context_str}\\\\n
---------------------\\n
Given the context information and not prior knowledge,
answer the query. Please be brief, concise, and complete.\\n
If the context information does not contain an answer to the query,
respond with \\"No information\\".\\n
Query: {query_str}[/INST] </s>"""
prompt = PromptTemplate(template=prompt, input_variables=["query_str", "context_str"])
llm_chain = prompt | llm
answer = llm_chain.invoke({"query_str":query, "context_str":reranked_messages})
print(f"\n\nANSWER:\n\n{answer}")我們問題的答案是:
「根據上下文資訊,User5 似乎是你團隊中最了解加密協議的人。他們提到新協議顯著提高了資料安全性,特別是在雲端部署方面。」
如果你閱讀 chat_history.json 中的訊息,你可以自行驗證 User5 是否確實是最專業的用戶。
tag總結
我們已經看到如何設置 Milvus Lite、使用 Jina Embeddings v2 嵌入聊天資料,以及使用 Jina Reranker v1 優化搜尋結果,這些都應用在搜尋 Slack 聊天歷史的實際案例中。Milvus Lite 簡化了 Python 應用程式開發,無需複雜的服務器設置。它與 Jina Embeddings 和 Reranker 的整合,旨在讓您更輕鬆地獲取工作場所中的重要資訊,從而提高生產力。
tag立即使用 Jina AI 模型和 Milvus
集成了 Jina Embeddings 和 Reranker 的 Milvus Lite 為您提供完整的處理流程,只需幾行程式碼即可使用。
我們很想聽聽您的使用案例,並討論 Jina AI Milvus 擴展如何滿足您的業務需求。通過我們的網站或我們的 Discord 頻道與我們聯繫,分享您的回饋並了解我們最新的模型。如果您對 Milvus 和 Jina AI 的整合有任何疑問,歡迎加入 Milvus 社群。
