



Jina CLIP v1(jina-clip-v1)是一個新的多模態嵌入模型,它擴展了 OpenAI 的原始 CLIP 模型的功能。透過這個新模型,使用者只需要一個嵌入模型,就能在純文本和文本-圖像跨模態檢索方面獲得最先進的效能。Jina AI 在純文本檢索方面比 OpenAI CLIP 的效能提升了 165%,在圖像對圖像檢索方面提升了 12%,而在文本對圖像和圖像對文本任務方面的效能則相同或略有提升。這種增強的效能使得 Jina CLIP v1 在處理多模態輸入時不可或缺。
在本文中,我們首先將討論原始 CLIP 模型的缺點,以及我們如何使用獨特的協同訓練方法來解決這些問題。然後,我們將展示我們的模型在各種檢索基準測試上的效果。最後,我們將提供詳細說明,指導使用者如何透過我們的 Embeddings API 和 Hugging Face 開始使用 Jina CLIP v1。
tag用於多模態 AI 的 CLIP 架構
2021 年 1 月,OpenAI 發布了 CLIP(對比語言-圖像預訓練)模型。CLIP 擁有簡單但巧妙的架構:它將兩個嵌入模型(一個用於文本,一個用於圖像)組合成單一模型,並共享同一個輸出嵌入空間。其文本和圖像嵌入可以直接相互比較,使得文本嵌入和圖像嵌入之間的距離能夠反映出該文本描述圖像的程度,反之亦然。
這在多模態信息檢索和零樣本圖像分類中證明非常有用。無需進一步特殊訓練,CLIP 就能很好地將圖像分類到具有自然語言標籤的類別中。

原始 CLIP 中的文本嵌入模型是一個只有 6300 萬參數的自定義神經網絡。在圖像方面,OpenAI 發布的 CLIP 提供了一系列 ResNet 和 ViT 模型。每個模型都經過了各自模態的預訓練,然後通過帶有標題的圖像進行訓練,為準備好的圖像-文本對生成相似的嵌入。
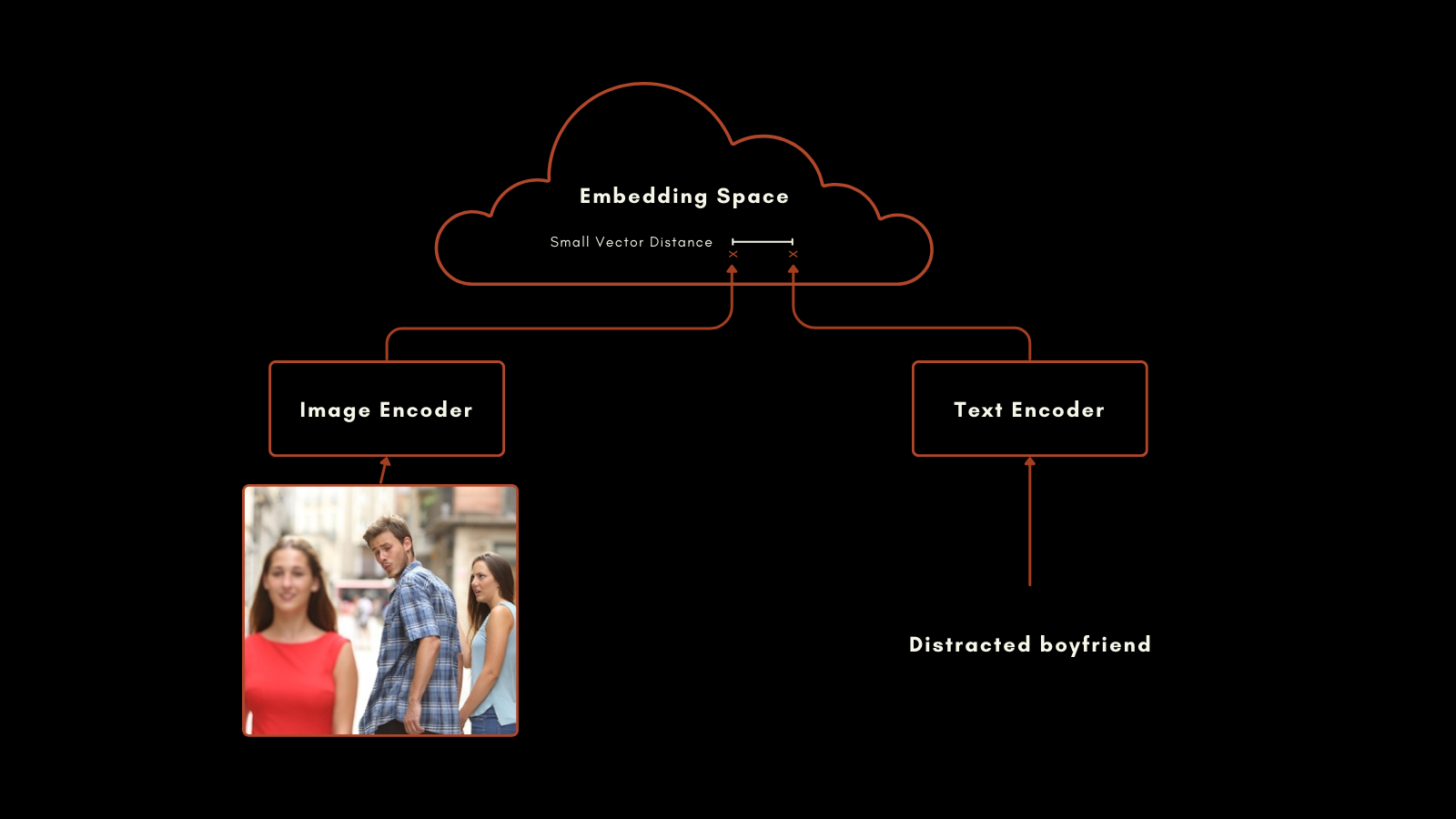
這種方法產生了令人印象深刻的結果。特別值得注意的是它的零樣本分類效能。例如,即使訓練數據中沒有包含太空人的標記圖像,CLIP 也能基於其對文本和圖像中相關概念的理解,正確識別太空人的圖片。
然而,OpenAI 的 CLIP 有兩個重要缺點:
- 首先是其文本輸入容量非常有限。它最多可以接受 77 個標記的輸入,但實證分析顯示,在實際使用中它產生嵌入時使用的標記不超過 20 個。這是因為 CLIP 是從帶有標題的圖像訓練而來,而標題往往非常簡短。這與目前支持數千個標記的文本嵌入模型形成對比。
- 其次,在純文本檢索場景中,其文本嵌入的效能非常差。圖像標題是一種非常有限的文本類型,無法反映文本嵌入模型預期支持的廣泛使用場景。
在大多數實際使用案例中,純文本和圖像-文本檢索是結合使用的,或者至少兩者都可用於任務。為純文本任務維護第二個嵌入模型實際上使 AI 框架的規模和複雜性翻倍。
Jina AI 的新模型直接解決了這些問題,jina-clip-v1 利用近年來的進展,為涉及文本和圖像模態所有組合的任務帶來了最先進的效能。
tagJina CLIP v1 簡介
Jina CLIP v1 保留了 OpenAI 原始 CLIP 的架構:兩個經過協同訓練以產生相同嵌入空間輸出的模型。
在文本編碼方面,我們改編了 Jina BERT v2 架構,該架構用於 Jina Embeddings v2 模型。這個架構支持最先進的 8k 標記輸入窗口,並輸出 768 維向量,能夠從更長的文本中產生更準確的嵌入。這比原始 CLIP 模型支持的 77 個標記輸入多出 100 多倍。
在圖像嵌入方面,我們使用了北京人工智能研究院的最新模型:EVA-02 模型。我們已經實證比較了多個圖像 AI 模型,在相似預訓練的跨模態環境中對它們進行測試,EVA-02 明顯優於其他模型。它的模型規模也與 Jina BERT 架構相當,因此圖像和文本處理任務的計算負載大致相同。
這些選擇為使用者帶來了重要的好處:
- 在所有基準測試和所有模態組合上都有更好的效能,特別是在純文本嵌入效能方面有很大提升。
EVA-02在圖像-文本和純圖像任務上都表現出實證上的優越效能,加上 Jina AI 的額外訓練,提升了純圖像效能。- 支持更長的文本輸入。Jina Embeddings 的 8k 標記輸入支持使其能夠處理詳細的文本信息並將其與圖像關聯。
- 因為這個多模態模型即使在非多模態場景中也具有高效能,所以在空間、計算、代碼維護和複雜性方面都能節省大量成本。
tag訓練
我們高效能多模態 AI 方案的一部分是我們的訓練數據和程序。我們注意到,圖像標題中使用的文本非常短是 CLIP 類模型在純文本效能不佳的主要原因,我們的訓練明確設計用於解決這個問題。
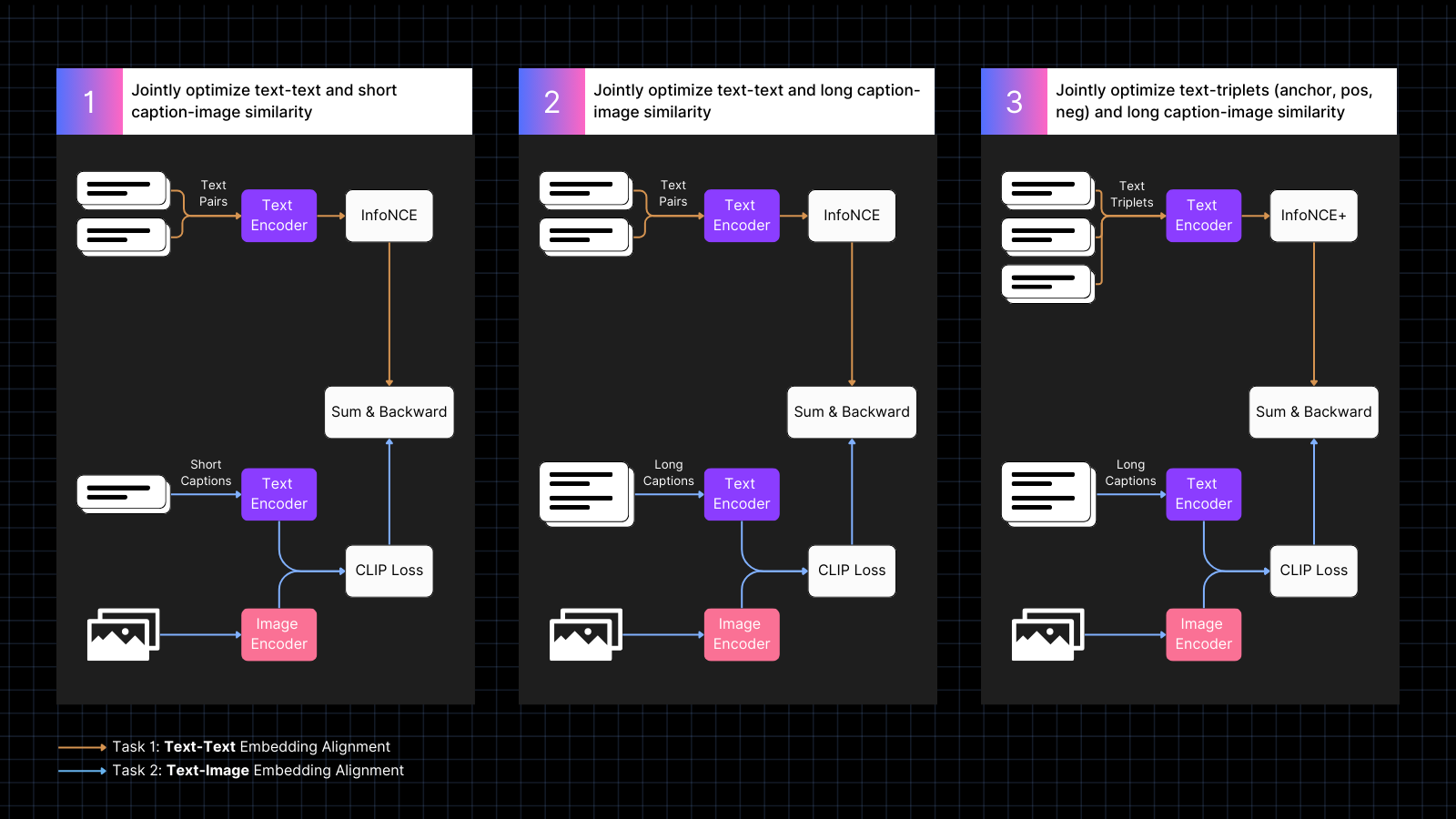
訓練分為三個步驟:
- 使用帶標題的圖像數據來學習對齊圖像和文本嵌入,並與具有相似含義的文本對交錯進行。這種協同訓練同時優化這兩種任務。在這個階段,模型的純文本效能會下降,但不會像僅使用圖像-文本對訓練那樣嚴重。
- 使用合成數據,將圖像與由 AI 模型生成的更長且描述該圖像的文本對齊。同時繼續使用純文本對進行訓練。在這個階段,模型學會了關注與圖像相關的更長文本。
- 使用具有難負樣本的文本三元組來進一步提升純文本效能,通過學習進行更精細的語義區分。同時,繼續使用圖像和長文本的合成對進行訓練。在這個階段,純文本效能顯著提升,而模型不會失去任何圖像-文本能力。
如需了解有關訓練和模型架構的更多詳細信息,請閱讀我們最近的論文:
tag多模態嵌入的新突破
我們評估了 Jina CLIP v1 在純文本、純圖像以及涉及兩種輸入模態的跨模態任務中的表現。我們使用 MTEB 檢索基準來評估純文本性能。對於純圖像任務,我們使用了 CIFAR-100 基準。對於跨模態任務,我們在 Flickr8k、Flickr30K 和 MSCOCO Captions 上進行評估,這些都包含在 CLIP Benchmark 中。
結果總結如下表:
| Model | Text-Text | Text-to-Image | Image-to-Text | Image-Image |
|---|---|---|---|---|
| jina-clip-v1 | 0.429 | 0.899 | 0.803 | 0.916 |
| openai-clip-vit-b16 | 0.162 | 0.881 | 0.756 | 0.816 |
| % increase vs OpenAI CLIP |
165% | 2% | 6% | 12% |
從這些結果中可以看出,jina-clip-v1 在所有類別中都優於 OpenAI 的原始 CLIP,並且在純文本和純圖像檢索方面表現顯著更好。平均來看,性能提升了 46%。
你可以在我們最近的論文中找到更詳細的評估。
tagEmbeddings API 入門
你可以使用 Jina Embeddings API 輕鬆地將 Jina CLIP v1 整合到你的應用程序中。
下面的代碼展示了如何使用 Python 中的 requests 包調用 API 來獲取文本和圖像的嵌入。它將文本字符串和圖像 URL 傳遞給 Jina AI 服務器,並返回兩種編碼。
<YOUR_JINA_AI_API_KEY> 替換為已激活的 Jina API 密鑰。你可以從 Jina Embeddings 網頁獲得一個包含一百萬個免費令牌的試用密鑰。import requests
import numpy as np
from numpy.linalg import norm
cos_sim = lambda a,b: (a @ b.T) / (norm(a)*norm(b))
url = 'https://api.jina.ai/v1/embeddings'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer <YOUR_JINA_AI_API_KEY>'
}
data = {
'input': [
{"text": "Bridge close-shot"},
{"url": "https://fastly.picsum.photos/id/84/1280/848.jpg?hmac=YFRYDI4UsfbeTzI8ZakNOR98wVU7a-9a2tGF542539s"}],
'model': 'jina-clip-v1',
'encoding_type': 'float'
}
response = requests.post(url, headers=headers, json=data)
sim = cos_sim(np.array(response.json()['data'][0]['embedding']), np.array(response.json()['data'][1]['embedding']))
print(f"Cosine text<->image: {sim}")
tag與主要 LLM 框架的整合
Jina CLIP v1 已經可以在 LlamaIndex 和 LangChain 中使用:
- LlamaIndex:使用
JinaEmbedding與MultimodalEmbedding基類,並調用get_image_embeddings或get_text_embeddings。 - LangChain:使用
JinaEmbeddings,並調用embed_images或embed_documents。
tag定價
文本和圖像輸入都按令牌消耗計費。
對於英文文本,我們通過實證計算得出,平均每個詞需要 1.1 個令牌。
對於圖像,我們計算覆蓋圖像所需的 224x224 像素瓦片數量。某些瓦片可能部分為空白,但計費相同。每個瓦片處理成本為 1,000 個令牌。
範例
對於一張 750x500 像素的圖像:
- 圖像被分為 224x224 像素的瓦片。
- 計算瓦片數量,將寬度(像素)除以 224,然後向上取整。
750/224 ≈ 3.35 → 4 - 對高度(像素)重複相同操作:
500/224 ≈ 2.23 → 3
- 計算瓦片數量,將寬度(像素)除以 224,然後向上取整。
- 此範例中所需的瓦片總數為:
4(水平)x 3(垂直)= 12 個瓦片 - 成本將為 12 x 1,000 = 12,000 個令牌
tag企業支援
我們為購買 110 億令牌生產部署方案的用戶推出新的權益。這包括:
- 與我們的產品和工程團隊進行三小時的諮詢,討論您的具體使用案例和需求。
- 為您的 RAG(檢索增強生成)或向量搜索用例定制的 Python notebook,展示如何將 Jina AI 的模型整合到您的應用中。
- 指派專屬客戶經理和優先電子郵件支援,以確保您的需求得到及時有效的滿足。
tagHugging Face 上的開源 Jina CLIP v1
Jina AI 致力於開源搜索基礎,為此,我們在 Hugging Face 上以 Apache 2.0 許可免費提供此模型。
你可以在 jina-clip-v1 的 Hugging Face 模型頁面上找到在自己的系統或雲端安裝上下載和運行此模型的示例代碼。

tag總結
Jina AI 的最新模型 — jina-clip-v1 — 代表了多模態嵌入模型的重大進展,相比 OpenAI 的 CLIP 提供了顯著的性能提升。在純文本和純圖像檢索任務中取得了顯著改進,同時在文本到圖像和圖像到文本任務中也表現出色,為複雜的嵌入用例提供了一個有前途的解決方案。
由於資源限制,目前這個模型僅支援英文文字。我們正在努力擴展其功能以支援更多語言。
