


今天,我們很高興宣布 jina-embeddings-v3,這是一個具有 5.7 億參數的前沿文本嵌入模型。它在**多語言**數據和**長文本**檢索任務上達到了最先進的性能,支持長達 8192 個 token 的輸入長度。該模型具有特定任務的低秩適應(LoRA)適配器,使其能夠為各種任務生成高質量的嵌入,包括**查詢文檔檢索**、**聚類**、**分類**和**文本匹配**。
在 MTEB 英語、多語言和 LongEmbed 的評估中,jina-embeddings-v3 在英語任務上優於 OpenAI 和 Cohere 的最新專有嵌入,同時在所有多語言任務上也超越了 multilingual-e5-large-instruct。憑藉 1024 的預設輸出維度,得益於套娃表示學習(MRL)的整合,用戶可以任意將嵌入維度截斷至 32 而不影響性能。


jina-embeddings-v2-(zh/es/de) 指的是我們的雙語模型套件,該套件僅在中文、西班牙文和德文的單語言和跨語言任務上進行測試,不包括其他語言。此外,我們沒有報告 openai-text-embedding-3-large 和 cohere-embed-multilingual-v3.0 的分數,因為這些模型並未在全範圍的多語言和跨語言 MTEB 任務上進行評估。
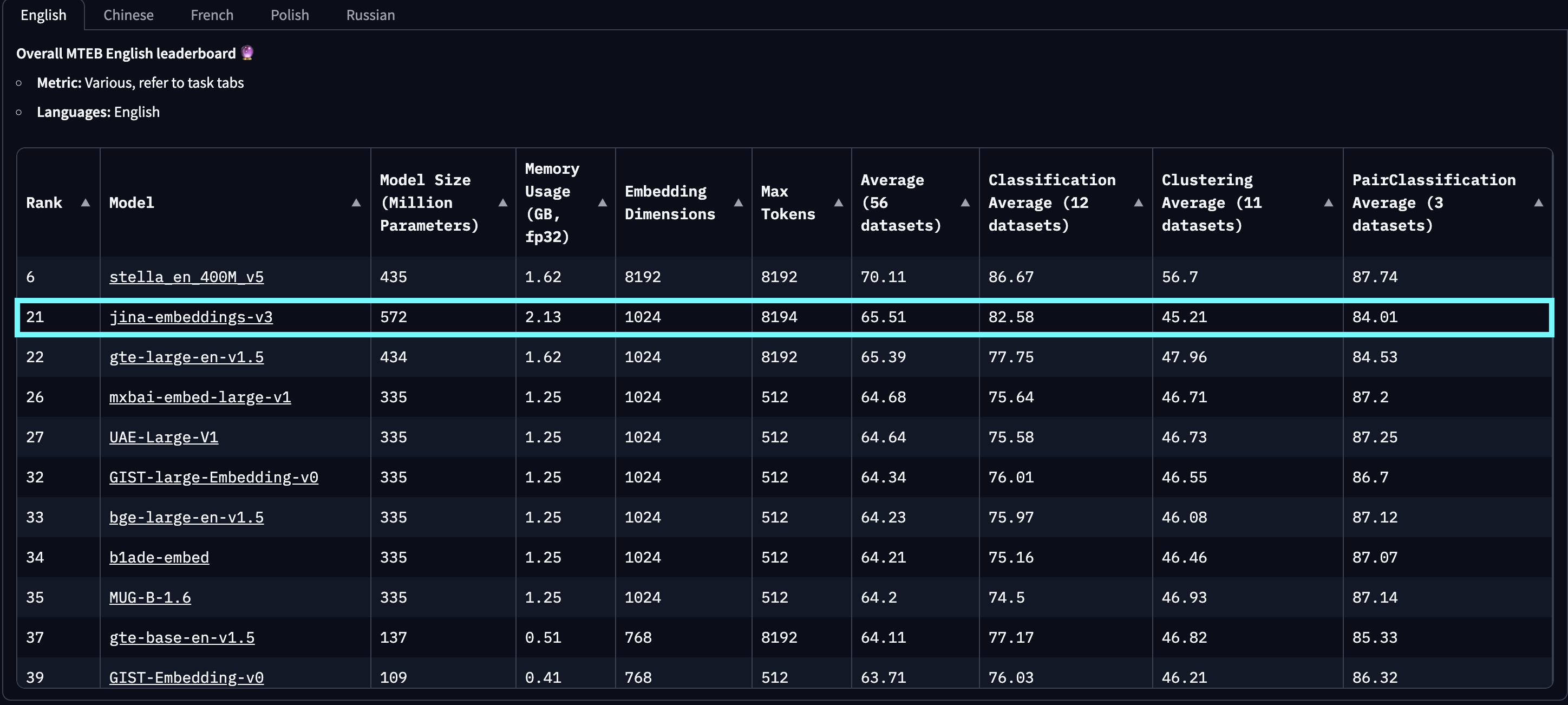
baai-bge-m3 使用的固定位置嵌入和 jina-embeddings-v2 使用的基於 ALiBi 的方法。自 2024 年 9 月 18 日發布以來,jina-embeddings-v3 是**最佳**多語言模型,並在 MTEB 英語排行榜上參數少於 10 億的模型中排名**第二**。v3 總共支持 89 種語言,其中包括 30 種表現最佳的語言:阿拉伯語、孟加拉語、中文、丹麥語、荷蘭語、英語、芬蘭語、法語、格魯吉亞語、德語、希臘語、印地語、印尼語、義大利語、日語、韓語、拉脫維亞語、挪威語、波蘭語、葡萄牙語、羅馬尼亞語、俄語、斯洛伐克語、西班牙語、瑞典語、泰語、土耳其語、烏克蘭語、烏爾都語和越南語。

jina-embeddings-v2 相比也顯示出超線性的改進。此圖表是通過從 MTEB 排行榜選擇前 100 個嵌入模型創建的,排除了那些沒有規模信息的模型(通常是閉源或專有模型)。明顯的惡意提交也被過濾掉了。此外,與最近受到關注的基於 LLM 的嵌入(如 e5-mistral-7b-instruct)相比,後者的參數規模為 71 億(大 12 倍)且輸出維度為 4096(大 4 倍),但在 MTEB 英語任務上僅提升了 1%,jina-embeddings-v3 是一個更具成本效益的解決方案,更適合生產和邊緣計算環境。
tag模型架構
| 特性 | 描述 |
|---|---|
| 基礎 | jina-XLM-RoBERTa |
| 基礎參數量 | 559M |
| 含 LoRA 參數量 | 572M |
| 最大輸入 tokens | 8192 |
| 最大輸出維度 | 1024 |
| 層數 | 24 |
| 詞彙量 | 250K |
| 支援語言數量 | 89 |
| 注意力機制 | FlashAttention2,也可不使用 |
| 池化方式 | Mean pooling |
jina-embeddings-v3 的架構如下圖所示。為了實現骨幹架構,我們對 XLM-RoBERTa 模型進行了幾項關鍵修改:(1) 實現長文本序列的有效編碼,(2) 允許特定任務的嵌入編碼,以及 (3) 採用最新技術提升整體模型效率。我們繼續使用原始的 XLM-RoBERTa 分詞器。雖然 jina-embeddings-v3 擁有 5.7 億參數,比 1.37 億參數的 jina-embeddings-v2 更大,但仍遠小於從 LLM 微調的嵌入模型。

jina-XLM-RoBERTa 模型,包含四個不同任務的五個 LoRA 適配器。jina-embeddings-v3 的主要創新在於使用 LoRA 適配器。我們引入了五個特定任務的 LoRA 適配器來優化四種任務的嵌入。模型的輸入包含兩部分:文本(待嵌入的長文檔)和任務。jina-embeddings-v3 支援四種任務並實現了五個可選的適配器:retrieval.query 和 retrieval.passage 用於非對稱檢索任務中的查詢和段落嵌入,separation 用於聚類任務,classification 用於分類任務,以及 text-matching 用於語義相似度等任務,如 STS 或對稱檢索。LoRA 適配器僅佔總參數量的不到 3%,對計算造成的額外開銷極小。
為了進一步提升性能並減少記憶體消耗,我們整合了 FlashAttention 2,支援啟用點檢查,並使用 DeepSpeed 框架進行高效的分散式訓練。
tag入門指南
tag通過 Jina AI Search Foundation API
使用 jina-embeddings-v3 最簡單的方法是訪問 Jina AI 首頁並導航到 Search Foundation API 部分。從今天開始,這個模型將成為所有新用戶的預設選項。您可以直接在那裡探索不同的參數和功能。
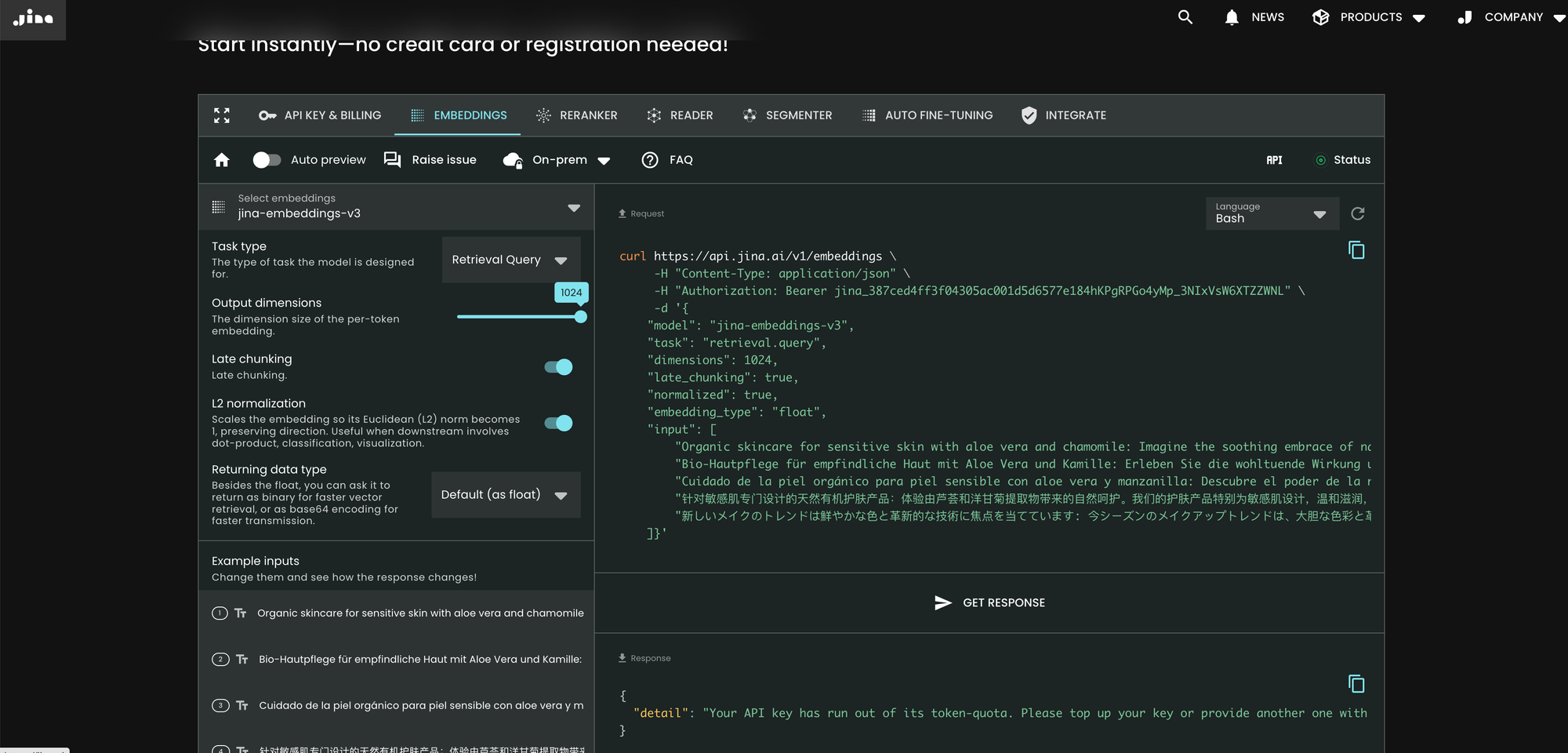
curl https://api.jina.ai/v1/embeddings \
-H "Content-Type: application/json" \
-H "Authorization: Bearer jina_387ced4ff3f04305ac001d5d6577e184hKPgRPGo4yMp_3NIxVsW6XTZZWNL" \
-d '{
"model": "jina-embeddings-v3",
"task": "text-matching",
"dimensions": 1024,
"late_chunking": true,
"input": [
"Organic skincare for sensitive skin with aloe vera and chamomile: ...",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille: Erleben Sie die wohltuende Wirkung...",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla: Descubre el poder ...",
"针对敏感肌专门设计的天然有机护肤产品:体验由芦荟和洋甘菊提取物带来的自然呵护。我们的护肤产品特别为敏感肌设计,...",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています: 今シーズンのメイクアップトレンドは、大胆な色彩と革新的な技術に注目しています。..."
]}'
與 v2 相比,v3 在 API 中引入了三個新參數:task、dimensions 和 late_chunking。
參數 task
task 參數至關重要,必須根據下游任務進行設置。生成的嵌入將針對該特定任務進行優化。詳細資訊請參考下方列表。
task 值 |
任務描述 |
|---|---|
retrieval.passage |
在查詢-文檔檢索任務中嵌入文檔 |
retrieval.query |
在查詢-文檔檢索任務中嵌入查詢 |
separation |
文檔聚類、語料庫視覺化 |
classification |
文本分類 |
text-matching |
(預設)語義文本相似度、一般對稱檢索、推薦、尋找相似項目、去重 |
請注意,API 不是先生成通用的元嵌入,然後用額外的微調 MLP 進行調整。相反,它將特定任務的 LoRA 適配器插入每個 transformer 層(共 24 層)中,並一次性完成編碼。更多詳細資訊可以在我們的 arXiv 論文中找到。
參數 dimensions
dimensions 參數允許使用者以最低成本在空間效率和性能之間做出權衡。由於 jina-embeddings-v3 使用了 MRL 技術,您可以根據需要降低嵌入的維度(甚至可以降到單一維度!)。較小的嵌入對向量數據庫更友好,其性能成本可以從下圖中估算。

參數 late_chunking
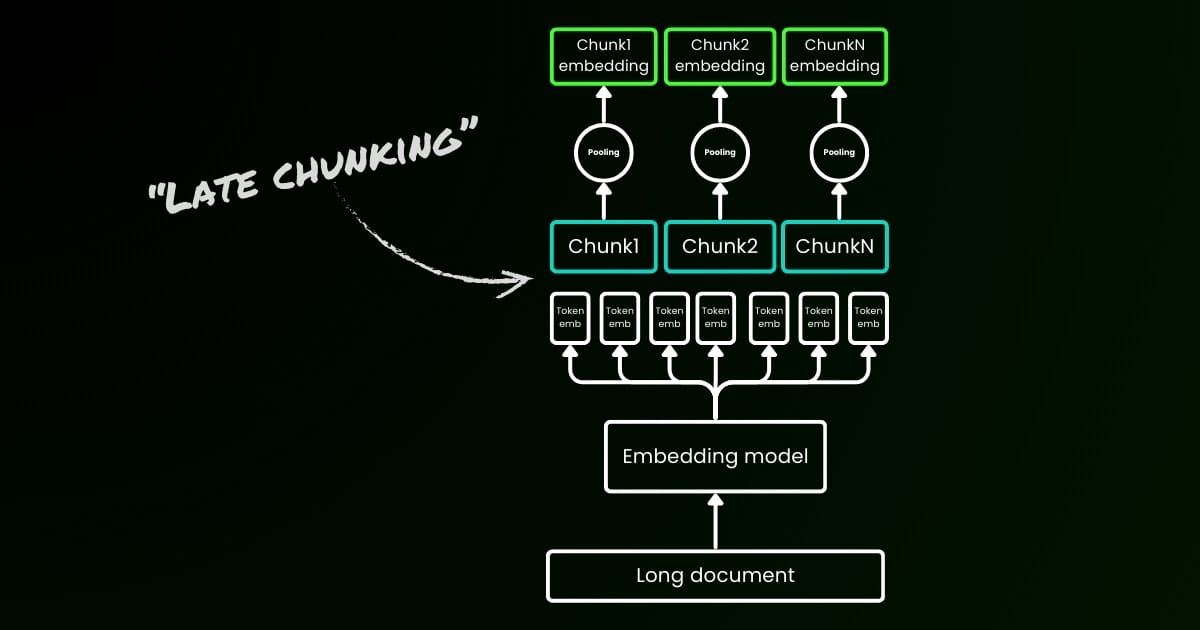
最後,late_chunking 參數控制是否使用我們上個月引入的新分塊方法來編碼一批句子。當設置為 true 時,我們的 API 會將 input 欄位中的所有句子連接起來,作為單一字符串輸入到模型中。換句話說,我們將輸入中的句子視為原本來自同一個章節、段落或文檔。在內部,模型會嵌入這個長的連接字符串,然後執行延遲分塊,返回一個與輸入列表大小相匹配的嵌入列表。因此,列表中的每個嵌入都會受到前面嵌入的影響。
從使用者的角度來看,設置 late_chunking 不會改變輸入或輸出格式。您只會注意到嵌入值的變化,因為它們現在是基於整個前文上下文而不是獨立計算的。在使用時需要知道late_chunking=True 表示每個請求中的總 token 數(通過加總 input 中的所有 token)限制在 8192,這是 jina-embeddings-v3 允許的最大上下文長度。當 late_chunking=False 時,則沒有這樣的限制;總 token 數僅受到Embedding API 的請求限制。
Late Chunking 開啟與關閉:輸入和輸出格式保持一致,唯一的區別在於嵌入值。當啟用 late_chunking 時,嵌入會受到 input 中整個前文內容的影響,而沒有它時,嵌入則是獨立計算的。
tag透過 Azure 和 AWS
jina-embeddings-v3 現已在 AWS SageMaker 和 Azure Marketplace 上提供。


如果需要在這些平台之外或在公司內部部署使用,請注意該模型是根據 CC BY-NC 4.0 授權。如需商業用途諮詢,歡迎與我們聯繫。
tag透過向量數據庫和合作夥伴
我們與 Pinecone、Qdrant 和 Milvus 等向量數據庫提供商,以及 LlamaIndex、Haystack 和 Dify 等 LLM 協調框架密切合作。在發布時,我們很高興地宣布 Pinecone、Qdrant、Milvus 和 Haystack 已經整合了對 jina-embeddings-v3 的支援,包括三個新參數:task、dimensions 和 late_chunking。其他已經整合 v2 API 的合作夥伴只需將模型名稱改為 jina-embeddings-v3 即可支援 v3。不過,他們可能尚未支援 v3 中引入的新參數。
透過 Pinecone

透過 Qdrant

透過 Milvus

透過 Haystack

tag結論
在 2023 年 10 月,我們發布了 jina-embeddings-v2-base-en,這是世界上第一個具有 8K 上下文長度的開源嵌入模型。它是唯一一個支援長上下文並與 OpenAI 的 text-embedding-ada-002 相匹配的文本嵌入模型。今天,經過一年的學習、實驗和寶貴經驗,我們很驕傲地發布 jina-embeddings-v3—這是文本嵌入模型的新里程碑,也是我們公司的重大突破。
通過這次發布,我們繼續在我們所擅長的領域中保持卓越:長上下文嵌入,同時也解決了業界和社群最迫切需要的功能—多語言嵌入。與此同時,我們將性能推向了新的高度。藉由任務特定 LoRA、MRL 和 late chunking 等新功能,我們相信 jina-embeddings-v3 將真正成為各種應用的基礎嵌入模型,包括 RAG、智能代理等。與最近的基於 LLM 的嵌入(如 NV-embed-v1/v2)相比,我們的模型參數效率非常高,使其更適合生產和邊緣設備使用。
展望未來,我們計劃專注於評估和改進 jina-embeddings-v3 在資源有限語言上的表現,並進一步分析由數據可用性限制造成的系統性失誤。此外,jina-embeddings-v3 的模型權重及其創新功能和獨特見解,將作為我們即將推出的模型(包括 jina-clip-v2)的基礎,jina-reranker-v3 和 reader-lm-v2。




