





我們今天發布了 Jina Reranker v2(jina-reranker-v2-base-multilingual),這是我們在搜尋基礎系列中最新且表現最佳的神經重排序模型。使用 Jina Reranker v2,RAG/搜尋系統的開發者可以享受以下功能:
- 多語言:支援超過 100 種語言的相關搜尋結果,表現優於
bge-reranker-v2-m3; - 代理能力:為代理型 RAG 提供最先進的函數調用和文本到 SQL 的文檔重排序功能;
- 程式碼檢索:在程式碼檢索任務上取得頂尖表現,以及
- 超快速度:文檔處理量比
bge-reranker-v2-m3快15 倍,比 jina-reranker-v1-base-en 快 6 倍。
您可以通過我們的 Reranker API 開始使用 Jina Reranker v2,我們為所有新用戶提供 100 萬個免費 token。

在本文中,我們將詳細說明 Jina Reranker v2 支援的這些新功能,展示我們的重排序模型與其他最先進模型(包括 Jina Reranker v1)相比的表現,並解釋使 Jina Reranker v2 在任務準確度和文檔處理量方面達到頂尖表現的訓練過程。
tag回顧:為什麼需要重排序器
雖然嵌入模型是搜尋基礎中使用最廣泛和最被理解的組件,但它們往往為了檢索速度而犧牲精確度。基於嵌入的搜尋模型通常是雙編碼器模型,其中每個文檔都被嵌入並存儲,然後查詢也被嵌入,檢索則基於查詢嵌入與文檔嵌入之間的相似度。在這個模型中,用戶查詢和匹配文檔之間的許多 token 層級互動細節都丟失了,因為原始查詢和文檔永遠無法"看到"對方 – 只有它們的嵌入可以。這可能會降低檢索準確度 – 而這正是交叉編碼器重排序模型擅長的領域。

重排序器通過採用交叉編碼器架構來解決這種細粒度語義的缺失,在該架構中,查詢-文檔對被一起編碼以產生相關性分數,而不是嵌入。研究表明,對於大多數 RAG 系統來說,使用重排序模型可以改善語義理解並減少虛假生成。
tagJina Reranker v2 的多語言支援
在過去,Jina Reranker v1 的特點是在四個關鍵英語基準測試中達到了最先進的表現。今天,我們在 Jina Reranker v2 中大幅擴展了重排序功能,支援超過 100 種語言和跨語言任務!
為了評估 Jina Reranker v2 的跨語言和英語能力,我們通過以下三個基準測試,將其性能與類似的重排序模型進行比較:
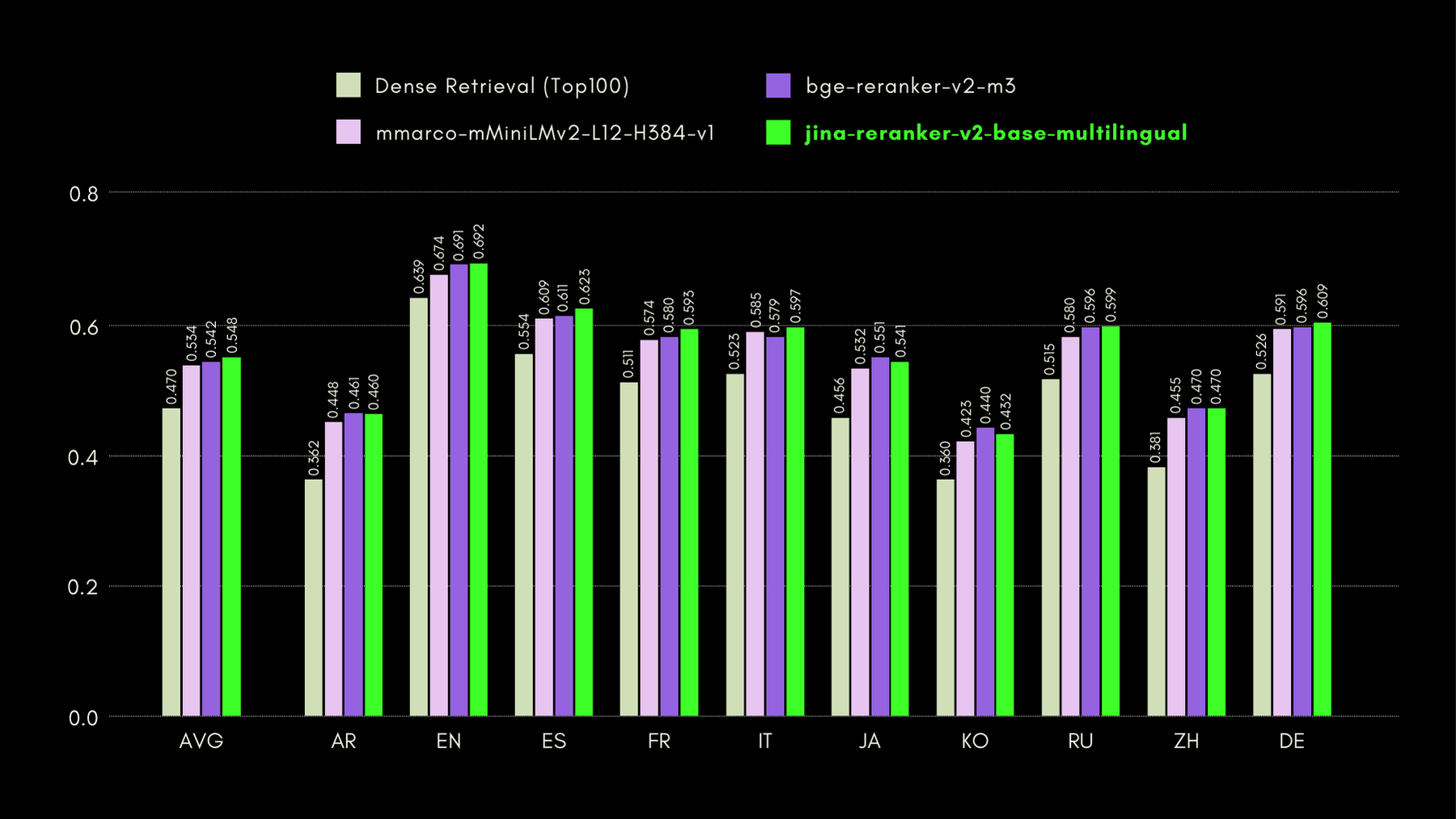
MKQA:多語言知識問答
這個數據集包含 26 種語言的問題和答案,源自真實世界的知識庫,旨在評估問答系統的跨語言性能。MKQA 由英語查詢及其非英語手動翻譯組成,並包含多種語言(包括英語)的答案。
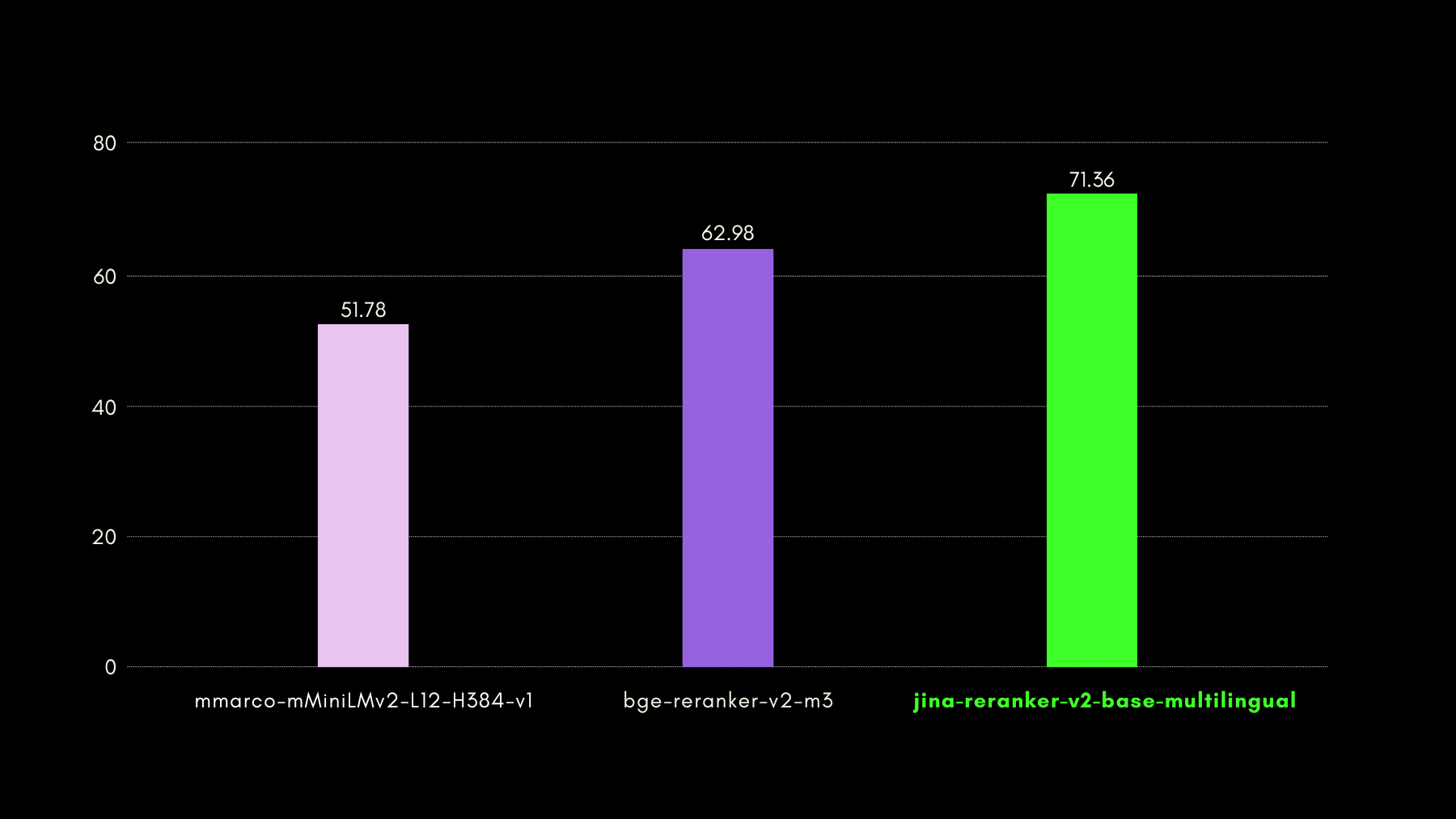
在下圖中,我們報告了每個重排序器的召回率@10 分數,包括作為基準的"密集檢索器",執行傳統的基於嵌入的搜尋:
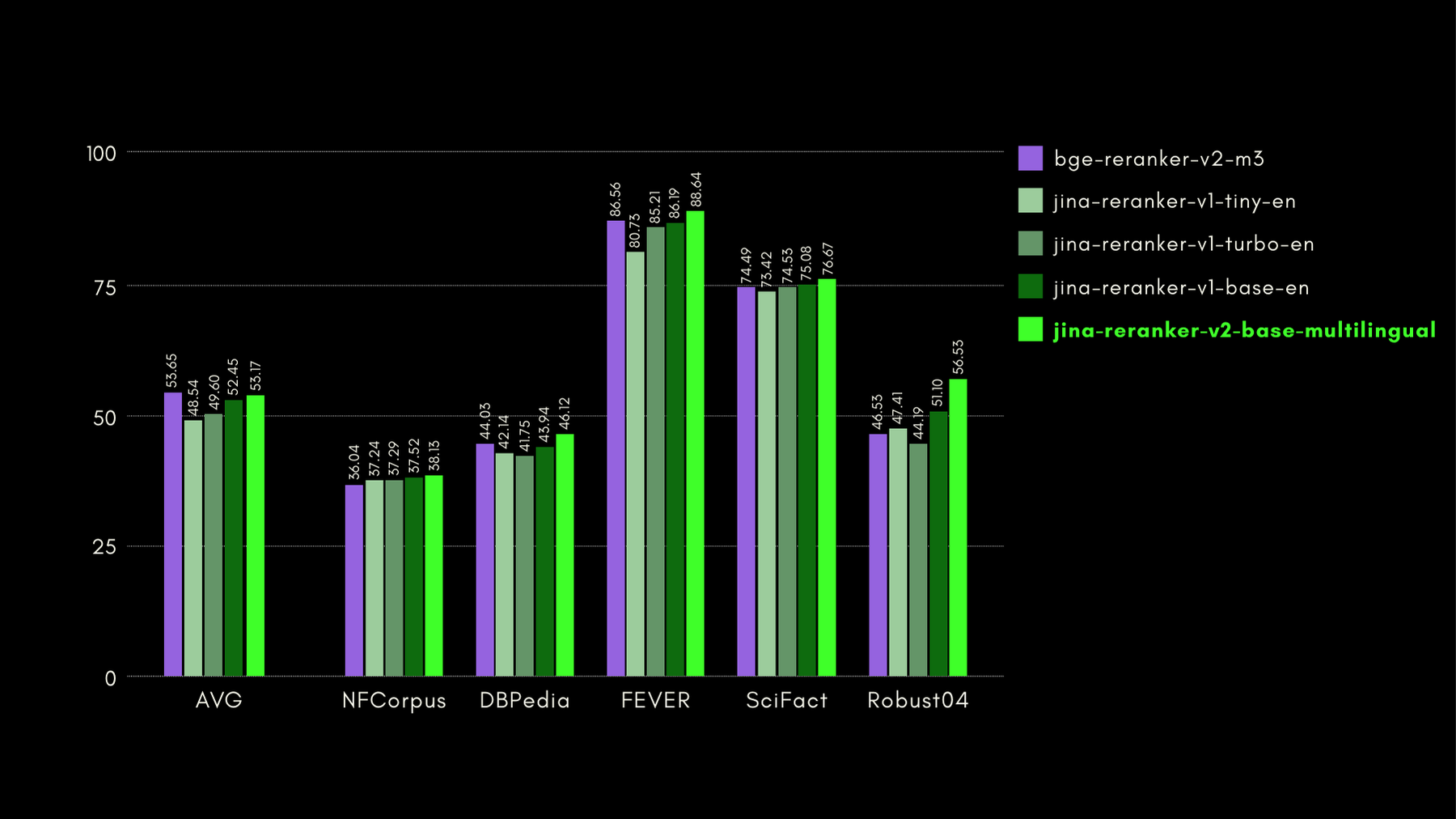
BEIR:多樣化 IR 任務的異構基準
這個開源資料庫包含多種語言的檢索基準,但我們只關注英語任務。這些包含 17 個數據集,沒有任何訓練數據,這些數據集的重點是評估神經或詞法檢索器的檢索準確度。
在下圖中,我們報告了每個重排序器在 BEIR 上的 NDCG@10 分數。BEIR 的結果清楚地表明,jina-reranker-v2-base-multilingual 新引入的多語言功能並不影響其英語檢索能力,而且比起 jina-reranker-v1-base-en 有顯著改進。
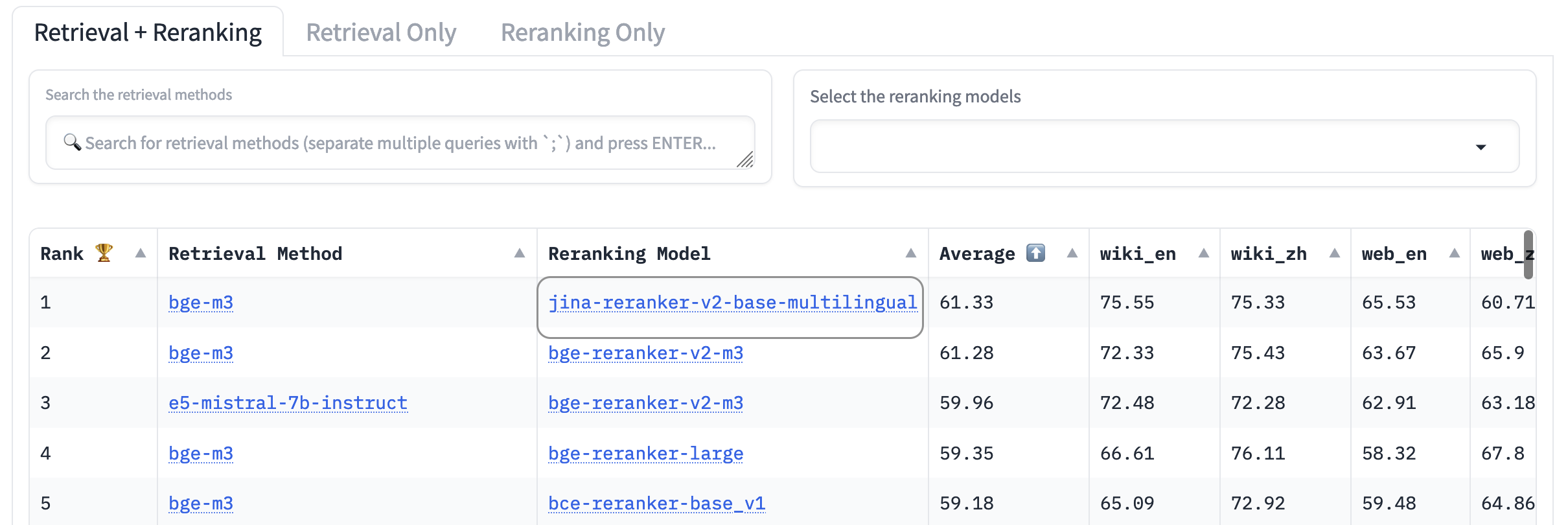
AirBench:自動化異構 IR 基準
我們與北京智源研究院共同創建並發布了用於 RAG 系統的 AirBench 基準測試。該基準測試使用自動生成的合成數據來測試自定義領域和任務,且不會公開發布真實答案,這樣受測模型就無法過度擬合數據集。
在撰寫本文時,jina-reranker-v2-base-multilingual 的表現超過了所有其他重排序模型,在排行榜上名列第一。
tag工具代理回顧:教導 LLM 使用工具
自從幾年前 AI 大爆發以來,人們發現 AI 模型在電腦應該擅長的事情上表現不佳。例如,考慮這個與 Mistral-7b-Instruct-v0.1 的對話:

乍看之下可能覺得是對的,但實際上 203 乘以 7724 等於 1,567,972。
為什麼 LLM 的結果會差了十倍以上?這是因為 LLM 並不是為了進行數學運算或任何其他類型的推理而訓練的,而且缺乏內部遞迴幾乎注定了它們無法解決複雜的數學問題。它們被訓練來說話或執行一些其他不需要精確性的任務。
LLM 很容易產生幻覺答案。從它的角度來看,15,824,772 是一個完全合理的 204 × 7,724 的答案。只不過這個答案完全錯誤。
Agentic RAG 改變了生成式 LLM 的角色,從它們不擅長的思考和知識儲存,轉向它們擅長的閱讀理解和將資訊合成為自然語言。它不是直接生成答案,而是在可用的數據源中找到與你的請求相關的資訊並呈現給語言模型。它的工作不是為你編造答案,而是以自然且回應式的形式呈現由不同系統找到的答案。
我們已經訓練 Jina Reranker v2 使其對 SQL 數據庫架構和函數調用具有敏感度。這需要與傳統文本檢索不同的語義。它必須具備任務和程式碼意識,我們專門為此功能訓練了我們的重排序器。
tagJina Reranker v2 在結構化數據查詢中的應用
雖然嵌入和重排序模型已經將非結構化數據視為一等公民,但大多數模型對結構化表格數據的支持仍然不足。
Jina Reranker v2 了解查詢結構化數據庫(如 MySQL 或 MongoDB)的下游意圖,並根據輸入查詢為結構化表格架構分配正確的相關性分數。
您可以在下面看到,重排序器在 LLM 被提示從自然語言查詢生成 SQL 查詢之前,檢索最相關的表格:
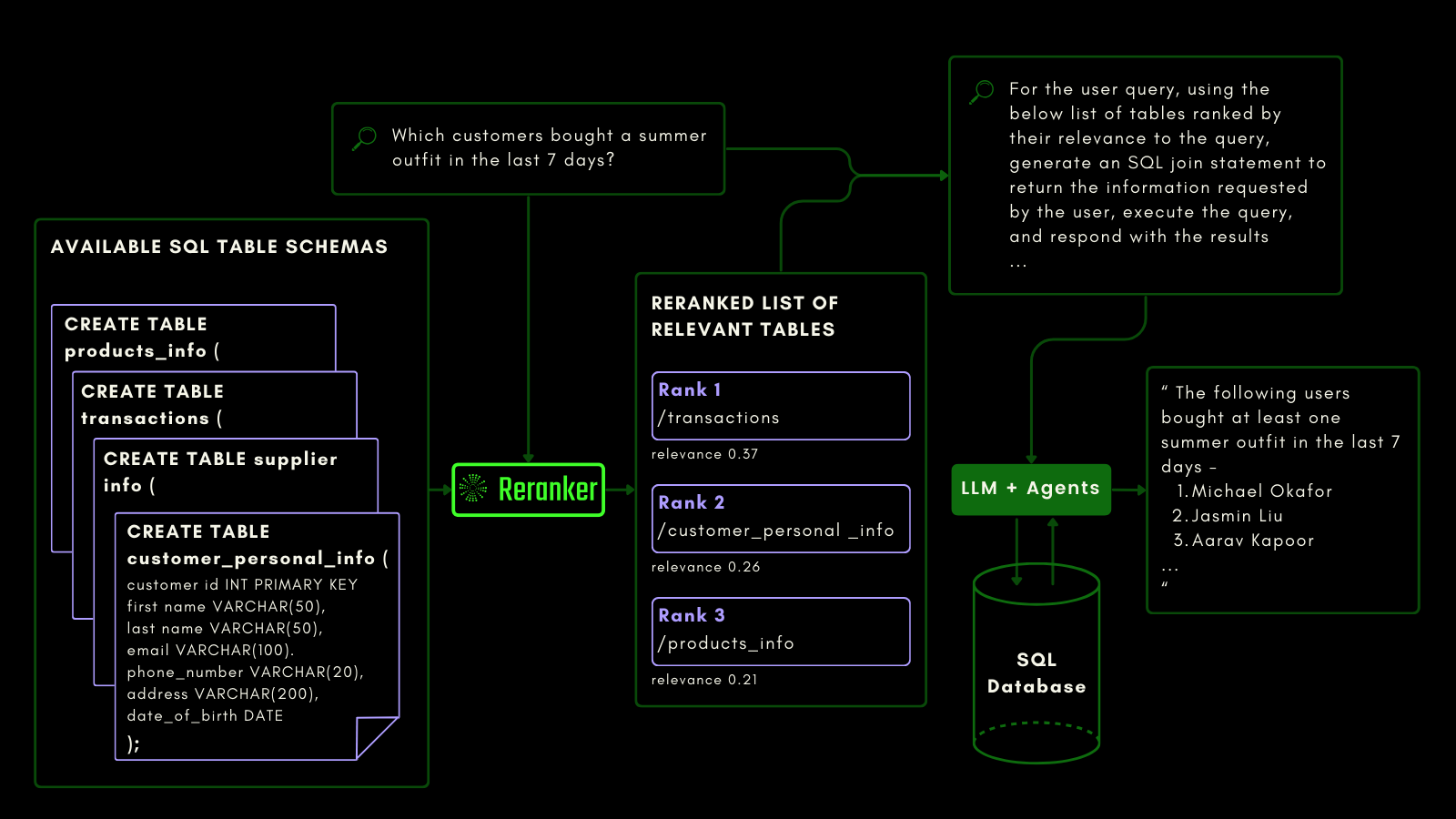
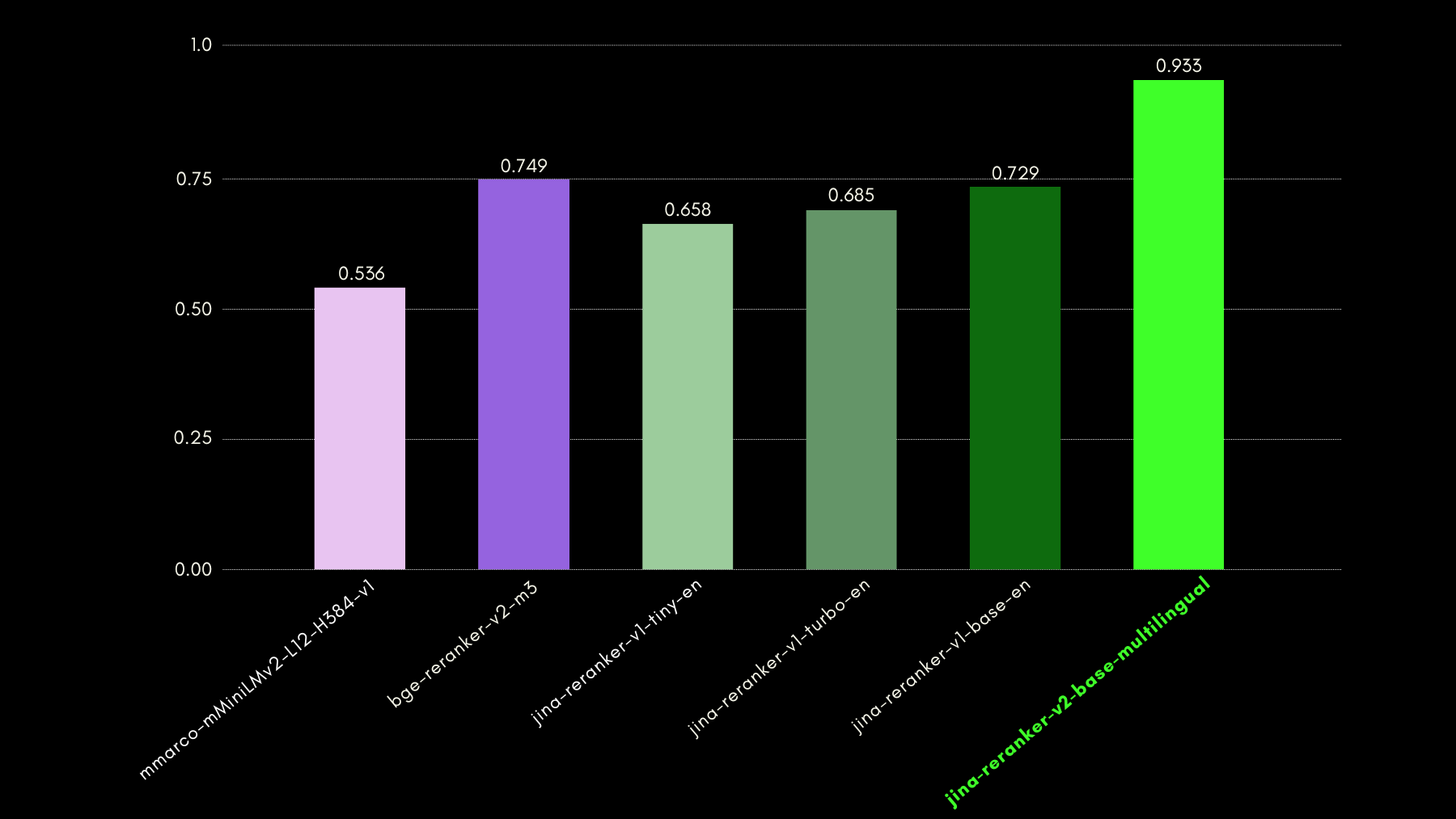
我們使用 NSText2SQL 數據集基準測試評估了查詢感知能力。我們從原始數據集的「instruction」列中提取用自然語言編寫的指令和相應的表格架構。
下圖比較了不同重排序模型在對應自然語言查詢的正確表格架構排名中的成功程度,使用 recall@3 指標:
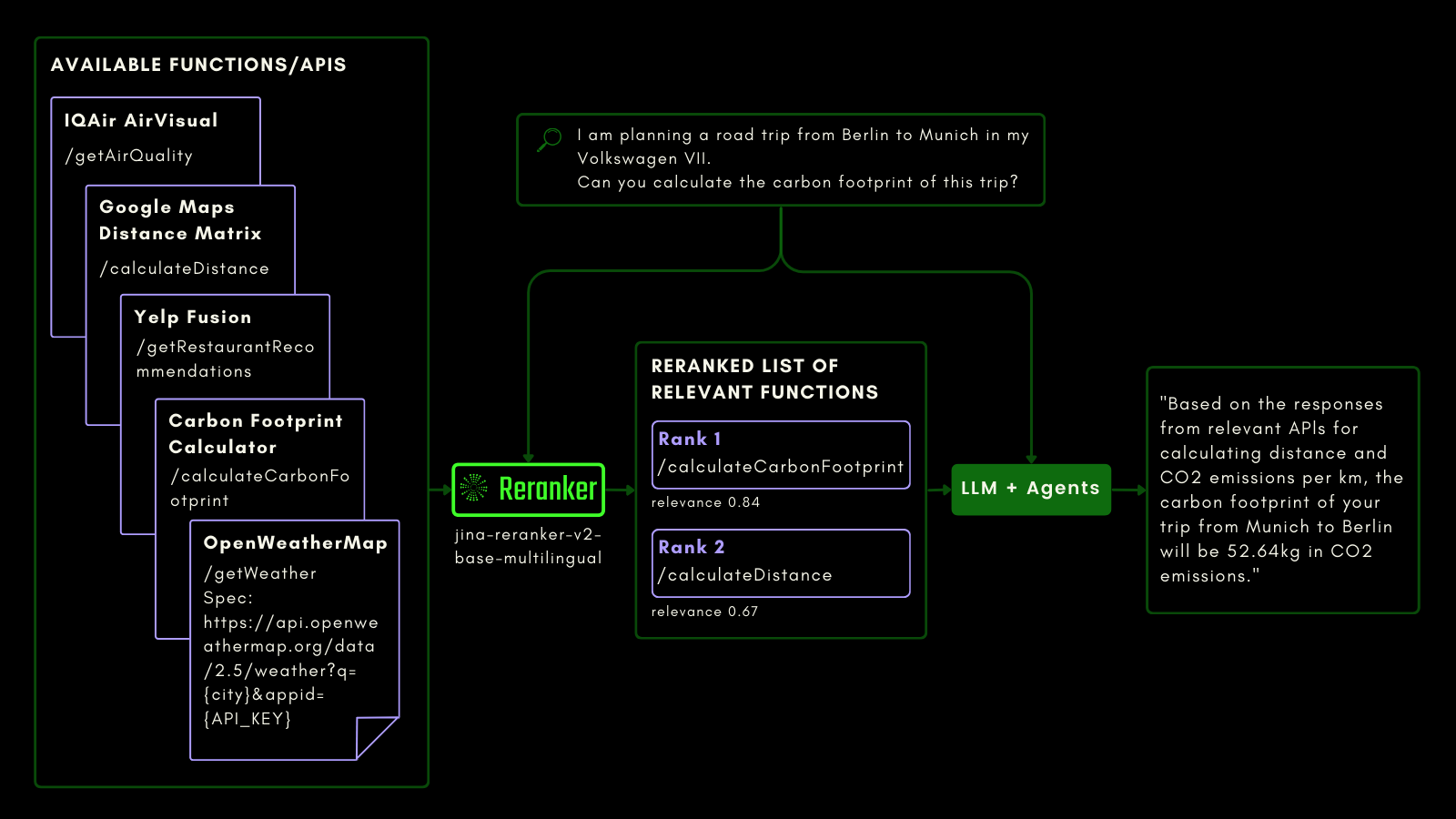
tagJina Reranker v2 在函數調用中的應用
就像查詢 SQL 表格一樣,您可以使用 Agentic RAG 來調用外部工具。考慮到這一點,我們將函數調用整合到 Jina Reranker v2 中,讓它能夠理解您對外部函數的意圖,並相應地為函數規範分配相關性分數。
下面的示意圖(通過一個例子)解釋了 LLM 如何使用 Reranker 來改進函數調用功能,並最終改善 Agentic AI 的用戶體驗。
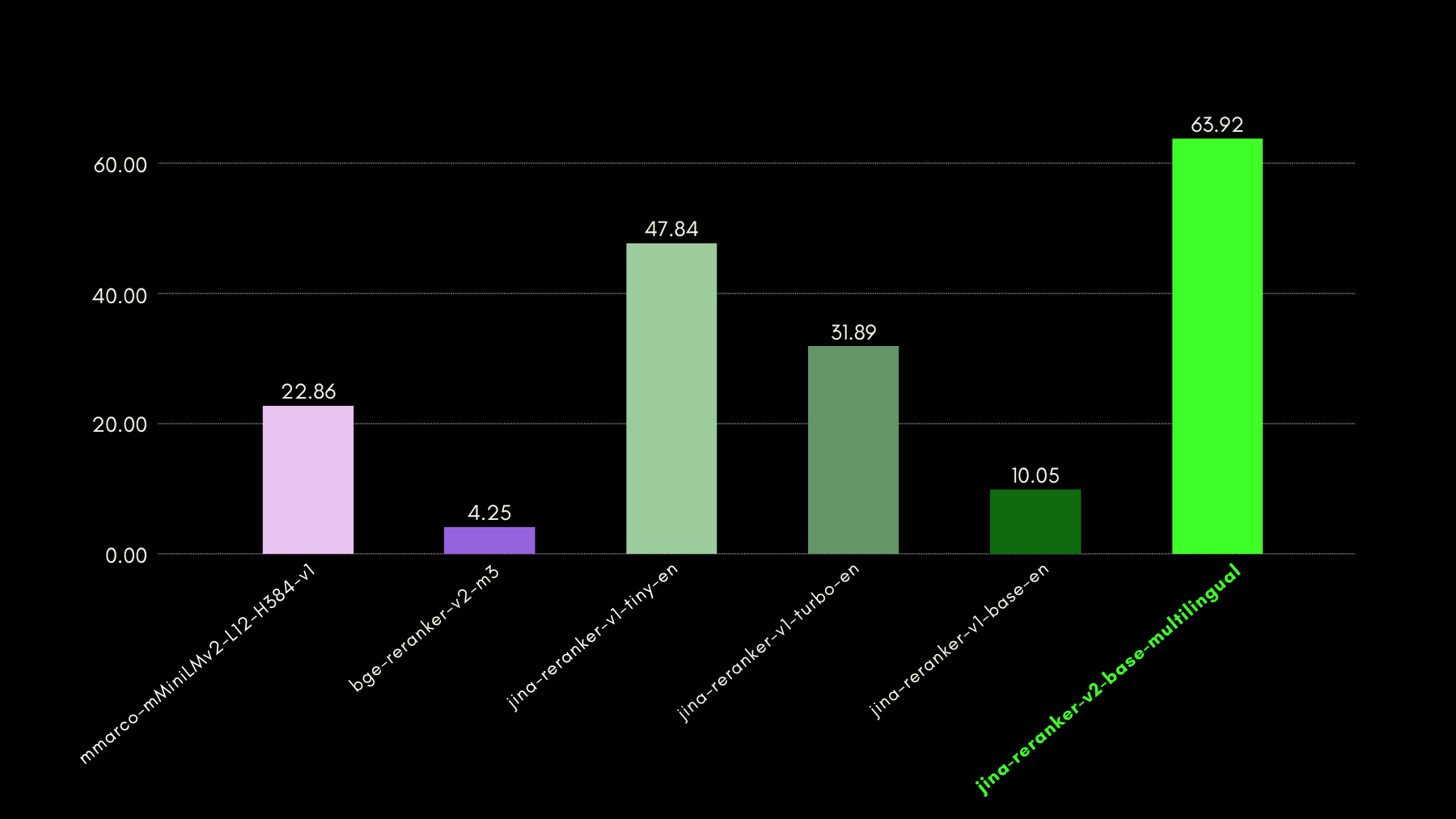
我們使用 ToolBench 基準測試評估了函數感知能力。該基準測試收集了超過 16,000 個公共 API 以及相應的合成生成指令,用於單一和多 API 設定。
以下是與其他重排序模型相比較的結果(recall@3 指標):
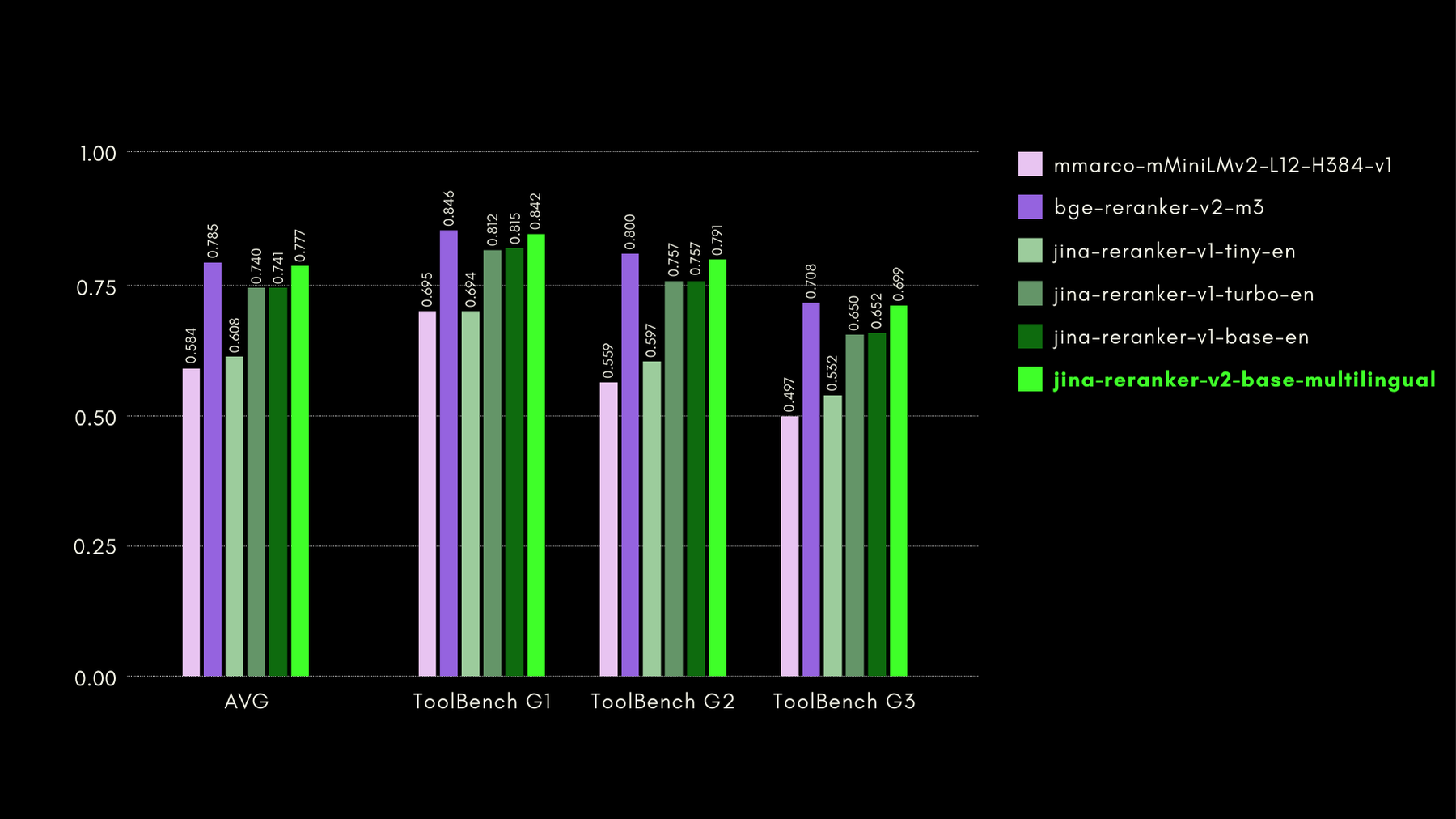
正如我們稍後將會展示的,jina-reranker-v2-base-multilingual 達到了接近最佳水準的效能,同時具有比 bge-reranker-v2-m3 小一半的模型大小,以及快將近 15 倍的優勢。
tagJina Reranker v2 在程式碼檢索上的表現
Jina Reranker v2 除了在函數呼叫和結構化資料查詢方面受過訓練外,與同等規模的競爭模型相比,在程式碼檢索方面也有所改進。我們使用 CodeSearchNet 基準測試評估了其程式碼檢索能力。這個基準測試結合了 docstring 格式和自然語言格式的查詢,並標註了與查詢相關的程式碼段。
以下是與其他重排序模型相比,使用 MRR@10 的結果:
tagJina Reranker v2 的超快推理速度
雖然交叉編碼器型神經重排序器在預測檢索文件的相關性方面表現出色,但它們的推理速度比嵌入模型慢。也就是說,在大多數向量資料庫中,將查詢與 n 個文件逐一比較的速度遠比 HNSW 或任何其他快速檢索方法慢。我們在 Jina Reranker v2 中解決了這個速度問題。
- 我們獨特的訓練見解(在下一節中描述)使我們的模型僅用 278M 參數就達到了最先進的準確性。相比之下,
bge-reranker-v2-m3有 567M 參數,Jina Reranker v2 的規模僅為其一半。這種縮減是提高吞吐量(每 50ms 處理的文件數)的首要原因。 - 即使在模型規模相當的情況下,Jina Reranker v2 的吞吐量也是我們之前英語版最先進的 Jina Reranker v1 模型的 6 倍。這是因為我們使用 Flash Attention 2 實作 Jina Reranker v2,在 transformer 模型的注意力層中引入了記憶體和計算優化。
您可以在以下圖表中看到上述改進步驟對 Jina Reranker v2 吞吐量性能的影響:
tag我們如何訓練 Jina Reranker v2
我們分四個階段訓練 jina-reranker-v2-base-multilingual:
- 英語資料準備:我們僅使用英語資料訓練骨幹模型來準備第一版模型,包括配對(對比訓練)或三元組(查詢、正確回應、錯誤回應)、查詢-函數結構對和查詢-表格結構對。
- 添加跨語言資料:在下一階段,我們添加了跨語言配對和三元組資料集,以專門改進骨幹模型在檢索任務上的多語言能力。
- 添加所有多語言資料:在這個階段,我們主要專注於確保模型能看到最大量的資料。我們使用來自超過 100 種低資源和高資源語言的所有配對和三元組資料集,對第二階段的模型檢查點進行微調。
- 使用挖掘的難負例進行微調:在觀察第三階段的重排序性能後,我們通過添加更多三元組資料進行微調,特別是為現有查詢添加更多難負例樣本 - 表面上看似與查詢相關但實際上是錯誤的回應。
這種四階段訓練方法基於以下見解:在訓練過程中盡早包含函數和表格結構,使模型能夠特別注意這些用例,並學會更多關注候選文件的語義而非語言結構。
tagJina Reranker v2 的實際應用
tag透過我們的 Reranker API
使用 Jina Reranker v2 最快速和最簡單的方法是使用 Jina Reranker 的 API。
前往該頁面的 API 部分,以使用您選擇的程式語言整合 jina-reranker-v2-base-multilingual。
範例 1:函數呼叫排序
要為外部函數/工具進行相關性排序,請按以下方式格式化查詢和文件(函數結構):
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "I am planning a road trip from Berlin to Munich in my Volkswagen VII. Can you calculate the carbon footprint of this trip?",
"documents": [
"{'\''Name'\'': '\''getWeather'\'', '\''Specification'\'': '\''Provides current weather information for a specified city'\'', '\''spec'\'': '\''https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}'\'', '\''example'\'': '\''https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateDistance'\'', '\''Specification'\'': '\''Calculates the driving distance and time between multiple locations'\'', '\''spec'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}'\'', '\''example'\'': '\''https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'\''}",
"{'\''Name'\'': '\''calculateCarbonFootprint'\'', '\''Specification'\'': '\''Estimates the carbon footprint for various activities, including transportation'\'', '\''spec'\'': '\''https://www.carboninterface.com/api/v1/estimates'\'', '\''example'\'': '\''{type: vehicle, distance: distance, vehicle_model_id: car}'\''}"
]
}'記得將 <YOUR JINA AI TOKEN HERE> 替換為您的個人 Reranker API 令牌
您應該會得到:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 383,
"prompt_tokens": 383
},
"results": [
{
"index": 2,
"document": {
"text": "{'Name': 'calculateCarbonFootprint', 'Specification': 'Estimates the carbon footprint for various activities, including transportation', 'spec': 'https://www.carboninterface.com/api/v1/estimates', 'example': '{type: vehicle, distance: distance, vehicle_model_id: car}'}"
},
"relevance_score": 0.5422876477241516
},
{
"index": 1,
"document": {
"text": "{'Name': 'calculateDistance', 'Specification': 'Calculates the driving distance and time between multiple locations', 'spec': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins={startCity}&destinations={endCity}&key={API_KEY}', 'example': 'https://maps.googleapis.com/maps/api/distancematrix/json?origins=Berlin&destinations=Munich&key=YOUR_API_KEY'}"
},
"relevance_score": 0.23283305764198303
},
{
"index": 0,
"document": {
"text": "{'Name': 'getWeather', 'Specification': 'Provides current weather information for a specified city', 'spec': 'https://api.openweathermap.org/data/2.5/weather?q={city}&appid={API_KEY}', 'example': 'https://api.openweathermap.org/data/2.5/weather?q=Berlin&appid=YOUR_API_KEY'}"
},
"relevance_score": 0.05033063143491745
}
]
}範例 2:排序 SQL 查詢
同樣地,要為您的查詢獲取結構化表格架構的相關性分數,您可以使用以下範例 API 呼叫:
curl -X 'POST' \
'https://api.jina.ai/v1/rerank' \
-H 'accept: application/json' \
-H 'Authorization: Bearer <YOUR JINA AI TOKEN HERE>' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-reranker-v2-base-multilingual",
"query": "which customers bought a summer outfit in the past 7 days?",
"documents": [
"CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));",
"CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));",
"CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));",
"CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
]
}'預期的回應是:
{
"model": "jina-reranker-v2-base-multilingual",
"usage": {
"total_tokens": 253,
"prompt_tokens": 253
},
"results": [
{
"index": 2,
"document": {
"text": "CREATE TABLE transactions (transaction_id INT PRIMARY KEY, customer_id INT, purchase_date DATE, FOREIGN KEY (customer_id) REFERENCES customer_personal_info(customer_id), product_id INT, FOREIGN KEY (product_id) REFERENCES products(product_id));"
},
"relevance_score": 0.2789437472820282
},
{
"index": 0,
"document": {
"text": "CREATE TABLE customer_personal_info (customer_id INT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50));"
},
"relevance_score": 0.06477169692516327
},
{
"index": 3,
"document": {
"text": "CREATE TABLE products (product_id INT PRIMARY KEY, product_name VARCHAR(100), season VARCHAR(50), supplier_id INT, FOREIGN KEY (supplier_id) REFERENCES supplier_company_info(supplier_id));"
},
"relevance_score": 0.027742892503738403
},
{
"index": 1,
"document": {
"text": "CREATE TABLE supplier_company_info (supplier_id INT PRIMARY KEY, company_name VARCHAR(100), contact_name VARCHAR(50));"
},
"relevance_score": 0.025516605004668236
}
]
}tag透過 RAG/LLM 框架
Jina Reranker 與 LLM 和 RAG 協調框架的現有整合應該已經可以透過使用模型名稱 jina-reranker-v2-base-multilingual 直接使用。請參考各自的文件頁面,了解如何在您的應用程式中整合 Jina Reranker v2。
- Haystack by deepset:Jina Reranker v2 可以在 Haystack 中使用 JinaRanker 類別:
from haystack import Document
from haystack_integrations.components.rankers.jina import JinaRanker
docs = [Document(content="Paris"), Document(content="Berlin")]
ranker = JinaRanker(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>")
ranker.run(query="City in France", documents=docs, top_k=1)
- LlamaIndex:Jina Reranker v2 可以作為 JinaRerank node postprocessor 模組使用,只需初始化它:
import os
from llama_index.postprocessor.jinaai_rerank import JinaRerank
jina_rerank = JinaRerank(model="jina-reranker-v2-base-multilingual", api_key="<YOUR JINA AI API KEY HERE>", top_n=1)
- Langchain:使用 Jina Rerank 整合在您現有的應用程式中使用 Jina Reranker 2。JinaRerank 模組應該使用正確的模型名稱進行初始化:
from langchain_community.document_compressors import JinaRerank
reranker = JinaRerank(model="jina-reranker-v2-base-multilingual", jina_api_key="<YOUR JINA AI API KEY HERE>")
tag透過 HuggingFace
我們也開放(在 CC-BY-NC-4.0 授權下)在 Hugging Face 上提供 jina-reranker-v2-base-multilingual 模型用於研究和評估目的。

要從 Hugging Face 下載並運行模型,請安裝 transformers 和 einops 庫:
pip install transformers einops
pip install ninja
pip install flash-attn --no-build-isolation
使用您的 Hugging Face 存取令牌通過 Hugging Face CLI 登入您的 Hugging Face 帳戶:
huggingface-cli login --token <"HF-Access-Token">
下載預訓練模型:
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(
'jinaai/jina-reranker-v2-base-multilingual',
torch_dtype="auto",
trust_remote_code=True,
)
model.to('cuda') # 如果沒有 GPU 可用,則使用 'cpu'
model.eval()
定義查詢和要重新排序的文件:
query = "Organic skincare products for sensitive skin"
documents = [
"Organic skincare for sensitive skin with aloe vera and chamomile.",
"New makeup trends focus on bold colors and innovative techniques",
"Bio-Hautpflege für empfindliche Haut mit Aloe Vera und Kamille",
"Neue Make-up-Trends setzen auf kräftige Farben und innovative Techniken",
"Cuidado de la piel orgánico para piel sensible con aloe vera y manzanilla",
"Las nuevas tendencias de maquillaje se centran en colores vivos y técnicas innovadoras",
"针对敏感肌专门设计的天然有机护肤产品",
"新的化妆趋势注重鲜艳的颜色和创新的技巧",
"敏感肌のために特別に設計された天然有機スキンケア製品",
"新しいメイクのトレンドは鮮やかな色と革新的な技術に焦点を当てています",
]
構建句子對並計算相關性分數:
sentence_pairs = [[query, doc] for doc in documents]
scores = model.compute_score(sentence_pairs, max_length=1024)
分數將是一個浮點數列表,每個浮點數代表相應文件與查詢的相關性分數。較高的分數表示較高的相關性。
或者,使用 rerank 函數通過根據 max_query_length 和
max_length。每個片段都會單獨進行評分,然後將每個片段的分數組合起來,產生最終的重排序結果:results = model.rerank(
query,
documents,
max_query_length=512,
max_length=1024,
top_n=3
)
該函數不僅會返回每個文檔的相關性分數,還會返回它們的內容和在原始文檔列表中的位置。
tag透過私有雲部署
Jina Reranker v2 在 AWS 和 Azure 帳戶上進行私有部署的預構建套件,很快就能在我們的 AWS Marketplace 和 Azure Marketplace 賣家頁面上找到。
tagJina Reranker v2 的主要特點
Jina Reranker v2 代表了搜索基礎的重要功能擴展:
- 使用交叉編碼的最先進檢索技術開啟了廣泛的新應用領域。
- 增強的多語言和跨語言功能消除了使用場景中的語言障礙。
- 業界最佳的函數調用支援,結合結構化數據查詢意識,將您的代理 RAG 功能提升到更高的精確度水平。
- 更好地檢索電腦程式碼和電腦格式化數據,遠超純文本信息檢索的範疇。
- 更快的文檔處理量確保無論使用何種檢索方法,您現在都可以更快地重新排序更多檢索到的文檔,並將大部分細粒度相關性計算卸載給 jina-reranker-v2-base-multilingual。
有了 Reranker v2,RAG 系統變得更加精確,幫助您現有的信息管理解決方案產生更多更好的可操作結果。跨語言支持使所有這些功能可直接用於跨國和多語言企業,並提供易於使用的 API,價格實惠。
通過使用源自實際使用場景的基準測試,您可以親自體驗 Jina Reranker v2 如何在與實際商業模型相關的任務中保持最先進的性能,這些功能都集中在一個 AI 模型中,既可以降低您的成本,又能使您的技術堆疊更加簡單。






