

最新!第二部分:深入探討邊界線索和誤解。
大約一年前,在 2023 年 10 月,我們發布了世界上第一個具有 8K 上下文長度的開源嵌入模型,jina-embeddings-v2-base-en。此後,關於嵌入模型中長上下文的用處,一直存在著諸多爭議。對於許多應用來說,將數千字長的文檔編碼為單一嵌入表示並非理想選擇。許多使用案例需要檢索較小的文本片段,而且密集向量檢索系統通常在處理較小的文本片段時表現更好,因為語義在嵌入向量中不太可能被「過度壓縮」。
檢索增強生成(RAG)是最著名的應用之一,它需要將文檔分割成較小的文本塊(例如在 512 個標記內)。這些塊通常存儲在向量資料庫中,其向量表示由文本嵌入模型生成。在運行時,相同的嵌入模型將查詢編碼為向量表示,然後用於識別相關的存儲文本塊。這些文本塊隨後被傳遞給大型語言模型(LLM),後者根據檢索到的文本合成對查詢的回應。

簡而言之,嵌入較小的塊似乎更為可取,部分原因是下游 LLM 的輸入大小限制,同時也因為人們擔心長上下文中的重要上下文信息在壓縮成單一向量時可能會被稀釋。
但如果行業只需要 512 上下文長度的嵌入模型,那麼訓練 8192 上下文長度的模型有什麼意義呢?
在本文中,我們通過探索 RAG 中簡單分塊-嵌入管線的局限性,重新審視這個重要但令人不適的問題。我們引入了一種名為「Late Chunking」的新方法,它利用 8192 長度嵌入模型提供的豐富上下文信息來更有效地嵌入文本塊。
tag丟失上下文問題
簡單的分塊-嵌入-檢索-生成 RAG 管線並非沒有挑戰。具體來說,這個過程可能會破壞遠距離上下文依賴關係。換句話說,當相關信息分散在多個塊中時,將文本片段脫離上下文可能會使其失去效果,這使得這種方法特別有問題。
在下圖中,一篇 Wikipedia 文章被分割成句子塊。你可以看到像「its」和「the city」這樣的詞指代的是「Berlin」,而「Berlin」只在第一句中提到。這使得嵌入模型更難將這些引用與正確的實體聯繫起來,從而產生較低質量的向量表示。

這意味著,如果我們將一篇長文章分割成句子長度的塊,如上例所示,RAG 系統可能難以回答「柏林的人口是多少?」這樣的查詢。因為城市名稱和人口數字從未在同一個塊中出現,而且在沒有更大文檔上下文的情況下,提供給 LLM 的任一塊都無法解析像「it」或「the city」這樣的照應引用。
有一些啟發式方法可以緩解這個問題,比如使用滑動窗口重新採樣、使用多個上下文窗口長度,以及執行多次文檔掃描。然而,像所有啟發式方法一樣,這些方法都是碰運氣的;它們在某些情況下可能有效,但在理論上無法保證其有效性。
tag解決方案:Late Chunking
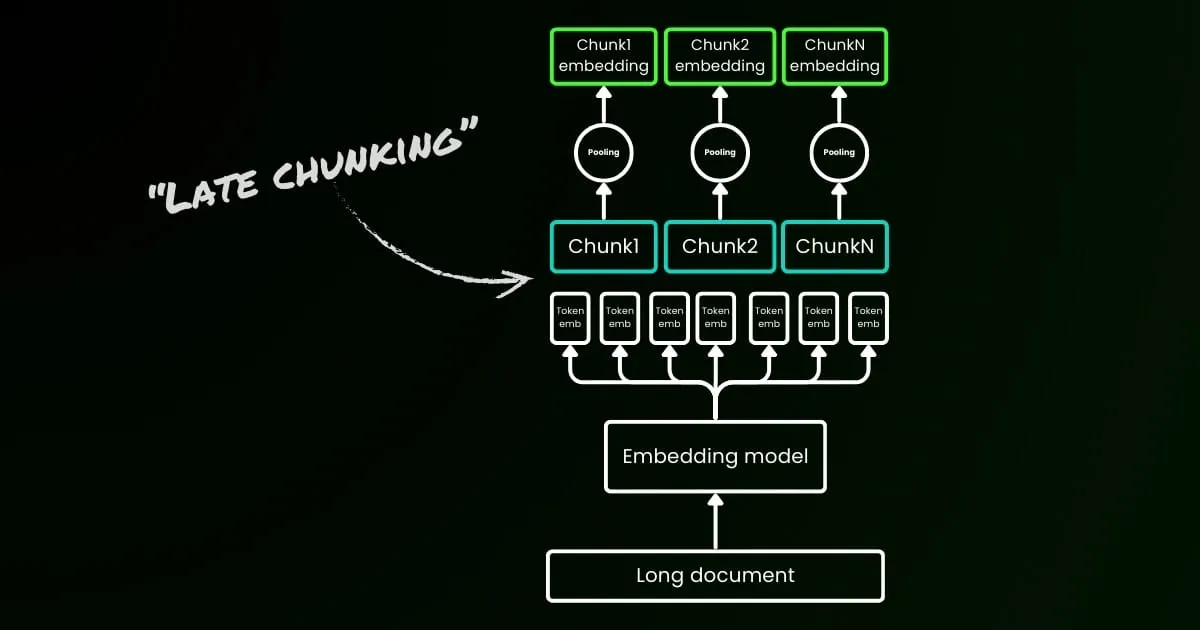
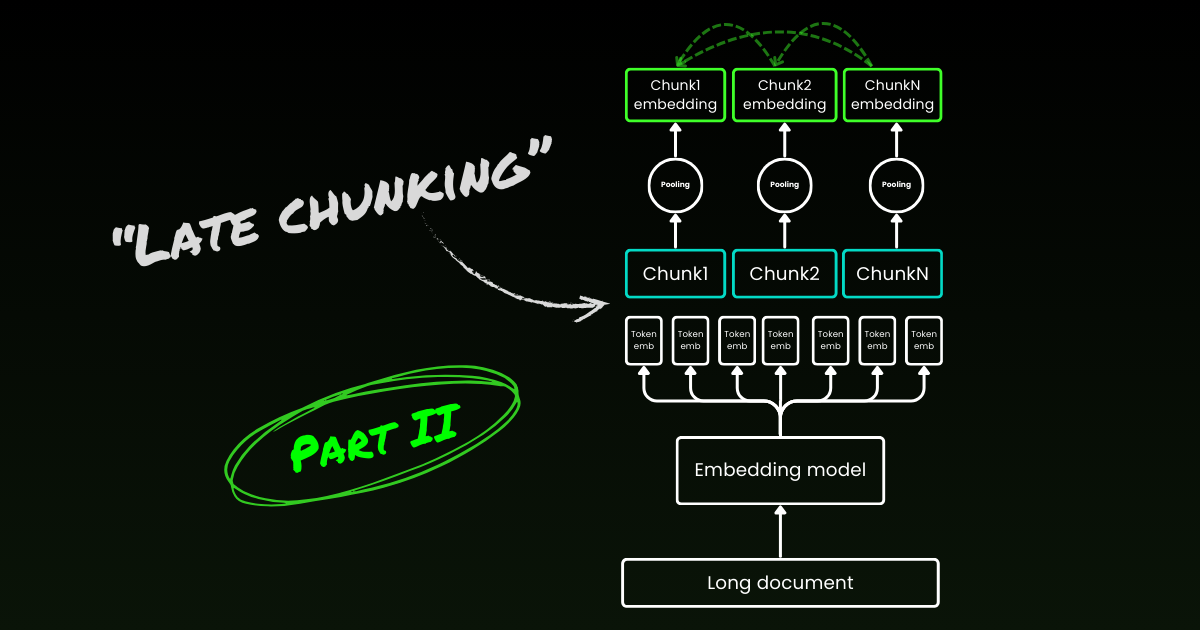
簡單的編碼方法(如下圖左側所示)涉及使用句子、段落或最大長度限制來預先分割文本。之後,嵌入模型被重複應用於這些結果塊。為了為每個塊生成單一嵌入,許多嵌入模型使用這些標記級嵌入的平均池化來輸出單一嵌入向量。

相比之下,我們在本文中提出的「Late Chunking」方法首先將嵌入模型的 transformer 層應用於整個文本或盡可能多的文本。這會為每個標記生成一個包含整個文本信息的向量表示序列。隨後,對這個標記向量序列的每個塊進行平均池化,產生考慮了整個文本上下文的每個塊的嵌入。與生成獨立同分布(i.i.d.)塊嵌入的簡單編碼方法不同,Late Chunking 創建了一組塊嵌入,其中每一個都是「以前一個為條件」,從而為每個塊編碼更多的上下文信息。
顯然,要有效應用 Late Chunking,我們需要像 jina-embeddings-v2-base-en 這樣的長上下文嵌入模型,它支持高達 8192 個標記——大約相當於十頁標準文本。這種大小的文本片段更不太可能有需要更長上下文才能解決的上下文依賴關係。
需要強調的是,Late Chunking 仍然需要邊界線索,但這些線索只在獲得標記級嵌入之後才使用——因此在命名中使用「late」一詞。
| 簡單分塊 | Late Chunking | |
|---|---|---|
| 邊界線索的需求 | 是 | 是 |
| 邊界線索的使用 | 直接在預處理中 | 在從 transformer 層獲得標記級嵌入之後 |
| 結果塊嵌入 | i.i.d. | 條件性 |
| 鄰近塊的上下文信息 | 丟失。一些啟發式方法(如重疊採樣)可緩解此問題 | 通過長上下文嵌入模型得到良好保留 |
tag實作和質性評估


Late Chunking 的實作可以在上面連結的 Google Colab 中找到。在這裡,我們利用 Tokenizer API 中最近發布的功能,該功能利用所有可能的邊界線索將長文檔分割成有意義的塊。關於這個功能背後的算法的更多討論可以在 X 上找到。

當對上述維基百科的例子應用延遲分段時,你可以立即看到語義相似度的改善。例如,在維基百科文章中提到"這個城市"和"柏林"時,表示"這個城市"的向量現在包含了將其與先前提到的"柏林"聯繫起來的資訊,這使其在涉及該城市名稱的查詢中能更好地匹配。
| Query | Chunk | Sim. on naive chunking | Sim. on late chunking |
|---|---|---|---|
| Berlin | Berlin is the capital and largest city of Germany, both by area and by population. | 0.849 | 0.850 |
| Berlin | Its more than 3.85 million inhabitants make it the European Union's most populous city, as measured by population within city limits. | 0.708 | 0.825 |
| Berlin | The city is also one of the states of Germany, and is the third smallest state in the country in terms of area. | 0.753 | 0.850 |
你可以在上面的數值結果中觀察到這一點,這些結果比較了"Berlin"這個詞的嵌入與使用餘弦相似度得到的關於柏林文章中各個句子的嵌入。"Sim. on IID chunk embeddings"列顯示了"Berlin"查詢嵌入與使用先驗分段的嵌入之間的相似度值,而"Sim. under contextual chunk embedding"則代表使用延遲分段方法的結果。
tag在 BEIR 上的定量評估
為了驗證延遲分段在玩具示例之外的有效性,我們使用了 BeIR 中的一些檢索基準進行了測試。這些檢索任務包括一個查詢集、一個文本文檔語料庫,以及一個存儲與每個查詢相關文檔 ID 資訊的 QRels 文件。
要識別與查詢相關的文檔,首先將文檔進行分段,編碼成嵌入索引,並使用 k-近鄰(kNN)為每個查詢嵌入確定最相似的段落。由於每個段落對應一個文檔,因此可以將段落的 kNN 排名轉換為文檔的 kNN 排名(在排名中多次出現的文檔只保留第一次出現)。然後將這個結果排名與地面真相 QRels 文件提供的排名進行比較,並計算 nDCG@10 等檢索指標。下面描述了這個程序,為了可重現性,評估腳本可以在此存儲庫中找到。
 jina-ai
jina-ai我們在各種 BeIR 數據集上運行了這個評估,比較了朴素分段與我們的延遲分段方法。為了獲取邊界線索,我們使用了一個將文本分割成大約 256 個標記的正則表達式。朴素和延遲分段評估都使用了 jina-embeddings-v2-small-en 作為嵌入模型;這是 v2-base-en 模型的一個較小版本,仍然支持最多 8192 個標記長度。結果可以在下表中找到。
| Dataset | Avg. Document Length (characters) | Naive Chunking (nDCG@10) | Late Chunking (nDCG@10) | No Chunking (nDCG@10) |
|---|---|---|---|---|
| SciFact | 1498.4 | 64.20% | 66.10% | 63.89% |
| TRECCOVID | 1116.7 | 63.36% | 64.70% | 65.18% |
| FiQA2018 | 767.2 | 33.25% | 33.84% | 33.43% |
| NFCorpus | 1589.8 | 23.46% | 29.98% | 30.40% |
| Quora | 62.2 | 87.19% | 87.19% | 87.19% |
在所有情況下,延遲分段都比朴素方法提高了分數。在某些情況下,它甚至超越了將整個文檔編碼為單一嵌入的效果,而在其他數據集中,完全不分段反而產生了最好的結果(當然,不分段只有在不需要對段落進行排名時才有意義,這種情況在實踐中很少見)。如果我們將朴素方法和延遲分段之間的性能差距與文檔長度進行對比,很明顯文檔的平均長度與延遲分段帶來的 nDCG 分數改善程度相關。換句話說,文檔越長,延遲分段策略的效果就越好。

tag結論
在本文中,我們介紹了一種稱為"延遲分段"的簡單方法,通過利用長上下文嵌入模型的力量來嵌入短段落。我們展示了傳統的獨立同分佈段落嵌入如何無法保留上下文資訊,導致檢索效果不佳;以及延遲分段如何提供一個簡單而高效的解決方案,以在每個段落中維持和調節上下文資訊。延遲分段的效果在較長文檔上變得更加顯著——這種能力只有通過像 jina-embeddings-v2-base-en 這樣的高級長上下文嵌入模型才能實現。我們希望這項工作不僅能驗證長上下文嵌入模型的重要性,還能激發該主題的進一步研究。
繼續閱讀第二部分:深入探討邊界線索和誤解。





