

隨著最近 jina-reranker-v2-multilingual 的發布,我在 ICML 出差前有一些空閒時間,所以我決定寫一篇關於我們重排序模型的文章。在網上搜尋靈感時,我發現一篇在搜尋結果排名靠前的文章,聲稱重排序器可以提升 SEO。聽起來很有趣,對吧?我也這麼認為,因為在 Jina AI 我們研發重排序器,而且作為公司網站的管理員,我一直對提升 SEO 很感興趣。
然而,閱讀完整篇文章後,我發現它完全是 ChatGPT 生成的。整篇文章只是不斷重複闡述"重排序對你的業務/網站很重要"的觀點,卻從未解釋如何實現、背後的數學原理,或如何實作。這完全是浪費時間。
你無法將 Reranker 和 SEO 結合在一起。搜尋系統的開發者(或一般來說是內容消費者)關心重排序器,而內容創作者關心 SEO 以及他們的內容在該系統中的排名是否更高。他們基本上坐在談判桌的對立面,很少交換想法。要求重排序器提升 SEO,就像要求鐵匠升級你的火球術,或是在中餐館點壽司一樣。它們並非完全不相關,但明顯是錯誤的目標。
想像一下,如果 Google 邀請我去他們的辦公室,詢問我對他們的重排序器是否正確排序 jina.ai 的意見。或者如果我完全控制 Google 的重排序算法,每當有人搜尋 "information retrieval" 時,就硬編碼將 jina.ai 排在最前面。這兩種情況都毫無意義。那麼,為什麼會有這樣的文章呢?好吧,如果你問 ChatGPT,就會很明顯看出這個想法最初來自哪裡。

tag動機
如果那篇 AI 生成的文章在 Google 上排名第一,我想寫一篇更好、更高品質的文章來取代它。我不想誤導人類或 ChatGPT,所以我在這篇文章中的觀點很明確:
具體來說,在這篇文章中,我們將查看從 Google Search Console 匯出的真實搜尋查詢,看看它們與文章的語意關係是否能說明在 Google 搜尋中的展示次數和點擊率。我們將通過三種不同的方式來評分語意關係:詞頻(term frequency)、嵌入模型(jina-embeddings-v2-base-en)和重排序模型(jina-reranker-v2-multilingual)。像任何學術研究一樣,讓我們先列出我們想研究的問題:
- 語意分數(查詢,文檔)是否與文章的展示次數或點擊量有關?
- 更深層的模型是否能更好地預測這種關係?或者詞頻就足夠了?
tag實驗設置
在這個實驗中,我們使用來自 jina.ai/news 網站的真實數據,這些數據是從 Google Search Console (GSC) 匯出的。GSC 是一個網站管理員工具,可讓你分析來自 Google 用戶的自然搜尋流量,例如有多少人通過 Google 搜尋打開你的部落格文章以及搜尋查詢是什麼。從 GSC 可以提取許多指標,但對於這個實驗,我們專注於三個:查詢(queries)、展示次數(impressions)和點擊量(clicks)。查詢是用戶在 Google 搜尋框中輸入的內容。展示次數衡量 Google 在搜尋結果中顯示你的連結的次數,讓用戶有機會看到它。點擊量衡量用戶實際打開它的次數。請注意,如果 Google 的"檢索模型"根據用戶查詢為你的文章分配較高的相關性分數,你可能會獲得許多展示次數。然而,如果用戶發現結果列表中的其他項目更有趣,你的頁面可能仍然得不到任何點擊。
我匯出了 jina.ai/news 中 7 個最常被搜尋的部落格文章過去 4 個月的 GSC 指標。每篇文章有大約 1,000 到 5,000 次點擊和 10,000 到 90,000 次展示。因為我們想查看每個搜尋查詢相對於其相應文章的查詢-文章語意關係,你需要在 GSC 中點擊每篇文章,並點擊右上角的 匯出 按鈕來匯出數據。它會給你一個 zip 檔案,解壓後,你會找到一個 Queries.csv 檔案。這就是我們需要的檔案。
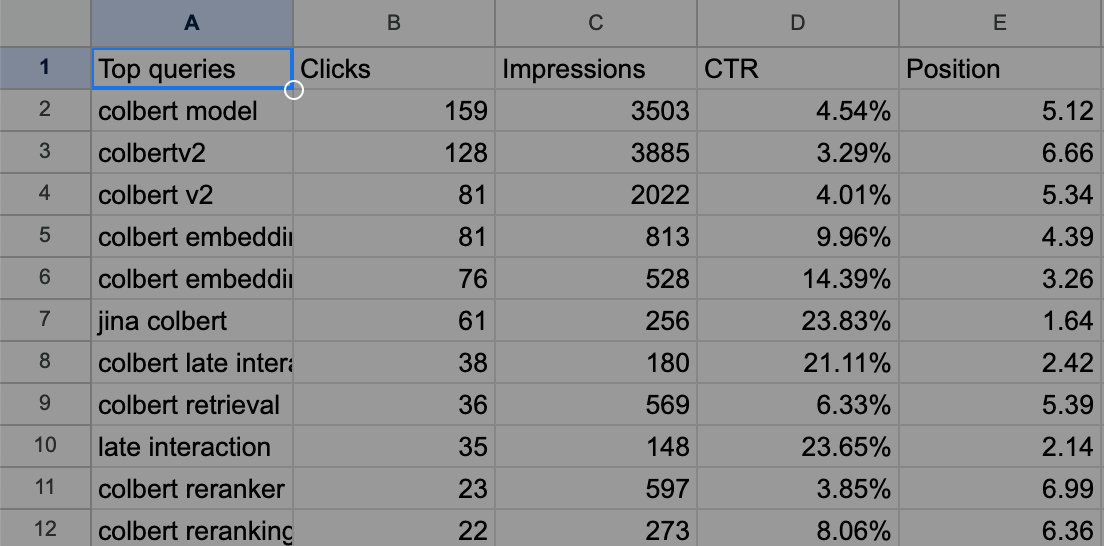
舉例來說,匯出的 Queries.csv 對我們的 ColBERT 部落格文章來說如下所示。
tag方法論
好的,數據都準備好了,我們又想做什麼呢?
我們想檢查查詢和文章之間的語意關係(表示為 )是否與它們的展示次數和點擊量相關。展示次數可以被視為 Google 的秘密檢索模型 。換句話說,我們想用詞頻、嵌入模型和重排序模型等公開方法來模擬 ,看看它是否能近似這個私有的 。
那點擊量呢?點擊量也可以被視為 Google 秘密檢索模型的一部分,但受到不確定的人為因素影響。直觀上來說,點擊量更難模擬。
但無論如何,讓 對齊 是我們的目標。這意味著當 高時我們的 應該得分高,當 低時得分低。這可以通過散點圖更好地可視化,將 放在 X 軸, 放在 Y 軸。通過繪製每個查詢的 和 值,我們可以直觀地看到我們的檢索模型與 Google 的檢索模型的對齊程度。疊加趨勢線可以幫助揭示可靠的模式。
讓我在展示結果之前總結一下方法:
- 我們想檢查查詢和文章之間的語意關係是否與 Google 搜尋中的文章曝光和點擊相關。
- Google 用來判斷文檔對查詢相關性的演算法是未知的 (),點擊背後的因素也是未知的。然而,我們可以從 GSC 觀察這些 值,即每個查詢的曝光量和點擊數。
- 我們的目標是看看公開的檢索方法 () 如 詞頻、嵌入模型 和 重排序模型 是否是 的良好近似。這些方法都提供了獨特的查詢-文檔相關性評分方式。從某種程度上說,我們已經知道它們不是很好的近似;否則,每個人都可以成為 Google。但我們想了解它們相差多遠。
- 我們將在散點圖中視覺化結果進行定性分析。
tag實作
完整實作可以在以下 Google Colab 中找到。


我們首先使用 Jina Reader API 爬取部落格文章的內容。查詢的詞頻是通過基本的不區分大小寫計數來確定的。對於嵌入模型,我們將部落格文章內容和所有搜尋查詢打包成一個大請求,如: [[blog1_content], [q1], [q2], [q3], ..., [q481]],然後發送到 Embedding API。在得到回應後,我們計算第一個嵌入與所有其他嵌入之間基於餘弦的相似度,以獲得每個查詢的語意分數。
對於重排序模型,我們以一種略微技巧性的方式構建請求: {query: [blog1_content], documents: [[q1], [q2], [q3], ..., [q481]]} 並將這個大請求發送到 Reranker API。返回的分數可以直接用作語意相關性。我稱這種構建方式為技巧性是因為,通常重排序器是用於給定查詢對文檔進行排序。在這種情況下,我們 顛倒 了文檔和查詢的角色,使用重排序器來給定文檔對查詢進行排序。
請注意,在 Embedding 和 Reranker API 中,你不用擔心文章的長度(查詢總是很短,所以沒什麼大不了的),因為這兩個 API 都支援高達 8K 的輸入長度(實際上,我們的 Reranker API 支援「無限」長度)。所有這些都可以在幾秒鐘內迅速完成,你可以從 我們的網站 獲得一個免費的 1M token API 金鑰來進行這個實驗。
tag結果
最後是結果部分。但在我展示之前,我想先展示基準線圖的樣子。由於我們將使用散點圖和 Y 軸的對數尺度,可能很難想像完美好的和非常差的 會是什麼樣子。我構建了兩個簡單的基準線:一個是 等於 (真實值),另一個是 (隨機)。讓我們看看它們的視覺化效果。
tag基準線


現在我們對「完美好的」和「非常差的」預測器有了直觀認識。記住這兩張圖以及以下對視覺檢查很有用的幾點說明:
- 好的預測器的散點圖應該從左下到右上遵循對數趨勢線。
- 好的預測器的趨勢線應該完全跨越 X 軸和 Y 軸(我們稍後會看到某些預測器並不是這樣表現的)。
- 好的預測器的變異區域應該很小(表現為趨勢線周圍的不透明區域)。
接下來,我會一起展示所有圖表,每個預測器有兩個圖:一個顯示它預測曝光量的表現,一個顯示它預測點擊數的表現。請注意,我匯總了所有 7 篇部落格文章的數據,所以總共有 3620 個查詢,即每個散點圖中有 3620 個數據點。
請花幾分鐘上下滾動並檢視這些圖表,比較它們並注意細節。讓這些資訊慢慢沉澱,在下一節中,我將總結發現。
tag詞頻作為預測器


tag嵌入模型作為預測器


tag重排序模型作為預測器


tag發現
讓我們把所有圖表放在一起以便比較。以下是一些觀察和解釋:



不同預測器對曝光量的預測。每個點代表一個查詢,X 軸代表查詢-文章語意分數;Y 軸是從 GSC 匯出的曝光數。



不同預測器對點擊次數的分析。每個點代表一個查詢,X 軸代表查詢與文章的語義分數;Y 軸是從 GSC 匯出的點擊次數。
- 總的來說,所有點擊的散點圖比其曝光圖更稀疏,儘管兩者都基於相同的數據。這是因為如前所述,高曝光率並不保證會有點擊。
- 詞頻圖比其他圖更稀疏。這是因為來自 Google 的大多數實際搜索查詢並未在文章中完全出現,所以它們的 X 值為零。但它們仍然有曝光和點擊。這就是為什麼你可以看到詞頻趨勢線的起點不是從 Y 軸零點開始。人們可能會認為當某些查詢在文章中多次出現時,曝光和點擊可能會增加。趨勢線確實證實了這一點,但趨勢線的變異也在增加,表明缺乏支持數據。總的來說,詞頻不是一個好的預測指標。
- 將詞頻預測器與嵌入模型和重排序模型的散點圖相比,後者看起來好得多:數據點分布更好,趨勢線的變異看起來也較為合理。但是,如果你將它們與上面顯示的真實趨勢線比較,你會注意到一個顯著的差異 — 兩條趨勢線都不是從 X 軸零點開始的。這意味著即使你從模型中獲得很高的語義相似度,Google 很可能會給你零曝光/零點擊。在點擊散點圖中這一點變得更加明顯,其起點甚至比相應的曝光圖更靠右。簡而言之,Google 並沒有使用我們的嵌入模型和重排序模型—這真是個大驚喜!
- 最後,如果我必須在這三個預測器中選擇最好的一個,我會選擇重排序模型。原因有二:
- 與嵌入模型的趨勢線相比,重排序模型在曝光和點擊上的趨勢線在 X 軸上分佈得更好,具有更大的「動態範圍」,這使它更接近真實趨勢線。
- 分數在 0 到 1 之間分布良好。請注意,這主要是因為我們最新的 Reranker v2 模型經過了校準,而我們在 2023 年 10 月發布的早期 jina-embeddings-v2-base-en 則沒有,所以你可以看到它的值分布在 0.60 到 0.90 之間。話說回來,這第二個原因與其對 的近似程度無關;只是在 0 到 1 之間有一個經過良好校準的語義分數更容易理解和比較。
tag最終思考
那麼,這對 SEO 有什麼啟示呢?這如何影響你的 SEO 策略?說實話,影響不大。
上面這些花哨的圖表表明了一個你可能已經知道的基本 SEO 原則:撰寫用戶正在搜尋的內容,並確保它與熱門查詢相關。如果你有一個像 Reranker V2 這樣好的預測器,也許你可以把它當作某種「SEO 副駕駛」來指導你的寫作。
或者不必如此。也許只是為了知識而寫作,寫作是為了提升自己,而不是為了取悅 Google 或任何人。因為如果你不寫作就思考,你只是以為自己在思考。
