


在 2024 年 4 月,我們發布了 Jina Reader,這是一個簡單的 API,只需添加前綴 r.jina.ai 就能將任何 URL 轉換成適合 LLM 使用的 markdown 格式。儘管背後涉及複雜的網絡編程,但核心的「閱讀」部分相當直接。首先,我們使用無頭 Chrome 瀏覽器獲取網頁的源代碼。然後,我們利用 Mozilla 的 Readability 包來提取主要內容,移除頁眉、頁腳、導航欄和側邊欄等元素。最後,我們使用 正則表達式和 Turndown 庫將清理後的 HTML 轉換為 markdown。結果是一個結構良好的 markdown 文件,可供 LLM 用於事實核查、摘要和推理。
在 Jina Reader 發布後的最初幾週,我們收到了大量反饋,特別是關於內容質量的問題。有些用戶認為內容太詳細,而其他人則覺得不夠詳細。還有報告指出 Readability 過濾器刪除了錯誤的內容,或者 Turndown 在將某些 HTML 部分轉換為 markdown 時遇到困難。幸運的是,通過添加新的正則表達式模式或啟發式規則,許多這些問題都得到了成功解決。
從那時起,我們一直在思考一個問題:與其通過更多啟發式規則和正則表達式來修補(這變得越來越難以維護,而且對多語言支持不友好),我們能否用語言模型來進行端到端的解決這個問題?
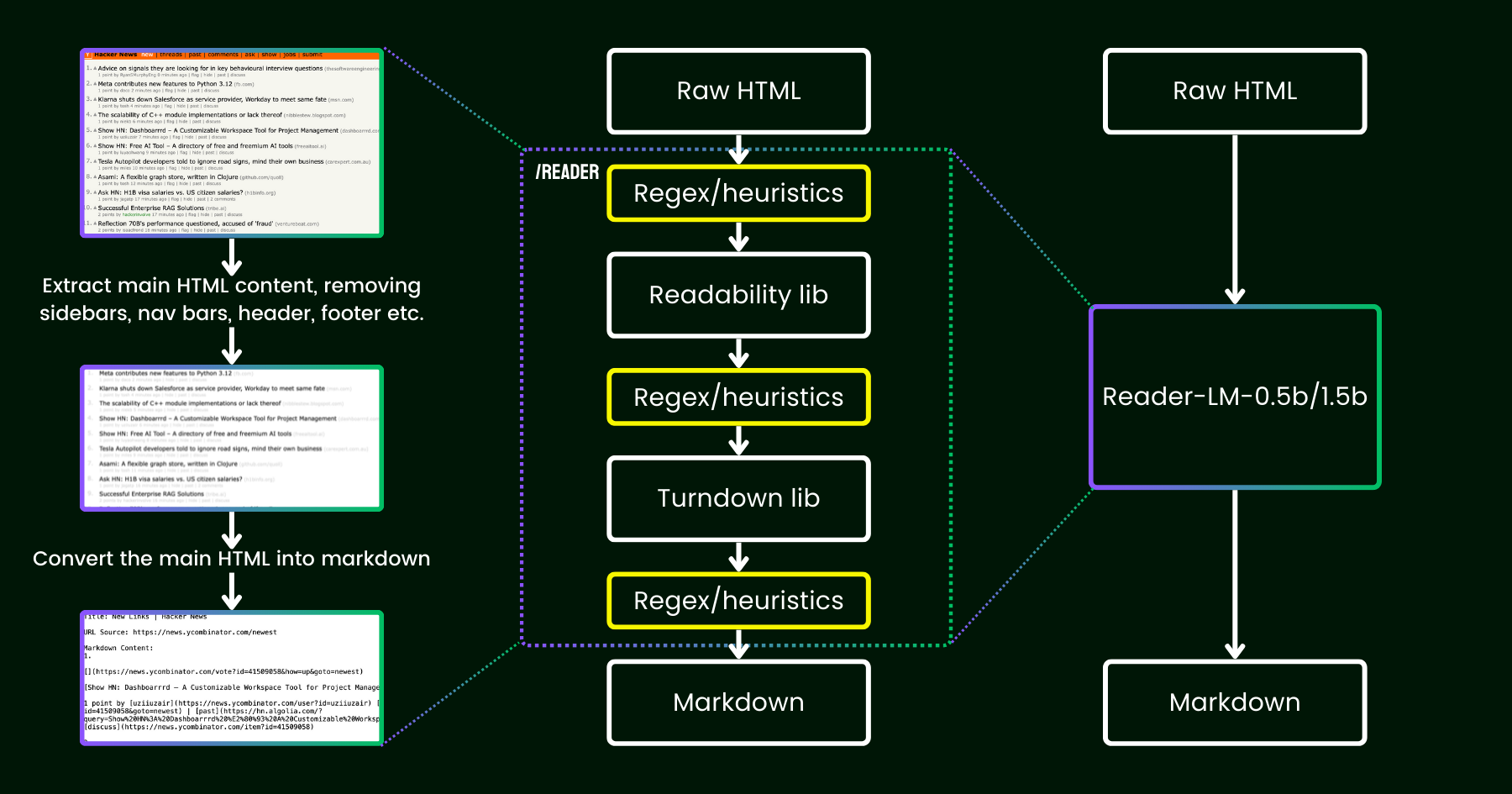
reader-lm,使用小型語言模型替代 readability+turndown+正則表達式啟發式規則的流程。乍看之下,使用 LLM 進行數據清理似乎過於浪費,因為它們的成本效益低且速度較慢。但如果我們考慮使用**小型語言模型(SLM)**——一個參數少於 10 億並能在邊緣設備上高效運行的模型呢?這聽起來更有吸引力,對吧?但這真的可行還是只是一廂情願?根據縮放定律,較少的參數通常導致推理和總結能力的降低。因此,如果參數規模太小,SLM 甚至可能難以生成任何有意義的內容。讓我們進一步探討 HTML 轉 Markdown 這個任務:
- 首先,我們考慮的任務**並不像典型的 LLM 任務那麼具有創造性和複雜性**。在將 HTML 轉換為 markdown 的過程中,模型主要需要從輸入到輸出進行**選擇性複製**(即跳過 HTML 標記、側邊欄、頁眉、頁腳),很少需要生成新內容(主要是插入 markdown 語法)。這與 LLM 處理的更廣泛任務(如生成詩歌或編寫代碼)形成鮮明對比,後者的輸出涉及更多創造性,而不是直接從輸入複製貼上。這個觀察表明 SLM 可能有效,因為這個任務*看起來*比一般的文本生成更簡單。
- 其次,我們需要**優先考慮長上下文支持**。現代 HTML 通常包含比簡單的
<div>標記更多的雜訊。內聯 CSS 和腳本很容易使代碼膨脹到數十萬個標記。對於 SLM 來說,要在這種情況下實用,上下文長度必須足夠大。8K 或 16K 的標記長度*完全*不夠用。
看來我們需要的是一個**淺而寬**的 SLM。「淺」是指任務主要是簡單的「複製貼上」,因此需要較少的 transformer 塊;「寬」是指它需要長上下文支持才能實用,所以注意力機制需要特別關注。之前的研究表明,上下文長度和推理能力密切相關。對於 SLM 來說,在保持參數規模小的同時優化這兩個維度是極其具有挑戰性的。
今天,我們很高興宣布這個解決方案的第一個版本,發布 reader-lm-0.5b 和 reader-lm-1.5b,這兩個專門訓練用於**直接從雜亂的原始 HTML 生成乾淨 markdown** 的 SLM。這兩個模型都支持多語言,並支持長達 **256K 標記**的上下文長度。儘管體積小巧,這些模型在這項任務上達到了最先進的性能,超越了更大的 LLM 對手,同時只有後者規模的 1/50。

以下是這兩個模型的規格:
| reader-lm-0.5b | reader-lm-1.5b | |
|---|---|---|
| # 參數數量 | 494M | 1.54B |
| 上下文長度 | 256K | 256K |
| 隱藏維度 | 896 | 1536 |
| # 層數 | 24 | 28 |
| # 查詢頭 | 14 | 12 |
| # KV 頭 | 2 | 2 |
| 頭部大小 | 64 | 128 |
| 中間層大小 | 4864 | 8960 |
| 多語言支持 | 是 | 是 |
| HuggingFace 倉庫 | 連結 | 連結 |
tagReader-LM 入門
tag在 Google Colab 上使用
體驗 reader-lm 最簡單的方式是運行我們的 Colab 筆記本,其中我們展示如何使用 reader-lm-1.5b 將 Hacker News 網站轉換為 markdown。該筆記本經過優化,可以在 Google Colab 的免費 T4 GPU 層上順暢運行。您也可以加載 reader-lm-0.5b 或將 URL 更改為任何網站並探索輸出。請注意,模型的輸入(即提示)是原始 HTML——不需要前綴指令。

請注意,免費版的 T4 GPU 有一些限制,可能會影響模型執行時的進階優化功能。T4 不支援 bfloat16 和 flash attention 等功能,這可能會導致較高的 VRAM 使用量,以及在處理較長輸入時效能較慢。對於生產環境,我們建議使用像 RTX 3090/4090 這樣的高階 GPU 以獲得明顯更好的效能。
tag生產環境:即將在 Azure 和 AWS 上架
Reader-LM 可在 Azure Marketplace 和 AWS SageMaker 上使用。如果您需要在這些平台之外或在公司內部使用這些模型,請注意這兩個模型都採用 CC BY-NC 4.0 授權。如需商業用途諮詢,歡迎聯繫我們。


tag基準測試
為了定量評估 Reader-LM 的效能,我們將其與多個大型語言模型進行比較,包括:GPT-4o、Gemini-1.5-Flash、Gemini-1.5-Pro、LLaMA-3.1-70B、Qwen2-7B-Instruct。
這些模型使用以下指標進行評估:
- ROUGE-L(越高越好):這個指標廣泛用於摘要和問答任務,用於測量預測輸出與參考內容在 n-gram 層面的重疊度。
- Token 錯誤率(TER,越低越好):此指標計算生成的 markdown token 未出現在原始 HTML 內容中的比率。我們設計這個指標來評估模型的幻覺率,幫助我們識別模型產生未在 HTML 中出現的內容的情況。後續將根據案例研究進行改進。
- 詞錯誤率(WER,越低越好):常用於 OCR 和 ASR 任務,WER 考慮詞序並計算錯誤,如插入(ADD)、替換(SUB)和刪除(DEL)。這個指標提供了生成的 markdown 與預期輸出之間不匹配的詳細評估。
為了讓 LLM 執行此任務,我們使用了以下統一的指令作為前綴提示:
Your task is to convert the content of the provided HTML file into the corresponding markdown file. You need to convert the structure, elements, and attributes of the HTML into equivalent representations in markdown format, ensuring that no important information is lost. The output should strictly be in markdown format, without any additional explanations.結果可在下表中查看。
| ROUGE-L | WER | TER | |
|---|---|---|---|
| reader-lm-0.5b | 0.56 | 3.28 | 0.34 |
| reader-lm-1.5b | 0.72 | 1.87 | 0.19 |
| gpt-4o | 0.43 | 5.88 | 0.50 |
| gemini-1.5-flash | 0.40 | 21.70 | 0.55 |
| gemini-1.5-pro | 0.42 | 3.16 | 0.48 |
| llama-3.1-70b | 0.40 | 9.87 | 0.50 |
| Qwen2-7B-Instruct | 0.23 | 2.45 | 0.70 |
tag定性研究
我們通過目視檢查輸出的 markdown 進行了定性研究。我們選擇了 22 個 HTML 來源,包括新聞文章、部落格文章、登陸頁面、電商頁面和論壇帖子,涵蓋多種語言:英語、德語、日語和中文。我們也將依賴正則表達式、啟發式方法和預定義規則的 Jina Reader API 作為基準。
評估聚焦於輸出的四個關鍵維度,每個模型按 1(最低)到 5(最高)的等級進行評分:
- 標題提取:評估每個模型如何使用正確的 markdown 語法識別和格式化文件的 h1、h2、...、h6 標題。
- 主要內容提取:評估模型準確轉換正文、保留段落、格式化列表和維持呈現一致性的能力。
- 豐富結構保留:分析每個模型維護文件整體結構的效果,包括標題、副標題、項目符號和有序列表。
- Markdown 語法使用:評估每個模型將 HTML 元素(如
<a>(連結)、<strong>(粗體文字)和<em>(斜體))正確轉換為對應 markdown 格式的能力。
結果如下圖所示。

Reader-LM-1.5B 在所有維度上都表現穩定,特別是在結構保留和 markdown 語法使用方面表現出色。雖然它並不總是優於 Jina Reader API,但其表現與 Gemini 1.5 Pro 等較大模型相當,使其成為大型 LLM 的高效替代方案。Reader-LM-0.5B 雖然規模較小,但仍提供穩固的表現,特別是在結構保留方面。
tag我們如何訓練 Reader-LM
tag數據準備
我們使用 Jina Reader API 生成原始 HTML 及其對應的 markdown 訓練對。在實驗過程中,我們發現 SLM 對訓練數據的品質特別敏感。因此,我們建立了一個數據管道,確保只有高品質的 markdown 條目被納入訓練集。
此外,我們添加了一些由 GPT-4o 生成的合成 HTML 及其對應的 markdown。與真實世界的 HTML 相比,合成數據通常更短、結構更簡單且更可預測,噪聲水平也明顯較低。
最後,我們使用聊天模板連接 HTML 和 markdown。最終的訓練數據格式如下:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{{RAW_HTML}}<|im_end|>
<|im_start|>assistant
{{MARKDOWN}}<|im_end|>
完整的訓練數據總計 25 億個 token。
tag兩階段訓練
我們實驗了從 65M 和 135M 到 3B 參數的多種模型大小。以下表格列出了每個模型的具體規格。
| reader-lm-65m | reader-lm-135m | reader-lm-360m | reader-lm-0.5b | reader-lm-1.5b | reader-lm-1.7b | reader-lm-3b | |
|---|---|---|---|---|---|---|---|
| Hidden Size | 512 | 576 | 960 | 896 | 1536 | 2048 | 3072 |
| # Layers | 8 | 30 | 32 | 24 | 28 | 24 | 32 |
| # Query Heads | 16 | 9 | 15 | 14 | 12 | 32 | 32 |
| # KV Heads | 8 | 3 | 5 | 2 | 2 | 32 | 32 |
| Head Size | 32 | 64 | 64 | 64 | 128 | 64 | 96 |
| Intermediate Size | 2048 | 1536 | 2560 | 4864 | 8960 | 8192 | 8192 |
| Attention Bias | False | False | False | True | True | False | False |
| Embedding Tying | False | True | True | True | True | True | False |
| Vocabulary Size | 32768 | 49152 | 49152 | 151646 | 151646 | 49152 | 32064 |
| Base Model | Lite-Oute-1-65M-Instruct | SmolLM-135M | SmolLM-360M-Instruct | Qwen2-0.5B-Instruct | Qwen2-1.5B-Instruct | SmolLM-1.7B | Phi-3-mini-128k-instruct |
模型訓練分為兩個階段:
- 短而簡單的 HTML:在這個階段,最大序列長度(HTML + markdown)設定為 32K tokens,總共訓練了 15 億個 tokens。
- 長而複雜的 HTML:序列長度擴展到 128K tokens,訓練了 12 億個 tokens。我們在這個階段實作了來自朱子霖的"Ring Flash Attention"(2024)的 zigzag-ring-attention 機制。
由於訓練數據包含了長達 128K tokens 的序列,我們認為該模型可以毫無問題地支援到 256K tokens。然而,處理 512K tokens 可能會有挑戰,因為將 RoPE 位置嵌入擴展到訓練序列長度的四倍可能會導致性能下降。
對於 65M 和 135M 參數的模型,我們觀察到它們可以實現合理的"複製"行為,但僅限於短序列(少於 1K tokens)。隨著輸入長度增加,這些模型難以產生任何合理的輸出。考慮到現代 HTML 源代碼很容易超過 100K tokens,1K tokens 的限制遠遠不夠。
tag退化和無意義循環
我們遇到的一個主要挑戰是退化現象,特別是重複和循環的形式。在生成一些 tokens 後,模型會開始重複生成相同的 token,或陷入循環,不斷重複一小段 tokens 序列,直到達到允許的最大輸出長度。

為了解決這個問題:
- 我們採用了對比搜索作為解碼方法,並在訓練過程中加入對比損失。從我們的實驗來看,這種方法在實踐中有效地減少了重複生成。
- 我們在 transformer pipeline 中實作了一個簡單的重複停止標準。這個標準會自動檢測模型何時開始重複 tokens,並提前停止解碼以避免無意義循環。這個想法受到了這個討論的啟發。
tag長輸入的訓練效率
為了減少處理長輸入時出現內存不足(OOM)錯誤的風險,我們實作了分塊模型前向傳播。這種方法通過較小的塊來編碼長輸入,減少 VRAM 使用。
我們改進了訓練框架中的數據打包實作,這是基於 Transformers Trainer 的。為了優化訓練效率,多個短文本(例如 2K tokens)被連接成一個長序列(例如 30K tokens),實現無填充訓練。然而,在原始實作中,一些短例子被分割成兩個子文本並包含在不同的長訓練序列中。在這種情況下,第二個子文本會失去其上下文(在我們的案例中是原始 HTML 內容),導致訓練數據損壞。這迫使模型依賴其參數而不是輸入上下文,我們認為這是產生幻覺的主要來源。
最終,我們選擇了 0.5B 和 1.5B 模型進行發布。0.5B 模型是能夠在長上下文輸入上實現所需"選擇性複製"行為的最小模型,而 1.5B 模型是在不會遇到參數規模收益遞減的情況下,顯著改善性能的最小較大模型。
tag替代架構:僅編碼器模型
在這個專案的早期,我們也探索了使用僅編碼器架構來解決這個任務。如前所述,HTML 到 Markdown 的轉換任務主要是一個"選擇性複製"任務。給定一個訓練對(原始 HTML 和 markdown),我們可以將同時存在於輸入和輸出中的 tokens 標記為 1,其餘標記為 0。這將問題轉換為類似命名實體識別(NER)的 token 分類任務。
雖然這種方法在邏輯上似乎合理,但在實踐中遇到了重大挑戰。首先,來自真實世界的原始 HTML 極其嘈雜且冗長,使得 1 標籤極其稀疏,因此模型難以學習。其次,在 0-1 模式中編碼特殊的 markdown 語法是有問題的,因為像 ## title、*bold* 和 | table | 這樣的符號在原始 HTML 輸入中並不存在。第三,輸出 tokens 並不總是嚴格遵循輸入的順序。特別是在表格和連結中經常發生輕微的重排序,這使得在簡單的 0-1 模式中表示這種重排序行為變得困難。短距離重排序可以通過動態規劃或對齊扭曲算法來處理,引入像 -1, -2, +1, +2 這樣的標籤來表示距離偏移,將二元分類問題轉換為多類 token 分類任務。
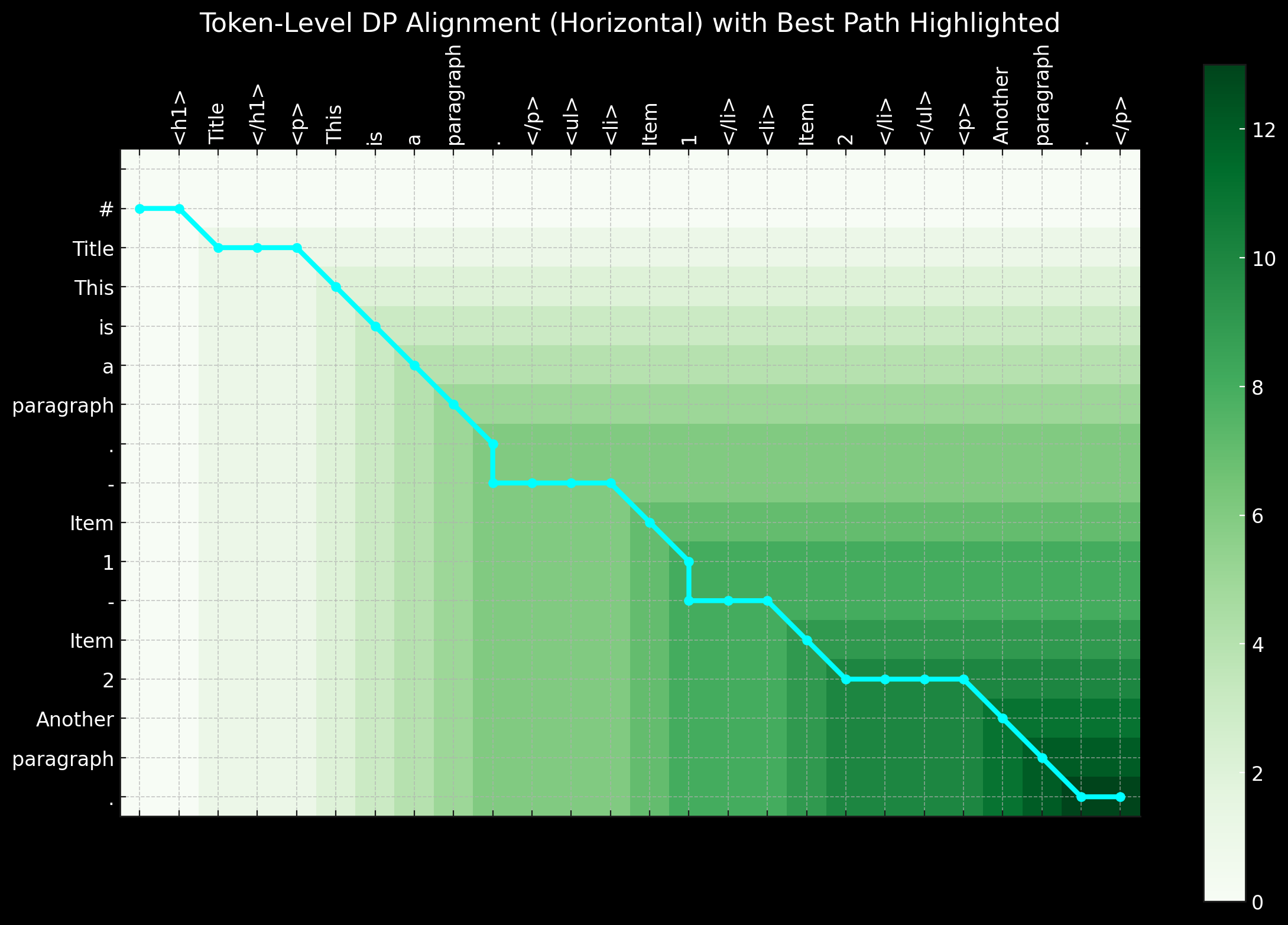
總之,使用僅編碼器架構並將其視為 token 分類任務來解決問題有其優點,特別是因為與僅解碼器模型相比,訓練序列更短,更適合 VRAM。然而,主要挑戰在於準備好的訓練數據。當我們意識到使用動態規劃和啟發式方法來創建完美的 token 級別標籤序列所花費的時間和精力過於龐大時,我們決定放棄這種方法。
tag結論
Reader-LM 是一個創新的小型語言模型 (SLM),專為網路上的數據提取和清理而設計。受到 Jina Reader 的啟發,我們的目標是創建一個端到端的語言模型解決方案,能夠將原始、雜亂的 HTML 轉換為整潔的 markdown。同時,我們注重成本效益,保持模型體積小巧,確保 Reader-LM 實用且可用。這也是 Jina AI 首次訓練的僅解碼器長上下文模型。
儘管這項任務最初可能看起來只是一個簡單的「選擇性複製」問題,但將 HTML 轉換和清理為 markdown 遠非易事。具體來說,它要求模型在位置感知和基於上下文的推理方面表現出色,這需要更大的參數規模,特別是在隱藏層方面。相比之下,學習 markdown 語法相對比較直接。
在實驗過程中,我們還發現從頭開始訓練 SLM 特別具有挑戰性。從預訓練模型開始,再繼續進行特定任務的訓練,顯著提高了訓練效率。在效率和品質方面仍有很大的改進空間:擴展上下文長度、加快解碼速度,以及在輸入中添加指令支持,這將使 Reader-LM 能夠將網頁的特定部分提取為 markdown。




