

繼將 Jina Embeddings 整合到 Deepset 的 Haystack 2.0 和發布 Jina Reranker 之後,我們很高興宣布 Jina Reranker 現在也可以通過 Jina Haystack 擴展使用。


Haystack 是一個端到端的框架,可以協助您完成 GenAI 專案生命週期的每個階段。無論您想要執行文件搜索、檢索增強生成(RAG)、問答還是答案生成,Haystack 都可以將最先進的 embedding 模型和 LLM 整合到管道中,以構建端到端的 NLP 應用程式並解決您的使用案例。
在這篇文章中,我們將展示如何使用它們來建立自己的 Jira 工單搜索引擎,以簡化您的操作並且不再浪費時間建立重複的問題。
要跟隨本教程,您需要一個 Jina Reranker API 金鑰。您可以從 Jina Reranker 網站建立一個擁有一百萬個代幣免費試用額度的金鑰。
tag檢索 Jira 支援工單
任何處理複雜專案的團隊都經歷過這種困擾:想要提交一個問題,但不知道是否已經有相同問題的工單存在。
在接下來的教程中,我們將向您展示如何使用 Jina Reranker 和 Haystack 管道輕鬆創建一個工具,該工具可以在建立新工單時提示可能的重複工單。
- 通過輸入需要與所有現有工單進行核對的工單,管道將首先從數據庫中檢索所有相關問題。
- 然後它會從列表中移除初始工單(如果它已經存在於數據庫中)和任何子工單(即父 ID 對應於原始工單的工單)。
- 最終的選擇現在只包括可能涵蓋與原始工單相同主題但在數據庫中未通過其 ID 標記為相關的問題。這些工單會被重新排序以確保最大的相關性,並使您能夠識別數據庫中的重複條目。
tag獲取數據集
為了實施我們的解決方案,我們選擇了 Apache Zookeeper 專案中所有"進行中"的 Jira 工單。這是一個用於協調分布式應用程序進程的開源服務。
我們已將工單放在一個 JSON 文件中以使其更方便使用。請下載該文件到您的工作空間。
tag設置先決條件
要安裝需求,請運行:
pip install --q chromadb haystack-ai jina-haystack chroma-haystack
要輸入 API 金鑰,將其設置為環境變數:
import os
import getpass
os.environ["JINA_API_KEY"] = getpass.getpass()
getpass.getpass() 將提示您在相應的代碼塊下方輸入 API 金鑰。您可以在那裡輸入金鑰並按 Enter 繼續教程。如果您願意,也可以直接用 API 金鑰替換 getpass.getpass()。tag建立索引管道
索引管道將預處理工單,將它們轉換為向量,並進行存儲。我們將使用 Chroma DocumentStore 作為我們的向量數據庫來存儲向量嵌入,通過 Chroma Document Store Haystack 整合。
from haystack_integrations.document_stores.chroma import ChromaDocumentStore
document_store = ChromaDocumentStore()
我們將首先定義我們的自定義數據預處理器,只考慮相關的文檔字段並刪除所有空條目:
import json
from typing import List
from haystack import Document, component
relevant_keys = ['Summary', 'Issue key', 'Issue id', 'Parent id', 'Issue type', 'Status', 'Project lead', 'Priority', 'Assignee', 'Reporter', 'Creator', 'Created', 'Updated', 'Last Viewed', 'Due Date', 'Labels',
'Description', 'Comment', 'Comment__1', 'Comment__2', 'Comment__3', 'Comment__4', 'Comment__5', 'Comment__6', 'Comment__7', 'Comment__8', 'Comment__9', 'Comment__10', 'Comment__11', 'Comment__12',
'Comment__13', 'Comment__14', 'Comment__15']
@component
class RemoveKeys:
@component.output_types(documents=List[Document])
def run(self, file_name: str):
with open(file_name, 'r') as file:
tickets = json.load(file)
cleaned_tickets = []
for t in tickets:
t = {k: v for k, v in t.items() if k in relevant_keys and v}
cleaned_tickets.append(t)
return {'documents': cleaned_tickets}
然後我們需要創建一個自定義 JSON 轉換器,將工單轉換為 Haystack 可以理解的 Document 對象:
@component
class JsonConverter:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document]):
tickets_documents = []
for t in tickets:
if 'Parent id' in t:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': t['Parent id']})
else:
t = Document(content=json.dumps(t), meta={'Issue key': t['Issue key'], 'Issue id': t['Issue id'], 'Parent id': ''})
tickets_documents.append(t)
return {'documents': tickets_documents}
最後,我們對 Documents 進行嵌入,並將這些嵌入寫入 ChromaDocumentStore:
from haystack import Pipeline
from haystack.components.writers import DocumentWriter
from haystack_integrations.components.retrievers.chroma import ChromaEmbeddingRetriever
from haystack.document_stores.types import DuplicatePolicy
from haystack_integrations.components.embedders.jina import JinaDocumentEmbedder
retriever = ChromaEmbeddingRetriever(document_store=document_store)
retriever_reranker = ChromaEmbeddingRetriever(document_store=document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component('cleaner', RemoveKeys())
indexing_pipeline.add_component('converter', JsonConverter())
indexing_pipeline.add_component('embedder', JinaDocumentEmbedder(model='jina-embeddings-v2-base-en'))
indexing_pipeline.add_component('writer', DocumentWriter(document_store=document_store, policy=DuplicatePolicy.SKIP))
indexing_pipeline.connect('cleaner', 'converter')
indexing_pipeline.connect('converter', 'embedder')
indexing_pipeline.connect('embedder', 'writer')
indexing_pipeline.run({'cleaner': {'file_name': 'tickets.json'}})
這應該會創建一個進度條並輸出一個包含存儲信息的簡短 JSON:
Calculating embeddings: 100%|██████████| 1/1 [00:01<00:00, 1.21s/it]
{'embedder': {'meta': {'model': 'jina-embeddings-v2-base-en',
'usage': {'total_tokens': 20067, 'prompt_tokens': 20067}}},
'writer': {'documents_written': 31}}tag建立查詢流程
讓我們建立一個查詢流程,以便開始比較工單。在 Haystack 2.0 中,檢索器與 DocumentStore 緊密結合。如果我們將文件存儲傳遞給先前初始化的檢索器,此流程就可以訪問我們生成的文件,並將它們傳遞給重排序器。重排序器然後直接將這些文件與問題進行比較,並根據相關性進行排名。
我們首先定義自定義清理器,以移除包含與作為查詢傳遞的問題具有相同問題 ID 或父 ID 的工單:
from typing import Optional
@component
class RemoveRelated:
@component.output_types(documents=List[Document])
def run(self, tickets: List[Document], query_id: Optional[str]):
retrieved_tickets = []
for t in tickets:
if not t.meta['Issue id'] == query_id and not t.meta['Parent id'] == query_id:
retrieved_tickets.append(t)
return {'documents': retrieved_tickets}
然後我們對查詢進行嵌入,檢索相關文件,清理選擇,最後進行重排序:
from haystack_integrations.components.embedders.jina import JinaTextEmbedder
from haystack_integrations.components.rankers.jina import JinaRanker
query_pipeline_reranker = Pipeline()
query_pipeline_reranker.add_component('query_embedder_reranker', JinaTextEmbedder(model='jina-embeddings-v2-base-en'))
query_pipeline_reranker.add_component('query_retriever_reranker', retriever_reranker)
query_pipeline_reranker.add_component('query_cleaner_reranker', RemoveRelated())
query_pipeline_reranker.add_component('query_ranker_reranker', JinaRanker())
query_pipeline_reranker.connect('query_embedder_reranker.embedding', 'query_retriever_reranker.query_embedding')
query_pipeline_reranker.connect('query_retriever_reranker', 'query_cleaner_reranker')
query_pipeline_reranker.connect('query_cleaner_reranker', 'query_ranker_reranker')
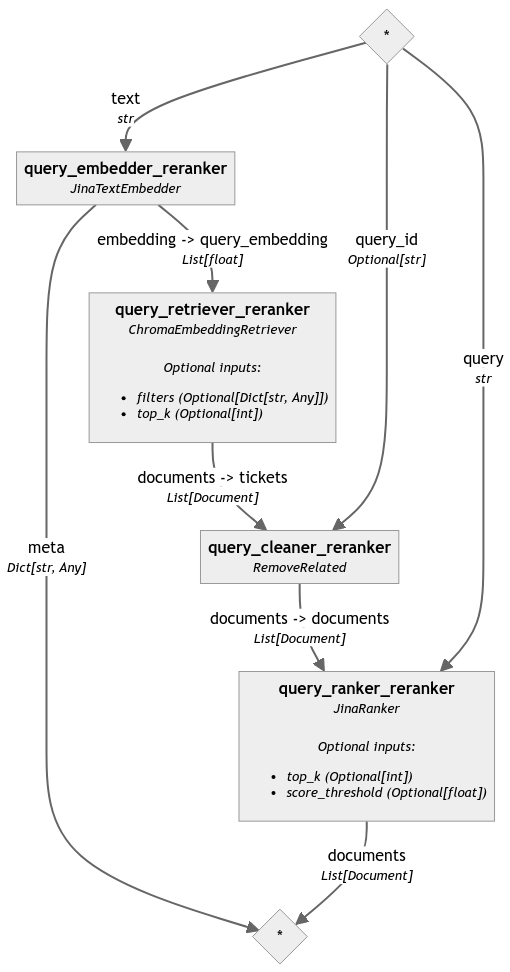
為了突顯重排序器帶來的差異,我們分析了同一個流程但沒有最後重排序步驟的情況(為了便於閱讀,本文省略了相應的程式碼,但可以在 notebook 中找到):
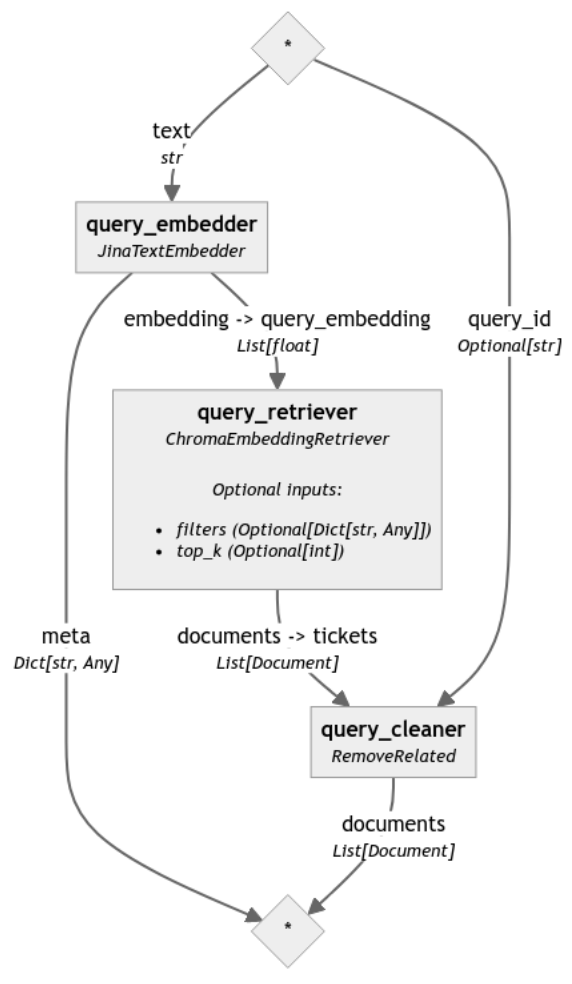
為了比較這兩個流程的結果,我們現在以現有工單的形式定義查詢,這裡是「ZOOKEEPER-3282」:
query_ticket_key = 'ZOOKEEPER-3282'
with open('tickets.json', 'r') as file:
tickets = json.load(file)
for ticket in tickets:
if ticket['Issue key'] == query_ticket_key:
query = str(ticket)
query_ticket_id = ticket['Issue id']
這涉及「文件的大規模重構」[sic]。你會看到,儘管拼寫錯誤,Jina Reranker 仍能正確檢索到相似的工單。
{
"Summary": "a big refactor for the documetations"
"Issue key": "ZOOKEEPER-3282"
"Issue id:: 13216608
"Parent id": ""
"Issue Type": "Task"
"Status": "In Progress"
"Project lead": "phunt"
"Priority": "Major"
"Assignee": "maoling"
"Reporter": "maoling"
"Creator": "maoling"
"Created": "19/Feb/19 11:50"
"Updated": "04/Aug/19 12:48"
"Last Viewed": "12/Mar/24 11:56"
"Description": "Hi guys: I'am working on doing a big refactor for the documetations.it aims to - 1.make a better reading experiences and help users know more about zookeeper quickly,as good as other projects' doc(e.g redis,hbase). - 2.have less changes to diff with the original docs as far as possible. - 3.solve the problem when we have some new features or improvements,but cannot find a good place to doc it. The new catalog may looks kile this: * is new one added. ** is the one to keep unchanged as far as possible. *** is the one modified. -------------------------------------------------------------- |---Overview |---Welcome ** [1.1] |---Overview ** [1.2] |---Getting Started ** [1.3] |---Release Notes ** [1.4] |---Developer |---API *** [2.1] |---Programmer's Guide ** [2.2] |---Recipes *** [2.3] |---Clients * [2.4] |---Use Cases * [2.5] |---Admin & Ops |---Administrator's Guide ** [3.1] |---Quota Guide ** [3.2] |---JMX ** [3.3] |---Observers Guide ** [3.4] |---Dynamic Reconfiguration ** [3.5] |---Zookeeper CLI * [3.6] |---Shell * [3.7] |---Configuration flags * [3.8] |---Troubleshooting & Tuning * [3.9] |---Contributor Guidelines |---General Guidelines * [4.1] |---ZooKeeper Internals ** [4.2] |---Miscellaneous |---Wiki ** [5.1] |---Mailing Lists ** [5.2] -------------------------------------------------------------- The Roadmap is: 1.(I pick up it : D) 1.1 write API[2.1], which includes the: 1.1.1 original API Docs which is a Auto-generated java doc,just give a link. 1.1.2. Restful-api (the apis under the /zookeeper-contrib-rest/src/main/java/org/apache/zookeeper/server/jersey/resources) 1.2 write Clients[2.4], which includes the: 1.2.1 C client 1.2.2 zk-python, kazoo 1.2.3 Curator etc....... look at an example from: https://redis.io/clients # write Recipes[2.3], which includes the: - integrate "Java Example" and "Barrier and Queue Tutorial"(Since some bugs in the examples and they are obsolete,we may delete something) into it. - suggest users to use the recipes implements of Curator and link to the Curator's recipes doc. # write Zookeeper CLI[3.6], which includes the: - about how to use the zk command line interface [./zkCli.sh] e.g ls /; get ; rmr;create -e -p etc....... - look at an example from redis: https://redis.io/topics/rediscli # write shell[3.7], which includes the: - list all usages of the shells under the zookeeper/bin. (e.g zkTxnLogToolkit.sh,zkCleanup.sh) # write Configuration flags[3.8], which includes the: - list all usages of configurations properties(e.g zookeeper.snapCount): - move the original Advanced Configuration part of zookeeperAdmin.md into it. look at an example from:https://coreos.com/etcd/docs/latest/op-guide/configuration.html # write Troubleshooting & Tuning[3.9], which includes the: - move the original "Gotchas: Common Problems and Troubleshooting" part of Administrator's Guide.md into it. - move the original "FAQ" into into it. - add some new contents (e.g https://www.yumpu.com/en/document/read/29574266/building-an-impenetrable-zookeeper-pdf-github). look at an example from:https://redis.io/topics/problems https://coreos.com/etcd/docs/latest/tuning.html # write General Guidelines[4.1], which includes the: - move the original "Logging" part of ZooKeeper Internals into it as the logger specification. - write specifications about code, git commit messages,github PR etc ... look at an example from: http://hbase.apache.org/book.html#hbase.commit.msg.format # write Use Cases[2.5], which includes the: - just move the context from: https://cwiki.apache.org/confluence/display/ZOOKEEPER/PoweredBy into it. - add some new contents.(e.g Apache Projects:Spark;Companies:twitter,fb) -------------------------------------------------------------- BTW: - Any insights or suggestions are very welcomed.After the dicussions,I will create a series of tickets(An umbrella) - Since these works can be done parallelly, if you are interested in them, please don't hesitate,just assign to yourself, pick it up. (Notice: give me a ping to avoid the duplicated work)."
}
最後,我們運行查詢流程。在這種情況下,它會檢索 20 個工單,刪除 ID 相關的條目,對它們進行重排序,並輸出 10 個最相關問題的最終選擇。
在重新排序步驟之前,輸出包含 17 張票證:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13191544 | ZOOKEEPER-3170 | Umbrella for eliminating ZooKeeper flaky tests |
| 2 | 13400622 | ZOOKEEPER-4375 | Quota cannot limit the specify value when multiply clients create/set znodes |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 13295073 | ZOOKEEPER-3775 | Wrong message in IOException |
| 5 | 13268474 | ZOOKEEPER-3617 | ZK digest ACL permissions gets overridden |
| 6 | 13296971 | ZOOKEEPER-3787 | Apply modernizer-maven-plugin to build |
| 7 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 8 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
| 9 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 10 | 13262130 | ZOOKEEPER-3578 | Add a new CLI: multi |
| 11 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 12 | 13262494 | ZOOKEEPER-3583 | Add new apis to get node type and ttl time info |
| 13 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 14 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 15 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 16 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 17 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
在加入重新排序器後,我們現在執行查詢管道:
result = query_pipeline_reranker.run(data={'query_embedder_reranker':{'text': query},
'query_retriever_reranker': {'top_k': 20},
'query_cleaner_reranker': {'query_id': query_ticket_id},
'query_ranker_reranker': {'query': query, 'top_k': 10}
}
)
for idx, res in enumerate(result['query_ranker_reranker']['documents']):
print('Doc {}:'.format(idx + 1), res)
最終輸出是 10 張最相關的票證:
| Rank | Issue ID | Issue Key | Summary |
|---|---|---|---|
| 1 | 13262989 | ZOOKEEPER-3587 | Add a documentation about docker |
| 2 | 13265507 | ZOOKEEPER-3600 | support the complete linearizable read and multiply read consistency level |
| 3 | 13249579 | ZOOKEEPER-3499 | [admin server way] Add a complete backup mechanism for zookeeper internal |
| 4 | 12478629 | ZOOKEEPER-915 | Errors that happen during sync() processing at the leader do not get propagated back to the client. |
| 5 | 13262828 | ZOOKEEPER-3585 | Add a documentation about RequestProcessors |
| 6 | 13297249 | ZOOKEEPER-3789 | fix the build warnings about @see,@link,@return found by IDEA |
| 7 | 12998876 | ZOOKEEPER-2519 | zh->state should not be 0 while handle is active |
| 8 | 13536435 | ZOOKEEPER-4696 | Update for Zookeeper latest version |
| 9 | 12728973 | ZOOKEEPER-1983 | Append to zookeeper.out (not overwrite) to support logrotation |
| 10 | 13222060 | ZOOKEEPER-3318 | [CLI way]Add a complete backup mechanism for zookeeper internal |
tagJina Embeddings 和 Reranker 的優勢
總結這個教程,我們基於 Jina Embeddings、Jina Reranker 和 Haystack 2.0 構建了一個重複票證識別工具。上述結果清楚地表明,需要 Jina Embeddings 通過向量搜尋檢索相關文檔,並需要 Jina Reranker 最終獲取最相關的內容。
以兩個與新增文檔相關的問題為例,即"ZOOKEEPER-3585"和"ZOOKEEPER-3587",我們看到在檢索步驟之後,它們分別被正確地列在第 11 和第 9 位。在對文檔重新排序後,它們現在都進入了最相關文檔的前 5 名,分別位於第 5 和第 1 位,顯示出顯著的改進。
通過在 Haystack 的管道中整合這兩個模型,整個工具已經可以使用。這種組合使 Jina Haystack 擴展成為您應用程式的完美解決方案。





