


自從 OpenAI 發布 O1 模型以來,AI 社群中最受討論的話題之一就是擴展測試時計算。這指的是在推理階段——AI 模型針對輸入生成輸出的階段——而非在預訓練期間分配額外的計算資源。一個著名的例子是"思維鏈"多步推理,它使模型能夠進行更廣泛的內部思考,例如評估多個可能的答案、更深入的規劃,在得出最終回應前進行自我反思。這種策略提高了答案品質,特別是在複雜的推理任務中。阿里巴巴最近發布的 QwQ-32B-Preview 模型就遵循了這種通過增加測試時計算來改進 AI 推理的趨勢。
使用 OpenAI 的 O1 模型時,用戶可以明顯注意到,當模型構建推理鏈來解決問題時,多步推理需要額外的時間。
在 Jina AI,我們更專注於 embeddings 和 rerankers,而不是 LLMs,所以對我們來說,從這個角度考慮擴展測試時計算是很自然的:"思維鏈"如何應用於 embedding 模型?雖然一開始可能不太直觀,但本文探討了一個新的視角,並展示了如何將擴展測試時計算應用於 jina-clip 來對分佈外(OOD)圖像進行分類——解決原本不可能完成的任務。

tag案例研究

我們的實驗使用 TheFusion21/PokemonCards 數據集進行寶可夢分類,該數據集包含數千張寶可夢交換卡片圖像。這個任務是圖像分類,其中輸入是剪裁過的寶可夢卡片藝術作品(去除所有文字/描述),輸出是從預定義的名稱集合中選擇正確的寶可夢名稱。這個任務對 CLIP embedding 模型來說是一個特別有趣的挑戰,因為:
- 寶可夢的名稱和視覺表現對模型來說是特定領域的、分佈外的概念,使直接分類變得困難
- 每個寶可夢都有清晰的視覺特徵,可以分解為基本元素(形狀、顏色、姿勢),這些是 CLIP 可能更容易理解的
- 卡片藝術作品提供了一致的視覺格式,同時通過不同的背景、姿勢和藝術風格引入複雜性
- 這個任務需要同時整合多個視覺特徵,類似於語言模型中的複雜推理鏈

Absol G,Aerodactyl,Weedle,Caterpie、Azumarill、Bulbasaur、Venusaur、Absol、Aggron、Beedrill δ、Alakazam、Ampharos、Dratini、Ampharos、Ampharos、Arcanine、Blaine's Moltres、Aerodactyl、Celebi & Venusaur-GX、Caterpie]tag基準方法
基準方法使用寶可夢卡牌圖片和名稱之間的簡單直接比較。首先,我們裁剪每張寶可夢卡片圖像以移除所有文字資訊(標題、頁尾、描述),以防止 CLIP 模型因這些文字中出現的寶可夢名稱而進行簡單猜測。然後,我們使用 jina-clip-v1 和 jina-clip-v2 模型對裁剪後的圖像和寶可夢名稱進行編碼,以獲得其各自的嵌入表示。分類是通過計算這些圖像和文字嵌入之間的餘弦相似度來完成的——每個圖像都與具有最高相似度分數的名稱匹配。這在卡牌藝術作品和寶可夢名稱之間建立了一對一的直接匹配,而不需要任何額外的上下文或屬性資訊。以下偽代碼總結了基準方法。
# Preprocessing
cropped_images = [crop_artwork(img) for img in pokemon_cards] # Remove text, keep only art
pokemon_names = ["Absol", "Aerodactyl", ...] # Raw Pokemon names
# Get embeddings using jina-clip-v1
image_embeddings = model.encode_image(cropped_images)
text_embeddings = model.encode_text(pokemon_names)
# Classification by cosine similarity
similarities = cosine_similarity(image_embeddings, text_embeddings)
predicted_names = [pokemon_names[argmax(sim)] for sim in similarities]
# Evaluate
accuracy = mean(predicted_names == ground_truth_names)tag分類的"思維鏈"
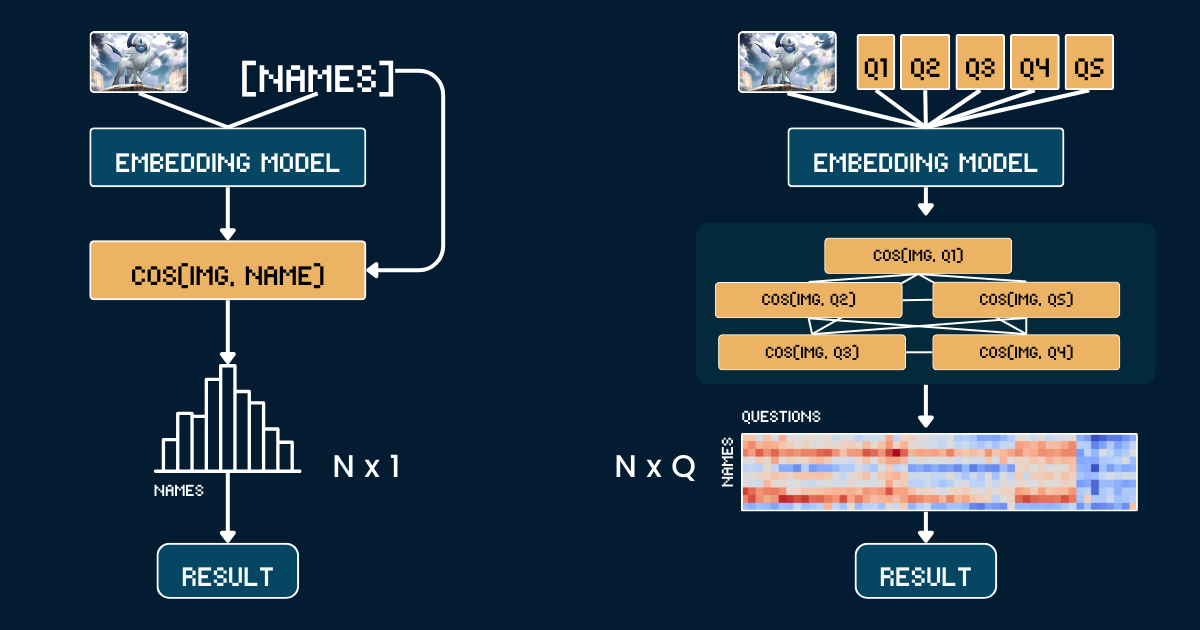
我們不是直接將圖像與名稱匹配,而是將寶可夢識別分解為一個結構化的視覺屬性系統。我們定義了五個關鍵屬性組:主要顏色(如"白色"、"藍色")、基本形態(如"一隻狼"、"一隻有翅膀的爬行動物")、關鍵特徵(如"單一白角"、"大翅膀")、體型(如"四足狼形"、"有翅膀且纖細")和背景場景(如"外太空"、"綠色森林")。
對於每個屬性組,我們創建特定的文本提示(如"這隻寶可夢的身體主要是{}顏色")並配對相關選項。然後我們使用模型計算圖像與每個屬性選項之間的相似度分數。這些分數通過 softmax 轉換為概率,以獲得更校準的置信度衡量。
完整的思維鏈(CoT)結構包含兩個部分:classification_groups 描述提示組,以及 pokemon_rules 定義每個寶可夢應匹配的屬性選項。例如,阿勃梭魯應該在顏色上匹配"白色",在形態上匹配"狼形"。完整的 CoT 如下所示(我們稍後將解釋如何建構這個):
pokemon_system = {
"classification_cot": {
"dominant_color": {
"prompt": "This Pokémon's body is mainly {} in color.",
"options": [
"white", # Absol, Absol G
"gray", # Aggron
"brown", # Aerodactyl, Weedle, Beedrill δ
"blue", # Azumarill
"green", # Bulbasaur, Venusaur, Celebi&Venu, Caterpie
"yellow", # Alakazam, Ampharos
"red", # Blaine's Moltres
"orange", # Arcanine
"light blue"# Dratini
]
},
"primary_form": {
"prompt": "It looks like {}.",
"options": [
"a wolf", # Absol, Absol G
"an armored dinosaur", # Aggron
"a winged reptile", # Aerodactyl
"a rabbit-like creature", # Azumarill
"a toad-like creature", # Bulbasaur, Venusaur, Celebi&Venu
"a caterpillar larva", # Weedle, Caterpie
"a wasp-like insect", # Beedrill δ
"a fox-like humanoid", # Alakazam
"a sheep-like biped", # Ampharos
"a dog-like beast", # Arcanine
"a flaming bird", # Blaine's Moltres
"a serpentine dragon" # Dratini
]
},
"key_trait": {
"prompt": "Its most notable feature is {}.",
"options": [
"a single white horn", # Absol, Absol G
"metal armor plates", # Aggron
"large wings", # Aerodactyl, Beedrill δ
"rabbit ears", # Azumarill
"a green plant bulb", # Bulbasaur, Venusaur, Celebi&Venu
"a small red spike", # Weedle
"big green eyes", # Caterpie
"a mustache and spoons", # Alakazam
"a glowing tail orb", # Ampharos
"a fiery mane", # Arcanine
"flaming wings", # Blaine's Moltres
"a tiny white horn on head" # Dratini
]
},
"body_shape": {
"prompt": "The body shape can be described as {}.",
"options": [
"wolf-like on four legs", # Absol, Absol G
"bulky and armored", # Aggron
"winged and slender", # Aerodactyl, Beedrill δ
"round and plump", # Azumarill
"sturdy and four-legged", # Bulbasaur, Venusaur, Celebi&Venu
"long and worm-like", # Weedle, Caterpie
"upright and humanoid", # Alakazam, Ampharos
"furry and canine", # Arcanine
"bird-like with flames", # Blaine's Moltres
"serpentine" # Dratini
]
},
"background_scene": {
"prompt": "The background looks like {}.",
"options": [
"outer space", # Absol G, Beedrill δ
"green forest", # Azumarill, Bulbasaur, Venusaur, Weedle, Caterpie, Celebi&Venu
"a rocky battlefield", # Absol, Aggron, Aerodactyl
"a purple psychic room", # Alakazam
"a sunny field", # Ampharos
"volcanic ground", # Arcanine
"a red sky with embers", # Blaine's Moltres
"a calm blue lake" # Dratini
]
}
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 2
},
"Absol G": {
"dominant_color": 0,
"primary_form": 0,
"key_trait": 0,
"body_shape": 0,
"background_scene": 0
},
// ...
}
}
最終的分類將這些屬性概率結合在一起——我們不是進行單一的相似度比較,而是進行多個結構化比較並匯總其概率,以做出更明智的決定。
# Classification process
def classify_pokemon(image):
# Generate all text prompts
all_prompts = []
for group in classification_cot:
for option in group["options"]:
prompt = group["prompt"].format(option)
all_prompts.append(prompt)
# Get embeddings and similarities
image_embedding = model.encode_image(image)
text_embeddings = model.encode_text(all_prompts)
similarities = cosine_similarity(image_embedding, text_embeddings)
# Convert to probabilities per attribute group
probabilities = {}
for group_name, group_sims in group_similarities:
probabilities[group_name] = softmax(group_sims)
# Score each Pokemon based on matching attributes
scores = {}
for pokemon, rules in pokemon_rules.items():
score = 0
for group, target_idx in rules.items():
score += probabilities[group][target_idx]
scores[pokemon] = score
return max(scores, key=scores.get)tag複雜度分析
假設我們要將一張圖像分類為 N 個寶可夢名稱之一。基準方法需要計算 N 個文本嵌入(每個寶可夢名稱一個)。相比之下,我們的擴展測試時間計算方法需要計算 Q 個文本嵌入,其中
Q 是所有問題中問題選項組合的總數。兩種方法都需要計算一個圖像嵌入並執行最終的分類步驟,所以我們將這些共同操作排除在比較之外。在這個案例研究中,我們的 N=13 和 Q=52。在極端情況下,當 Q = N 時,我們的方法基本上就會退化為基準方法。然而,有效擴展測試時計算的關鍵在於:
- 精心構造問題以增加
Q - 確保每個問題都能提供關於最終答案的不同、有意義的線索
- 設計盡可能正交的問題以最大化它們的聯合資訊增益。
這種方法類似於"二十個問題"遊戲,每個問題都經過策略性選擇,以有效縮小可能的答案範圍。
tag評估
我們的評估在 117 張測試圖像上進行,涵蓋 13 個不同的寶可夢類別。結果如下:
| Approach | jina-clip-v1 | jina-clip-v2 |
|---|---|---|
| Baseline | 31.36% | 16.10% |
| CoT | 46.61% | 38.14% |
| Improvement | +15.25% | +22.04% |
可以看到,在這個非常規或 OOD 任務上,相同的 CoT 分類對兩個模型都帶來了顯著的改進(分別提升了 15.25% 和 22.04%)。這也表明一旦構建了 pokemon_system,相同的 CoT 系統可以有效地在不同模型間遷移;且無需微調或後期訓練。
值得注意的是 v1 在寶可夢分類上相對較強的基準性能(31.36%)。該模型是在 LAION-400M(包含寶可夢相關內容)上訓練的。相比之下,v2 是在 DFN-2B(抽樣 400M 實例)上訓練的,這是一個品質更高但過濾更嚴格的數據集,可能排除了寶可夢相關內容,這解釋了 V2 在這個特定任務上較低的基準性能(16.10%)。
tag有效構建 pokemon_system
我們的擴展測試時計算方法的有效性很大程度上取決於我們如何構建 pokemon_system。構建這個系統有不同的方法,從手動到完全自動化。
手動構建
最直接的方法是手動分析寶可夢數據集並創建屬性組、提示和規則。領域專家需要識別關鍵的視覺屬性,如顏色、形狀和獨特特徵。然後為每個屬性編寫自然語言提示,列舉每個屬性組的可能選項,並將每個寶可夢映射到其正確的屬性選項。雖然這提供了高質量的規則,但耗時且難以擴展到更大的 N。
LLM 輔助構建
我們可以利用 LLM 來加速這個過程,通過提示它們來生成分類系統。一個結構良好的提示應要求基於視覺特徵的屬性組、自然語言提示模板、全面且互斥的選項,以及每個寶可夢的映射規則。LLM 可以快速生成初稿,不過其輸出可能需要驗證。
I need help creating a structured system for Pokemon classification. For each Pokemon in this list: [Absol, Aerodactyl, Weedle, Caterpie, Azumarill, ...], create a classification system with:
1. Classification groups that cover these visual attributes:
- Dominant color of the Pokemon
- What type of creature it appears to be (primary form)
- Its most distinctive visual feature
- Overall body shape
- What kind of background/environment it's typically shown in
2. For each group:
- Create a natural language prompt template using "{}" for the option
- List all possible options that could apply to these Pokemon
- Make sure options are mutually exclusive and comprehensive
3. Create rules that map each Pokemon to exactly one option per attribute group, using indices to reference the options
Please output this as a Python dictionary with two main components:
- "classification_groups": containing prompts and options for each attribute
- "pokemon_rules": mapping each Pokemon to its correct attribute indices
Example format:
{
"classification_groups": {
"dominant_color": {
"prompt": "This Pokemon's body is mainly {} in color",
"options": ["white", "gray", ...]
},
...
},
"pokemon_rules": {
"Absol": {
"dominant_color": 0, # index for "white"
...
},
...
}
}一個更穩健的方法是將 LLM 生成與人工驗證相結合。首先,LLM 生成初始系統。然後,專家審查並修正屬性分組、選項完整性和規則準確性。LLM 根據這些反饋改進系統,這個過程不斷迭代直到達到滿意的質量。這種方法在效率和準確性之間取得平衡。
使用 DSPy 自動構建
對於完全自動化的方法,我們可以使用 DSPy 來迭代優化 pokemon_system。這個過程從一個簡單的 pokemon_system 開始,可以是手動或由 LLM 編寫的初始提示。每個版本都在保留集上進行評估,使用準確率作為 DSPy 的反饋信號。基於這個性能,生成優化的提示(即新版本的 pokemon_system)。這個循環重複直到收斂,在整個過程中,嵌入模型保持完全不變。
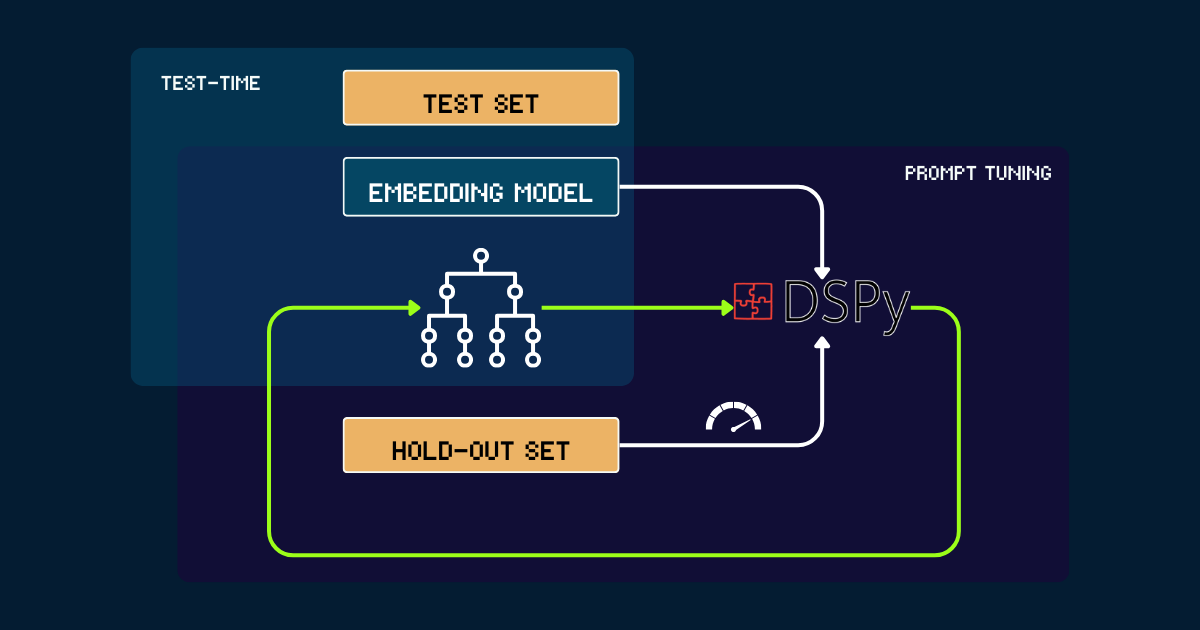
pokemon_system CoT 設計;調整過程只需要為每個任務執行一次。tag為什麼要擴展嵌入模型的測試時計算?
因為擴展預訓練最終會在經濟上變得難以承受。
自 Jina 嵌入套件發布以來——包括 jina-embeddings-v1、v2、v3、jina-clip-v1、v2 和 jina-ColBERT-v1、v2——每次通過擴展預訓練進行的模型升級都伴隨著更多成本。例如,我們的第一個模型 jina-embeddings-v1 於 2023 年 6 月發布,擁有 1.1 億參數。當時訓練它的成本在 5,000 到 10,000 美元之間,取決於如何計算。對於 jina-embeddings-v3,雖然改進顯著,但主要來自於投入資源的增加。頂級模型的成本軌跡已經從數千美元上升到數萬美元,對於較大的 AI 公司,甚至達到了數億美元。雖然在預訓練中投入更多的金錢、資源和數據會產生更好的模型,但邊際回報最終會使進一步擴展在經濟上變得不可持續。

另一方面,現代嵌入模型正變得越來越強大:多語言、多任務、多模態,並具有強大的零樣本和指令跟隨能力。這種多功能性為算法改進和擴展測試時計算留下了很大空間。
問題就變成了:用戶願意為他們深切關心的查詢付出多少成本?如果為固定的預訓練模型容忍更長的推理時間能顯著改善結果質量,許多人會認為這是值得的。在我們看來,擴展嵌入模型的測試時計算還有大量未開發的潛力。這代表著一個轉變,從單純增加訓練時的模型大小,轉向在推理階段增加計算努力以實現更好的性能。
tag結論
我們對 jina-clip-v1/v2 的測試時計算案例研究顯示了幾個關鍵發現:
- 我們在非常規或分佈外(OOD)數據上取得了更好的性能,無需對嵌入進行任何微調或後期訓練。
- 系統通過迭代細化相似度搜索和分類標準,做出了更細微的區分。
- 通過引入動態提示調整和迭代推理,我們將嵌入模型的推理過程從單一查詢轉變為更複雜的思維鏈。
這個案例研究僅僅觸及了測試時計算可能性的表面。在算法上還有很大的擴展空間。例如,我們可以開發方法來迭代選擇最能有效縮小答案空間的問題,類似於"二十個問題"遊戲中的最佳策略。通過擴展測試時計算,我們可以推動嵌入模型超越其當前限制,使它們能夠處理曾經看似遙不可及的更複雜、更細緻的任務。
