


Jina AI 宣布在其最先進的重排序模型系列中推出新模型,現已在 AWS Sagemaker 和 Hugging Face 上提供:jina-reranker-v1-turbo-en 和 jina-reranker-v1-tiny-en。這些模型在保持標準基準測試的高性能的同時,優先考慮速度和大小,為那些對響應時間和資源使用至關重要的環境提供更快速且更節省記憶體的重排序過程。




Reranker Turbo 和 Tiny 經過優化,可在資訊檢索應用中實現極快的響應時間。與我們的嵌入模型一樣,它們使用 JinaBERT 架構,這是 BERT 架構的一個變體,並通過 ALiBi 的對稱雙向變體進行了增強。該架構支援長文本序列,我們的模型最多可接受 8,192 個 tokens,非常適合對大型文件進行深入分析和需要詳細語言理解的複雜查詢。
Turbo 和 Tiny 模型借鑑了 Jina Reranker v1 的經驗。重排序可能會成為資訊檢索應用的主要瓶頸。傳統的搜尋應用是一項非常成熟的技術,其性能已被充分理解。重排序器為基於文本的檢索增加了極大的精確度,但 AI 模型體積龐大,運行速度可能較慢且成本較高。
許多使用者更傾向於使用更小、更快、成本更低的模型,即使這可能會犧牲一些準確性。有一個單一的目標——重新排序搜索結果——使得簡化模型成為可能,並在更緊湊的模型中為使用者提供有競爭力的性能。通過減少隱藏層的數量,我們加快了處理速度並減小了模型大小。這些模型運行成本更低,更快的速度使其更適合於不能容忍太多延遲的應用,同時保留了幾乎所有大型模型的性能。
在本文中,我們將向您展示 Reranker Turbo 和 Reranker Tiny 的架構,評估其性能,並向您展示如何開始使用它們。
tag精簡的架構
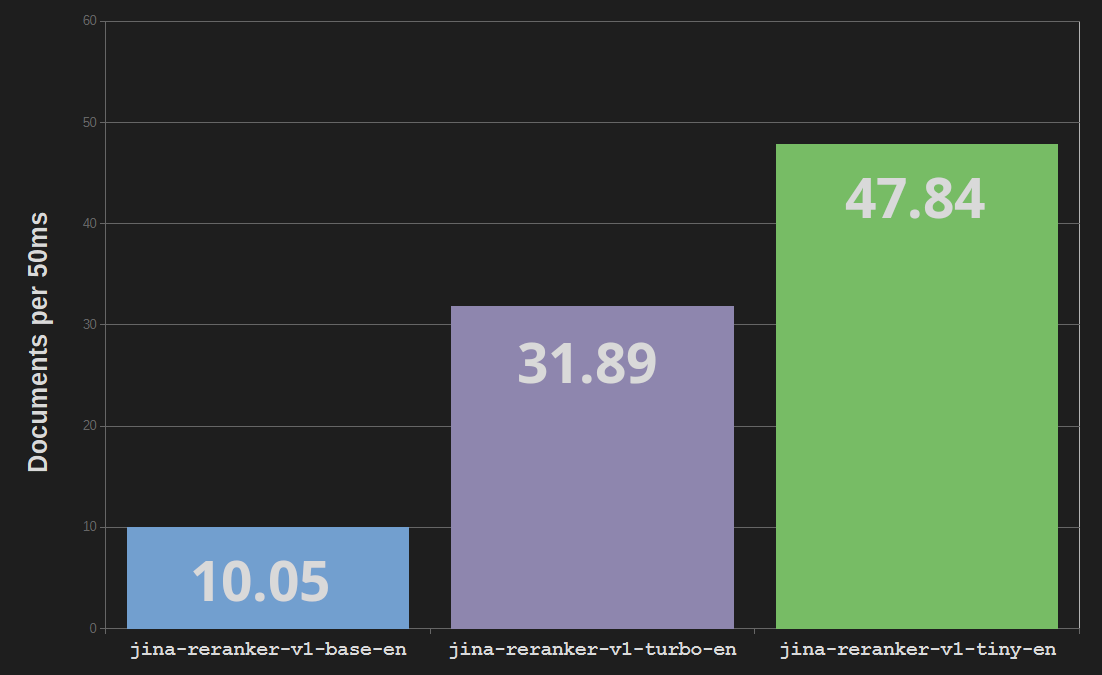
Jina Reranker Turbo(jina-reranker-v1-turbo-en)使用六層架構,總共有 3,780 萬個參數,相比之下,基礎重排序模型 jina-reranker-v1-base-en 有 1.37 億個參數和十二層。這代表模型大小減少了四分之三,處理速度提高了三倍。
Reranker Tiny(jina-reranker-v1-tiny-en)使用四層架構,擁有 3,300 萬個參數,提供更強的並行處理能力和更快的速度——幾乎是基礎 Reranker 模型的五倍——同時比 Turbo 模型節省 13% 的記憶體成本。
tag知識蒸餾
我們使用知識蒸餾技術訓練 Reranker Turbo 和 Tiny。這是一種使用現有 AI 模型來訓練另一個模型以匹配其行為的技術。我們不使用外部數據源,而是使用現有模型來生成訓練數據。我們使用 Jina Reranker 基礎模型對文檔集合進行排序,然後使用這些結果來訓練 Turbo 和 Tiny。通過這種方式,我們可以將更多數據引入訓練過程,因為我們不受現實世界數據的限制。
這有點像學生向老師學習:已經訓練好的、高性能的模型——Jina Reranker Base 模型——通過生成新的訓練數據來「教導」未訓練的 Jina Turbo 和 Jina Tiny 模型。這種技術被廣泛用於從大型模型創建小型模型。在最理想的情況下,"教師"模型和"學生"模型之間的任務性能差異可以非常小。
tag在 BEIR 上的評估
精簡和知識蒸餾帶來的好處幾乎沒有影響性能質量。在資訊檢索的 BEIR 基準測試中,jina-reranker-v1-turbo-en 的準確率達到 jina-reranker-v1-base-en 的 95%,而 jina-reranker-v1-tiny-en 達到基礎模型分數的 92.5%。
所有 Jina Reranker 模型都能與其他流行的重排序模型相抗衡,而且大多數其他模型的尺寸都要大得多。
| Model | BEIR Score (NDCC@10) | Parameters |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 52.45 | 137M |
| jina-reranker-v1-turbo-en | 49.60 | 38M |
| jina-reranker-v1-tiny-en | 48.54 | 33M |
| Other reranking models | ||
mxbai-rerank-base-v1 |
49.19 | 184M |
mxbai-rerank-xsmall-v1 |
48.80 | 71M |
ms-marco-MiniLM-L-6-v2 |
48.64 | 23M |
bge-reranker-base |
47.89 | 278M |
ms-marco-MiniLM-L-4-v2 |
47.81 | 19M |
NDCC@10:使用前 10 個結果的歸一化折減累積增益計算的分數。
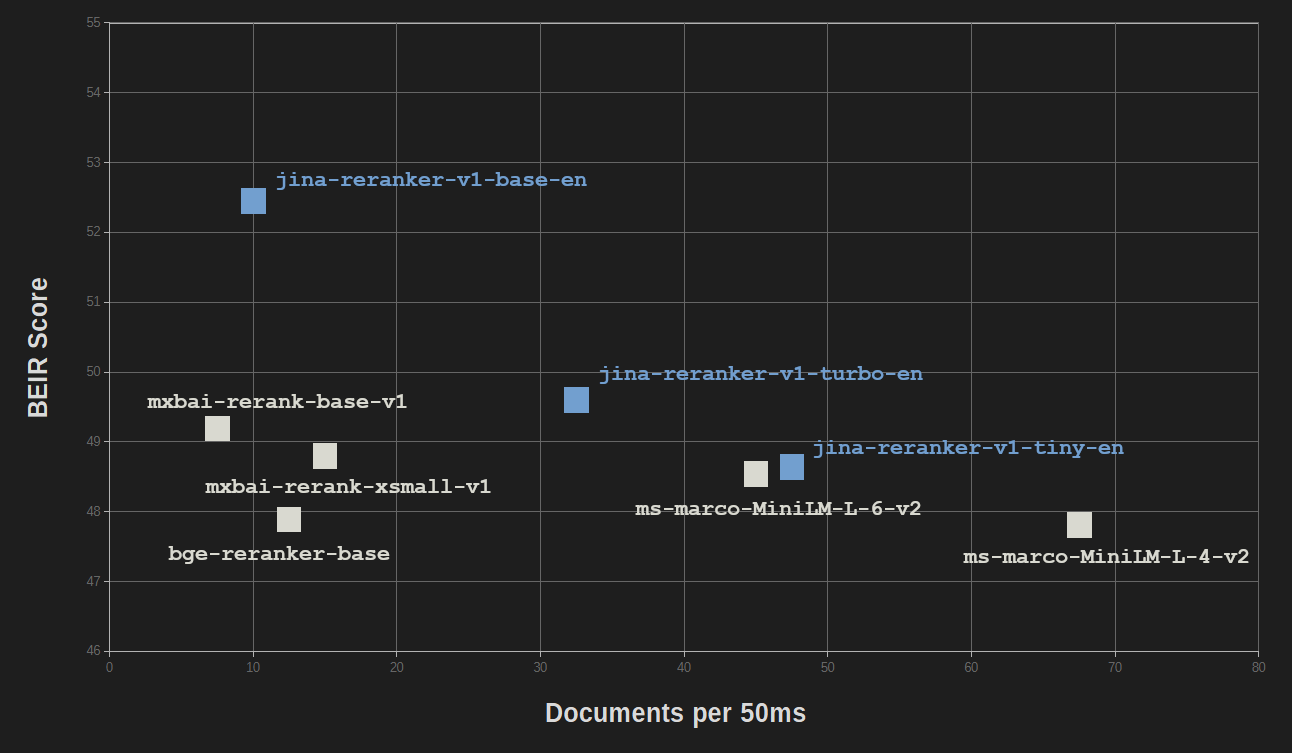
只有 MiniLM-L6(ms-marco-MiniLM-L-6-v2)和 MiniLM-L4(ms-marco-MiniLM-L-4-v2)具有相當的大小和速度,而 jina-reranker-v1-turbo-en 和 jina-reranker-v1-tiny-en 的表現則相當或明顯更好。
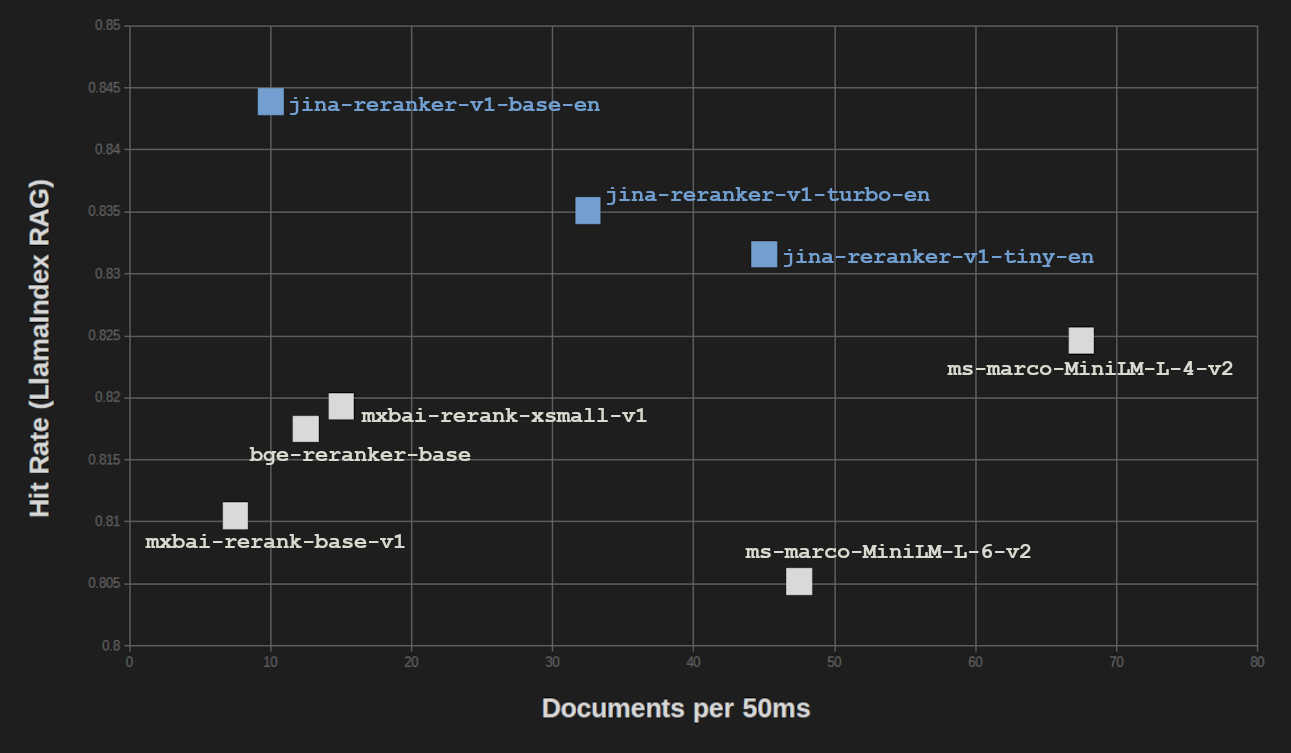
在 LlamaIndex RAG Benchmark 上,我們也獲得了類似的結果。我們在 RAG 設置中使用三個嵌入模型進行向量搜索(jina-embeddings-v2-base-en、bge-base-en-v1.5 和 Cohere-embed-english-v3.0)測試了所有三個 Jina Rerankers,並對分數取平均值。
| Reranker Model | Avg. Hit Rate | Avg. MRR |
|---|---|---|
| Jina Reranker models | ||
| jina-reranker-v1-base-en | 0.8439 | 0.7006 |
| jina-reranker-v1-turbo-en | 0.8351 | 0.6498 |
| jina-reranker-v1-tiny-en | 0.8316 | 0.6761 |
| Other reranking models | ||
mxbai-rerank-base-v1 |
0.8105 | 0.6583 |
mxbai-rerank-xsmall-v1 |
0.8193 | 0.6673 |
ms-marco-MiniLM-L-6-v2 |
0.8052 | 0.6121 |
bge-reranker-base |
0.8175 | 0.6480 |
ms-marco-MiniLM-L-4-v2 |
0.8246 | 0.6354 |
MRR:平均倒數排名
對於檢索增強生成(RAG)任務,結果質量的損失甚至比在 BEIR 純信息檢索基準測試中更小。當將 RAG 性能與處理速度進行比較時,我們發現只有 ms-marco-MiniLM-L-4-v2 提供了明顯更高的吞吐量,但這是以顯著降低結果質量為代價的。
tagAWS 上的成本節省
使用 Reranker Turbo 和 Reranker Tiny 可以為需要支付記憶體使用量和 CPU 時間費用的 AWS 和 Azure 用戶帶來巨大的節省。雖然不同使用案例的節省程度各有不同,但記憶體使用量大約減少 75% 就直接對應於在按記憶體收費的雲端系統中節省 75% 的費用。
此外,更快的吞吐量意味著您可以在更便宜的 AWS 實例上執行更多查詢。
tag開始使用
Jina Reranker 模型易於使用並整合到您的應用程式和工作流程中。要開始使用,您可以訪問 Reranker API 頁面,了解如何使用我們的服務並獲得 100 萬個免費令牌來試用。

我們的模型也在 AWS SageMaker 上提供。更多信息,請參見我們的在 AWS 中設置檢索增強生成系統的教程。

Jina Reranker 模型也可以從 Hugging Face 下載,使用 Apache 2.0 授權:




