



在 2023 年 10 月,我們推出了 jina-embeddings-v2,這是第一個能處理長達 8,192 個 tokens 輸入的開源嵌入模型系列。在此基礎上,我們今年發布了 jina-embeddings-v3,在保持相同的輸入長度支援下提供了更多增強功能。

在本文中,我們將深入探討長文本嵌入,並回答一些問題:將如此大量的文本整合到單個向量中何時是實用的?分段是否能改善檢索效果?如果能,要如何做?在分段文本時如何保留文檔不同部分的上下文?
為了回答這些問題,我們將比較幾種生成嵌入的方法:
- 長文本嵌入(編碼最多 8,192 個 tokens 的文檔)與短文本(即在 192 個 tokens 處截斷)。
- 不分塊與簡單分塊和後期分塊的比較。
- 在簡單分塊和後期分塊中使用不同的塊大小。
tag長文本處理真的有用嗎?
長文本嵌入模型能夠在單個嵌入中編碼長達十頁的文本,為大規模文本表示開啟了新的可能性。但這真的有用嗎?根據很多人的說法……並不。




來源:How AI Is Built 播客中 Nils Reimer 的引述、brainlag 的推文、egorfine 在 Hacker News 的評論、andy99 在 Hacker News 的評論
我們將透過深入研究長文本處理能力、長文本何時有用以及何時應該(或不應該)使用它來回應這些疑慮。但首先,讓我們聽聽這些懷疑者的意見,並看看長文本嵌入模型面臨的一些問題。
tag長文本嵌入的問題
假設我們正在為文章建立文件搜索系統,比如我們 Jina AI 部落格上的文章。有時一篇文章可能涵蓋多個主題,像是我們關於參加 ICML 2024 會議的報告,其中包含:
- 介紹部分,涵蓋有關 ICML 的一般資訊(參與人數、地點、範圍等)。
- 我們的工作展示(jina-clip-v1)。
- 在 ICML 上展示的其他有趣研究論文的摘要。
如果我們只為這篇文章創建一個嵌入,那麼這個嵌入就代表了三個不同主題的混合:
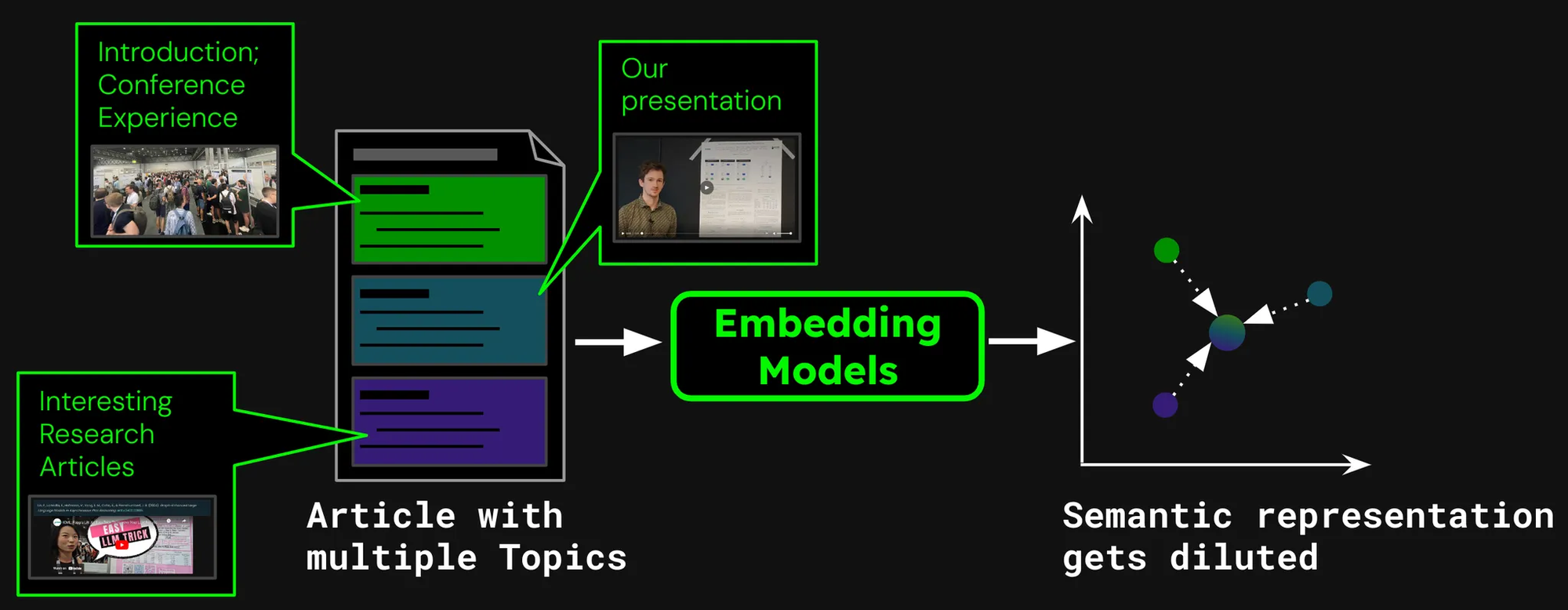
這會導致幾個問題:
- 表示稀釋:雖然文本中的所有主題可能都有關聯,但用戶的搜索查詢可能只與其中一個相關。然而,單個嵌入(在這種情況下,是整篇部落格文章的嵌入)在向量空間中只是一個點。隨著更多文本被加入模型的輸入中,嵌入會轉向捕捉文章的整體主題,使其在表示特定段落內容時效果降低。
- 容量限制:嵌入模型產生固定大小的向量,與輸入長度無關。隨著輸入內容的增加,模型在向量中表示所有這些資訊變得更加困難。這就像把一張圖片縮小到 16×16 像素 — 如果你縮小一個簡單物體的圖片,比如蘋果,你仍然可以從縮小的圖片中得到意義。但如果是縮小柏林的街道地圖?那就不行了。
- 資訊損失:在某些情況下,即使是長文本嵌入模型也會達到其極限;許多模型支援最多 8,192 個 tokens 的文本編碼。更長的文檔需要在嵌入前被截斷,導致資訊損失。如果與用戶相關的資訊位於文檔的末尾,它根本就不會被嵌入捕捉到。
- 你可能需要文本分段:某些應用需要文本特定段落的嵌入而不是整個文檔的嵌入,比如在文本中識別相關段落。
tag長文本與截斷的比較
為了看看長文本處理是否真的有價值,讓我們來看兩種檢索場景的表現:
- 編碼最多 8,192 個 tokens 的文檔(約 10 頁文本)。
- 在 192 個 tokens 處截斷文檔並進行編碼。
我們將使用以下方法來比較結果:使用 jina-embeddings-v3 的 nDCG@10 檢索指標。我們測試了以下數據集:
| 數據集 | 描述 | 查詢示例 | 文檔示例 | 平均文檔長度(字符) |
|---|---|---|---|---|
| NFCorpus | 一個全文醫療檢索數據集,包含 3,244 個查詢,文檔主要來自 PubMed。 | "使用飲食治療哮喘和濕疹" | "他汀類藥物使用與乳腺癌存活率:芬蘭全國隊列研究 最近的研究表明 [...]" | 326,753 |
| QMSum | 一個基於查詢的會議摘要數據集,需要對相關會議片段進行摘要。 | "是教授提出這個問題並建議使用知識工程技巧 [...]" | "項目經理:現在可以嗎?{語音聲音} 好的。抱歉?好的,大家都準備好開始會議了嗎?[...]" | 37,445 |
| NarrativeQA | 包含長篇故事及其相關特定內容問題的問答數據集。 | "Sophia 在巴黎擁有什麼樣的生意?" | "The Project Gutenberg EBook of The Old Wives' Tale, by Arnold Bennett\n\nThis eBook is for the use of anyone anywhere [...]" | 53,336 |
| 2WikiMultihopQA | 一個多跳問答數據集,最多需要 5 個推理步驟,使用模板設計以避免捷徑。 | "The Seeker(The Who 樂隊的歌曲)的作曲家獲得了什麼獎項?" | "段落 1:\nMargaret,布里恩伯爵夫人\nMarguerite d'Enghien(出生於 1365 年 - 逝世於 1394 年後),是統治者 suo jure [...]" | 30,854 |
| SummScreenFD | 一個需要整合分散劇情的電視劇劇本摘要數據集,包含電視劇劇本和摘要。 | "Penny 得到了一把新椅子,Sheldon 很喜歡直到他發現她是從 [...]" | "[外景。拉斯維加斯城市(庫存)- 夜晚]\n[外景。阿伯納西住宅 - 車道 -- 夜晚]\n(路燈柱上的燈 [...]" | 1,613 |
我們可以看到,編碼超過 192 個 token 可以帶來顯著的性能提升:
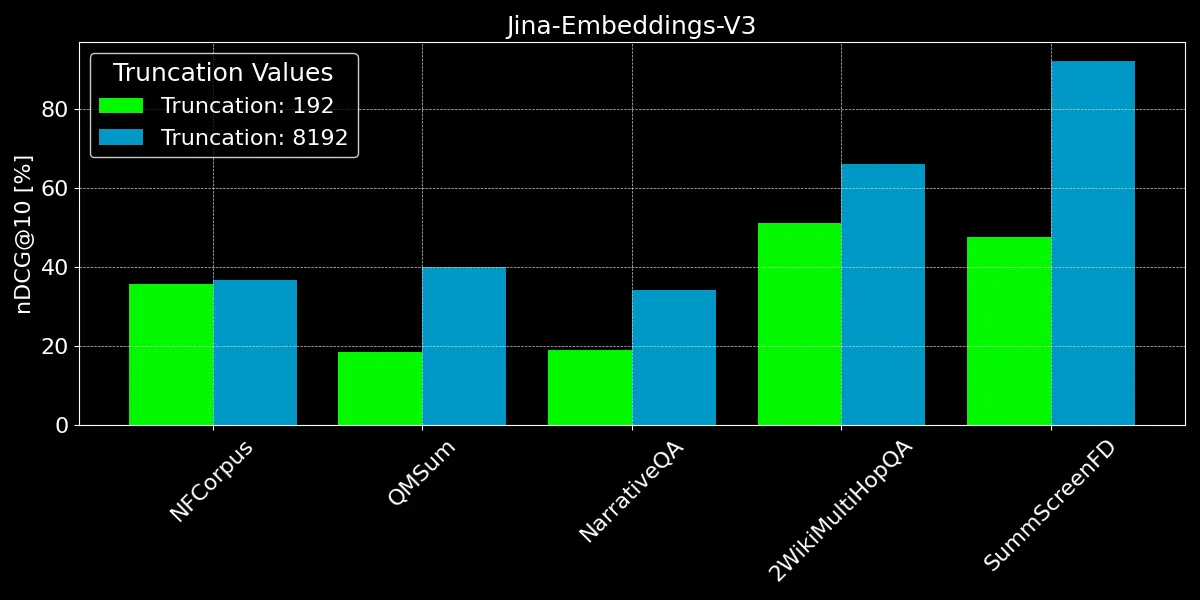
然而,在不同數據集上,我們看到的改進程度不一:
- 對於 NFCorpus,截斷幾乎沒有影響。這是因為標題和摘要都在文檔的開頭,而這些內容與典型的用戶搜索詞高度相關。無論是否截斷,最相關的資料都在 token 限制範圍內。
- QMSum 和 NarrativeQA 被視為"閱讀理解"任務,用戶通常在文本中搜索特定事實。這些事實經常分散在文檔的各個細節中,可能超出 192 token 的截斷限制。例如,在 NarrativeQA 文檔《Percival Keene》中,"誰是偷 Percival 午餐的惡霸?"這個問題的答案遠超出了這個限制。同樣,在 2WikiMultiHopQA 中,相關信息分散在整個文檔中,需要模型在多個章節中導航和綜合知識以有效回答查詢。
- SummScreenFD 是一個旨在識別與給定摘要相對應的劇本的任務。由於摘要包含了分散在整個劇本中的信息,編碼更多的文本可以提高摘要與正確劇本匹配的準確性。
tag分段文本以提升檢索性能
• 分段(Segmentation):在輸入文本中檢測邊界標記,例如句子或固定數量的 token。
• 簡單分塊(Naive chunking):在編碼之前根據分段標記將文本分成塊。
• 延遲分塊(Late chunking):先編碼文檔,然後再進行分段(保留塊之間的上下文)。
我們可以使用各種方法來首先對文檔進行分段,而不是將整個文檔嵌入到一個向量中:

一些常見的方法包括:
- 固定大小分段:文檔被分成固定數量 token 的片段,這個數量由嵌入模型的分詞器決定。這確保了片段的分詞與整個文檔的分詞相對應(按特定字符數分段可能導致不同的分詞結果)。
- 按句子分段:文檔被分成句子,每個塊由 n 個句子組成。
- 按語義分段:每個片段對應多個句子,嵌入模型決定連續句子的相似性。具有高嵌入相似性的句子被分配到同一個塊中。
為了簡單起見,我們在本文中使用固定大小分段。
tag使用簡單分塊進行文檔檢索
一旦我們執行了固定大小分段,我們可以根據這些片段對文檔進行簡單分塊:
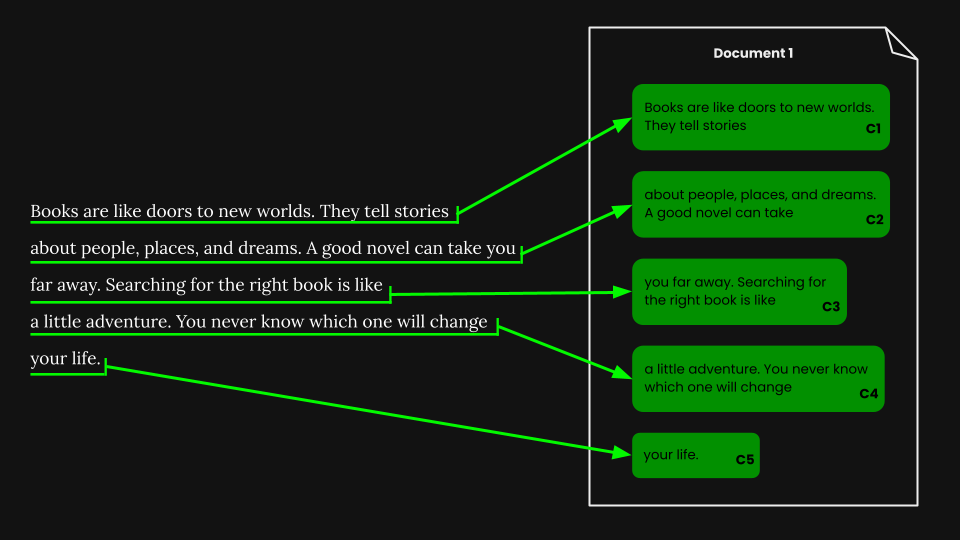
使用 jina-embeddings-v3,我們將每個塊編碼成準確捕捉其語義的嵌入向量,然後將這些嵌入存儲在向量數據庫中。
在運行時,模型將用戶的查詢編碼為查詢向量。我們將其與向量數據庫中的塊嵌入進行比較,以找到具有最高餘弦相似度的塊,然後將相應的文檔返回給用戶:
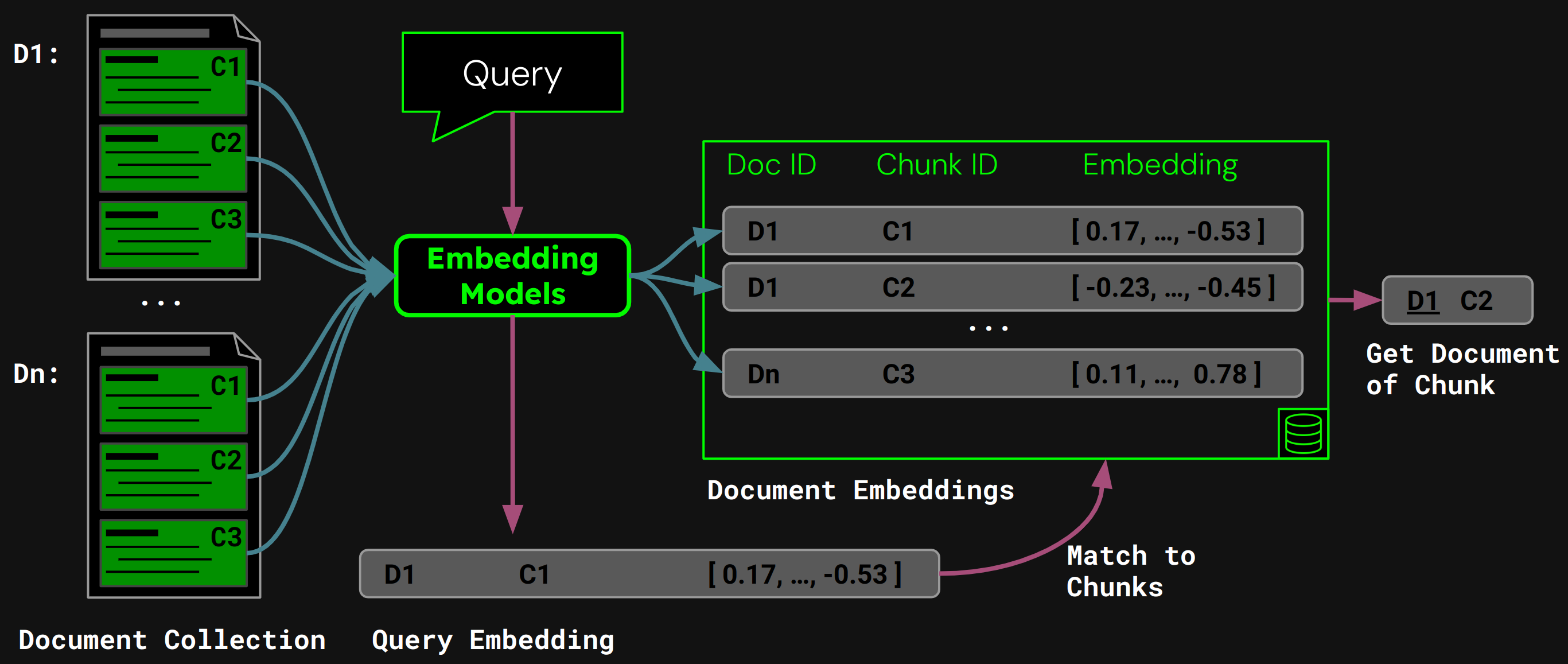
tag樸素分塊的問題

雖然樸素分塊解決了長上下文 embedding 模型的一些限制,但它也有其缺點:
- 無法看到全局:在文檔檢索中,小塊的多個 embeddings 可能無法捕捉文檔的整體主題。這就像只見樹木而不見森林。
- 缺失上下文問題:如圖 6 所示,由於缺少上下文信息,無法準確解釋這些塊。
- 效率:更多的塊需要更多的存儲空間,並增加檢索時間。
tag後期分塊解決了上下文問題
後期分塊分兩個主要步驟進行:
- 首先,它利用模型的長上下文能力將整個文檔編碼為 token embeddings。這保留了文檔的完整上下文。
- 然後,它通過對特定序列的 token embeddings 進行平均池化來創建塊 embeddings,這些序列對應於在分割過程中識別的邊界提示。
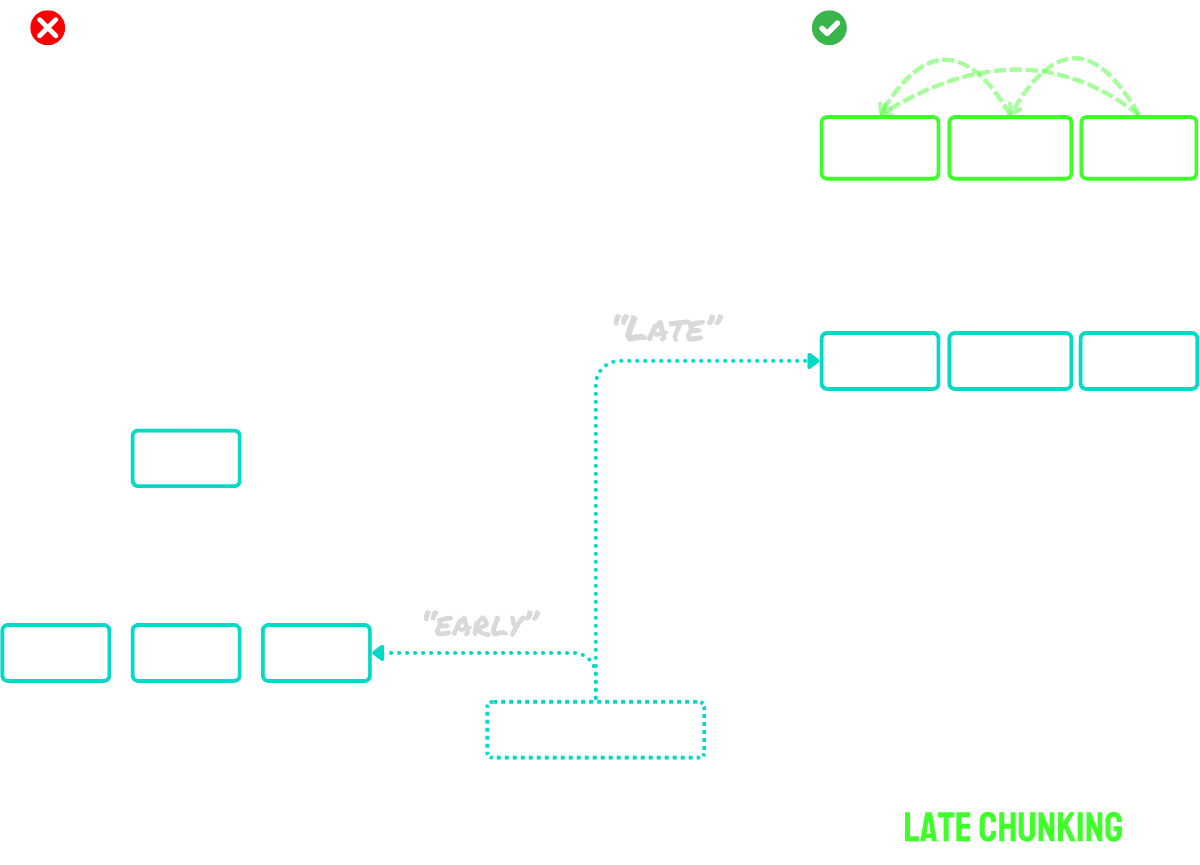
這種方法的主要優勢在於 token embeddings 是上下文化的 —— 意味著它們自然捕捉了與文檔其他部分的引用和關係。由於 embedding 過程發生在分塊之前,每個塊都保留了對更廣泛文檔上下文的認知,從而解決了困擾樸素分塊方法的上下文缺失問題。
對於超過模型最大輸入大小的文檔,我們可以使用「長後期分塊」:
- 首先,我們將文檔分解為重疊的「宏塊」。每個宏塊的大小都適合模型的最大上下文長度(例如,8,192 個 tokens)。
- 模型處理這些宏塊以創建 token embeddings。
- 一旦我們有了 token embeddings,我們就進行標準的後期分塊 —— 應用平均池化來創建最終的塊 embeddings。
這種方法允許我們處理任何長度的文檔,同時仍然保持後期分塊的優勢。可以將其視為兩階段過程:首先使文檔適合模型處理,然後應用常規的後期分塊程序。
簡而言之:
- 樸素分塊:將文檔分割成小塊,然後分別對每個塊進行編碼。
- 後期分塊:一次性對整個文檔進行編碼以創建 token embeddings,然後基於分段邊界通過池化 token embeddings 來創建塊 embeddings。
- 長後期分塊:將大型文檔分割成適合模型上下文窗口的重疊宏塊,對這些塊進行編碼以獲得 token embeddings,然後像正常一樣應用後期分塊。
如需該想法的更詳細描述,請查看我們的論文或上述提到的博客文章。
tag要分塊還是不分塊?
我們已經看到長上下文 embedding 通常優於較短文本 embeddings,並概述了樸素分塊和後期分塊策略。現在的問題是:分塊是否比長上下文 embedding 更好?
為了進行公平比較,我們在開始分割之前將文本值截斷到模型的最大序列長度(8,192 tokens)。我們使用固定大小的分割,每段 64 個 tokens(對於樸素分割和後期分塊都是如此)。讓我們比較三種情況:
- 不分割:我們將每個文本編碼成單個 embedding。這導致與之前的實驗(見圖 2)相同的分數,但我們在這裡包含它們以便更好地比較。
- 樸素分塊:我們對文本進行分割,然後根據邊界提示應用樸素分塊。
- 後期分塊:我們對文本進行分割,然後使用後期分塊來確定 embeddings。
對於後期分塊和樸素分割,我們使用塊檢索來確定相關文檔(如本文前面的圖 5 所示)。
結果顯示沒有明顯的贏家:
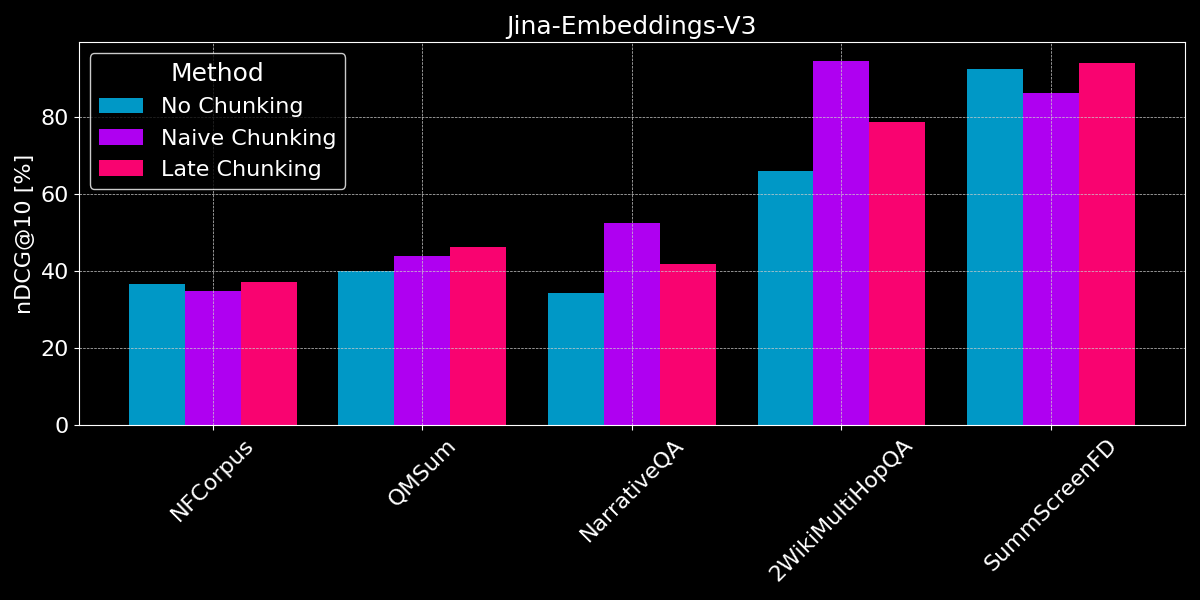
- 對於事實檢索,樸素分塊表現更好:對於 QMSum、NarrativeQA 和 2WikiMultiHopQA 數據集,模型必須識別文檔中的相關段落。在這裡,樸素分塊明顯優於將所有內容編碼為單個 embedding,因為可能只有少數塊包含相關信息,而這些塊比整個文檔的單個 embedding 能更好地捕捉這些信息。
- 後期分塊在連貫的文檔和相關上下文中效果最佳:對於涵蓋連貫主題且用戶搜索整體主題而非具體事實的文檔(如 NFCorpus),後期分塊略優於不分塊,因為它平衡了文檔範圍的上下文和局部細節。然而,雖然後期分塊通過保留上下文通常比簡單分塊效果更好,但當在包含大量無關信息的文檔中搜索孤立事實時,這種優勢可能成為負擔 - 正如在 NarrativeQA 和 2WikiMultiHopQA 的性能下降中所見,增加的上下文反而會造成更多干擾。
tag分塊大小是否有影響?
分塊方法的有效性實際上取決於數據集,這突顯了內容結構扮演著關鍵角色:
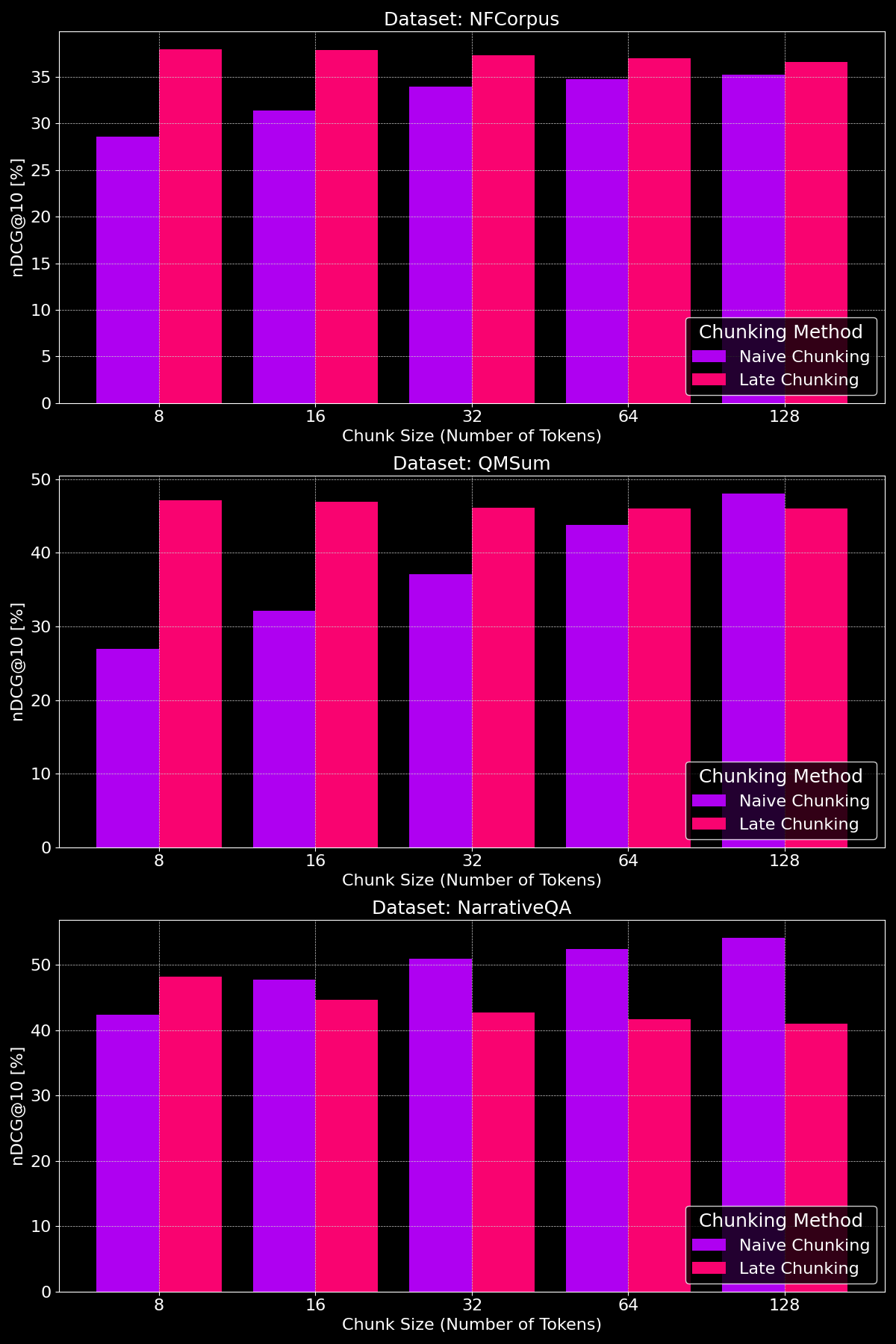
如我們所見,在較小的分塊大小下,後期分塊通常優於簡單分塊,因為較小的簡單分塊包含的上下文太少,而較小的後期分塊保留了整個文檔的上下文,使其在語義上更有意義。NarrativeQA 數據集是個例外,因為其中包含太多無關的上下文,導致後期分塊表現較差。在較大的分塊大小下,簡單分塊顯示出明顯的改善(有時甚至超過後期分塊),這是由於增加的上下文,而後期分塊的性能則逐漸下降。
tag要點:何時使用什麼?
在這篇文章中,我們研究了不同類型的文檔檢索任務,以更好地理解何時使用分段以及何時後期分塊有幫助。那麼,我們學到了什麼?
tag何時應該使用長上下文嵌入?
一般來說,在嵌入模型的輸入中包含盡可能多的文檔文本不會損害檢索準確性。然而,長上下文嵌入模型通常關注文檔的開頭,因為它們包含標題和介紹等對判斷相關性更重要的內容,但模型可能會錯過文檔中間的內容。
tag何時應該使用簡單分塊?
當文檔涵蓋多個方面,或用戶查詢針對文檔中的特定信息時,分塊通常可以提高檢索性能。
最終,分段決策取決於多個因素,如是否需要向用戶顯示部分文本(例如 Google 在搜索結果預覽中顯示相關段落),這使得分段變得必要,或者計算和內存的限制,在這種情況下,由於增加了檢索開銷和資源使用,分段可能較不利。
tag何時應該使用後期分塊?
透過在創建分塊之前對整個文檔進行編碼,後期分塊解決了文本段因缺少上下文而失去意義的問題。這在每個部分都與整體相關的連貫文檔中特別有效。我們的實驗表明,後期分塊在將文本分成較小的分塊時特別有效,正如我們的論文所示。然而,有一個注意事項:如果文檔的部分內容彼此無關,包含這個更廣泛的上下文實際上可能會使檢索性能變差,因為它為嵌入增加了噪音。
tag結論
在長上下文嵌入、簡單分塊和後期分塊之間的選擇取決於您的檢索任務的具體要求。長上下文嵌入對於具有一般查詢的連貫文檔很有價值,而分塊在用戶尋找文檔中的特定事實或信息的情況下表現出色。後期分塊通過在較小的段落中保留上下文連貫性進一步提升了檢索效果。最終,了解您的數據和檢索目標將指導最佳方法,在準確性、效率和上下文相關性之間取得平衡。
如果您正在探索這些策略,可以考慮嘗試 jina-embeddings-v3 —— 其先進的長上下文功能、後期分塊和靈活性使其成為多樣化檢索場景的絕佳選擇。

