


最近,LAION AI 的創始人 Christoph Schuhmann 分享了一個關於文本嵌入模型的有趣觀察:
當句子中的詞語被隨機打亂時,它們的文本嵌入之間的餘弦相似度與原句相比仍然保持驚人的高度。
例如,讓我們看兩個句子:Berlin is the capital of Germany 和 the Germany Berlin is capital of。儘管第二個句子毫無意義,但文本嵌入模型卻無法真正區分它們。使用 jina-embeddings-v3,這兩個句子的餘弦相似度得分為 0.9295。
詞序並非嵌入模型不太敏感的唯一問題。語法轉換可能會極大地改變句子的含義,但對嵌入距離的影響卻很小。例如,She ate dinner before watching the movie 和 She watched the movie before eating dinner 的餘弦相似度為 0.9833,儘管它們的動作順序完全相反。
如果沒有特殊訓練,否定詞的一致性嵌入也是出了名的困難 —— This is a useful model 和 This is not a useful model 在嵌入空間中看起來幾乎完全相同。通常,將文本中的詞替換為相同類別的其他詞,比如將"today"改為"yesterday",或改變動詞時態,對嵌入的改變也沒有你想象的那麼大。
這帶來了嚴重的影響。考慮兩個搜索查詢:Flight from Berlin to Amsterdam 和 Flight from Amsterdam to Berlin。它們的嵌入幾乎完全相同,jina-embeddings-v3 給它們的餘弦相似度為 0.9884。對於旅遊搜索或物流這樣的實際應用來說,這個缺陷是致命的。
在本文中,我們探討嵌入模型面臨的挑戰,研究它們在詞序和詞語選擇方面持續存在的問題。我們分析了跨語言類別的關鍵失效模式——包括方向、時間、因果、比較和否定上下文——同時探索提高模型性能的策略。
tag為什麼打亂的句子會有驚人的相近餘弦分數?
起初,我們認為這可能是由於模型組合詞義的方式——它為每個詞創建一個嵌入(在我們上面的示例句子中有 6-7 個詞),然後通過平均池化將這些嵌入平均在一起。這意味著最終的嵌入幾乎沒有詞序信息。不管值的順序如何,平均值都是相同的。
然而,即使使用 CLS 池化的模型(通過觀察特殊的第一個詞來理解整個句子,應該對詞序更敏感)也存在相同的問題。例如,bge-1.5-base-en 對句子 Berlin is the capital of Germany 和 the Germany Berlin is capital of 仍然給出 0.9304 的餘弦相似度分數。
這指出了嵌入模型訓練方式的一個局限性。雖然語言模型在預訓練期間最初學習句子結構,但在對比訓練——我們用來創建嵌入模型的過程中,似乎失去了一些這種理解。
tag文本長度和詞序如何影響嵌入相似度?
為什麼模型在處理詞序時會遇到困難?首先想到的是文本的長度(以 token 為單位)。當文本被送入編碼函數時,模型首先生成一個 token 嵌入列表(即,每個分詞後的詞都有一個專門的向量來表示其含義),然後對它們進行平均。
為了了解文本長度和詞序如何影響嵌入相似度,我們生成了一個包含 180 個不同長度合成句子的數據集,分別包含 3、5、10、15、20 和 30 個 token。我們還隨機打亂了 token 以形成每個句子的變體:

以下是一些例子:
| 長度 (tokens) | 原始句子 | 打亂後的句子 |
|---|---|---|
| 3 | The cat sleeps | cat The sleeps |
| 5 | He drives his car carefully | drives car his carefully He |
| 15 | The talented musicians performed beautiful classical music at the grand concert hall yesterday | in talented now grand classical yesterday The performed musicians at hall concert the music |
| 30 | The passionate group of educational experts collaboratively designed and implemented innovative teaching methodologies to improve learning outcomes in diverse classroom environments worldwide | group teaching through implemented collaboratively outcomes of methodologies across worldwide diverse with passionate and in experts educational classroom for environments now by learning to at improve from innovative The designed |
我們將使用我們自己的 jina-embeddings-v3 模型和開源模型 bge-base-en-v1.5 對數據集進行編碼,然後計算原始句子和打亂句子之間的餘弦相似度:
| 長度 (tokens) | 平均餘弦相似度 | 餘弦相似度標準差 |
|---|---|---|
| 3 | 0.947 | 0.053 |
| 5 | 0.909 | 0.052 |
| 10 | 0.924 | 0.031 |
| 15 | 0.918 | 0.019 |
| 20 | 0.899 | 0.021 |
| 30 | 0.874 | 0.025 |
現在我們可以生成一個箱形圖,這使得餘弦相似度的趨勢更加清晰:
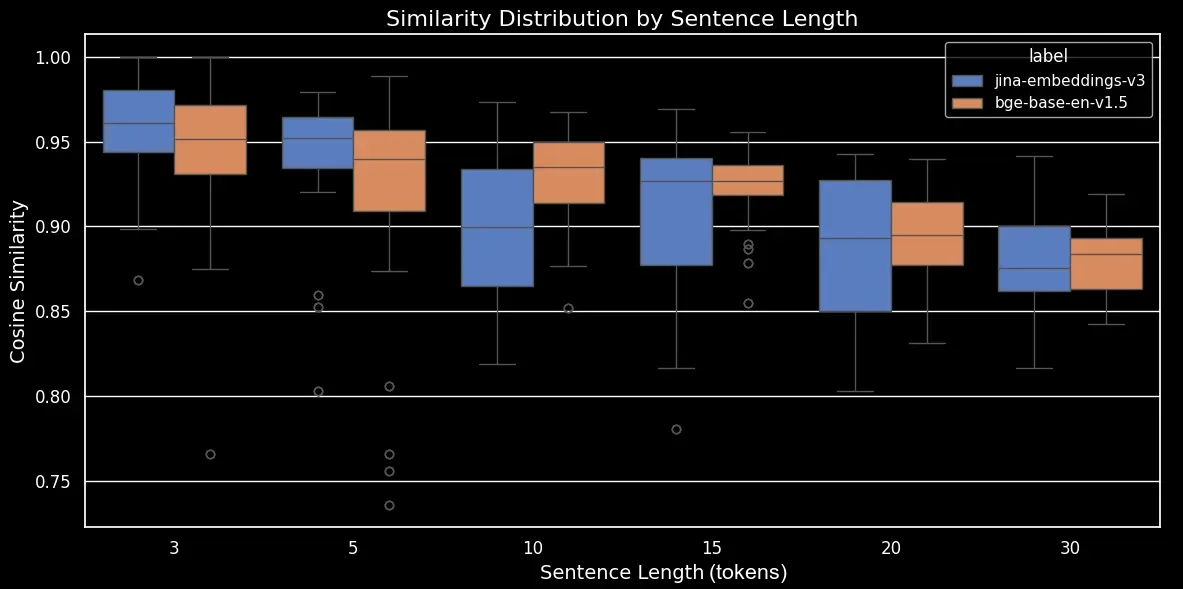
bge-base-en-1.5(未經微調)的打亂句子按句子長度的相似度分布如我們所見,嵌入的平均餘弦相似度存在明顯的線性關係。文本越長,原始句子和隨機打亂句子之間的平均餘弦相似度得分越低。這可能是由於"詞語位移"造成的,也就是詞在隨機打亂後離開其原始位置的距離。在較短的文本中,token 可以被打亂到的"位置"較少,所以不能移動太遠,而較長的文本有更多潛在的排列組合,詞可以移動更大的距離。
如下圖所示(餘弦相似度 vs. 平均字詞位移),文本越長,字詞位移就越大:
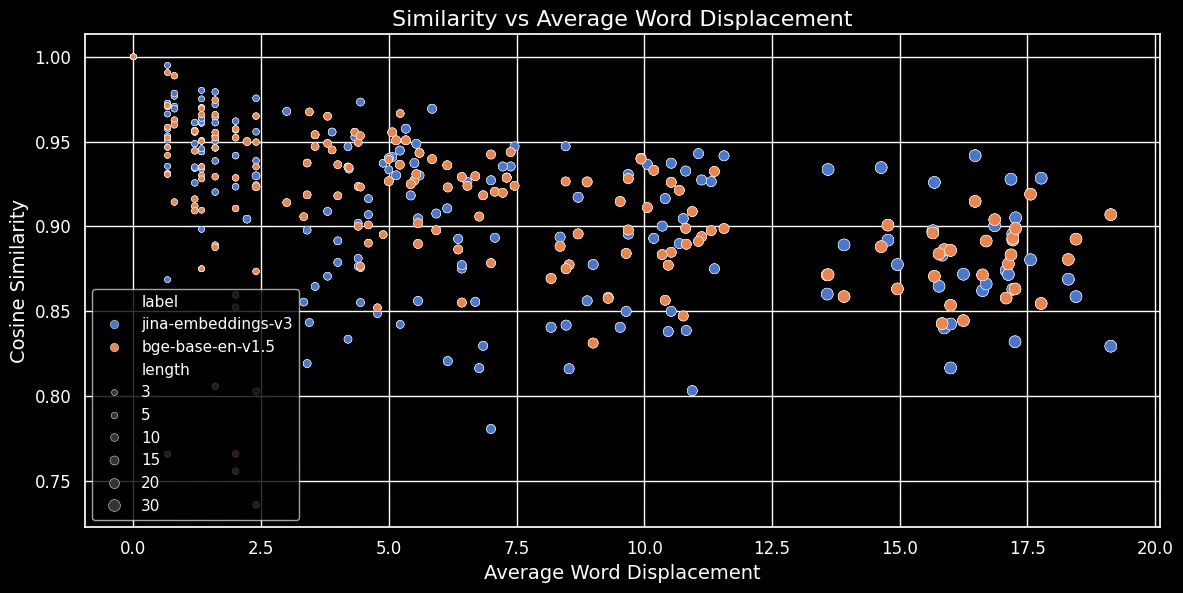
字詞嵌入取決於局部上下文,也就是最靠近它們的字詞。在短文本中,重新排列字詞不會大幅改變該上下文。然而,對於較長的文本,一個字詞可能會被移動到離其原始上下文很遠的地方,這可能會大幅改變其字詞嵌入。因此,打亂較長文本中的字詞會產生比較短文本更遠的嵌入距離。上圖顯示,無論是使用平均池化的 jina-embeddings-v3,還是使用 CLS 池化的 bge-base-en-v1.5,都呈現相同的關係:打亂較長的文本並使字詞位移更遠會導致較小的相似度分數。
tag更大的模型能解決問題嗎?
通常,當我們面臨這類問題時,一個常見的策略是直接使用更大的模型。但更大的文本嵌入模型真的能更有效地捕捉字詞順序資訊嗎?根據文本嵌入模型的擴展定律(在我們的 jina-embeddings-v3 發布文章中提到),更大的模型通常會提供更好的性能:
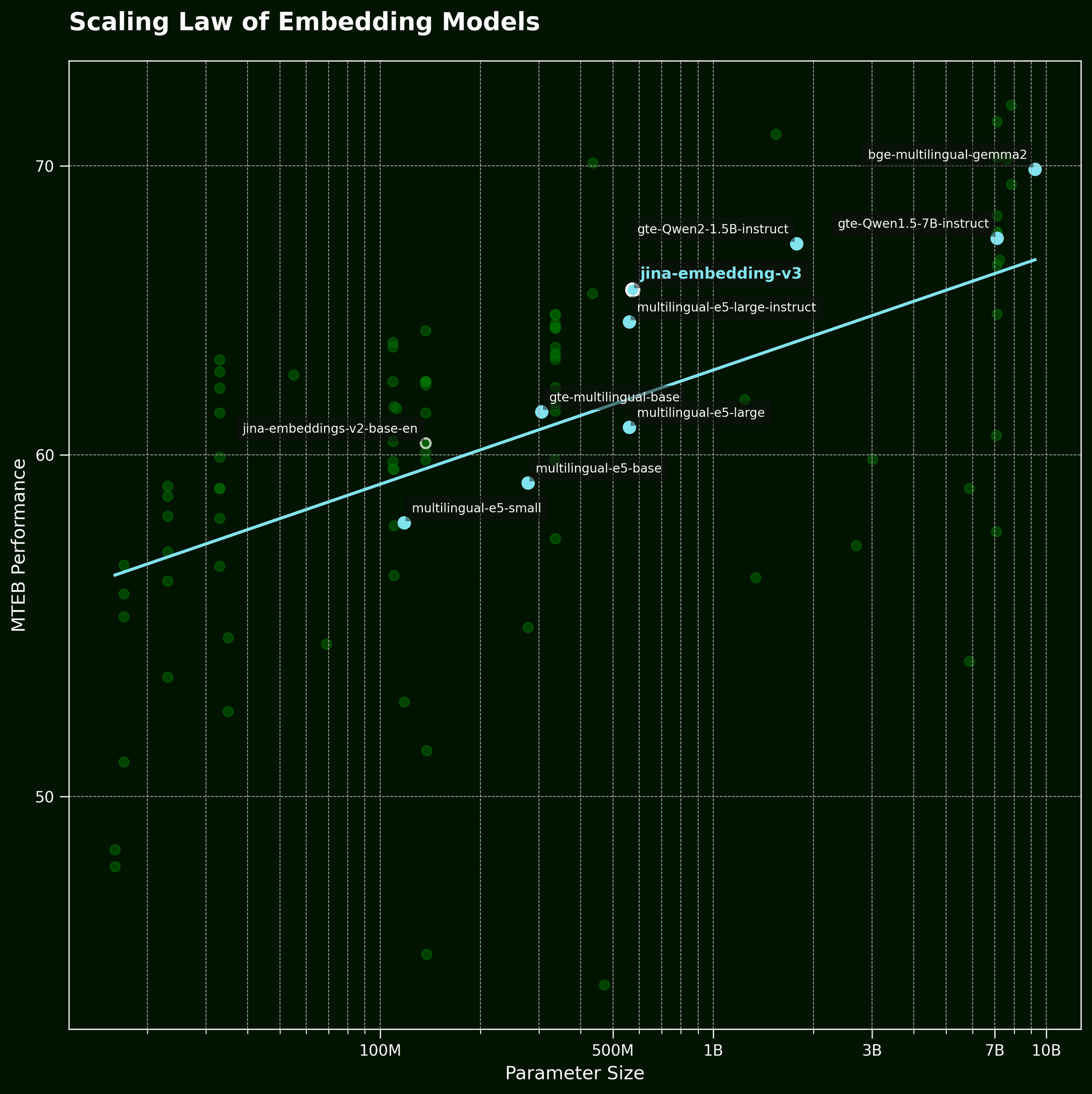
但更大的模型真的能更有效地捕捉字詞順序資訊嗎?我們測試了 BGE 模型的三個變體:bge-small-en-v1.5、bge-base-en-v1.5 和 bge-large-en-v1.5,參數規模分別為 3300 萬、1.1 億和 3.35 億。
我們將使用與之前相同的 180 個句子,但不考慮長度資訊。我們將使用這三個模型變體對原始句子及其隨機打亂的版本進行編碼,並繪製平均餘弦相似度:
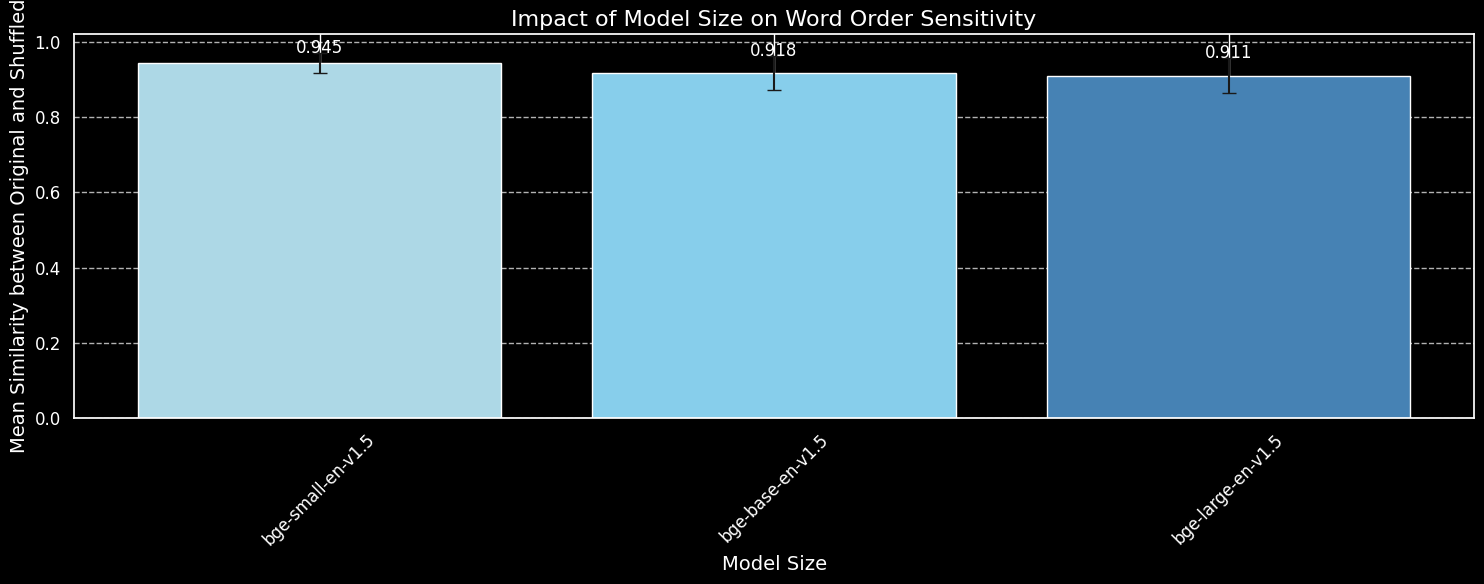
bge-small-en-v1.5、bge-base-en-v1.5 和 bge-large-en-v1.5。雖然我們可以看到較大的模型對字詞順序變化更敏感,但差異很小。即使是規模大得多的 bge-large-en-v1.5 在區分打亂和未打亂的句子時,最多也只是略微好一點。在決定嵌入模型對字詞重新排序的敏感度時,其他因素也會發揮作用,特別是訓練方案的差異。此外,餘弦相似度是衡量模型區分能力的一個非常有限的工具。然而,我們可以看到模型規模並不是主要考慮因素。我們不能簡單地讓模型變得更大來解決這個問題。
tag現實世界中的字詞順序和字詞選擇
jina-embeddings-v2(不是 我們最新的模型 jina-embeddings-v3),因為 v2 小得多,因此在我們的本地 GPU 上實驗時速度更快,參數量為 1.37 億,相比 v3 的 5.8 億。如我們在導言中提到的,字詞順序並不是嵌入模型唯一面臨的挑戰。更現實的實際挑戰是關於字詞選擇。有許多方式可以改變句子中的字詞——這些方式在嵌入中並沒有得到很好的反映。我們可以把「She flew from Paris to Tokyo」改成「She drove from Tokyo to Paris」,而嵌入仍然保持相似。我們已經將這些變化分類如下:
| 類別 | 範例 - 左 | 範例 - 右 | 餘弦相似度(jina) |
|---|---|---|---|
| 方向性 | She flew from Paris to Tokyo | She drove from Tokyo to Paris | 0.9439 |
| 時間性 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 |
| 因果性 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 |
| 比較性 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 |
| 否定 | He is standing by the table | He is standing far from the table | 0.9116 |
上表顯示了一些「失敗案例」,其中文本嵌入模型無法捕捉細微的詞序變化。這符合我們的預期:文本嵌入模型缺乏推理能力。例如,模型並不理解 "from" 和 "to" 之間的關係。文本嵌入模型執行語意匹配,語意通常在 token 層級捕捉,然後在池化後被壓縮成單一的密集向量。相比之下,在萬億 token 規模的大型數據集上訓練的 LLM(自回歸模型)開始展示出推理的突現能力。
這讓我們思考,我們能否通過對比學習使用三元組來微調嵌入模型,使查詢和正例更接近,同時推開查詢和負例?

例如,"Flight from Amsterdam to Berlin" 可以被視為 "Flight from Berlin to Amsterdam" 的負例對。事實上,在 jina-embeddings-v1 技術報告(Michael Guenther 等人)中,我們已經小規模地解決了這個問題:我們在一個由大型語言模型生成的否定數據集(包含 10,000 個示例)上微調了 jina-embeddings-v1 模型。

報告中的結果很有希望:
我們觀察到,在所有模型大小中,在三元組數據(包括我們的否定訓練數據集)上進行微調都顯著提升了性能,特別是在 HardNegation 任務上。
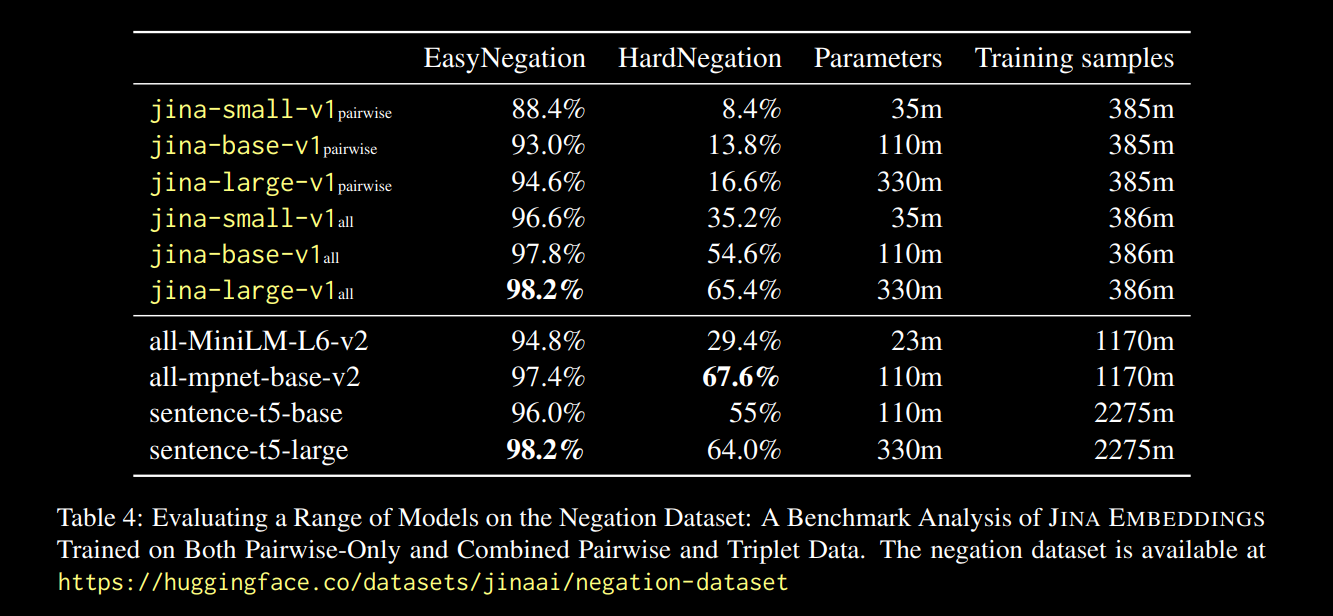
jina-embeddings 模型在成對訓練和組合三元組/成對訓練下的 EasyNegation 和 HardNegation 分數。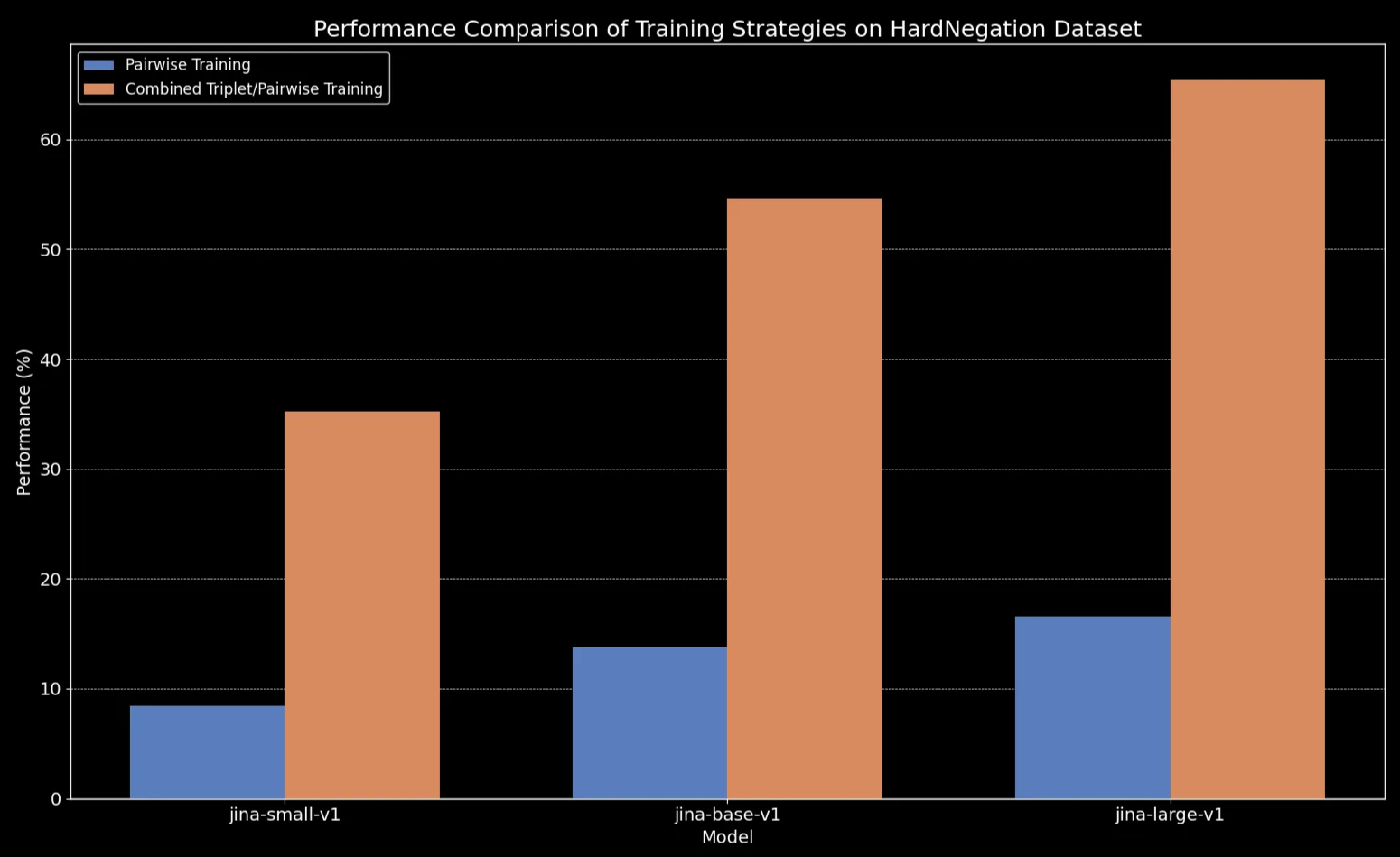
jina-embeddings 訓練策略的性能比較。tag使用精選數據集微調文本嵌入模型
在前面的部分中,我們探討了關於文本嵌入的幾個關鍵觀察:
- 較短的文本更容易在捕捉詞序方面出錯。
- 增加文本嵌入模型的大小並不一定能改善詞序理解。
- 對比學習可能為這些問題提供潛在的解決方案。
基於這些認識,我們在我們的否定和詞序數據集(總共約 11,000 個訓練樣本)上微調了 jina-embeddings-v2-base-en 和 bge-base-en-1.5:


為了幫助評估微調效果,我們生成了一個包含 1,000 個三元組的數據集,每個三元組包含一個 query、positive (pos) 和 negative (neg) 案例:

這是一個示例行:
| Anchor | The river flows from the mountains to the sea |
| Positive | Water travels from mountain peaks to ocean |
| Negative | The river flows from the sea to the mountains |
這些三元組旨在覆蓋各種失敗案例,包括由於詞序變化導致的方向性、時間性和因果性意義轉變。
我們現在可以在三個不同的評估集上評估模型:
- 180 個合成句子的集合(來自本文早前部分),隨機打亂。
- 5 個手動檢查的例子(來自上面的方向性/因果性等表格)。
- 94 個來自我們剛剛生成的三元組數據集的精選三元組。
以下是微調前後對打亂句子的差異:
| 句子長度(tokens) | 平均餘弦相似度(jina) |
平均餘弦相似度(jina-ft) |
平均餘弦相似度(bge) |
平均餘弦相似度(bge-ft) |
|---|---|---|---|---|
| 3 | 0.970 | 0.927 | 0.929 | 0.899 |
| 5 | 0.958 | 0.910 | 0.940 | 0.916 |
| 10 | 0.953 | 0.890 | 0.934 | 0.910 |
| 15 | 0.930 | 0.830 | 0.912 | 0.875 |
| 20 | 0.916 | 0.815 | 0.901 | 0.879 |
| 30 | 0.927 | 0.819 | 0.877 | 0.852 |
結果很明顯:儘管微調過程只花了五分鐘,我們在隨機打亂的句子數據集上看到了顯著的性能改善:
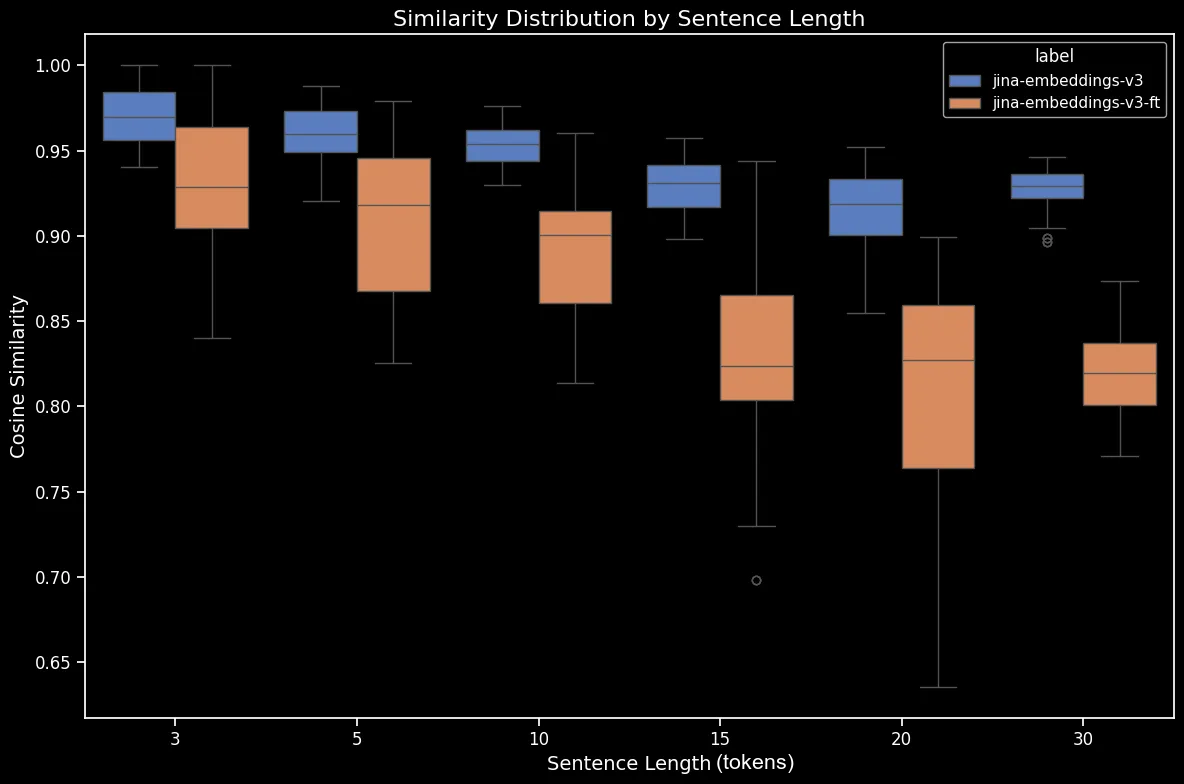
bge-base-en-1.5(已微調)在打亂句子上的相似度分布。我們在方向、時間、因果和比較案例上也看到了改善。模型表現出明顯的性能提升,這反映在平均餘弦相似度的下降上。最大的性能提升出現在否定案例上,這是因為我們的微調數據集包含了 10,000 個否定訓練範例。
| 類別 | 範例 - 左 | 範例 - 右 | 平均餘弦相似度 (jina) |
平均餘弦相似度 (jina-ft) |
平均餘弦相似度 (bge) |
平均餘弦相似度 (bge-ft) |
|---|---|---|---|---|---|---|
| 方向 | She flew from Paris to Tokyo. | She drove from Tokyo to Paris | 0.9439 | 0.8650 | 0.9319 | 0.8674 |
| 時間 | She ate dinner before watching the movie | She watched the movie before eating dinner | 0.9833 | 0.9263 | 0.9683 | 0.9331 |
| 因果 | The rising temperature melted the snow | The melting snow cooled the temperature | 0.8998 | 0.7937 | 0.8874 | 0.8371 |
| 比較 | Coffee tastes better than tea | Tea tastes better than coffee | 0.9457 | 0.8759 | 0.9723 | 0.9030 |
| 否定 | He is standing by the table | He is standing far from the table | 0.9116 | 0.4478 | 0.8329 | 0.4329 |
tag結論
在這篇文章中,我們深入探討了文本嵌入模型面臨的挑戰,特別是它們在有效處理詞序方面的困難。總的來說,我們識別出了五種主要的失敗類型:方向、時間、因果、比較和否定。在這些查詢中,詞序非常重要,如果您的使用場景涉及其中任何一種,了解這些模型的局限性是很有價值的。
我們還進行了一個快速實驗,將以否定為重點的數據集擴展到覆蓋所有五種失敗類別。結果令人鼓舞:通過精心選擇的「硬性否例」進行微調,使模型更好地識別哪些項目應該組合在一起,哪些不應該。話雖如此,還有更多工作要做。未來的步驟包括深入研究數據集的大小和質量如何影響性能。





