


在實驗 ColPali 風格的模型時,我們的一位工程師使用最近發布的 jina-clip-v2 模型創建了一個視覺化呈現。他映射了給定圖文對之間的 token embeddings 和 patch embeddings 的相似度,創建了熱力圖覆蓋層,產生了一些有趣的視覺洞察。

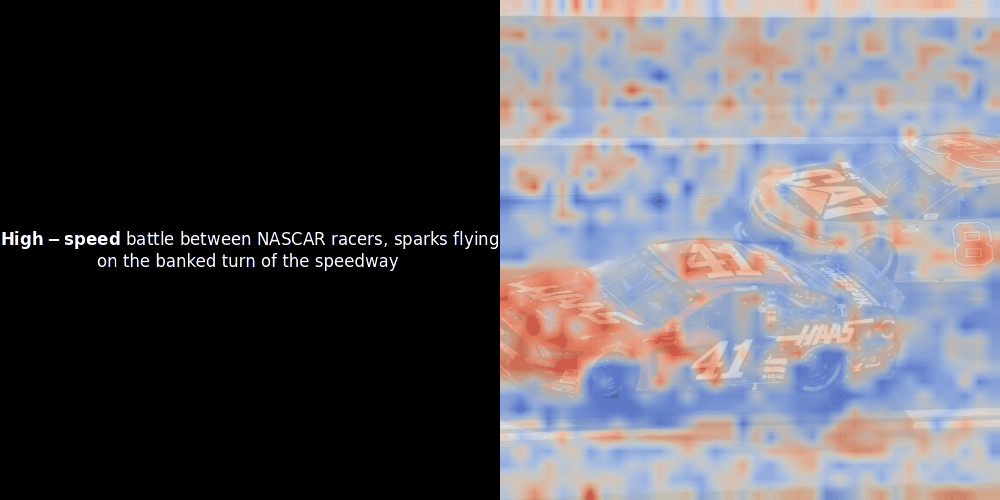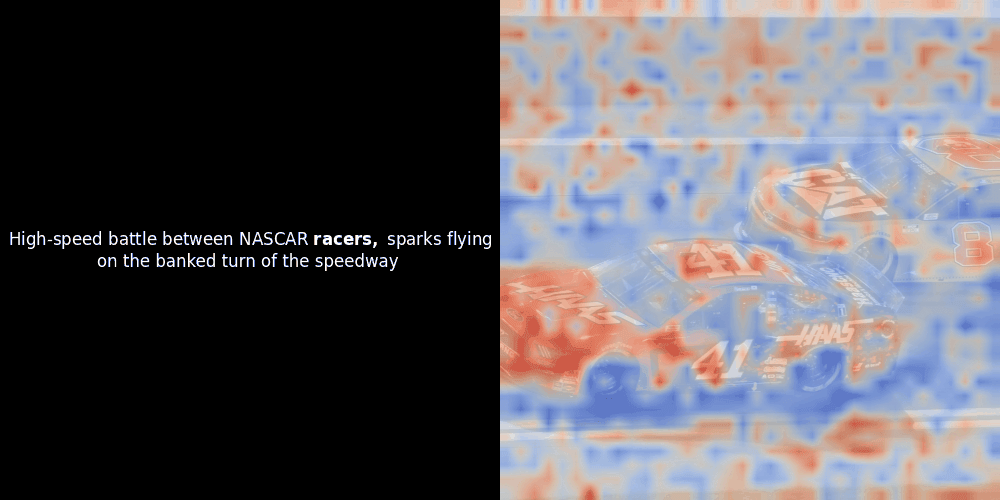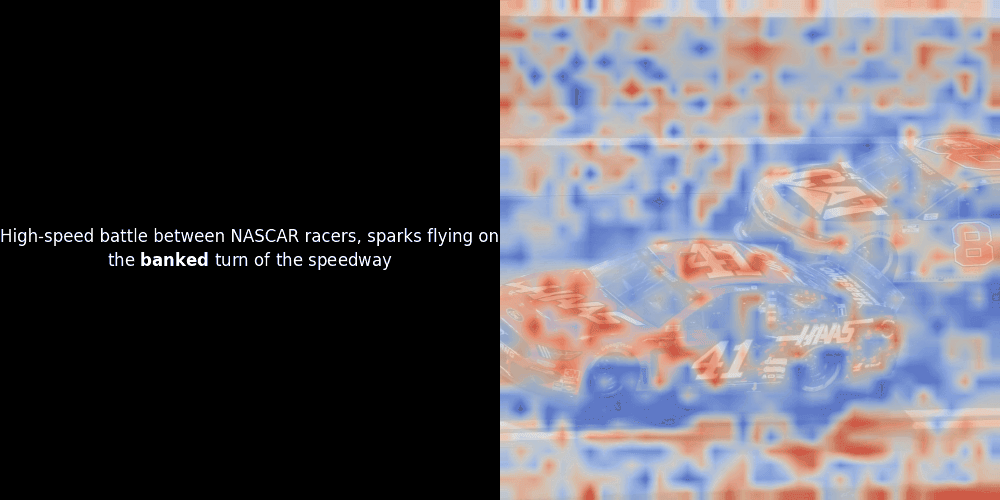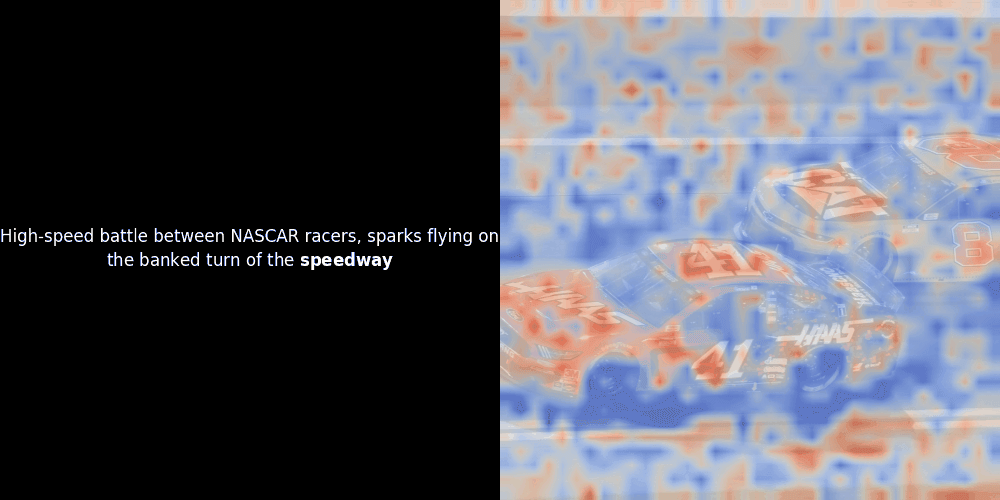
不幸的是,這只是一個啟發式的視覺化——而不是一個明確或有保證的機制。雖然 CLIP 類型的全局對比對齊可能(而且經常會)偶然在 patches 和 tokens 之間創建粗略的局部對齊,但這是一個意外的副作用,而不是模型的刻意目標。讓我解釋原因。
tag理解程式碼

讓我們從高層次來分解程式碼的功能。注意,jina-clip-v2 實際上並沒有提供任何預設的 API 來訪問 token 層級或 patch 層級的 embeddings——這個視覺化需要一些事後修補才能工作。
計算詞級別 embeddings
通過設置 model.text_model.output_tokens = True,調用 text_model(x=...,)[1] 將返回一個 (batch_size, seq_len, embed_dim) 的第二個元素作為 token embeddings。它接收一個輸入句子,用 Jina CLIP tokenizer 進行分詞,然後通過平均對應的 token embeddings 將子詞 tokens 重新組合成"詞"。它通過檢查 token 字串是否以 _ 字符開頭(在基於 SentencePiece 的 tokenizer 中很典型)來檢測新詞的開始。它產生一個詞級別 embeddings 列表和一個詞列表(所以"Dog"是一個 embedding,"and"是一個 embedding 等)。
計算 patch 級別 embeddings
對於圖像塔,vision_model(..., return_all_features=True) 將返回 (batch_size, n_patches+1, embed_dim),其中第一個 token 是 [CLS] token。從中,程式碼提取每個 patch 的 embeddings(即視覺 transformer 的 patch tokens)。然後將這些 patch embeddings 重塑成一個 2D 網格,patch_side × patch_side,接著上採樣以匹配原始圖像解析度。
視覺化詞-patch 相似度
相似度計算和後續的熱力圖生成是標準的"事後"可解釋性技術:選擇一個文本 embedding,計算與每個 patch embedding 的餘弦相似度,然後生成一個熱力圖,顯示哪些 patches 與該特定 token embedding 具有最高相似度。最後,它循環遍歷句子中的每個 token,在左側以粗體突出顯示該 token,並在右側的原始圖像上覆蓋基於相似度的熱力圖。所有幀被編譯成一個動態 GIF。
tag這是有意義的可解釋性嗎?
從純程式碼的角度來看,是的,邏輯是連貫的,並且會為每個 token 產生一個熱力圖。你會得到一系列顯示 patch 相似度的幀,所以腳本"做到了它所說的事情"。
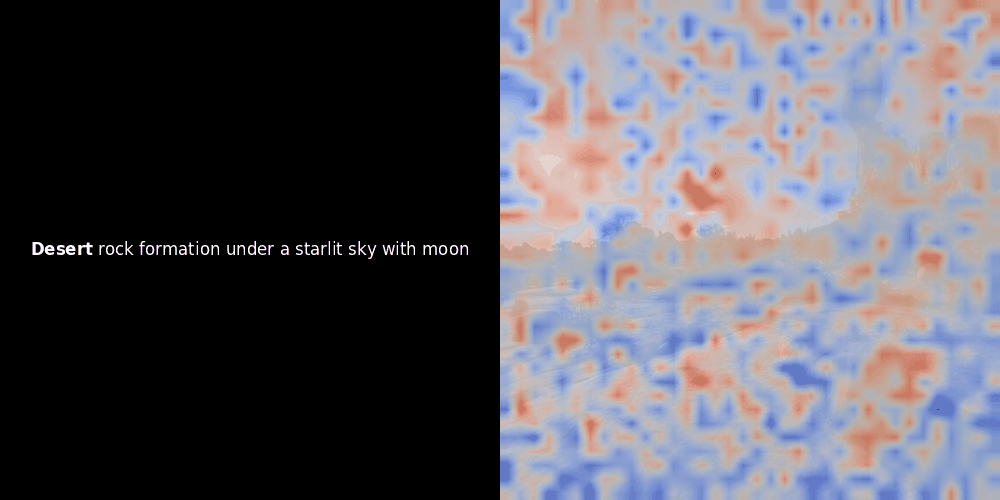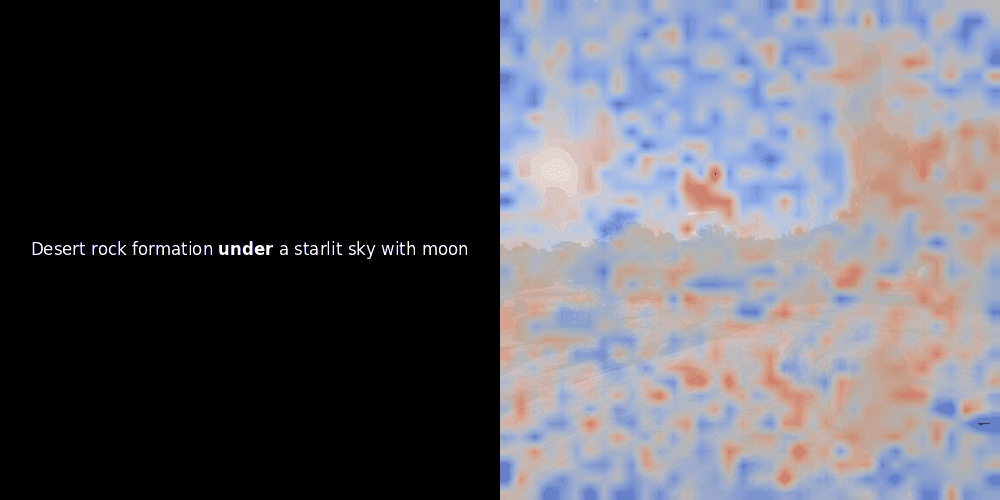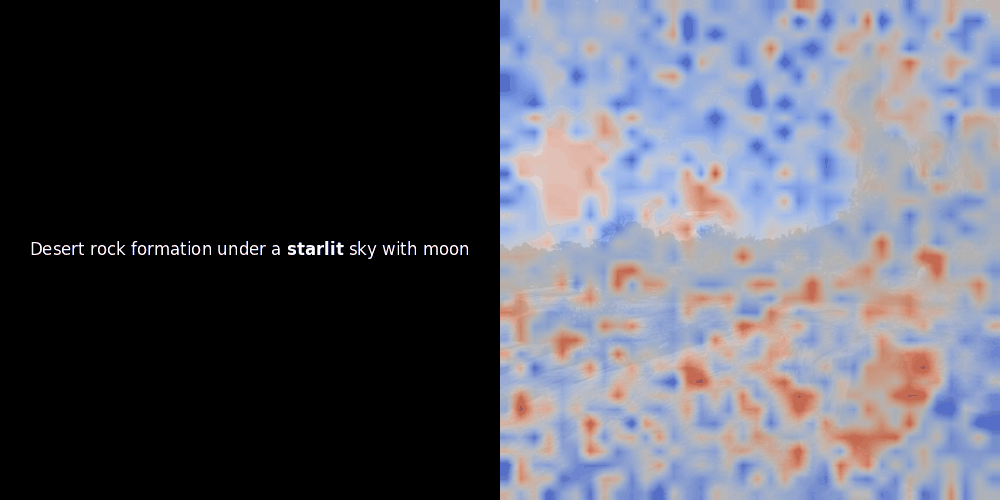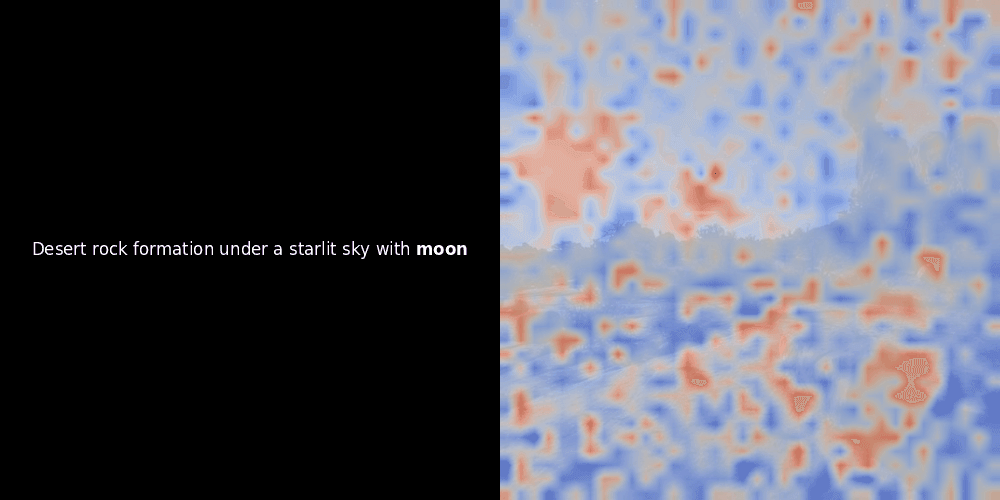

看上面的例子,我們可以看到像 moon 和 branches 這樣的詞似乎與原始圖像中相應的視覺 patches 良好對齊。但這裡的關鍵問題是:這是有意義的對齊,還是我們只是看到一個幸運的巧合?
這是一個更深層的問題。要理解這些注意事項,讓我們回顧一下 CLIP 是如何訓練的:

- CLIP 使用全局對比對齊來處理整個圖像和整個文本。在訓練過程中,圖像編碼器產生一個單一向量(池化表示),文本編碼器產生另一個單一向量;CLIP 被訓練使得這些向量在匹配的文本圖像對中相匹配,在其他情況下不匹配。
- 在"patch X 對應於 token Y"層面上沒有明確的監督。模型並未直接被訓練來突出顯示"圖像的這個區域是狗,那個區域是貓"等。相反,它被教導整個圖像表示應該與整個文本表示相匹配。
- 因為 CLIP 的架構在圖像端是 Vision Transformer,在文本端是文本 transformer——兩者形成獨立的編碼器——所以沒有原生地將 patches 與 tokens 對齊的交叉注意力模組。相反,你在每個塔中只得到純自注意力,再加上最終的全局圖像或文本 embeddings 投影。
簡而言之,這是一個啟發式的視覺化。任何給定的 patch embedding 可能與特定的 token embedding 接近或遠離,這有點是自然形成的。這更像是一個事後可解釋性技巧,而不是模型的穩健或官方的"注意力"。
tag為什麼可能會出現局部對齊?
那麼,為什麼我們有時會發現詞-patch 層級的局部對齊?事情是這樣的:儘管 CLIP 是在全局圖像-文本對比目標上訓練的,它仍然使用自注意力(在基於 ViT 的圖像編碼器中)和 transformer 層(用於文本)。在這些自注意力層中,圖像表示的不同部分可以相互作用,就像文本表示中的詞一樣。通過在大規模圖像-文本數據集上的訓練,模型自然會發展出內部潛在結構,幫助它將整體圖像與其相應的文本描述匹配。

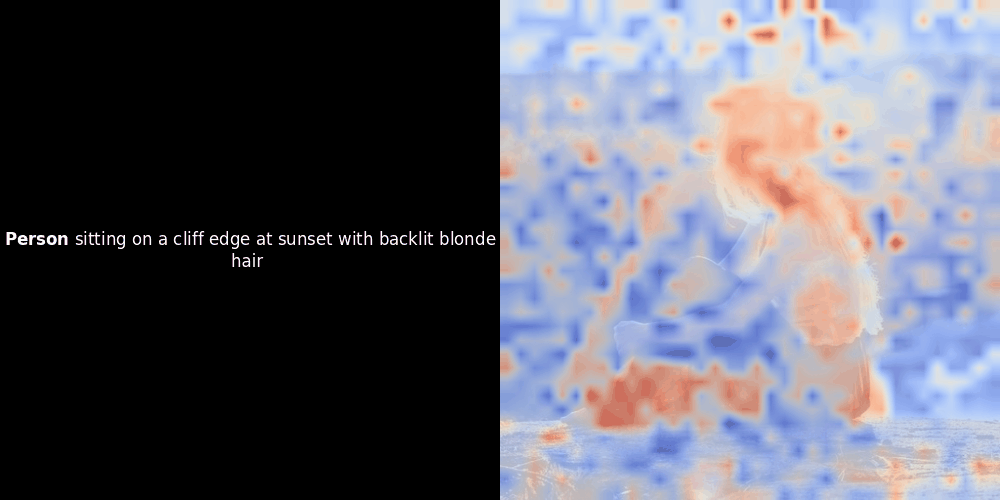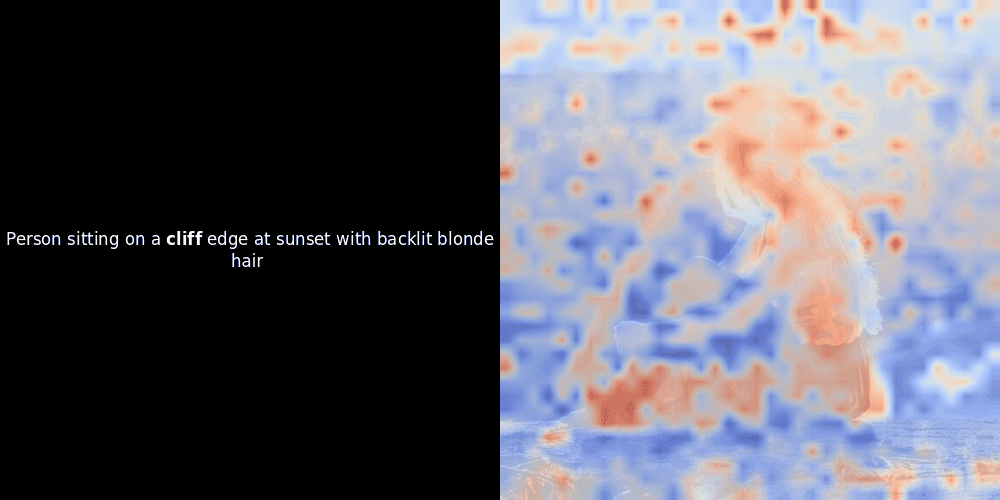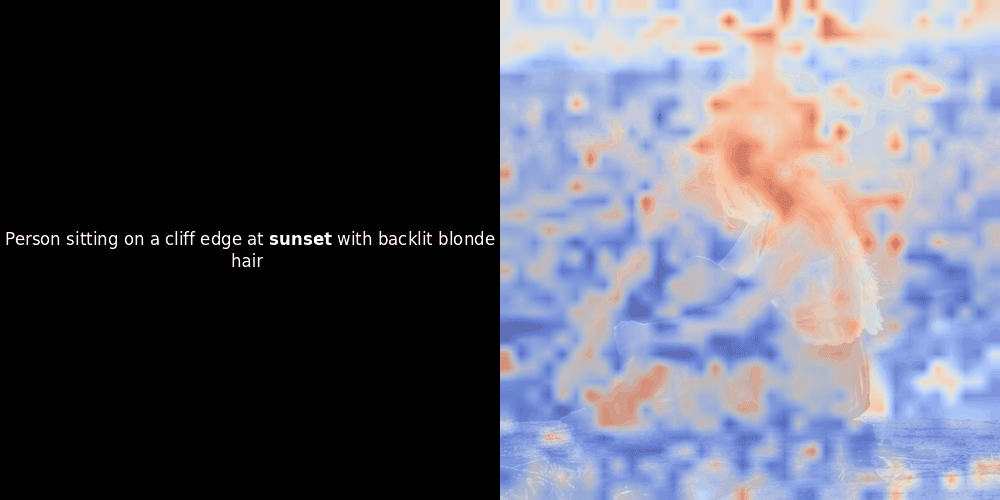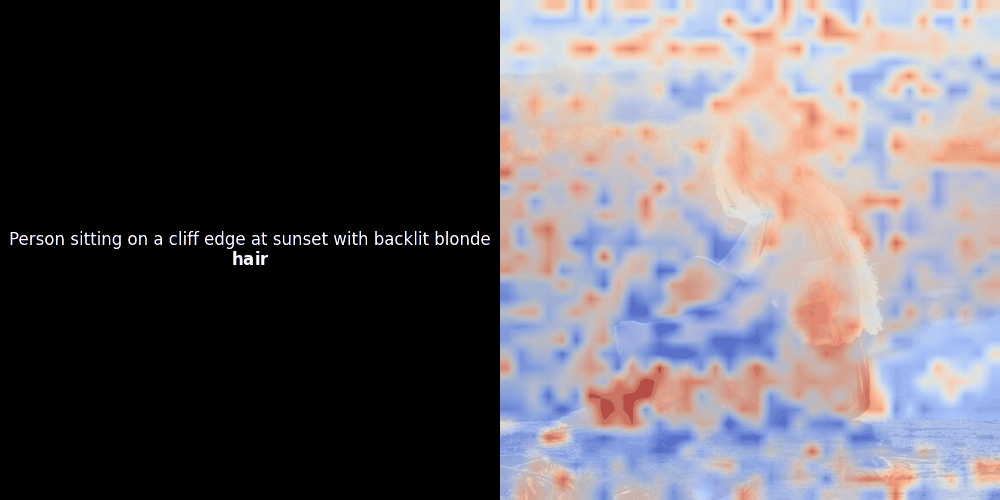
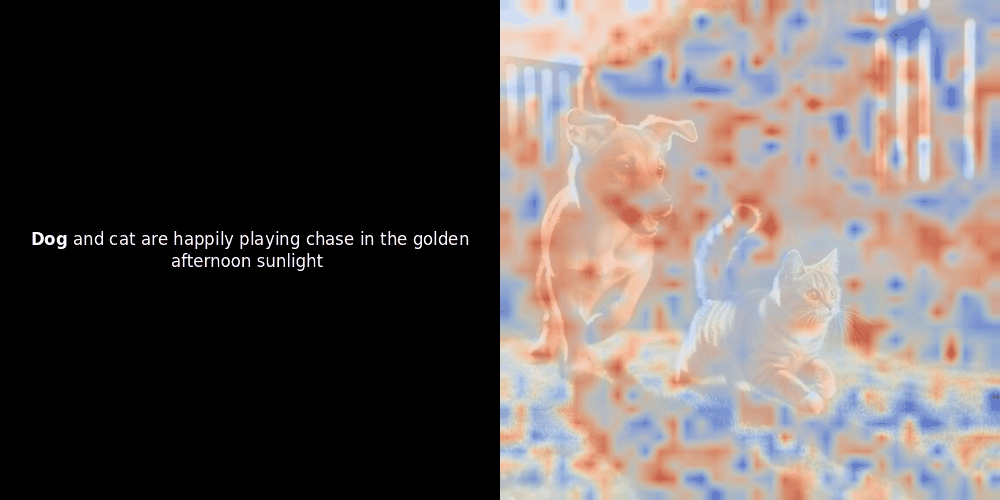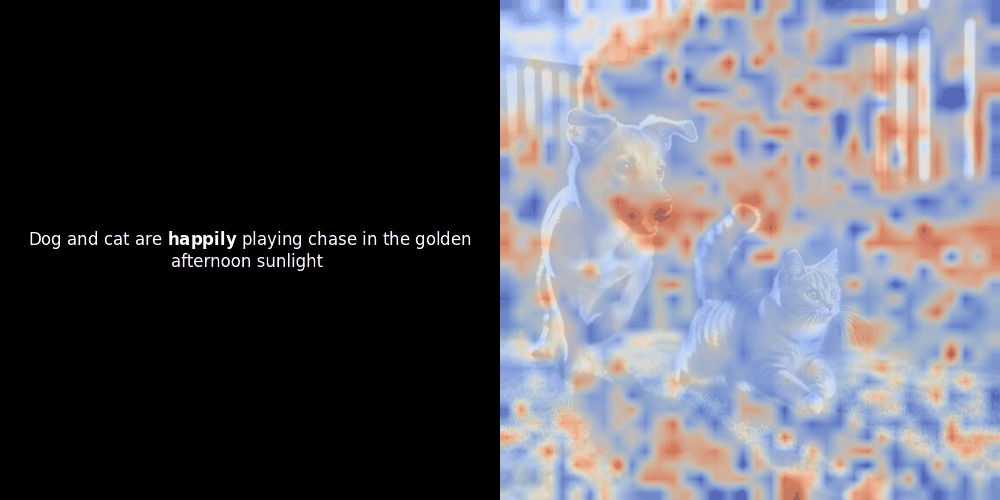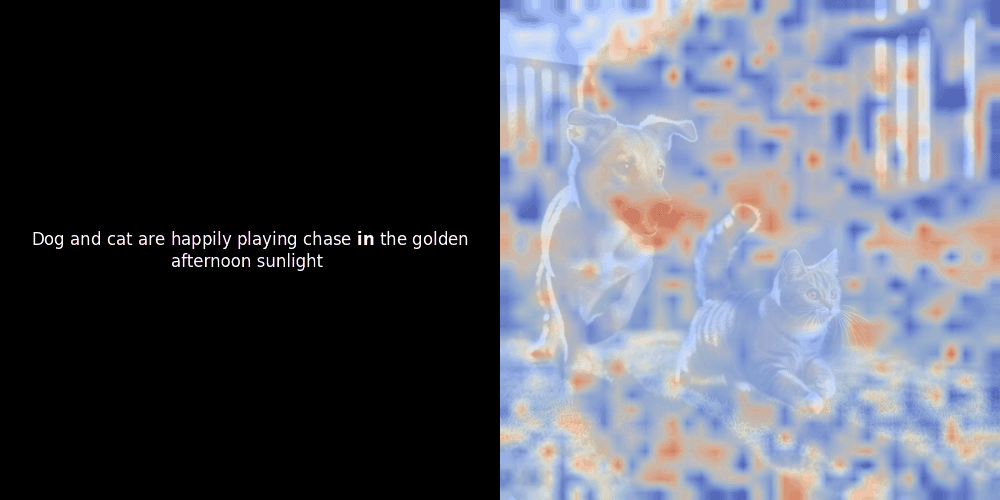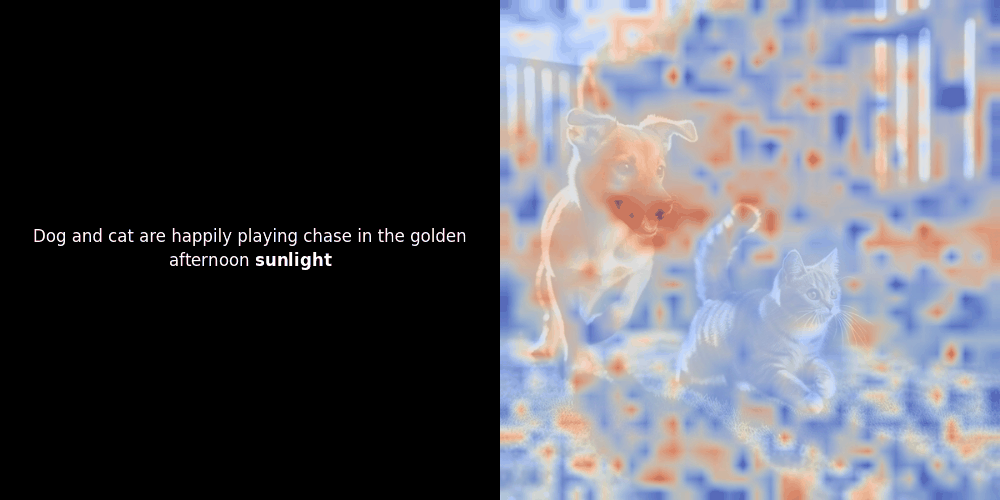
局部對齊可能在這些潛在表示中出現,至少有兩個原因:
- 共現模式:如果模型看到許多"狗"的圖像旁邊有許多"貓"的圖像(通常用這些詞標記或描述),它可以學習大致對應於這些概念的潛在特徵。因此,"狗"的 embedding 可能會接近於描繪狗形狀或紋理的局部 patches。這在 patch 層面上並非明確監督,而是從狗圖像/文本對的重複關聯中自然產生的。
- 自注意力:在 Vision Transformer 中,各個圖像塊之間會相互關注。顯著的圖像塊(如狗的臉部)可能會形成一個一致的潛在「特徵」,因為模型試圖為整個場景產生一個全局準確的表示。如果這有助於最小化整體對比損失,這種特徵就會被強化。
tag理論分析
CLIP 的對比學習目標是要最大化匹配的圖文對之間的餘弦相似度,同時最小化不匹配對之間的相似度。假設文本和圖像編碼器分別生成 token 和圖像塊嵌入:
全局相似度可以表示為局部相似度的聚合:
當特定的 token-patch 對在訓練數據中經常共同出現時,模型通過累積梯度更新來強化它們之間的相似度:
,其中 是共同出現的次數。這導致 顯著增加,促進了這些配對的更強局部對齊。然而,對比損失會在所有 token-patch 對之間分配梯度更新,限制了特定配對更新的強度:
這防止了個別 token-patch 相似度的顯著強化。
tag結論
CLIP 的 token-patch 視覺化利用了文本和圖像表示之間偶然的、自發的對齊。這種對齊雖然很有趣,但源於 CLIP 的全局對比訓練,缺乏精確且可靠的可解釋性所需的結構穩健性。產生的視覺化結果經常表現出噪聲和不一致性,限制了其在深入解釋應用中的實用性。

像 ColBERT 和 ColPali 這樣的後期交互模型通過在架構上嵌入明確的、細粒度的對齊來解決文本 token 和圖像塊之間的這些限制。通過獨立處理模態並在後期階段執行有針對性的相似度計算,這些模型確保每個文本 token 都能與相關的圖像區域產生有意義的關聯。
