


語義嵌入是現代 AI 模型的核心,包括聊天機器人和 AI 藝術模型。雖然它們有時對使用者是隱藏的,但它們仍然存在,就藏在表面之下。
嵌入理論只有兩個部分:
- 事物—AI 模型之外的事物,如文本和圖像—是由 AI 模型根據這些事物的數據創建的向量來表示。
- AI 模型之外事物之間的關係是由那些向量之間的空間關係來表示的。我們特別訓練 AI 模型來創建以這種方式工作的向量。
當我們製作圖像-文本多模態模型時,我們訓練模型使圖片的嵌入和描述或與這些圖片相關的文本的嵌入相對接近。這兩個向量所代表的事物—圖像和文本—之間的語義相似性反映在兩個向量之間的空間關係中。
例如,我們可以合理地預期,一個橙子的圖像的嵌入向量與文本「一個新鮮的橙子」的距離會比該圖像與文本「一個新鮮的蘋果」的距離更近。
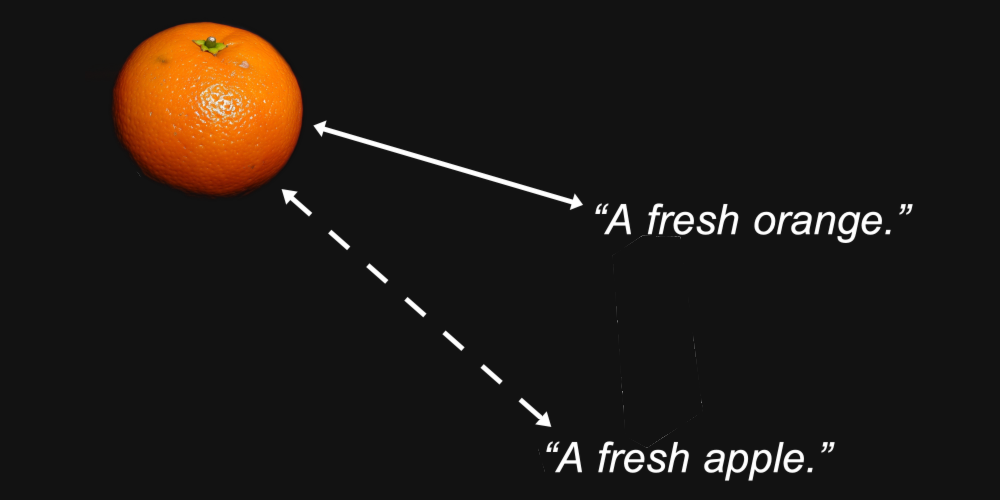
這就是嵌入模型的目的:生成讓我們關心的特徵—如圖像中描繪的或文本中命名的水果類型—被保留在它們之間的距離中的表示。
但多模態性引入了其他問題。我們可能發現,一張橙子的圖片與一張蘋果的圖片的距離,比它與文本「一個新鮮的橙子」的距離更近,而文本「一個新鮮的蘋果」與另一個文本的距離,比它與蘋果圖像的距離更近。
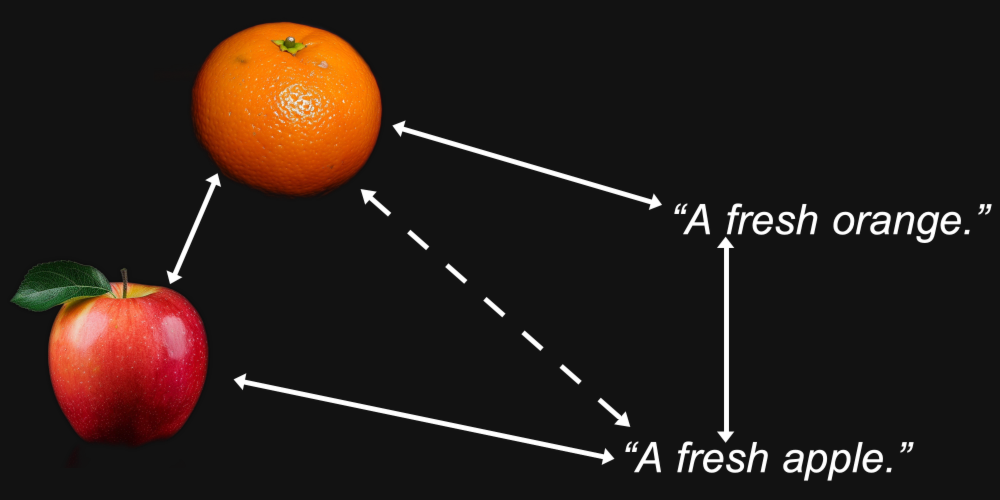
事實證明,這正是多模態模型所發生的情況,包括 Jina AI 自己的 Jina CLIP 模型(jina-clip-v1)。
為了測試這一點,我們從 Flickr8k 測試集中抽樣了 1,000 個文本-圖像對。每對包含五個標題文本(所以嚴格來說不是一對)和一個單獨的圖像,所有五個文本都在描述同一張圖像。
例如,以下圖像(Flickr8k 數據集中的 1245022983_fb329886dd.jpg):

它的五個標題:
A child in all pink is posing nearby a stroller with buildings in the distance.
A little girl in pink dances with her hands on her hips.
A small girl wearing pink dances on the sidewalk.
The girl in a bright pink skirt dances near a stroller.
The little girl in pink has her hands on her hips.
我們使用 Jina CLIP 嵌入圖像和文本,然後:
- 比較圖像嵌入與其標題文本嵌入之間的餘弦相似度。
- 取描述同一圖像的所有五個標題文本的嵌入,比較它們之間的餘弦相似度。
結果顯示出一個驚人的大差距,如圖 1 所示:
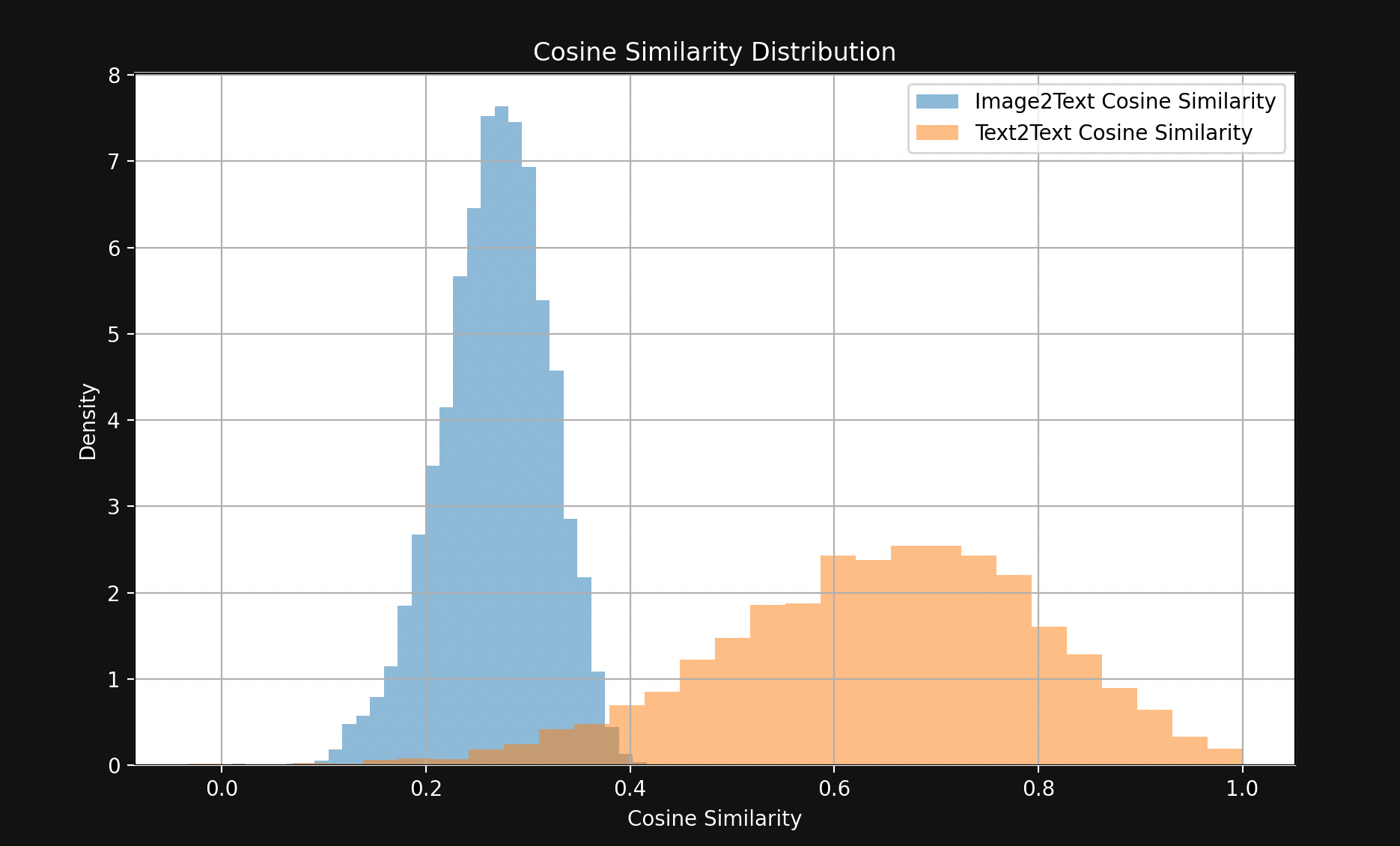
除了少數例外,匹配的文本對之間的距離比匹配的圖像-文本對更近。這強烈表明 Jina CLIP 在嵌入空間的一個部分編碼文本,而在另一個相對較遠的部分編碼圖像。文本和圖片之間的這個空間就是「多模態差距」。

多模態嵌入模型不僅編碼我們關心的語義信息:它們還編碼了輸入的媒體形式。根據 Jina CLIP,一張圖片並不如俗話說的值千言萬語。它擁有任何數量的文字都無法真正等同的內容。它將輸入的媒體形式編碼到其嵌入的語義中,而這並非任何人有意訓練它這樣做。
這種現象已在論文《Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning》[Liang et al., 2022]中進行了研究,該論文將其稱為「模態差距」。模態差距是指在嵌入空間中,一種媒體形式的輸入與另一種媒體形式的輸入之間的空間分離。雖然模型並非有意被訓練出這樣的差距,但這種差距在多模態模型中普遍存在。
我們對 Jina CLIP 中模態差距的研究很大程度上基於 Liang et al. [2022]。
tag模態差距從何而來?
Liang et al. [2022] 確定了模態差距背後的三個主要來源:
- 他們稱之為「錐形效應」的初始化偏差。
- 訓練過程中溫度(隨機性)的降低使得「取消學習」這種偏差變得非常困難。
- 在多模態模型中廣泛使用的對比學習程序,無意中強化了這種差距。
我們將依次看看每一個。
tag錐形效應
一個使用 CLIP 或 CLIP 風格架構建立的模型實際上是兩個獨立的 embedding 模型連結在一起。對於圖像-文本多模態模型來說,這意味著一個模型用於編碼文本,另一個完全獨立的模型用於編碼圖像,如下圖所示。
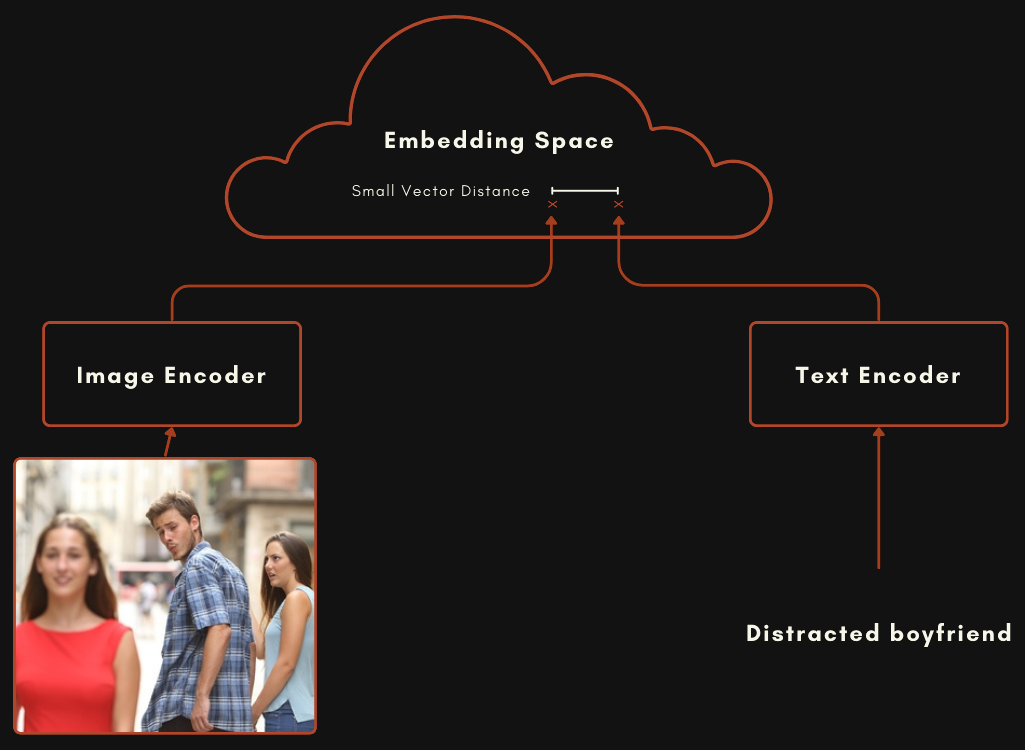
這兩個模型經過訓練,當文本能很好地描述圖像時,圖像 embedding 和文本 embedding 會相對接近。
你可以通過在兩個模型中隨機初始化權重,然後同時向其輸入圖像和文本對來訓練這樣的模型,從頭開始訓練以最小化兩個輸出之間的距離。原始的 OpenAI CLIP 模型就是以這種方式訓練的。然而,這需要大量的圖像-文本對和大量的計算資源。對於第一個 CLIP 模型,OpenAI 從互聯網上的帶標題材料中抓取了 4 億個圖像-文本對。
較新的 CLIP 風格模型使用預訓練組件。這意味著分別訓練每個組件作為一個良好的單模態 embedding 模型,一個用於文本,一個用於圖像。然後使用圖像-文本對對這兩個模型進行進一步的聯合訓練,這個過程稱為對比調優。使用對齊的圖像-文本對來慢慢"推動"權重,使匹配的文本和圖像 embedding 更接近,而不匹配的更遠離。
這種方法通常需要較少的圖像-文本對數據(這種數據難以獲得且成本高),而需要大量的無標題純文本和圖像,這些數據更容易獲得。Jina CLIP(jina-clip-v1)就是使用這種後者方法訓練的。我們使用一般文本數據預訓練了一個 JinaBERT v2 模型用於文本編碼,並使用預訓練的 EVA-02 圖像編碼器,然後使用各種對比訓練技術進行進一步訓練,如 Koukounas et al. [2024] 中所述
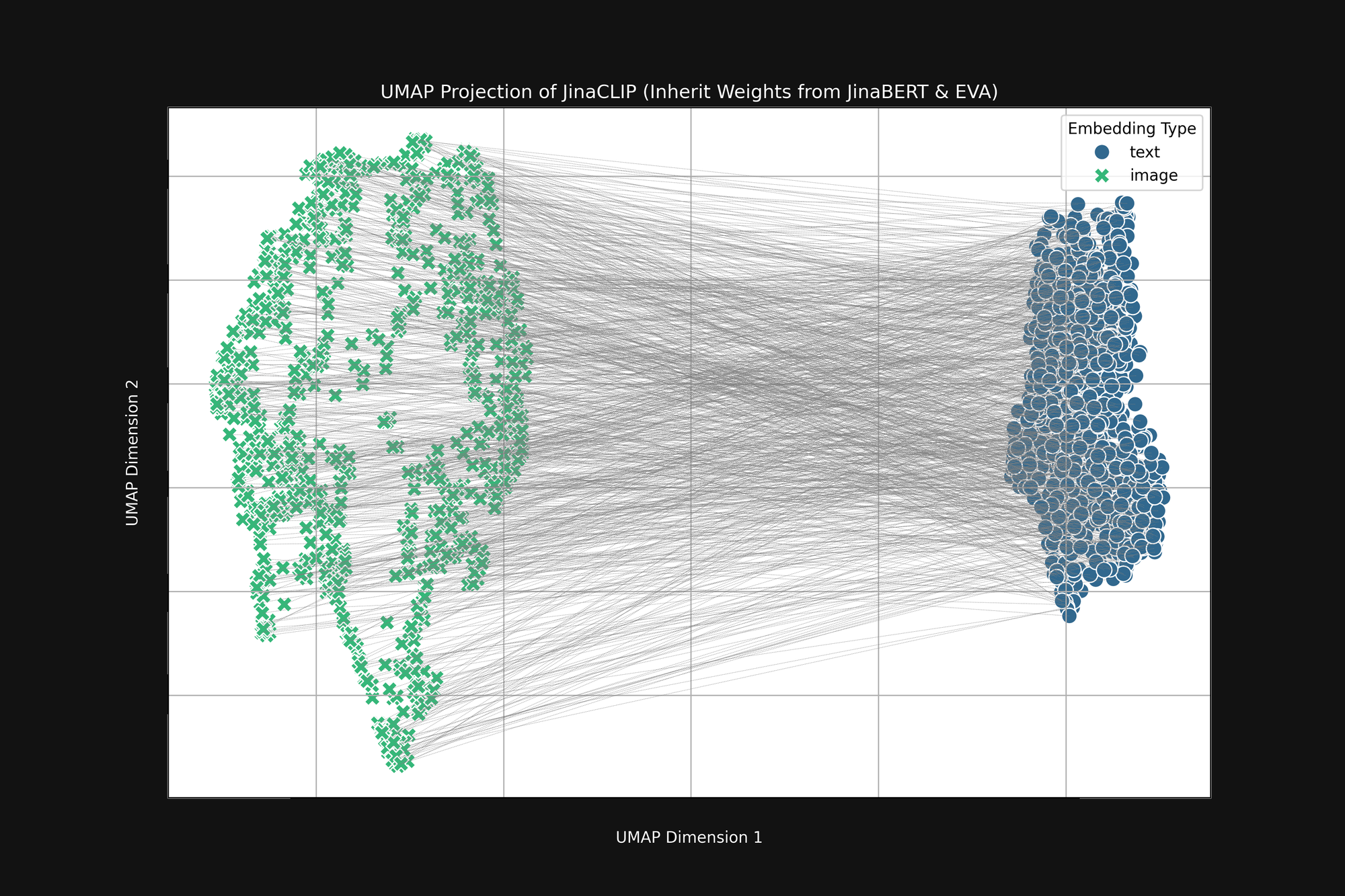
如果我們取這兩個預訓練模型並在與圖像-文本對訓練之前觀察它們的輸出,我們會注意到一些重要的事情。圖 2(上圖)是預訓練的 EVA-02 編碼器產生的圖像 embedding 和預訓練的 JinaBERT v2 產生的文本 embedding 的 UMAP 投影到二維空間,其中灰線表示匹配的圖像-文本對。這是在任何跨模態訓練之前的情況。
結果是一種截斷的"錐形",一端是圖像 embedding,另一端是文本 embedding。這個錐形在二維投影中難以完全呈現,但你大致可以在上圖中看到。所有文本都聚集在 embedding 空間的一個部分,而所有圖像則在另一個部分。如果在訓練後,文本與其他文本的相似度仍然高於與匹配圖像的相似度,這個初始狀態就是一個重要原因。最佳匹配圖像到文本、文本到文本以及圖像到圖像的目標與這種錐形完全兼容。
模型從一開始就有偏見,而且它所學習的內容並不會改變這一點。圖 3(下圖)是發布的 Jina CLIP 模型在使用圖像-文本對進行完整訓練後的相同分析。如果有什麼不同的話,這個多模態差距甚至更加明顯。
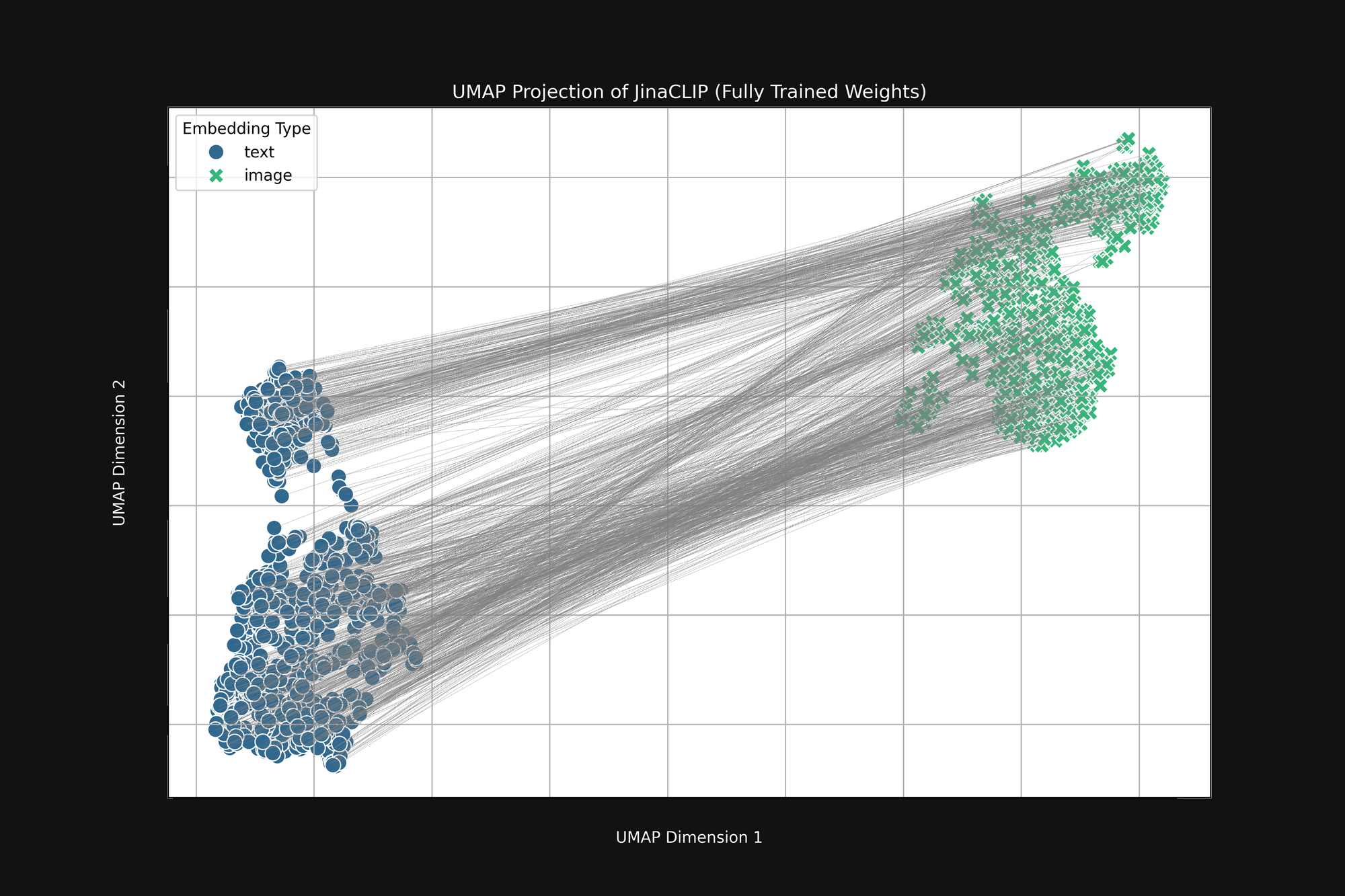
即使經過廣泛的訓練,Jina CLIP 仍然將媒體形式作為訊息的一部分進行編碼。
使用更昂貴的 OpenAI 方法,完全隨機初始化,也無法消除這種偏見。我們採用了原始的 OpenAI CLIP 架構並完全隨機化所有權重,然後進行了與上述相同的分析。結果仍然是截斷的錐形,如圖 4 所示:
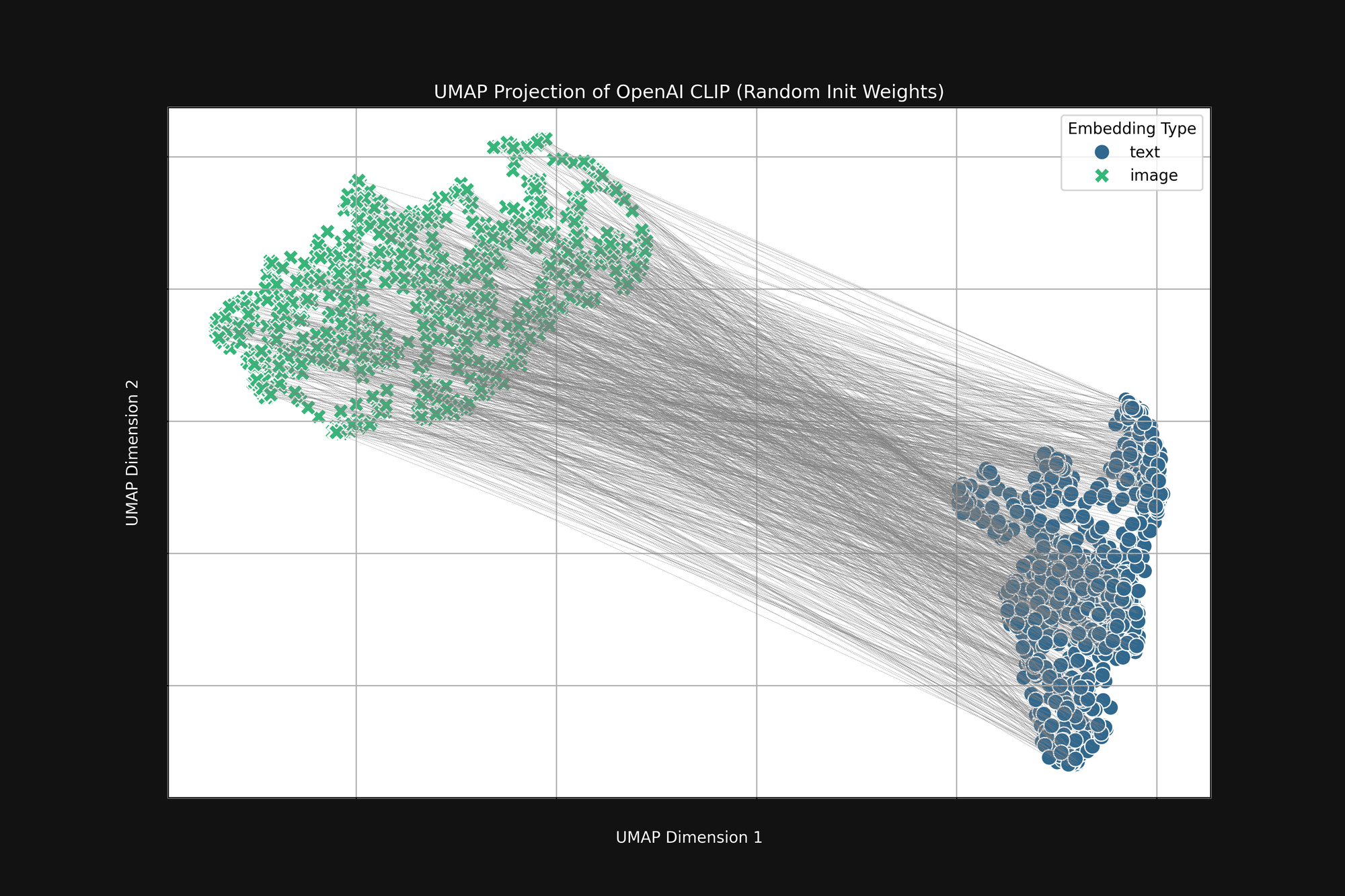
這種偏見是一個結構性問題,可能沒有任何解決方案。如果是這樣,我們只能尋找在訓練過程中糾正或緩解它的方法。
tag訓練溫度
在 AI 模型訓練過程中,我們通常會添加一些隨機性。我們計算一批訓練樣本應該如何改變模型中的權重,然後在實際改變權重之前為這些變化添加一個小的隨機因素。我們將隨機性的程度稱為溫度,這是類比於我們在熱力學中使用隨機性的方式。
高溫度會使模型發生非常快速的大變化,而低溫度則會減少模型每次看到訓練數據時可以改變的幅度。結果是,在高溫度下,我們可以預期單個 embedding 在訓練過程中會在 embedding 空間中大幅移動,而在低溫度下,它們的移動會慢得多。
訓練 AI 模型的最佳實踐是從高溫度開始,然後逐漸降低。這有助於模型在權重是隨機的或距離目標較遠的初始階段做出大幅度的學習跳躍,然後更穩定地學習細節。
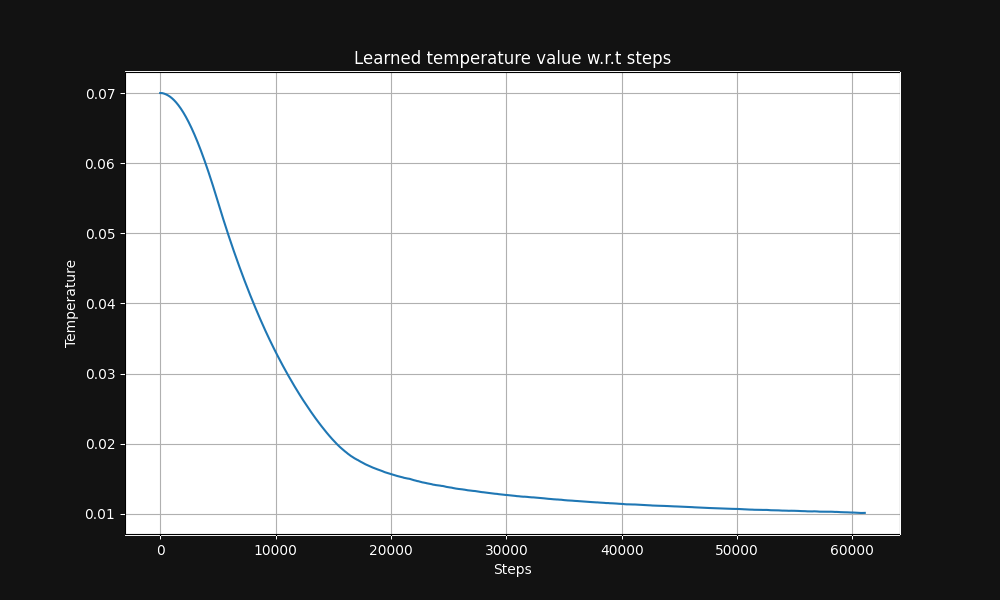
Jina CLIP 圖像-文本對訓練從溫度 0.07 開始(這是一個相對較高的溫度),並在訓練過程中指數級降低到 0.01,如下圖 5 所示,這是溫度與訓練步驟的關係圖:
我們想知道提高溫度——增加隨機性——是否會減少錐形效應,並使圖像 embedding 和文本 embedding 整體上更接近。因此我們用固定的溫度 0.1(一個非常高的值)重新訓練了 Jina CLIP。在每個訓練週期後,我們檢查了圖像-文本對和文本-文本對之間的距離分布,就像圖 1 中那樣。結果如下圖 6 所示:
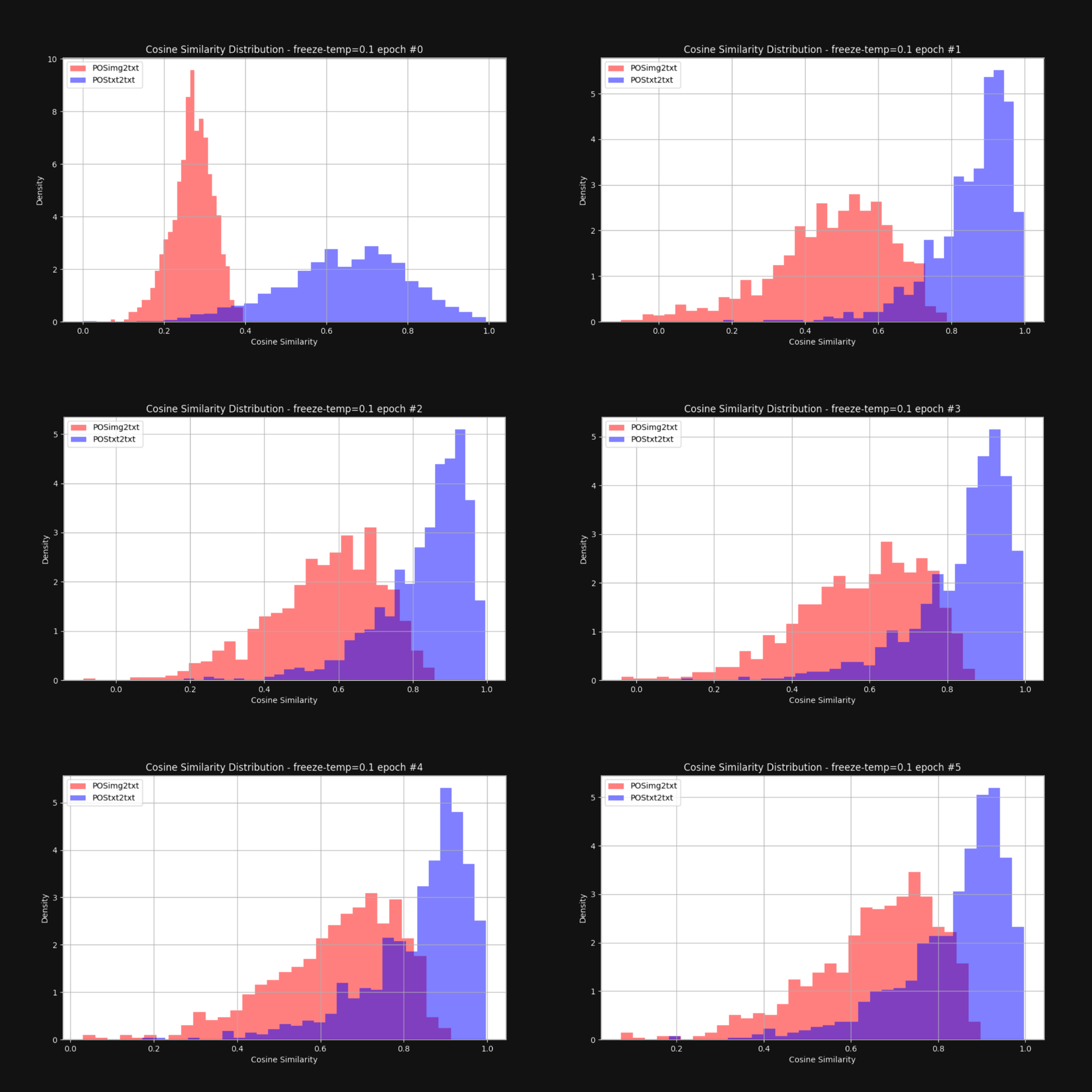
如您所見,保持高溫確實能顯著縮小多模態差距。在訓練過程中允許嵌入向量有較大的移動空間,有助於克服初始嵌入分布的偏差。
然而,這也是有代價的。我們使用六種不同的檢索測試來評估模型的性能:三個文本-文本檢索測試和三個文本-圖像檢索測試,分別來自 MS-COCO、Flickr8k 和 Flickr30k 數據集。在所有測試中,我們都看到性能在訓練初期急劇下降,然後緩慢上升,如圖 7 所示:
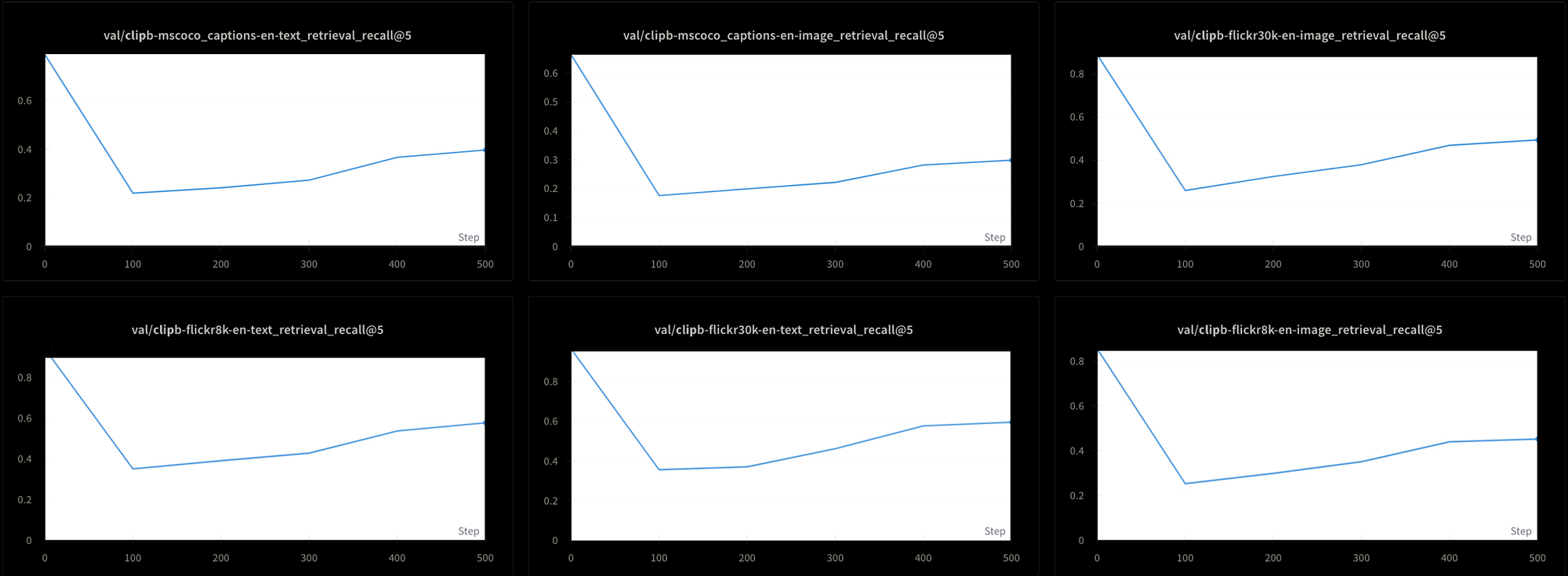
使用這種持續的高溫來訓練像 Jina CLIP 這樣的模型可能會非常耗時且昂貴。雖然理論上可行,但這並不是一個實用的解決方案。
tag對比學習和假負例問題
Liang 等人 [2022] 還發現,標準的對比學習實踐——我們用來訓練 CLIP 風格多模態模型的機制——傾向於加劇多模態差距。
對比學習本質上是一個簡單的概念。我們有一個圖像嵌入和一個文本嵌入,我們知道它們應該更接近,所以我們在訓練過程中調整模型中的權重來實現這一點。我們緩慢進行,每次只調整很小的量,而且調整的幅度與兩個嵌入之間的距離成比例:距離越近意味著變化越小,反之亦然。
這種技術在不僅使匹配的嵌入更接近,而且在不匹配時使它們更遠離時效果會更好。我們不僅要有應該在一起的圖像-文本對,還要有我們知道應該分開的對。
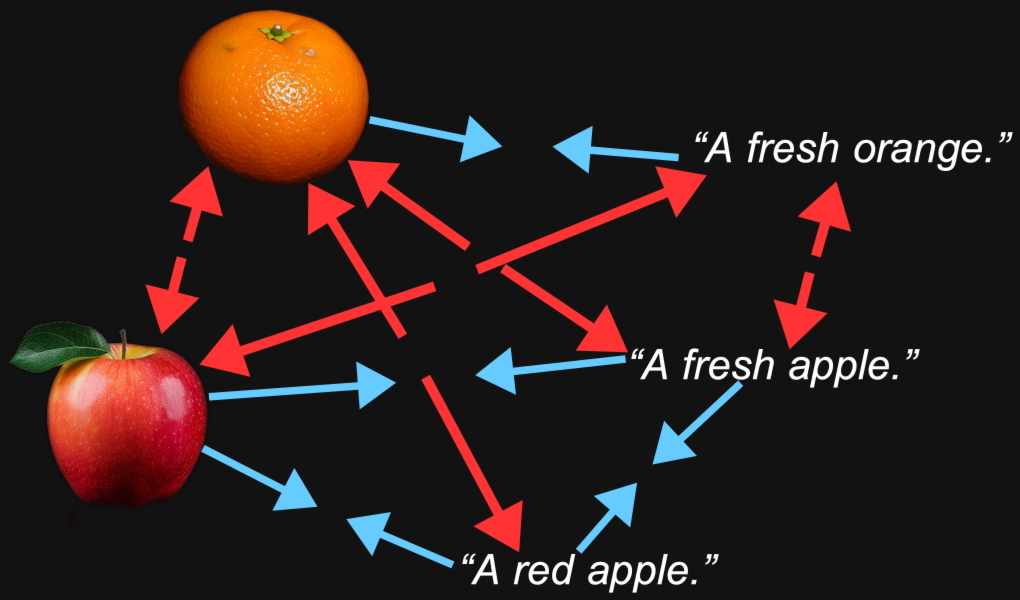
這帶來了一些問題:
- 我們的數據源完全由匹配對組成。沒有人會建立一個人工驗證不相關的文本和圖像數據庫,通過網絡爬取或其他無監督或半監督技術也難以構建這樣的數據庫。
- 即使表面上看起來完全不相關的圖像-文本對也不一定真的無關。我們沒有一個能夠客觀做出這種負面判斷的語義理論。例如,一張貓躺在門廊上的圖片與"一個人睡在沙發上"這段文本並非完全不匹配。兩者都涉及躺在某物上。
理想情況下,我們希望用確定相關和確定不相關的圖像-文本對來訓練,但沒有明顯的方法來獲得已知不相關的對。我們可以問人們"這個句子是否描述這張圖片?"並期望得到一致的答案。但問"這個句子是否與這張圖片完全無關?"則很難得到一致的答案。
相反,我們通過從訓練數據中隨機選擇圖片和文本來獲得不相關的圖像-文本對,期望它們在實際中幾乎總是不匹配的。在實踐中,我們將訓練數據分成批次。為了訓練 Jina CLIP,我們使用了包含 32,000 個匹配圖像-文本對的批次,但在這個實驗中,批次大小只有 16。
下表是從 Flickr8k 中隨機抽樣的 16 個圖像-文本對:
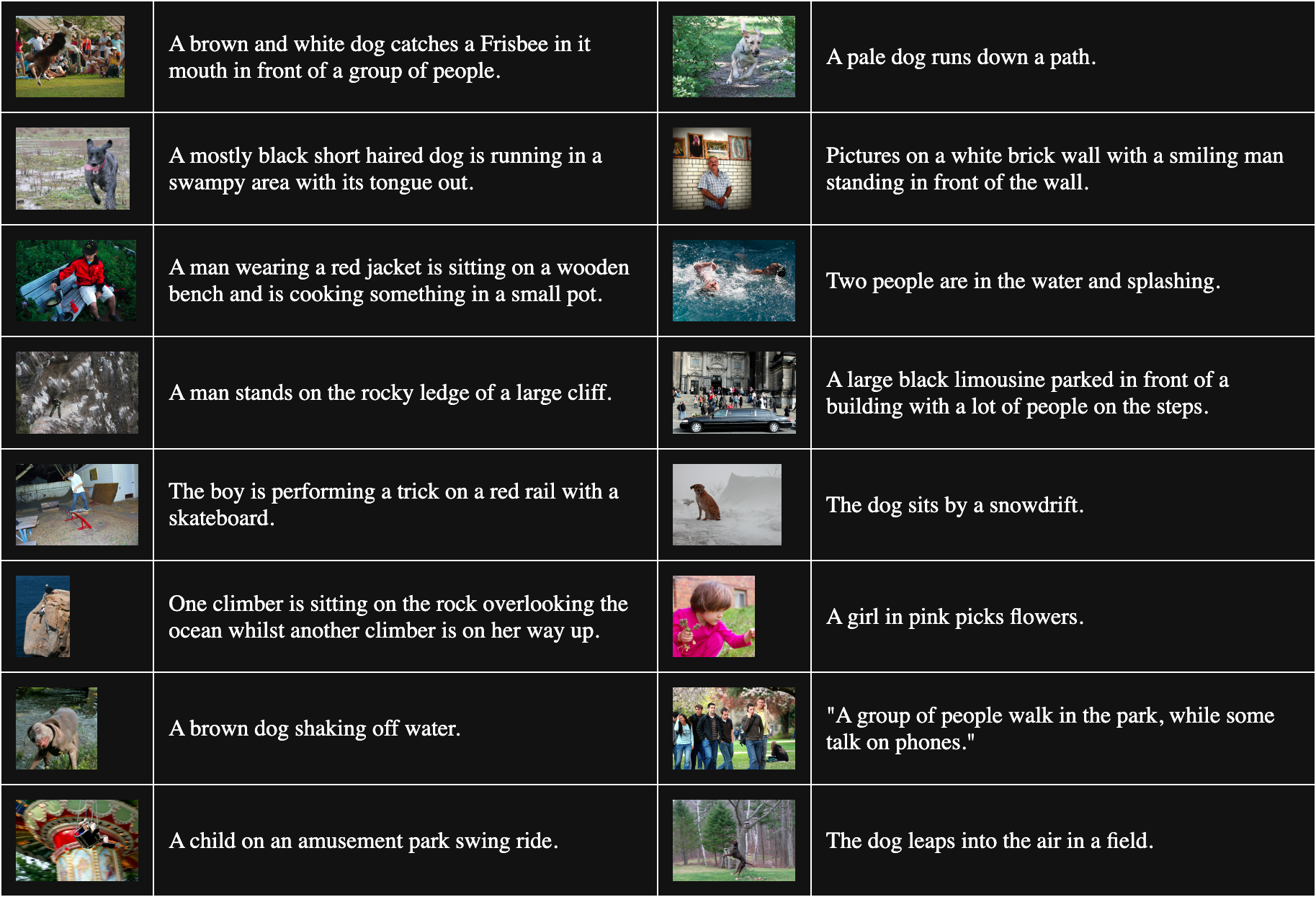
為了獲得不匹配的對,我們將批次中的每張圖片與除了與之匹配的文本之外的所有文本組合。例如,以下是一個不匹配的圖像和文本對:

說明文字:一個穿粉紅衣服的女孩在採摘花朵。
但這個程序假設所有與其他圖像匹配的文本都是同等程度的不良匹配。這並不總是正確的。例如:

說明文字:狗坐在雪堆旁邊。
雖然這段文本並未準確描述這張圖片,但它們都有一隻狗的共同點。將這對視為不匹配會傾向於將"狗"這個詞從任何狗的圖像中推開。
Liang 等人 [2022] 表明,這些不完美的不匹配對會將所有圖像和文本互相推開。
我們使用一個完全隨機初始化的 vit-b-32 圖像模型和一個類似隨機化的 JinaBERT v2 文本模型來驗證他們的說法,將訓練溫度設置為恆定的 0.02(適中的低溫度)。我們構建了兩組訓練數據:
- 一組是從 Flickr8k 中隨機抽取的批次,不匹配對按上述方式構建。
- 另一組中的批次是故意構建的,每個批次中包含同一張圖像的多個副本,但搭配不同的文本。這保證了相當數量的"不匹配"對實際上是彼此正確的匹配。
然後我們用每個訓練數據集分別訓練了兩個模型一個周期,並測量了每個模型在 Flickr8k 數據集中 1,000 個文本-圖像對之間的平均餘弦距離。用隨機批次訓練的模型平均餘弦距離為 0.7521,而用大量故意匹配的"不匹配"對訓練的模型平均餘弦距離為 0.7840。不正確的"不匹配"對的影響相當顯著。考慮到實際模型訓練時間更長且使用更多數據,我們可以看到這種效應會如何增長並加劇圖像和文本之間的整體差距。
tag媒介即訊息
加拿大傳播理論家 Marshall McLuhan 在他 1964 年的著作 《理解媒介:人的延伸》中提出了"媒介即訊息"這一短語,強調訊息並非自主存在的。訊息傳遞給我們時都帶有強烈影響其含義的語境,他著名地聲稱,這種語境中最重要的部分之一就是傳播媒介的本質。
多模態差距為我們提供了一個獨特的機會,讓我們可以研究 AI 模型中一類新興的語義現象。沒有人告訴 Jina CLIP 要對其訓練數據的媒介進行編碼 — 它就是自己做了。即使我們尚未解決多模態模型的問題,至少我們對問題的來源有了良好的理論理解。
我們應該假設,由於同樣的偏差,我們的模型正在編碼其他我們尚未發現的東西。例如,我們在多語言嵌入模型中可能存在相同的問題。對兩種或多種語言進行共同訓練可能會導致語言之間出現相同的差距,特別是因為類似的訓練方法被廣泛使用。解決差距問題可能會產生非常廣泛的影響。
對更廣泛模型中的初始化偏差進行研究也可能會帶來新的見解。如果媒介對嵌入模型來說就是信息,誰知道還有什麼在不知不覺中被編碼到我們的模型中?






