

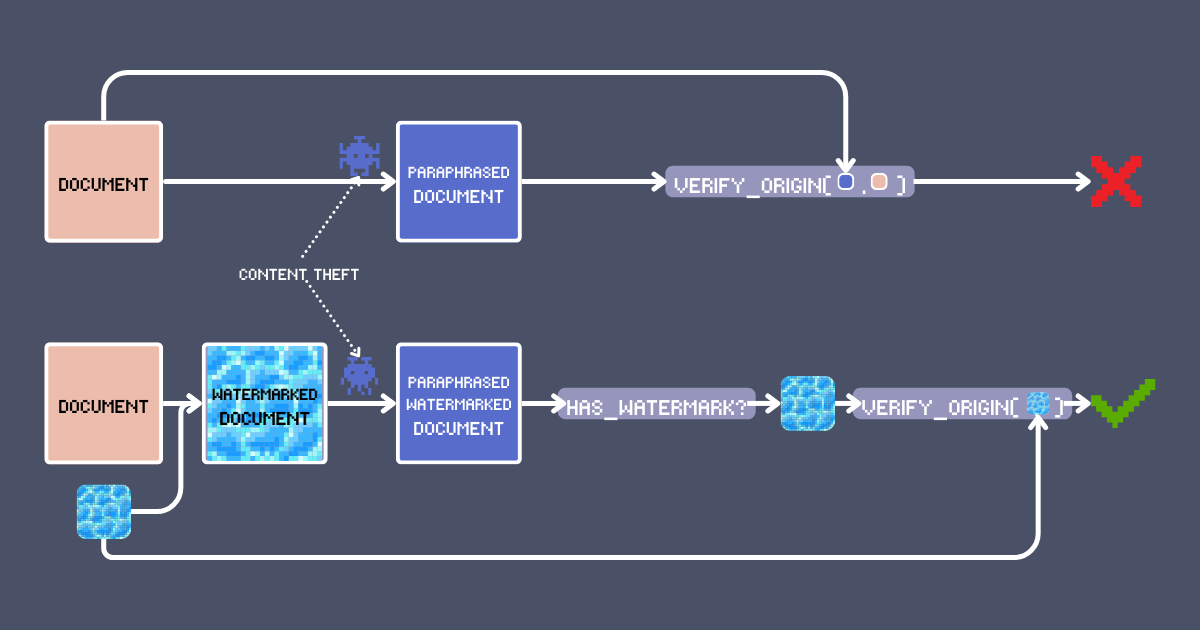
週日晚上,你發布了那篇投入整個週末心血的文章。每個詞、每個想法,都是獨一無二的你。幾個讚慢慢湧入。雖然不至於爆紅,但這是屬於你的作品。
三天後,滑動著你的信息流,你突然看到了:你的文章精髓被裝進了別人的軀殼!他們重新排列了文字,但你認得出自己的創作。最糟糕的是?他們的版本到處流傳,用你被盜的創意構建了病毒式的成功。這不是我們期待的創意經濟。
顯而易見的解決方案是在你的作品上署名。但老實說,這也是最容易被移除的。我們能做得更好嗎?在本文中,我們將展示一種使用 embedding 模型的水印技術,既可以簽署又可以檢測原創內容。這不只是另一個搜索/RAG 的陳詞濫調——它利用了 jina-embeddings-v3 的獨特功能,如長文本處理和跨語言對齊,來創建一個強大的認證系統,並允許我們在經過 LLM 改寫甚至翻譯等轉換後仍能維持可靠的內容驗證。
tag理解文本水印
數位水印多年來一直是內容保護的基石。當你發現一個帶有半透明標誌的迷因圖片時,你就看到了最基本形式的圖像水印。現代水印技術已經遠超過簡單的視覺覆蓋——許多水印現在對人眼是不可見的,同時仍然可以被機器讀取。
文本水印遵循類似的原則,但是在語義空間中運作。不是改變像素,文本水印微妙地修改內容,以保持原始含義的同時嵌入可檢測的簽名。因此,有效的文本水印的關鍵要求是:
- 語義保持:帶水印的文本應該保持其原始含義和可讀性,就像視覺水印不應該遮蓋圖像的關鍵元素一樣。
- 不可感知性:水印對人類讀者應該是無法察覺的,確保他們在內容轉換過程中無法有意識地保留或移除它。
- 機器可檢測:雖然水印對人類讀者來說可能很微妙,但它應該創建清晰、可測量的模式,使算法能夠可靠地識別。
- 轉換不變性:任何內容轉換(如改寫或翻譯),無論是有意的還是不知道水印存在的,都應該要麼保留水印,要麼需要如此實質性的改變,以至於從根本上改變原始內容的結構或含義。
tag使用 Embeddings 進行文本水印
讓我們使用 embeddings 來建立一個文本水印系統。首先,讓我們定義這個系統的關鍵組件:
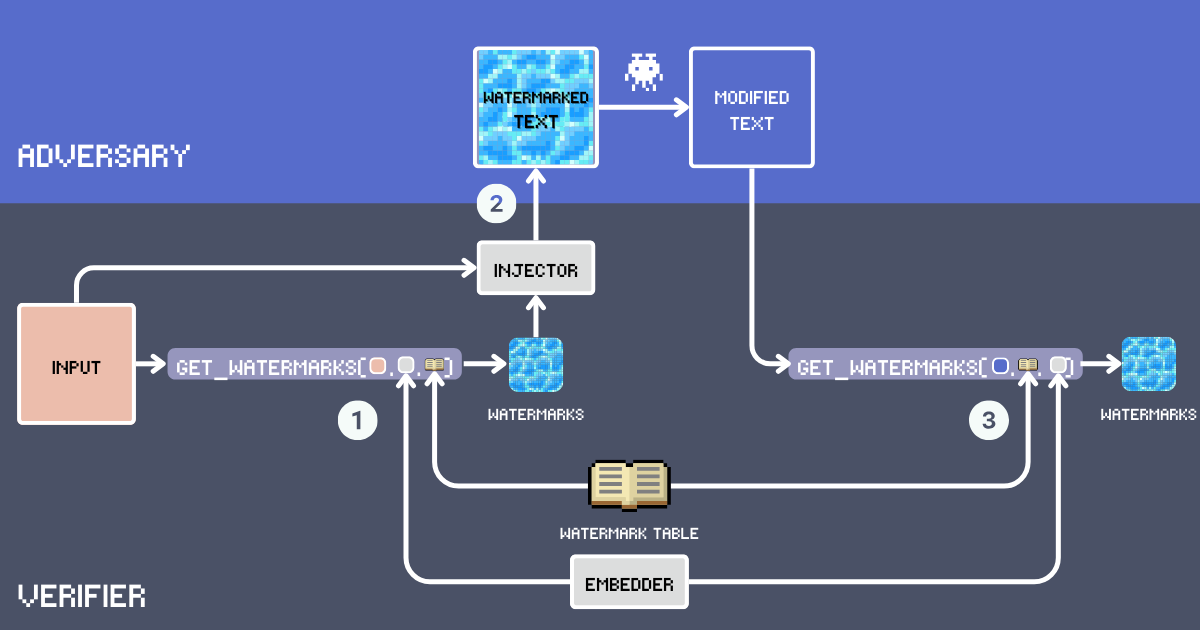
- 輸入:需要加水印的原始文本。
- 水印表:包含候選水印詞的秘密詞典。為了達到最佳的水印效果,這些詞應該足夠常見以自然地適應各種上下文。詞彙表排除了功能詞、專有名詞和可能顯得不自然的罕見詞,例如
delve into、embark是好的候選詞,而good則太常見了。下面,我們將使用高級英語詞彙來建立我們的 WatermarkTable。 - Embedder:一個 embedding 模型,服務於兩個目的:根據
input文本從WatermarkTable中選擇語義適當的詞,並幫助檢測可能被改寫文本中的水印。我們使用 jina-embeddings-v3 因為它能很好地處理超長文本和不同語言。這意味著我們可以為長文檔加水印,即使他們翻譯了文本也能抓到抄襲者。 - 水印:通過計算輸入文本 embedding 與表中 embeddings 的餘弦相似度從 WatermarkTable 中選擇的詞。詞的數量由插入比率決定,通常是輸入詞數的 12%。
- 注入器:一個遵循指令的 LLM,將水印詞整合到輸入文本中,同時保持連貫性、事實準確性、自然流暢性,以及水印詞在文本中的均勻分布。
- 帶水印的文本:注入器將水印詞插入
input後的輸出。 - 對手(內容盜竊):試圖在不注明出處的情況下重用帶水印文本的實體,通常通過改寫、翻譯或小幅編輯。現在,這簡單地意味著使用提示為
Paraphrase [text]的 LLM 進行自動重寫。 - 修改後的文本:對手對帶水印文本進行修改後的結果。這是我們需要檢查水印的文本。
tag算法


tag結論
從這些例子中,我們可以看到即使是使用這樣的基本設置,我們基於 embedding 的水印也相當穩健。特別值得注意的是,即使經過翻譯,水印仍然可以被檢測到。這種跨語言的穩健性是由 jina-embeddings-v3 模型強大的多語言功能實現的;如果沒有強大的多語言和跨語言能力,這種在翻譯中的持久性是無法實現的。
有幾種方法可以提高這個水印系統的準確性和穩健性。首先,水印表可以擴展並經過精心構建以確保多樣性。這很重要,因為更大、更多樣化的詞彙表能更好地覆蓋語義空間,使得為任何給定文本找到語境適當的水印變得更容易,同時降低重複或明顯模式的風險。
注入器組件可以通過實施更複雜的插入策略來改進。例如,它可以被指示在整個文本中均勻分布水印以保持不可察覺性。此外,我們可以使用延遲分塊技術為個別片段或句子生成水印,使注入器能夠對水印放置做出更細緻的決策。這將有助於在最終文本中同時維持整體的不可察覺性和語義連貫性。
對於有興趣深入探討的讀者,"POSTMARK: A Robust Blackbox Watermark for Large Language Models"(Chang 等人,EMNLP 2024)提供了一個包含數學公式和廣泛實驗的全面框架。作者系統地探討了水印詞彙的構建、最佳插入策略以及對各種攻擊的抵抗力。他們還通過自動化和人工評估,徹底分析了水印檢測和文本質量之間的權衡關係。





