

長文件分塊存在兩個問題:首先是確定斷點——即如何對文件進行分段。你可能會考慮固定的 token 長度、固定的句子數量,或更進階的技術,如正則表達式或語義分段模型。準確的分塊邊界不僅可以改善搜尋結果的可讀性,還能確保送入 LLM 的 RAG 系統中的分塊是精確且充分的——不多不少。
第二個問題是每個分塊中的上下文損失。一旦文件被分段,大多數人的下一個邏輯步驟是在批處理中分別嵌入每個分塊。然而,這會導致原始文件的全局上下文喪失。許多先前的研究首先解決第一個問題,認為更好的邊界檢測可以改善語義表示。例如,"語義分塊"將嵌入空間中具有高餘弦相似度的句子分組,以最小化語義單元的破壞。
從我們的觀點來看,這兩個問題幾乎是正交的,可以分別解決。如果必須優先處理,我們認為第二個問題更為關鍵。
| 問題 2:上下文信息 | |||
|---|---|---|---|
| 保留 | 喪失 | ||
| 問題 1:斷點 | 好 | 理想情況 | 搜尋結果差 |
| 差 | 搜尋結果好,但結果可能不易讀或不適合 LLM 推理 | 最糟糕的情況 |
tagLate Chunking 解決上下文損失
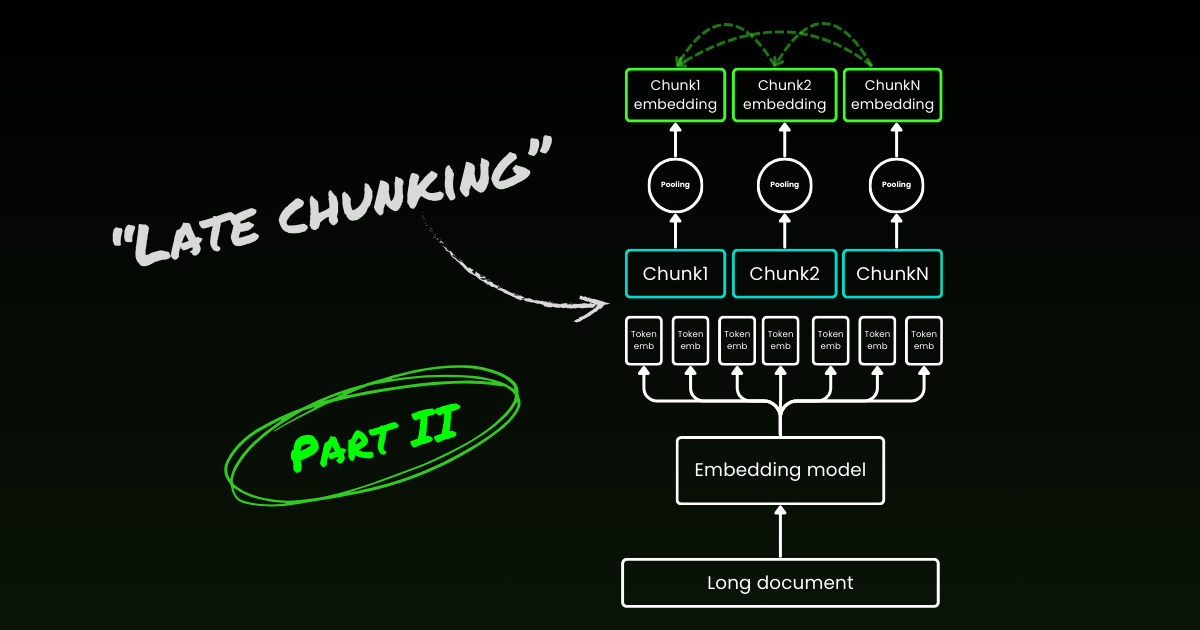
Late chunking 首先解決第二個問題:上下文損失。它不是為了找到理想的斷點或語義邊界。你仍然需要使用正則表達式、啟發式方法或其他技術將長文件分割成小塊。但是,與其在分段後立即嵌入每個分塊,late chunking 首先在一個上下文視窗中編碼整個文件(對於 jina-embeddings-v3 是 8192-token)。然後,它按照邊界提示對每個分塊進行平均池化——因此在 late chunking 中使用"late"一詞。

tagLate Chunking 對不良邊界提示具有彈性
真正有趣的是,實驗表明 late chunking 消除了對完美語義邊界的需求,這部分解決了上述第一個問題。事實上,應用於固定 token 邊界的 late chunking 表現優於具有語義邊界提示的原始分塊。當與 late chunking 配對時,像使用固定長度邊界這樣的簡單分段模型,其表現與進階邊界檢測算法相當。我們測試了三種不同大小的嵌入模型,結果表明它們在所有測試數據集中都一致地從 late chunking 中受益。話雖如此,嵌入模型本身仍然是表現最重要的因素——沒有任何情況下,使用 late chunking 的較弱模型會優於不使用它的較強模型。

jina-embeddings-v2-small)。作為消融研究的一部分,我們用不同的邊界提示(固定 token 長度、句子邊界和語義邊界)和不同的模型(jina-embeddings-v2-small、nomic-v1和 jina-embeddings-v3)測試了 late chunking。基於它們在 MTEB 上的表現,這三個嵌入模型的排名是:jina-embeddings-v2-small < nomic-v1 < jina-embeddings-v3。然而,這個實驗的重點不在於評估嵌入模型本身的性能,而是在於理解更好的嵌入模型如何與後期分塊和邊界提示互動。關於實驗的細節,請參閱我們的研究論文。| Combo | SciFact | NFCorpus | FiQA | TRECCOVID |
|---|---|---|---|---|
| Baseline | 64.2 | 23.5 | 33.3 | 63.4 |
| Late | 66.1 | 30.0 | 33.8 | 64.7 |
| Nomic | 70.7 | 35.3 | 37.0 | 72.9 |
| Jv3 | 71.8 | 35.6 | 46.3 | 73.0 |
| Late + Nomic | 70.6 | 35.3 | 38.3 | 75.0 |
| Late + Jv3 | 73.2 | 36.7 | 47.6 | 77.2 |
| SentBound | 64.7 | 28.3 | 30.4 | 66.5 |
| Late + SentBound | 65.2 | 30.0 | 33.9 | 66.6 |
| Nomic + SentBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SentBound | 71.4 | 35.8 | 43.7 | 72.4 |
| Late + Nomic + SentBound | 70.5 | 35.3 | 36.9 | 76.1 |
| Late + Jv3 + SentBound | 72.4 | 36.6 | 47.6 | 76.2 |
| SemanticBound | 64.3 | 27.4 | 30.3 | 66.2 |
| Late + SemanticBound | 65.0 | 29.3 | 33.7 | 66.3 |
| Nomic + SemanticBound | 70.4 | 35.3 | 34.8 | 74.3 |
| Jv3 + SemanticBound | 71.2 | 36.1 | 44.0 | 74.7 |
| Late + Nomic + SemanticBound | 70.5 | 36.9 | 36.9 | 76.1 |
| Late + Jv3 + SemanticBound | 72.4 | 36.6 | 47.6 | 76.2 |
請注意,對不良邊界具有彈性並不意味著我們可以忽視它們—它們對於人類和 LLM 的可讀性仍然很重要。我們是這樣看待這個問題的:在優化分段(即前面提到的第一個問題)時,我們可以完全專注於可讀性,而不必擔心語義/上下文的損失。後期分塊可以處理好或壞的斷點,所以你只需要關注可讀性。
tag後期分塊是雙向的
關於後期分塊的另一個常見誤解是,其條件塊嵌入僅依賴於先前的塊而不會"向前看"。這是不正確的。實際上,後期分塊中的條件依賴是雙向的,而不是單向的。這是因為嵌入模型(一個僅編碼器的 transformer)中的注意力矩陣是完全連接的,不像自回歸模型中使用的遮罩三角矩陣。形式上,第 k 個塊的嵌入 ,而不是 ,其中 表示語言模型的因子分解。這也解釋了為什麼後期分塊不依賴於精確的邊界放置。

tag後期分塊可以被訓練
後期分塊不需要對嵌入模型進行額外訓練。它可以應用於任何使用平均池化的長上下文嵌入模型,這使它對實踐者來說非常有吸引力。話雖如此,如果你在處理問答或查詢文檔檢索等任務,通過一些微調仍然可以進一步提高性能。具體來說,訓練數據由以下元組組成:
- 查詢(例如,問題或搜索詞)。
- 包含相關信息以回答查詢的文檔。
- 文檔中的相關片段,這是直接回答查詢的特定文本塊。
模型通過將查詢與其相關片段配對進行訓練,使用像 InfoNCE 這樣的對比損失函數。這確保了相關片段在嵌入空間中與查詢緊密對齊,而不相關的片段則被推得更遠。因此,模型學會在生成塊嵌入時專注於文檔中最相關的部分。更多詳情,請參考我們的研究論文。
tag後期分塊 vs 上下文檢索
在後期分塊推出後不久,Anthropic 引入了一個稱為上下文檢索的獨立策略。Anthropic 的方法是一種解決上下文丟失問題的暴力方法,其工作方式如下:
- 每個塊都與完整文檔一起發送給 LLM。
- LLM 為每個塊添加相關上下文。
- 這產生更豐富和更具信息性的嵌入。
在我們看來,這本質上是上下文豐富化,其中使用 LLM 將全局上下文明確地硬編碼到每個塊中,這在成本、時間和存儲方面都很昂貴。此外,目前還不清楚這種方法是否對塊邊界具有彈性,因為 LLM 依賴於準確和可讀的塊來有效地豐富上下文。相比之下,如上所示,後期分塊對邊界提示具有高度彈性。由於嵌入大小保持不變,它不需要額外的存儲空間。儘管利用了嵌入模型的完整上下文長度,它仍然比使用 LLM 生成豐富化要快得多。在我們研究論文的定性研究中,我們展示了 Anthropic 的上下文檢索與後期分塊的性能相似。然而,後期分塊通過利用僅編碼器 transformer 的固有機制,提供了一個更低級、更通用和更自然的解決方案。
tag哪些嵌入模型支持後期分塊?
後期分塊並不是 jina-embeddings-v3 或 v2 的專利。它是一種相當通用的方法,可以應用於任何使用平均池化的長上下文嵌入模型。例如,在這篇文章中,我們展示了 nomic-v1 也支持它。我們熱烈歡迎所有嵌入提供商在他們的解決方案中實現對後期分塊的支持。
作為模型使用者,在評估新的嵌入模型或 API 時,你可以按照以下步驟檢查它是否可能支持後期分塊:
- 單一輸出:模型/API 是否只提供每句話的一個最終 embedding,而不是 token 級別的 embeddings?如果是,那麼它可能無法支援延遲分塊(特別是對於那些網路 API)。
- 長文本支援:該模型/API 是否能處理至少 8192 個 tokens 的上下文?如果不能,延遲分塊就不適用——更準確地說,為短上下文模型改裝延遲分塊是沒有意義的。如果可以,請確保它在處理長文本時確實表現良好,而不是僅僅宣稱支援。你通常可以在模型的技術報告中找到這些資訊,例如在 LongMTEB 或其他長文本基準測試上的評估。
- 平均池化:對於自託管模型或在池化前提供 token 級別 embeddings 的 API,檢查其預設池化方法是否為平均池化。使用 CLS 或最大池化的模型與延遲分塊不相容。
總之,如果一個 embedding 模型支援長文本且預設使用平均池化,它就能輕鬆支援延遲分塊。查看我們的 GitHub 儲存庫以獲取實現細節和進一步討論。
tag結論
那麼,什麼是延遲分塊?延遲分塊是一種使用長文本 embedding 模型生成塊 embeddings 的直接方法。它快速、對邊界線索具有彈性,且高效。這不是一種啟發式方法或過度工程——而是一種基於對 transformer 機制深入理解的精心設計。
如今,圍繞 LLM 的炒作是不可否認的。在許多情況下,可以由像 BERT 這樣的較小模型有效解決的問題,反而被交給了 LLM 處理,這是由於人們對更大、更複雜解決方案的迷戀。大型 LLM 提供商推動其模型的更廣泛採用,而 embedding 提供商則提倡使用 embeddings,這並不令人驚訝——他們都在發揮各自的商業優勢。但最終,重要的不是炒作,而是行動,是什麼真正有效。讓社群、產業,最重要的是時間,來揭示哪種方法才是真正更精簡、更高效,且經得起時間考驗的。
請務必閱讀我們的研究論文,我們也鼓勵你在各種場景下對延遲分塊進行基準測試,並與我們分享你的反饋。
