



In unseren vorherigen Beiträgen haben wir die Herausforderungen des Chunkings untersucht und das Konzept des Late Chunking vorgestellt, das hilft, den Kontextverlust beim Einbetten von Chunks zu reduzieren. In diesem Beitrag konzentrieren wir uns auf eine weitere Herausforderung: das Finden optimaler Trennpunkte. Während sich unsere Late-Chunking-Strategie als sehr widerstandsfähig gegen schlechte Grenzen erwiesen hat, bedeutet das nicht, dass wir sie ignorieren können – sie sind weiterhin wichtig für die Lesbarkeit sowohl für Menschen als auch für LLMs. Unsere Perspektive ist folgende: Bei der Bestimmung von Trennpunkten können wir uns jetzt voll und ganz auf die Lesbarkeit konzentrieren, ohne uns Sorgen um semantischen oder Kontextverlust machen zu müssen. Late Chunking kann sowohl gute als auch schlechte Trennpunkte verarbeiten, sodass die Lesbarkeit Ihre primäre Sorge wird.
Vor diesem Hintergrund haben wir drei kleine Sprachmodelle trainiert, die speziell für die Segmentierung langer Dokumente entwickelt wurden, während sie semantische Kohärenz bewahren und komplexe Inhaltsstrukturen handhaben können. Diese sind:

simple-qwen-0.5, das Text basierend auf den strukturellen Elementen des Dokuments segmentiert.

topic-qwen-0.5, das Text basierend auf Themen innerhalb des Textes segmentiert.

summary-qwen-0.5, das Zusammenfassungen für jedes Segment generiert.
In diesem Beitrag werden wir diskutieren, warum wir dieses Modell entwickelt haben, wie wir die drei Varianten angegangen sind und wie sie sich im Vergleich zur Jina AI Segmenter API bewähren. Abschließend teilen wir unsere Erkenntnisse und einige Gedanken für die Zukunft.
tagSegmentierungsproblem
Segmentierung ist ein Kernelement in RAG-Systemen. Wie wir lange Dokumente in kohärente, handhabbare Segmente aufteilen, beeinflusst direkt die Qualität sowohl der Retrieval- als auch der Generierungsschritte und wirkt sich auf alles aus, von der Antwortrelevanz bis zur Zusammenfassungsqualität. Traditionelle Segmentierungsmethoden haben zwar gute Ergebnisse erzielt, sind aber nicht ohne Einschränkungen.
Um unseren vorherigen Beitrag zu paraphrasieren:
Bei der Segmentierung eines langen Dokuments besteht eine zentrale Herausforderung darin, zu entscheiden, wo die Segmente erstellt werden sollen. Dies kann durch feste Token-Längen, eine festgelegte Anzahl von Sätzen oder fortgeschrittenere Methoden wie Regex und semantische Segmentierungsmodelle erfolgen. Die Festlegung genauer Segmentgrenzen ist entscheidend, da sie nicht nur die Lesbarkeit der Suchergebnisse verbessert, sondern auch sicherstellt, dass die Segmente, die einem LLM in einem RAG-System bereitgestellt werden, sowohl präzise als auch ausreichend sind.
Während Late Chunking die Retrieval-Performance verbessert, ist es in RAG-Anwendungen entscheidend sicherzustellen, dass möglichst jedes Segment für sich genommen bedeutungsvoll ist und nicht nur ein zufälliger Textausschnitt. LLMs sind auf kohärente, gut strukturierte Daten angewiesen, um genaue Antworten zu generieren. Wenn Segmente unvollständig sind oder ihnen Bedeutung fehlt, könnte das LLM Probleme mit Kontext und Genauigkeit haben, was trotz der Vorteile des Late Chunking die Gesamtleistung beeinträchtigt. Kurz gesagt, ob Sie Late Chunking verwenden oder nicht, eine solide Segmentierungsstrategie ist essentiell für den Aufbau eines effektiven RAG-Systems (wie Sie im Benchmark-Abschnitt weiter unten sehen werden).
Traditionelle Segmentierungsmethoden, ob sie nun Inhalte an einfachen Grenzen wie Zeilenumbrüchen oder Sätzen trennen oder starre tokenbasierte Regeln verwenden, stoßen oft auf die gleichen Einschränkungen. Beide Ansätze berücksichtigen keine semantischen Grenzen und haben Schwierigkeiten mit mehrdeutigen Themen, was zu fragmentierten Segmenten führt. Um diese Herausforderungen zu bewältigen, haben wir ein kleines Sprachmodell speziell für die Segmentierung entwickelt und trainiert, das Themenwechsel erkennen und Kohärenz bewahren kann, während es effizient und anpassungsfähig für verschiedene Aufgaben bleibt.
tagWarum ein Small Language Model?
Wir haben ein Small Language Model (SLM) entwickelt, um spezifische Einschränkungen zu adressieren, auf die wir bei traditionellen Segmentierungstechniken gestoßen sind, insbesondere bei der Handhabung von Code-Snippets und anderen komplexen Strukturen wie Tabellen, Listen und Formeln. Bei traditionellen Ansätzen, die sich oft auf Token-Zählungen oder starre Strukturregeln verlassen, war es schwierig, die Integrität semantisch zusammenhängender Inhalte zu bewahren. Code-Snippets wurden zum Beispiel häufig in mehrere Teile segmentiert, was ihren Kontext zerstörte und es nachgelagerten Systemen erschwerte, sie genau zu verstehen oder abzurufen.
Durch das Training eines spezialisierten SLM wollten wir ein Modell schaffen, das diese bedeutungsvollen Grenzen intelligent erkennen und bewahren kann und sicherstellt, dass zusammengehörige Elemente zusammenbleiben. Dies verbessert nicht nur die Retrieval-Qualität in RAG-Systemen, sondern auch nachgelagerte Aufgaben wie Zusammenfassung und Frage-Antwort, bei denen die Beibehaltung kohärenter und kontextuell relevanter Segmente entscheidend ist. Der SLM-Ansatz bietet eine anpassungsfähigere, aufgabenspezifische Lösung, die traditionelle Segmentierungsmethoden mit ihren starren Grenzen einfach nicht bieten können.
tagTraining von SLMs: Drei Ansätze
Wir haben drei Versionen unseres SLM trainiert:
simple-qwen-0.5ist das geradlinigste Modell, entwickelt um Grenzen basierend auf den strukturellen Elementen des Dokuments zu identifizieren. Seine Einfachheit macht es zu einer effizienten Lösung für grundlegende Segmentierungsbedürfnisse.topic-qwen-0.5, inspiriert von Chain-of-Thought Reasoning, geht bei der Segmentierung einen Schritt weiter, indem es Themen im Text identifiziert, wie zum Beispiel "der Beginn des Zweiten Weltkriegs", und diese Themen verwendet, um Segmentgrenzen zu definieren. Dieses Modell stellt sicher, dass jedes Segment thematisch kohärent ist, was es gut geeignet für komplexe, mehrthemige Dokumente macht. Erste Tests zeigten, dass es besonders gut darin ist, Inhalte auf eine Weise zu segmentieren, die der menschlichen Intuition sehr nahe kommt.summary-qwen-0.5identifiziert nicht nur Textgrenzen, sondern generiert auch Zusammenfassungen für jedes Segment. Die Zusammenfassung von Segmenten ist in RAG-Anwendungen sehr vorteilhaft, besonders für Aufgaben wie die Beantwortung von Fragen zu langen Dokumenten, obwohl dies mit dem Kompromiss einhergeht, dass beim Training mehr Daten erforderlich sind.
Alle Modelle geben nur Segment-Heads zurück – eine gekürzte Version jedes Segments. Anstatt vollständige Segmente zu generieren, geben die Modelle Kernpunkte oder Unterthemen aus, was die Grenzerkennung und Kohärenz verbessert, indem sie sich auf semantische Übergänge konzentrieren, anstatt einfach Eingabeinhalte zu kopieren. Bei der Abfrage der Segmente wird der Dokumenttext basierend auf diesen Segment-Heads aufgeteilt und die vollständigen Segmente werden entsprechend rekonstruiert.
tagDatensatz
Wir verwendeten den wiki727k Datensatz, eine umfangreiche Sammlung strukturierter Textausschnitte aus Wikipedia-Artikeln. Er enthält über 727.000 Textabschnitte, die jeweils einen bestimmten Teil eines Wikipedia-Artikels repräsentieren, wie eine Einleitung, einen Abschnitt oder Unterabschnitt.
 koomri
koomritagData Augmentation
Um Trainingspaare für jede Modellvariante zu generieren, haben wir GPT-4 zur Datenanreicherung verwendet. Für jeden Artikel in unserem Trainingsdatensatz haben wir den folgenden Prompt gesendet:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()Wir haben eine einfache Aufteilung verwendet, um Abschnitte aus jedem Artikel zu generieren, indem wir bei \\n\\n\\n geteilt und dann bei \\n\\n unterteilt haben, um Folgendes zu erhalten (in diesem Fall ein Artikel über Common Gateway Interface):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
Anschließend haben wir eine JSON-Struktur mit den Abschnitten, Themen und Zusammenfassungen generiert:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Common Gateway Interface in Web Servers",
"The History and Standardization of CGI",
"CGI Scripts for Editing Web Pages",
"Reducing Web Server Overhead in Command Invocation"
],
"summaries": [
"CGI bietet ein Protokoll für Webserver zur Ausführung von Programmen, die dynamische Webseiten generieren.",
"Das NCSA definierte CGI ursprünglich 1993, was zu seiner Übernahme als Standard für Webserver und späteren Formalisierung in RFC 3875 unter Vorsitz von Ken Coar führte.",
"Dieser Text beschreibt, wie ein CGI-Skript die Bearbeitung und Speicherung von Webseiteninhalten über HTML-Formulare handhabt.",
"Der Text diskutiert Techniken zur Minimierung des Server-Overheads bei häufigen Befehlsaufrufen, einschließlich Prozess-Preforking, Verwendung vorkompilierter CGI-Programme und Implementierung benutzerdefinierter Webserver-Module."
]
}
Wir haben auch Rauschen hinzugefügt, indem wir Daten durchmischten, zufällige Zeichen/Wörter/Buchstaben hinzufügten, zufällig Interpunktion entfernten und immer Zeilenumbrüche entfernten.
All das kann teilweise zur Entwicklung eines guten Modells beitragen - aber nur bis zu einem gewissen Punkt. Um wirklich alle Register zu ziehen, musste das Modell kohärente Abschnitte erstellen, ohne Code-Snippets zu beschädigen. Dafür haben wir den Datensatz mit Code, Formeln und Listen erweitert, die von GPT-4o generiert wurden.
tagDas Training-Setup
Für das Training der Modelle haben wir folgendes Setup implementiert:
- Framework: Wir verwendeten Hugging Face's
transformersBibliothek integriert mitUnslothfür die Modelloptimierung. Dies war entscheidend für die Optimierung der Speichernutzung und Beschleunigung des Trainings, wodurch es möglich wurde, kleine Modelle mit großen Datensätzen effektiv zu trainieren. - Optimizer und Scheduler: Wir verwendeten den AdamW Optimizer mit einer linearen Lernratenplanung und Warm-up-Schritten, was uns ermöglichte, den Trainingsprozess während der ersten Epochen zu stabilisieren.
- Experiment Tracking: Wir verfolgten alle Trainingsexperimente mit Weights & Biases und protokollierten wichtige Metriken wie Training- und Validierungsverlust, Änderungen der Lernrate und die Gesamtleistung des Modells. Dieses Echtzeit-Tracking gab uns Einblicke in die Fortschritte der Modelle und ermöglichte schnelle Anpassungen, wenn nötig, um die Lernergebnisse zu optimieren.
tagDas Training selbst
Mit qwen2-0.5b-instruct als Basismodell trainierten wir drei Varianten unseres SLM mit Unsloth, jede mit einer anderen Segmentierungsstrategie im Sinn. Für unsere Samples verwendeten wir Trainingspaare, bestehend aus dem Text eines Artikels aus wiki727k und den resultierenden sections, topics oder summaries (oben im Abschnitt "Data Augmentation" erwähnt), je nach dem zu trainierenden Modell.
simple-qwen-0.5: Wir trainiertensimple-qwen-0.5mit 10.000 Samples über 5.000 Schritte und erreichten eine schnelle Konvergenz und effektive Erkennung von Grenzen zwischen kohärenten Textabschnitten. Der Trainingsverlust betrug 0,16.topic-qwen-0.5: Wie beisimple-qwen-0.5trainierten wirtopic-qwen-0.5mit 10.000 Samples über 5.000 Schritte und erreichten einen Trainingsverlust von 0,45.summary-qwen-0.5: Wir trainiertensummary-qwen-0.5mit 30.000 Samples über 15.000 Schritte. Dieses Modell zeigte vielversprechende Ergebnisse, hatte aber einen höheren Verlust (0,81) während des Trainings, was auf die Notwendigkeit von mehr Daten hinweist (etwa das Doppelte unserer ursprünglichen Sample-Anzahl), um sein volles Potenzial zu erreichen.
tagDie Segmente selbst
Hier sind Beispiele von drei aufeinanderfolgenden Segmenten aus jeder Segmentierungsstrategie, zusammen mit Jinas Segmenter API. Um diese Segmente zu erstellen, verwendeten wir zunächst Jina Reader, um einen Beitrag aus dem Jina AI Blog als Klartext zu extrahieren (einschließlich aller Seitendaten wie Header, Footer etc.), und übergaben ihn dann an jede Segmentierungsmethode.

tagJina Segmenter API
Jina Segmenter API verfolgte einen sehr granularen Ansatz bei der Segmentierung des Beitrags, indem es an Zeichen wie \n, \t etc. aufspaltete, um den Text in oft sehr kleine Segmente zu unterteilen. Betrachtet man nur die ersten drei, extrahierte es search\\n, notifications\\n und NEWS\\n aus der Navigationsleiste der Website, aber nichts Relevantes zum eigentlichen Beitragsinhalt:

Weiter unten erhielten wir endlich einige Segmente aus dem eigentlichen Blog-Beitragsinhalt, wobei in jedem nur wenig Kontext erhalten blieb:

(Im Interesse der Fairness haben wir für die Segmenter API mehr Chunks gezeigt als für die Modelle, einfach weil es sonst sehr wenige aussagekräftige Segmente zu zeigen gäbe)
tagsimple-qwen-0.5
simple-qwen-0.5 zerlegte den Blog-Beitrag basierend auf der semantischen Struktur und extrahierte viel längere Segmente mit kohärenter Bedeutung:
tagtopic-qwen-0.5
topic-qwen-0.5 identifizierte zunächst Themen basierend auf dem Dokumentinhalt und segmentierte dann das Dokument basierend auf diesen Themen:
tagsummary-qwen-0.5
summary-qwen-0.5 identifizierte Segmentgrenzen und generierte eine Zusammenfassung des Inhalts innerhalb jedes Segments:
tagBenchmarking der Modelle
Um die Leistung unserer Modelle zu bewerten, haben wir acht Blog-Beiträge aus dem Jina AI Blog extrahiert und sechs Fragen und Referenzantworten mit GPT-4o generiert.
Wir wendeten jede Segmentierungsmethode, einschließlich der Jina Segmenter API, auf diese Blog-Beiträge an und generierten dann Embeddings für die resultierenden Segmente mit jina-embeddings-v3, ohne spätes Chunking oder Reranking.

Jede Gruppe von Segmenten wurde dann separat indexiert und wir nutzten ein RAG-System, um jeden Index mit den zuvor generierten Fragen abzufragen.
topic-qwen-0.5 und summary-qwen-0.5 nur die Segmente selbst indexiert, nicht die generierten Zusammenfassungen oder Themen. Die Indexierung dieser zusätzlichen Daten würde die Leistung wahrscheinlich weiter verbessern.Um die Leistung zu messen, verglichen wir die aus dem Index jeder Segmentierungsmethode generierten Antworten mit den Ground-Truth-Antworten mittels F1-Scores aus der ROUGE-L-Evaluation, wobei höhere Scores bessere Leistung anzeigen.
Zum Beispiel erhielten wir für die Frage: "Welche Faktoren beeinflussen die numerischen Vergleichsfähigkeiten des jina-embeddings-v2-base-en Modells?" folgende Antworten:
tagGround Truth (Generiert von GPT-4 aus dem vollständigen Post-Text):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
tagJina Segmenter API (Score: 0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
tagsimple-qwen-0.5 (Score: 0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
tagtopic-qwen-0.5 (Score: 0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
tagsummary-qwen-0.5 (0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5 so niedrig?Dies ist größtenteils nur ein Zufall basierend auf der speziellen Frage, die wir dem Modell gestellt haben. Wie Sie in der untenstehenden Tabelle sehen können, ist der durchschnittliche ROUGE-Score von
topic-qwen-0.5 der höchste aller Segmentierungsmethoden.Wir bewerteten auch die Geschwindigkeit jeder Methode (durch Zeitmessung für die Generierung und Einbettung von Segmenten) und schätzten den Speicherplatzbedarf (durch Multiplikation der Anzahl der Einbettungen mit der Größe einer einzelnen 1024-dimensionalen Einbettung von jina-embeddings-v3). Dies ermöglichte uns, sowohl die Genauigkeit als auch die Effizienz der verschiedenen Segmentierungsstrategien zu bewerten.
tagWichtigste Erkenntnisse
Nach dem Test der Modellvarianten gegeneinander und gegen die Jina Segmenter API stellten wir fest, dass die neuen Modelle tatsächlich verbesserte Scores mit allen drei Methoden zeigten, besonders bei der Themensegmentierung:
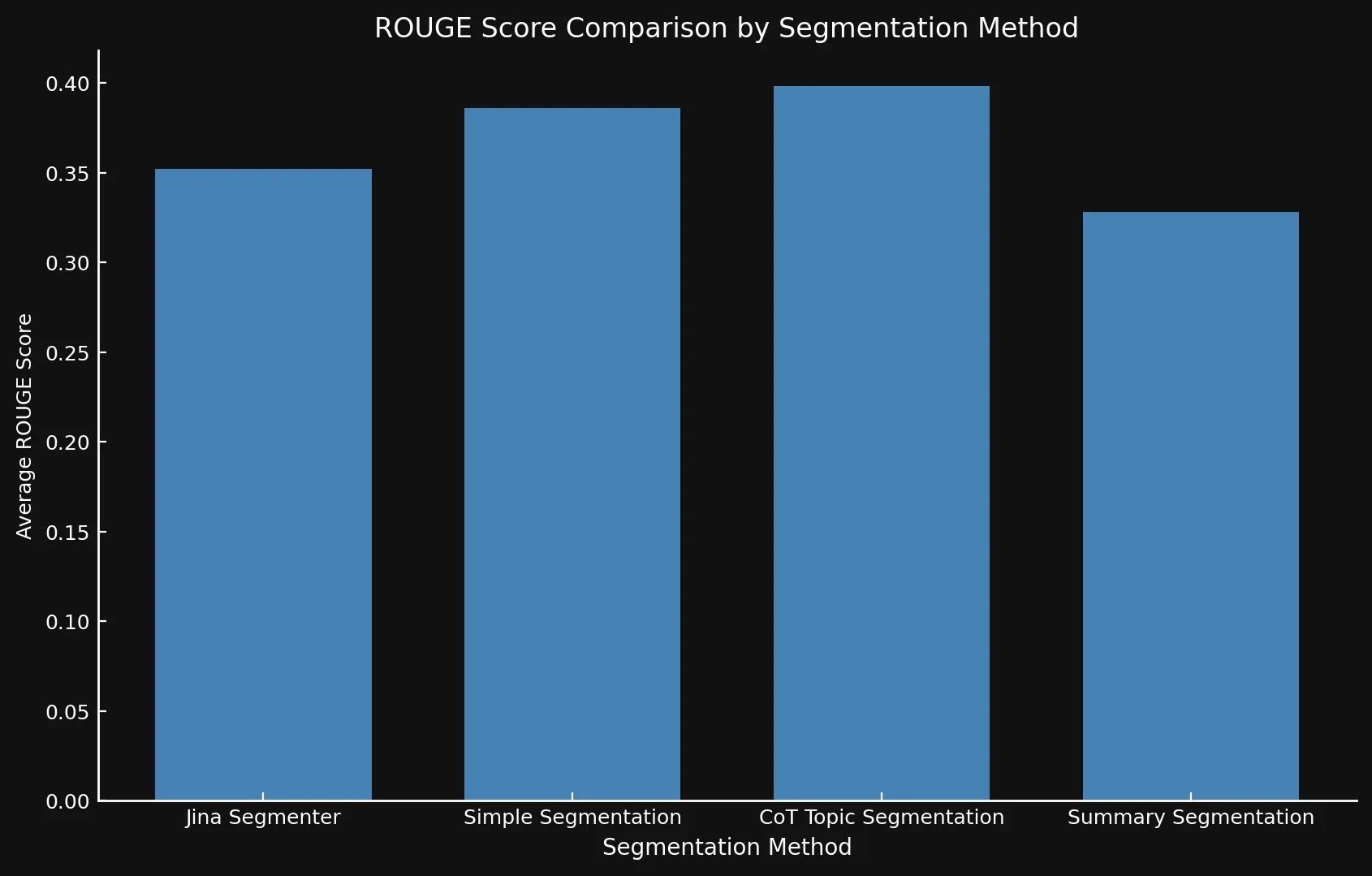
| Segmentierungsmethode | Durchschnittlicher ROUGE-Score |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 einen niedrigeren ROUGE-Score als topic-qwen-0.5? Kurz gesagt, summary-qwen-0.5 zeigte während des Trainings einen höheren Verlust, was den Bedarf an mehr Training für bessere Ergebnisse offenbart. Das könnte ein Thema für zukünftige Experimente sein.Allerdings wäre es interessant, die Ergebnisse mit der Late-Chunking-Funktion von jina-embeddings-v3 zu überprüfen, die die Kontextrelevanz der Segment-Embeddings erhöht und relevantere Ergebnisse liefert. Das könnte ein Thema für einen zukünftigen Blogbeitrag sein.
Bezüglich der Geschwindigkeit kann es schwierig sein, die neuen Modelle mit Jina Segmenter zu vergleichen, da letzteres eine API ist, während wir die drei Modelle auf einer Nvidia 3090 GPU liefen ließen. Wie Sie sehen können, wird jeder Geschwindigkeitsvorteil während des schnellen Segmentierungsschritts der Segmenter API schnell durch die Notwendigkeit überholt, Embeddings für so viele Segmente zu generieren:
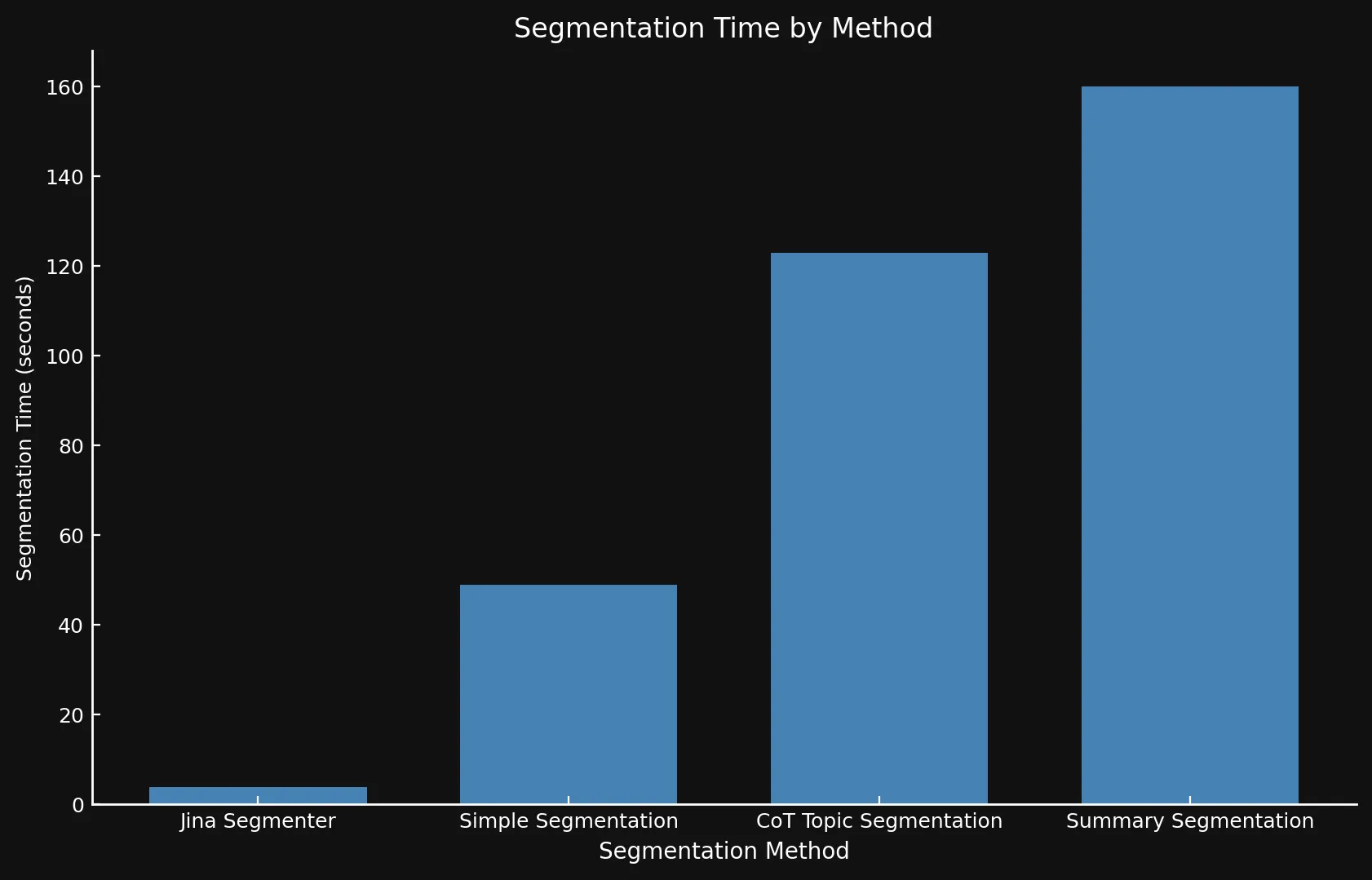
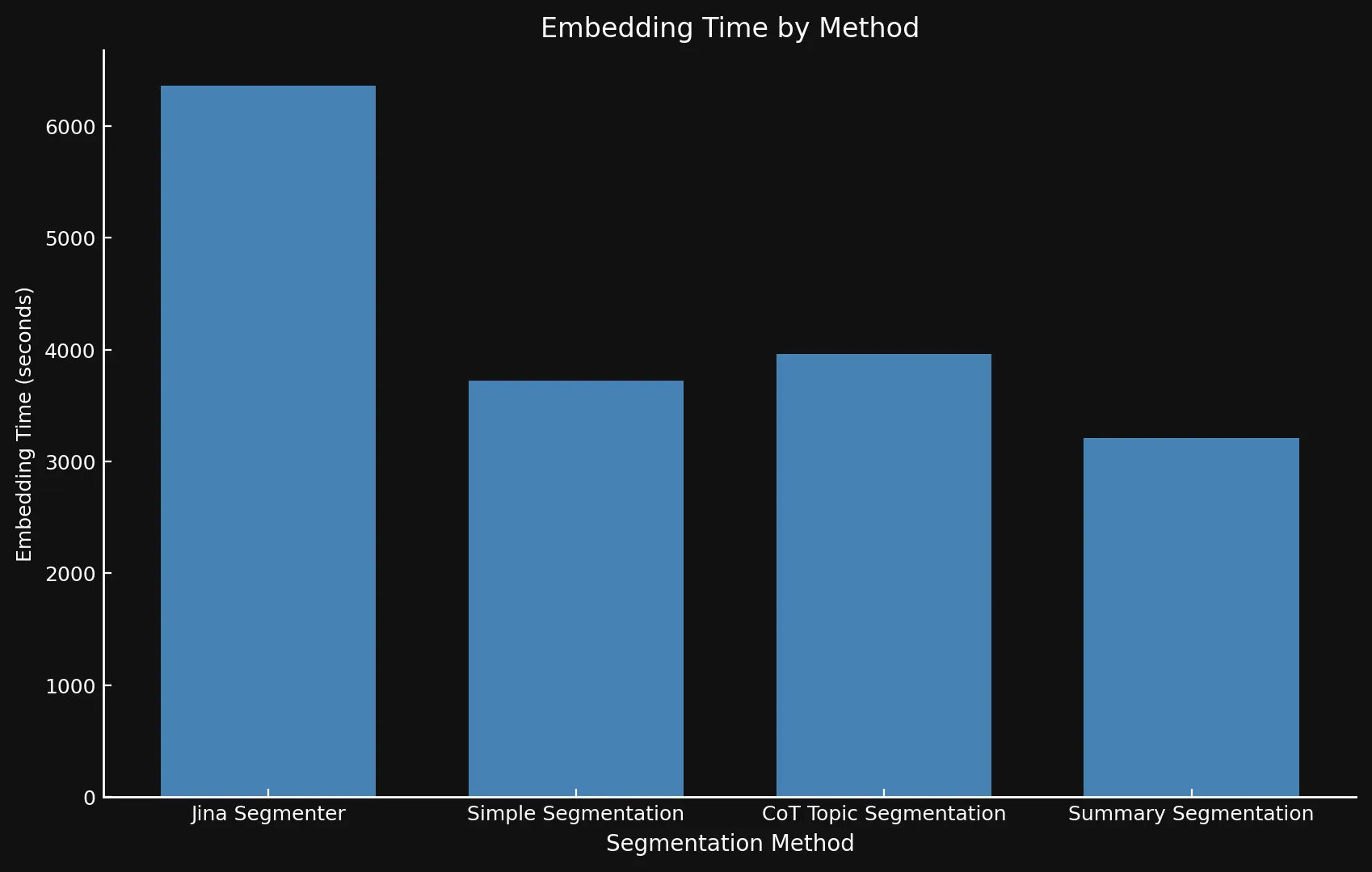
• Wir verwenden verschiedene Y-Achsen in beiden Grafiken, da die Darstellung so unterschiedlicher Zeitrahmen in einem Graphen oder mit konsistenten Y-Achsen nicht praktikabel war.
• Da wir dies rein als Experiment durchführten, verwendeten wir kein Batching bei der Generierung von Embeddings. Dies würde die Operationen für alle Methoden erheblich beschleunigen.
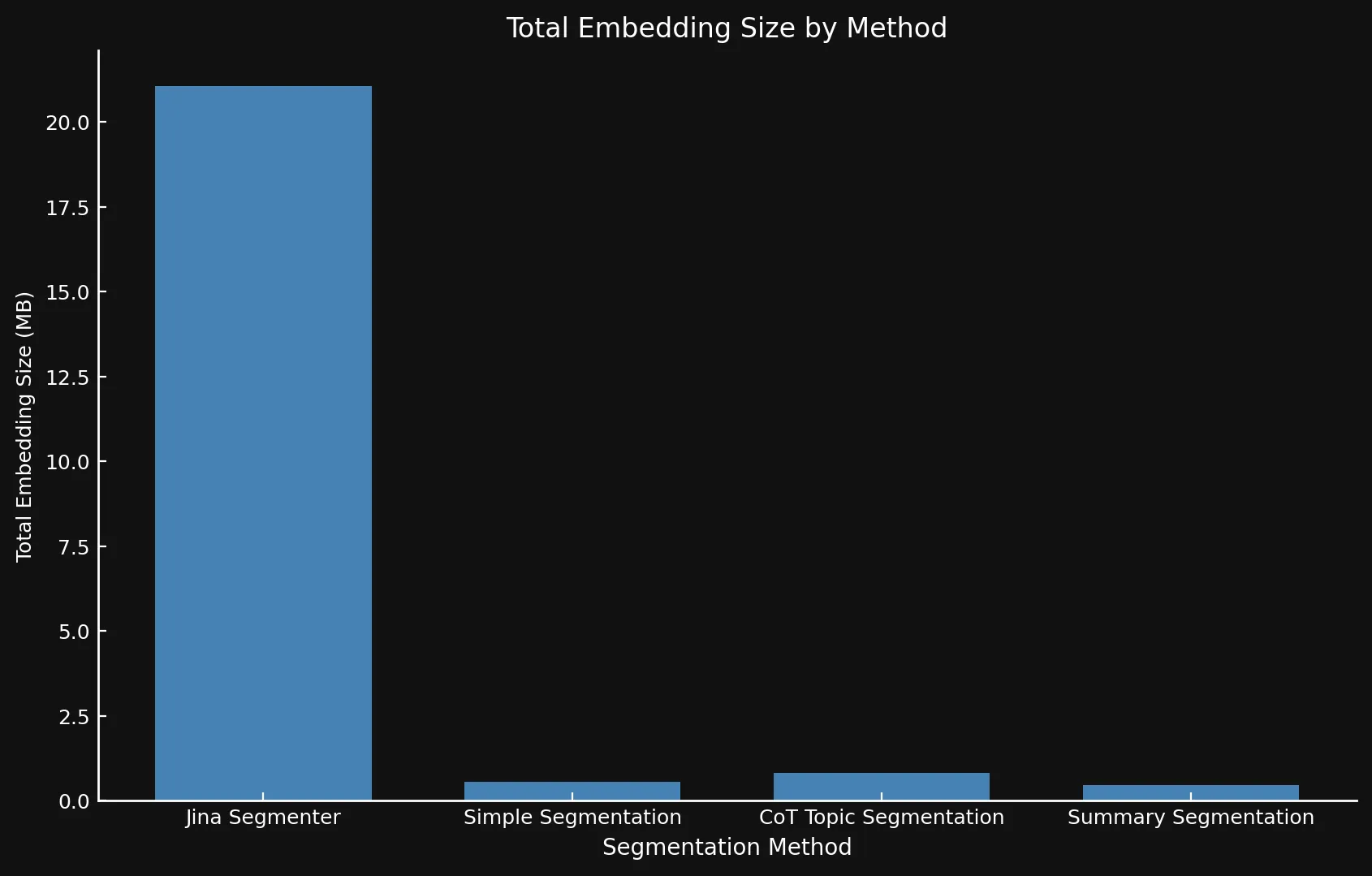
Natürlich bedeuten mehr Segmente mehr Embeddings. Und diese Embeddings benötigen viel Speicherplatz: Die Embeddings für die acht von uns getesteten Blogbeiträge beanspruchten über 21 MB mit der Segmenter API, während die Summary Segmentation mit schlanken 468 KB auskam. Dies, plus die höheren ROUGE-Scores unserer Modelle bedeuten weniger, aber bessere Segmente, was Geld spart und die Leistung steigert:
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
tagWas wir gelernt haben
tagDie Problemformulierung ist entscheidend
Eine wichtige Erkenntnis war der Einfluss der Aufgabenstellung. Indem wir das Modell Segmentköpfe ausgeben ließen, verbesserten wir die Erkennung von Grenzen und die Kohärenz, da wir uns auf semantische Übergänge konzentrierten, anstatt den Eingabeinhalt einfach in separate Segmente zu kopieren. Dies führte auch zu einem schnelleren Segmentierungsmodell, da die Generierung von weniger Text dem Modell ermöglichte, die Aufgabe schneller abzuschließen.
tagLLM-generierte Daten sind effektiv
Die Verwendung von LLM-generierten Daten, insbesondere für komplexe Inhalte wie Listen, Formeln und Code-Snippets, erweiterte den Trainingsdatensatz des Modells und verbesserte seine Fähigkeit, verschiedene Dokumentstrukturen zu verarbeiten. Dies machte das Modell anpassungsfähiger für unterschiedliche Inhaltstypen – ein entscheidender Vorteil bei der Verarbeitung technischer oder strukturierter Dokumente.
tagAusgabe-Only Datenkollation
Durch die Verwendung eines Output-Only Data Collators stellten wir sicher, dass sich das Modell während des Trainings auf die Vorhersage der Ziel-Tokens konzentrierte, anstatt nur von der Eingabe zu kopieren. Der Output-Only Collator gewährleistete, dass das Modell aus den tatsächlichen Zielsequenzen lernte und die korrekten Vervollständigungen oder Grenzen betonte. Diese Unterscheidung ermöglichte es dem Modell, schneller zu konvergieren, indem Overfitting auf die Eingabe vermieden wurde, und half ihm, besser über verschiedene Datensätze hinweg zu generalisieren.
tagEffizientes Training mit Unsloth
Mit Unsloth optimierten wir das Training unseres kleinen Sprachmodells und konnten es auf einer Nvidia 4090 GPU ausführen. Diese optimierte Pipeline ermöglichte es uns, ein effizientes, leistungsfähiges Modell ohne massive Rechenressourcen zu trainieren.
tagUmgang mit komplexen Texten
Die Segmentierungsmodelle überzeugten bei der Verarbeitung komplexer Dokumente mit Code, Tabellen und Listen, die für traditionellere Methoden typischerweise schwierig sind. Für technische Inhalte waren ausgeklügelte Strategien wie topic-qwen-0.5 und summary-qwen-0.5 effektiver, mit dem Potenzial, nachgelagerte RAG-Aufgaben zu verbessern.
tagEinfache Methoden für einfachere Inhalte
Für geradlinige, narrativ getriebene Inhalte sind einfachere Methoden wie die Segmenter API oft ausreichend. Fortgeschrittene Segmentierungsstrategien sind möglicherweise nur für komplexere, strukturierte Inhalte erforderlich, was je nach Anwendungsfall Flexibilität ermöglicht.
tagNächste Schritte
Während dieses Experiment in erster Linie als Machbarkeitsnachweis konzipiert war, könnten wir bei einer Erweiterung mehrere Verbesserungen vornehmen. Erstens, obwohl eine Fortsetzung dieses spezifischen Experiments unwahrscheinlich ist, würde das Training von summary-qwen-0.5 auf einem größeren Datensatz – idealerweise 60.000 statt 30.000 Samples – wahrscheinlich zu einer optimalen Leistung führen. Zusätzlich wäre eine Verfeinerung unseres Benchmarking-Prozesses vorteilhaft. Anstatt die vom LLM generierten Antworten aus dem RAG-System zu evaluieren, würden wir uns stattdessen darauf konzentrieren, die abgerufenen Segmente direkt mit der Ground Truth zu vergleichen. Schließlich würden wir über ROUGE-Scores hinausgehen und fortgeschrittenere Metriken (möglicherweise eine Kombination aus ROUGE und LLM-Scoring) einsetzen, die die Nuancen der Abruf- und Segmentierungsqualität besser erfassen.
tagFazit
In diesem Experiment untersuchten wir, wie kundenspezifische Segmentierungsmodelle, die für bestimmte Aufgaben entwickelt wurden, die Leistung von RAG verbessern können. Durch die Entwicklung und das Training von Modellen wie simple-qwen-0.5, topic-qwen-0.5 und summary-qwen-0.5 haben wir wichtige Herausforderungen traditioneller Segmentierungsmethoden angegangen, insbesondere bei der Aufrechterhaltung semantischer Kohärenz und der effektiven Verarbeitung komplexer Inhalte wie Code-Snippets. Unter den getesteten Modellen lieferte topic-qwen-0.5 durchgängig die sinnvollste und kontextuell relevanteste Segmentierung, besonders bei Dokumenten mit mehreren Themen.
Während Segmentierungsmodelle die strukturelle Grundlage für RAG-Systeme bieten, erfüllen sie eine andere Funktion als Late Chunking, das die Abrufleistung durch Aufrechterhaltung der kontextuellen Relevanz über Segmente hinweg optimiert. Diese beiden Ansätze können sich ergänzen, aber Segmentierung ist besonders wichtig, wenn eine Methode benötigt wird, die sich auf die Aufteilung von Dokumenten für kohärente, aufgabenspezifische Generierungsworkflows konzentriert.
