

Klassifizierung ist eine häufige nachgelagerte Aufgabe für Embeddings. Text-Embeddings können Text für Spam-Erkennung oder Stimmungsanalyse in vordefinierte Labels kategorisieren. Multimodale Embeddings wie jina-clip-v1 können für inhaltsbasierte Filterung oder Tag-Annotation eingesetzt werden. In letzter Zeit wird Klassifizierung auch verwendet, um Anfragen basierend auf Komplexität und Kosten an geeignete LLMs weiterzuleiten - einfache arithmetische Anfragen könnten beispielsweise an ein kleines Sprachmodell geleitet werden. Komplexe Denkaufgaben könnten an leistungsfähigere, aber kostspieligere LLMs weitergeleitet werden.
Heute stellen wir die neue Classifier API von Jina AI's Search Foundation vor. Sie unterstützt Zero-Shot und Few-Shot Online-Klassifizierung und basiert auf unseren neuesten Embedding-Modellen wie jina-embeddings-v3 und jina-clip-v1. Die Classifier API baut auf dem Online Passive-Aggressive Learning auf und ermöglicht so die Anpassung an neue Daten in Echtzeit. Benutzer können mit einem Zero-Shot-Klassifizierer beginnen und ihn sofort einsetzen. Sie können den Klassifizierer dann schrittweise aktualisieren, indem sie neue Beispiele einreichen oder wenn Concept Drift auftritt. Dies ermöglicht eine effiziente, skalierbare Klassifizierung verschiedener Inhaltstypen ohne umfangreiche anfängliche gelabelte Daten. Benutzer können ihre Klassifizierer auch für die öffentliche Nutzung freigeben. Wenn unsere neuen Embeddings erscheinen, wie das kommende multilinguale jina-clip-v2, können Benutzer sofort über die Classifier API darauf zugreifen und stellen so aktuelle Klassifizierungsfähigkeiten sicher.

tagZero-Shot-Klassifizierung
Die Classifier API bietet leistungsstarke Zero-Shot-Klassifizierungsfähigkeiten, die es ermöglichen, Text oder Bilder ohne vorheriges Training mit gelabelten Daten zu kategorisieren. Jeder Klassifizierer beginnt mit Zero-Shot-Fähigkeiten, die später durch zusätzliche Trainingsdaten oder Updates erweitert werden können - ein Thema, das wir im nächsten Abschnitt behandeln werden.
tagBeispiel 1: LLM-Anfragen weiterleiten
Hier ist ein Beispiel für die Verwendung der Classifier API zum Routing von LLM-Anfragen:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"Simple task",
"Complex reasoning",
"Creative writing"
],
"input": [
"Calculate the compound interest on a principal of $10,000 invested for 5 years at an annual rate of 5%, compounded quarterly.",
"分析使用CRISPR基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"AIが自意識を持つディストピアの未来を舞台にした短編小説を書いてください。人間とAIの関係や意識の本質をテーマに探求してください。",
"Erklären Sie die Unterschiede zwischen Merge-Sort und Quicksort-Algorithmen in Bezug auf Zeitkomplexität, Platzkomplexität und Leistung in der Praxis.",
"Write a poem about the beauty of nature and its healing power on the human soul.",
"Translate the following sentence into French: The quick brown fox jumps over the lazy dog."
]
}'Dieses Beispiel demonstriert die Verwendung von jina-embeddings-v3 zur Weiterleitung von Benutzeranfragen in mehreren Sprachen (Englisch, Chinesisch, Japanisch und Deutsch) in drei Kategorien, die drei verschiedenen LLM-Größen entsprechen. Das API-Antwortformat sieht wie folgt aus:
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "Simple task", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "Complex reasoning", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "Creative writing", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "Complex reasoning", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "Creative writing", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "Simple task", "score": 0.3561534285545349}
]
}Die Antwort enthält:
usage: Informationen über die Token-Nutzung.data: Ein Array von Klassifizierungsergebnissen, eines für jede Eingabe.- Jedes Ergebnis enthält das vorhergesagte Label (
prediction) und einen Konfidenzwert (score). Derscorefür jede Klasse wird durch Softmax-Normalisierung berechnet - für Zero-Shot basiert er auf Kosinus-Ähnlichkeiten zwischen Eingabe- und Label-Embeddings unterclassificationtask-LoRA; während er für Few-Shot auf gelernten linearen Transformationen des Eingabe-Embeddings für jede Klasse basiert - was zu Wahrscheinlichkeiten führt, die sich über alle Klassen zu 1 summieren. - Der
indexentspricht der Position der Eingabe in der ursprünglichen Anfrage.
- Jedes Ergebnis enthält das vorhergesagte Label (
tagBeispiel 2: Bild & Text kategorisieren
Lassen Sie uns ein multimodales Beispiel mit jina-clip-v1 untersuchen. Dieses Modell kann sowohl Text als auch Bilder klassifizieren und eignet sich damit ideal für die Inhaltskategorisierung über verschiedene Medientypen hinweg. Betrachten Sie den folgenden API-Aufruf:
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"Food and Dining",
"Technology and Gadgets",
"Nature and Outdoors",
"Urban and Architecture"
],
"input": [
{"text": "A sleek smartphone with a high-resolution display and multiple camera lenses"},
{"text": "Fresh sushi rolls served on a wooden board with wasabi and ginger"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "Vibrant autumn leaves in a dense forest with sunlight filtering through"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'Beachten Sie, wie wir Bilder in der Anfrage hochladen. Sie können auch einen base64-String verwenden, um ein Bild darzustellen. Die API gibt die folgenden Klassifizierungsergebnisse zurück:
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "Technology and Gadgets", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "Food and Dining", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "Nature and Outdoors", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "Urban and Architecture", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "Nature and Outdoors", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "Technology and Gadgets", "score": 0.27474141120910645}
]
}tagBeispiel 3: Erkennen, ob Jina Reader echte Inhalte erhält
Eine interessante Anwendung der Zero-Shot-Klassifizierung ist die Bestimmung der Website-Zugänglichkeit durch Jina Reader. Während dies wie eine einfache Aufgabe erscheinen mag, ist es in der Praxis überraschend komplex. Blockierte Nachrichten variieren stark von Site zu Site, erscheinen in verschiedenen Sprachen und nennen verschiedene Gründe (Bezahlschranken, Rate-Limits, Server-Ausfälle). Diese Vielfalt macht es schwierig, sich auf Regex oder feste Regeln zu verlassen, um alle Szenarien zu erfassen.
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)Das Skript ruft Inhalte über r.jina.ai ab und klassifiziert sie mit der Classifier API als "Blocked" oder "Accessible". Zum Beispiel würde https://r.jina.ai/https://www.crunchbase.com/organization/jina-ai wahrscheinlich aufgrund von Zugriffseinschränkungen als "Blocked" eingestuft, während https://r.jina.ai/https://jina.ai "Accessible" sein sollte.
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}Die Classifier API kann effektiv zwischen echten Inhalten und blockierten Ergebnissen von Jina Reader unterscheiden.
Dieses Beispiel nutzt jina-embeddings-v3 und bietet eine schnelle, automatisierte Möglichkeit zur Überwachung der Website-Zugänglichkeit, was besonders für Content-Aggregation oder Web-Scraping-Systeme in mehrsprachigen Umgebungen nützlich ist.
tagBeispiel 4: Filtern von Aussagen aus Meinungen für Grounding
Eine weitere spannende Anwendung der Zero-Shot-Klassifizierung ist das Filtern von aussageähnlichen Behauptungen aus Meinungen in langen Dokumenten. Beachten Sie, dass der Klassifizierer selbst nicht bestimmen kann, ob etwas faktisch wahr ist. Stattdessen identifiziert er Text, der im Stil einer faktischen Aussage geschrieben ist, der dann über eine Grounding API verifiziert werden kann, was oft recht aufwändig ist. Dieser zweistufige Prozess ist der Schlüssel zu effektivem Fact-Checking: Zunächst werden alle Meinungen und Gefühle herausgefiltert, dann werden die verbleibenden Aussagen zur Verifizierung gesendet.
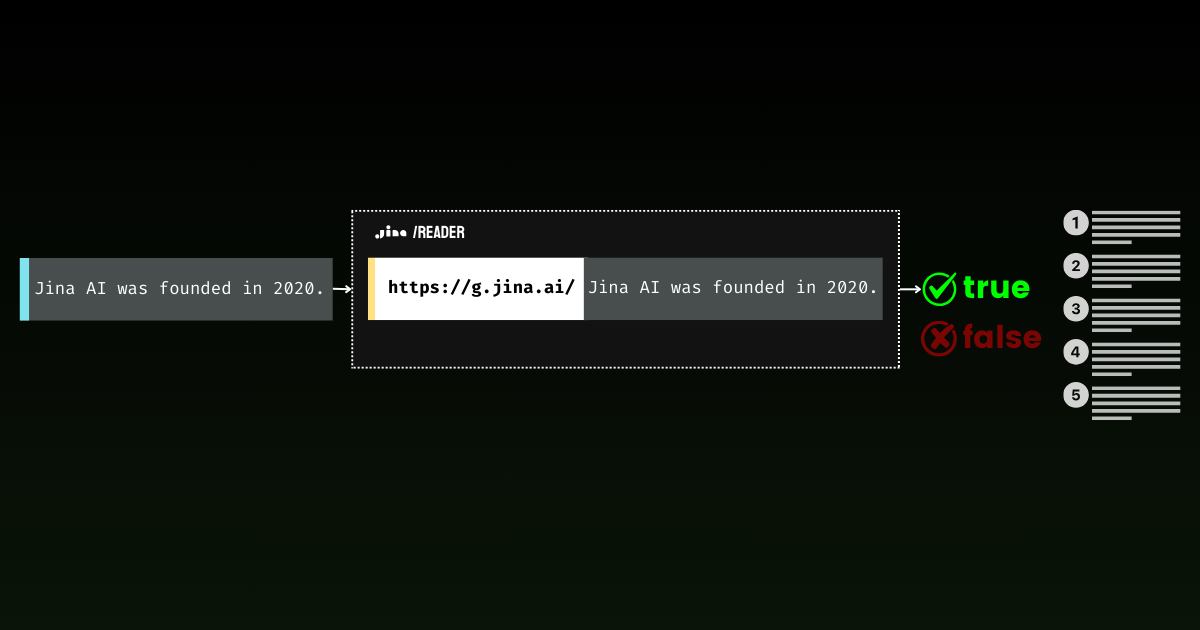
Betrachten Sie diesen Absatz über das Wettrüsten im Weltraum in den 1960er Jahren:
The Space Race of the 1960s was a breathtaking testament to human ingenuity. When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era. The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance. NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973. While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent. On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars. The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination. The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle.
Dieser Text vermischt absichtlich verschiedene Schreibstile - von aussageähnlichen Behauptungen (wie "Sputnik 1 wurde am 4. Oktober 1959 gestartet") bis hin zu eindeutigen Meinungen ("atemberaugendes Zeugnis"), emotionaler Sprache ("versetzte Angst in die Herzen") und interpretativen Behauptungen ("markierte den unbestreitbaren Beginn einer neuen Ära").
Die Aufgabe des Zero-Shot-Klassifizierers ist rein semantisch - er identifiziert, ob ein Textstück als Aussage oder als Meinung/Interpretation geschrieben ist. Zum Beispiel ist "The Soviet Union launched Sputnik 1 on October 4, 1959" als Aussage geschrieben, während "The Space Race was a breathtaking testament" eindeutig als Meinung geschrieben ist.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
# Step 1: Split text and classify
chunks = [chunk.strip() for chunk in text.split('.') if chunk.strip()]
labels = [
"subjective, opinion, feeling, personal experience, creative writing, position",
"fact"
]
# Classify chunks
classify_response = requests.post(
'https://api.jina.ai/v1/classify',
headers=headers,
json={
"model": "jina-embeddings-v3",
"input": [{"text": chunk} for chunk in chunks],
"labels": labels
}
)
# Sort chunks
subjective_chunks = []
factual_chunks = []
for chunk, classification in zip(chunks, classify_response.json()['data']):
if classification['prediction'] == labels[0]:
subjective_chunks.append(chunk)
else:
factual_chunks.append(chunk)
print("\nSubjective statements:", subjective_chunks)
print("\nFactual statements:", factual_chunks)Und Sie erhalten:
Subjective statements: ['The Space Race of the 1960s was a breathtaking testament to human ingenuity', 'The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance', 'While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent', "The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination"]
Factual statements: ['When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era', "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973", "On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars", 'The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle']Denken Sie daran, nur weil etwas als Aussage geschrieben ist, bedeutet das nicht, dass es wahr ist. Deshalb benötigen wir den zweiten Schritt - diese aussageähnlichen Behauptungen in eine Grounding API einzuspeisen, um die tatsächlichen Fakten zu überprüfen. Überprüfen wir zum Beispiel diese Aussage: "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973" mit dem Code unten.
ground_headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
ground_response = requests.get(
f'https://g.jina.ai/{quote(factual_chunks[1])}',
headers=ground_headers
)
print(ground_response.json())was Ihnen Folgendes liefert:
{'code': 200, 'status': 20000, 'data': {'factuality': 1, 'result': True, 'reason': "The statement is supported by multiple references confirming NASA's founding in 1958 and the significant financial investment in the Apollo program. The $28 billion figure aligns with the data provided in the references, which detail NASA's expenditures during the Apollo program from 1960 to 1973. Additionally, the context of NASA's budget peaking during this period further substantiates the claim. Therefore, the statement is factually correct based on the available evidence.", 'references': [{'url': 'https://en.wikipedia.org/wiki/Budget_of_NASA', 'keyQuote': "NASA's budget peaked in 1964–66 when it consumed roughly 4% of all federal spending. The agency was building up to the first Moon landing and the Apollo program was a top national priority, consuming more than half of NASA's budget.", 'isSupportive': True}, {'url': 'https://en.wikipedia.org/wiki/NASA', 'keyQuote': 'Established in 1958, it succeeded the National Advisory Committee for Aeronautics (NACA)', 'isSupportive': True}, {'url': 'https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo.html', 'keyQuote': 'More details on Apollo lunar landings', 'isSupportive': True}, {'url': 'https://usafacts.org/articles/50-years-after-apollo-11-moon-landing-heres-look-nasas-budget-throughout-its-history/', 'keyQuote': 'NASA has spent its money so far.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/history/', 'keyQuote': 'Discover the history of our human spaceflight, science, technology, and aeronautics programs.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/the-apollo-program/', 'keyQuote': 'Commander for Apollo 11, first to step on the lunar surface.', 'isSupportive': True}, {'url': 'https://www.planetary.org/space-policy/cost-of-apollo', 'keyQuote': 'A rich data set tracking the costs of Project Apollo, free for public use. Includes unprecedented program-by-program cost breakdowns.', 'isSupportive': True}, {'url': 'https://www.statista.com/statistics/1342862/nasa-budget-project-apollo-costs/', 'keyQuote': 'NASA's monetary obligations compared to Project Apollo's total costs from 1960 to 1973 (in million U.S. dollars)', 'isSupportive': True}], 'usage': {'tokens': 10640}}}Mit einem Faktualitätswert von 1 bestätigt die Grounding API, dass diese Aussage in historischen Fakten gut begründet ist. Dieser Ansatz eröffnet faszinierende Möglichkeiten, von der Analyse historischer Dokumente bis hin zur Echtzeitüberprüfung von Nachrichtenartikeln. Durch die Kombination von Zero-Shot-Klassifizierung mit Faktenüberprüfung schaffen wir eine leistungsfähige Pipeline für die automatisierte Informationsanalyse - zunächst werden Meinungen herausgefiltert, dann werden die verbleibenden Aussagen anhand vertrauenswürdiger Quellen überprüft.
tagAnmerkungen zur Zero-Shot-Klassifizierung
Verwendung semantischer Labels
Bei der Arbeit mit Zero-Shot-Klassifizierung ist es entscheidend, semantisch aussagekräftige Labels anstelle von abstrakten Symbolen oder Zahlen zu verwenden. Zum Beispiel sind "Technology", "Nature" und "Food" weitaus effektiver als "Class1", "Class2", "Class3" oder "0", "1", "2". "Positive sentiment" ist effektiver als "Positive" und "True". Embedding-Modelle verstehen semantische Beziehungen, daher ermöglichen beschreibende Labels dem Modell, sein vortrainiertes Wissen für genauere Klassifizierungen zu nutzen. Unser vorheriger Beitrag untersucht, wie man effektive semantische Labels für bessere Klassifizierungsergebnisse erstellt.

Zustandslose Natur
Zero-Shot-Klassifizierung ist grundsätzlich zustandslos, anders als traditionelle maschinelle Lernansätze. Das bedeutet, dass bei gleicher Eingabe und gleichem Modell die Ergebnisse immer konsistent sind, unabhängig davon, wer die API nutzt oder wann. Das Modell lernt oder aktualisiert sich nicht basierend auf den Klassifizierungen, die es durchführt; jede Aufgabe ist unabhängig. Dies ermöglicht die sofortige Nutzung ohne Einrichtung oder Training und bietet die Flexibilität, Kategorien zwischen API-Aufrufen zu ändern.
Diese Zustandslosigkeit steht in starkem Kontrast zu Few-Shot- und Online-Learning-Ansätzen, die wir als nächstes untersuchen werden. Bei diesen Methoden können sich Modelle an neue Beispiele anpassen und möglicherweise im Laufe der Zeit oder zwischen Benutzern unterschiedliche Ergebnisse liefern.
tagFew-Shot-Klassifizierung
Few-Shot-Klassifizierung bietet einen einfachen Ansatz zum Erstellen und Aktualisieren von Klassifizierern mit minimalen gelabelten Daten. Diese Methode stellt zwei primäre Endpunkte bereit: train und classify.
Der train-Endpunkt ermöglicht es Ihnen, einen Klassifizierer mit einer kleinen Menge von Beispielen zu erstellen oder zu aktualisieren. Ihr erster Aufruf von train wird eineclassifier_id, den Sie für nachfolgende Trainings verwenden können, wenn Sie neue Daten haben, Änderungen in der Datenverteilung bemerken oder neue Klassen hinzufügen müssen. Dieser flexible Ansatz ermöglicht es Ihrem Klassifizierer, sich im Laufe der Zeit weiterzuentwickeln und sich an neue Muster und Kategorien anzupassen, ohne von vorne beginnen zu müssen.
Ähnlich wie bei der Zero-Shot-Klassifizierung verwenden Sie den classify Endpunkt für Vorhersagen. Der Hauptunterschied besteht darin, dass Sie Ihre classifier_id in der Anfrage angeben müssen, aber keine Kandidaten-Labels bereitstellen müssen, da diese bereits Teil Ihres trainierten Modells sind.
tagBeispiel: Training eines Support-Ticket-Zuweisers
Lassen Sie uns diese Funktionen anhand eines Beispiels zur Klassifizierung von Kundenservice-Tickets für die Zuweisung an verschiedene Teams in einem schnell wachsenden Tech-Startup erkunden.
Initiales Training
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "I cant log into my account after the latest app update.",
"label": "team1"
},
{
"text": "My subscription renewal failed due to an expired credit card.",
"label": "team2"
},
{
"text": "How do I export my data from the platform?",
"label": "team3"
}
],
"num_iters": 10
}'Beachten Sie, dass wir beim Few-Shot-Learning team1 team2 als Klassenbezeichnungen verwenden können, auch wenn diese keine inhärente semantische Bedeutung haben. In der Antwort erhalten Sie eine classifier_id, die diesen neu erstellten Klassifizierer repräsentiert.
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3,
}
Notieren Sie sich die classifier_id, Sie werden sie später benötigen, um auf diesen Klassifizierer zu verweisen.
Aktualisierung des Klassifizierers zur Anpassung an Team-Umstrukturierungen
Während das Beispielunternehmen wächst, entstehen neue Arten von Problemen und auch die Teamstruktur ändert sich. Die Schönheit der Few-Shot-Klassifizierung liegt in ihrer Fähigkeit, sich schnell an diese Änderungen anzupassen. Wir können den Klassifizierer einfach aktualisieren, indem wir classifier_id und neue Beispiele angeben, neue Team-Kategorien einführen (z.B. team4) oder bestehende Problemtypen verschiedenen Teams neu zuweisen, während sich die Organisation weiterentwickelt.
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "Im getting a 404 error when trying to access the new AI chatbot feature.",
"label": "team4"
},
{
"text": "The latest security patch is conflicting with my company firewall.",
"label": "team1"
},
{
"text": "I need help setting up SSO for my organization account.",
"label": "team5"
}
],
"num_iters": 10
}'Verwendung eines trainierten Klassifizierers
Während der Inferenz müssen Sie nur den Eingabetext und die classifier_id bereitstellen. Die API übernimmt die Zuordnung zwischen Ihrer Eingabe und den zuvor trainierten Klassen und gibt das am besten geeignete Label basierend auf dem aktuellen Zustand des Klassifizierers zurück.
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "The new feature is causing my dashboard to load slowly."
},
{
"text": "I need to update my billing information for tax purposes."
}
]
}'Der Few-Shot-Modus hat zwei einzigartige Parameter.
tagParameter num_iters
Der Parameter num_iters bestimmt, wie intensiv der Klassifizierer aus Ihren Trainingsbeispielen lernt. Während der Standardwert von 10 für die meisten Fälle gut funktioniert, können Sie diesen Wert strategisch basierend auf Ihrem Vertrauen in die Trainingsdaten anpassen. Für qualitativ hochwertige Beispiele, die für die Klassifizierung wichtig sind, erhöhen Sie num_iters, um deren Bedeutung zu verstärken. Umgekehrt können Sie für weniger zuverlässige Beispiele num_iters senken, um deren Einfluss auf die Leistung des Klassifizierers zu minimieren. Dieser Parameter kann auch verwendet werden, um zeitbewusstes Lernen zu implementieren, bei dem aktuellere Beispiele höhere Iterationszahlen erhalten, um sich an sich entwickelnde Muster anzupassen, während historisches Wissen erhalten bleibt.
tagParameter access
Mit dem Parameter access können Sie steuern, wer Ihren Klassifizierer verwenden kann. Standardmäßig sind Klassifizierer privat und nur für Sie zugänglich. Wenn Sie den Zugriff auf "public" setzen, kann jeder mit Ihrer classifier_id den Klassifizierer mit seinem eigenen API-Schlüssel und Token-Kontingent verwenden. Dies ermöglicht das Teilen von Klassifizierern bei gleichzeitiger Wahrung der Privatsphäre - Benutzer können Ihre Trainingsdaten oder Konfiguration nicht sehen, und Sie können deren Klassifizierungsanfragen nicht sehen. Dieser Parameter ist nur für Few-Shot-Klassifizierung relevant, da Zero-Shot-Klassifizierer zustandslos sind. Es besteht keine Notwendigkeit, Zero-Shot-Klassifizierer zu teilen, da identische Anfragen immer die gleichen Antworten liefern, unabhängig davon, wer sie stellt.
tagAnmerkungen zum Few-Shot-Learning
Die Few-Shot-Klassifizierung in unserer API hat einige bemerkenswerte Eigenschaften. Im Gegensatz zu traditionellen Machine-Learning-Modellen verwendet unsere Implementierung One-Pass-Online-Learning - Trainingsbeispiele werden verarbeitet, um die Gewichte des Klassifizierers zu aktualisieren, werden aber danach nicht gespeichert. Dies bedeutet, dass Sie keine historischen Trainingsdaten abrufen können, aber es gewährleistet bessere Privatsphäre und Ressourceneffizienz.
Obwohl Few-Shot-Learning leistungsfähig ist, benötigt es eine Aufwärmphase, um die Zero-Shot-Klassifizierung zu übertreffen. Unsere Benchmarks zeigen, dass 200-400 Trainingsbeispiele typischerweise genügend Daten liefern, um eine überlegene Leistung zu sehen. Sie müssen jedoch nicht von Anfang an Beispiele für alle Klassen bereitstellen - der Klassifizierer kann mit der Zeit neue Klassen aufnehmen. Beachten Sie nur, dass neu hinzugefügte Klassen möglicherweise eine kurze Kaltstartphase oder Klassenungleichgewicht erfahren, bis ausreichend Beispiele bereitgestellt werden.
tagBenchmark
Für unsere Benchmark-Analyse haben wir Zero-Shot- und Few-Shot-Ansätze über verschiedene Datensätze hinweg evaluiert, einschließlich Textklassifizierungsaufgaben wie Emotionserkennung (6 Klassen) und Spam-Erkennung (2 Klassen) sowie Bildklassifizierungsaufgaben wie CIFAR10 (10 Klassen). Das Evaluierungsframework verwendete Standard-Train-Test-Splits, wobei Zero-Shot keine Trainingsdaten benötigte und Few-Shot Teile des Trainingssatzes verwendete. Wir verfolgten wichtige Metriken wie Trainingsgröße und Zielklassenanzahl, was kontrollierte Vergleiche ermöglichte. Um die Robustheit sicherzustellen, insbesondere beim Few-Shot-Learning, durchlief jede Eingabe mehrere Trainingsiterationen. Wir verglichen diese modernen Ansätze mit traditionellen Baselines wie Linear SVM und RBF SVM, um den Kontext ihrer Leistung zu verdeutlichen.



F1-Scores sind aufgetragen. Die vollständigen Benchmark-Einstellungen finden Sie in dieser Google-Tabelle.
Die F1-Diagramme zeigen interessante Muster über drei Aufgaben hinweg. Erwartungsgemäß zeigt die Zero-Shot-Klassifizierung von Anfang an konstante Leistung, unabhängig von der Trainingsdatenmenge. Im Gegensatz dazu weist Few-Shot-Learning eine schnelle Lernkurve auf, beginnt zunächst niedriger, übertrifft aber schnell die Zero-Shot-Leistung mit zunehmenden Trainingsdaten. Beide Methoden erreichen letztendlich eine vergleichbare Genauigkeit bei etwa 400 Proben, wobei Few-Shot einen leichten Vorsprung behält. Dieses Muster gilt sowohl für Mehrklassen- als auch für Bildklassifizierungsszenarien, was darauf hindeutet, dass Few-Shot-Learning besonders vorteilhaft sein kann, wenn Trainingsdaten verfügbar sind, während Zero-Shot auch ohne Trainingsbeispiele zuverlässige Leistung bietet. Die folgende Tabelle fasst die Unterschiede zwischen Zero-Shot- und Few-Shot-Klassifizierung aus Sicht des API-Benutzers zusammen.
| Feature | Zero-shot | Few-shot |
|---|---|---|
| Primary Use Case | Default solution for general classification | For data outside v3/clip-v1's domain or time-sensitive data |
| Training Data Required | No | Yes |
| Labels Required in /train | N/A | Yes |
| Labels Required in /classify | Yes | No |
| Classifier ID Required | No | Yes |
| Semantic Labels Required | Yes | No |
| State Management | Stateless | Stateful |
| Continuous Model Updates | No | Yes |
| Access Control | No | Yes |
| Maximum Classes | 256 | 16 |
| Maximum Classifiers | N/A | 16 |
| Maximum Inputs per Request | 1,024 | 1,024 |
| Maximum Token Length per Input | 8,192 tokens | 8,192 tokens |
tagZusammenfassung
Die Classifier API bietet leistungsstarke Zero-Shot- und Few-Shot-Klassifizierung sowohl für Text- als auch für Bildinhalte, angetrieben von fortschrittlichen Embedding-Modellen wie jina-embeddings-v3 und jina-clip-v1. Unsere Benchmarks zeigen, dass die Zero-Shot-Klassifizierung zuverlässige Leistung ohne Trainingsdaten bietet und damit ein ausgezeichneter Ausgangspunkt für die meisten Aufgaben mit Unterstützung für bis zu 256 Klassen ist. Während Few-Shot-Learning mit Trainingsdaten eine etwas bessere Genauigkeit erreichen kann, empfehlen wir, mit Zero-Shot-Klassifizierung zu beginnen, da sie sofortige Ergebnisse und Flexibilität bietet.
Die Vielseitigkeit der API unterstützt verschiedene Anwendungen, vom Routing von LLM-Anfragen bis zur Erkennung von Website-Zugänglichkeit und Kategorisierung mehrsprachiger Inhalte. Ob Sie mit Zero-Shot beginnen oder für spezielle Fälle zu Few-Shot-Learning übergehen, die API behält eine konsistente Schnittstelle für die nahtlose Integration in Ihre Pipeline bei. Wir sind besonders gespannt darauf zu sehen, wie Entwickler diese API in ihren Anwendungen einsetzen werden, und wir werden in Zukunft Unterstützung für neue Embedding-Modelle wie jina-clip-v2 einführen.




