


Gespräche über KI sind oft apokalyptisch. Ein Teil der Schuld liegt darin, wie apokalyptische Science-Fiction unser mentales Bild von künstlicher Intelligenz geprägt hat. Visionen von intelligenten Maschinen, die weitere Maschinen herstellen können, sind seit Generationen ein häufiges Motiv in der Science-Fiction.
Viele Menschen haben sich zu existenziellen Risiken durch die jüngsten Entwicklungen in der KI geäußert, viele davon Wirtschaftsführer, die an der Kommerzialisierung von KI beteiligt sind, und sogar einige Wissenschaftler und Forscher. Es ist zu einem Bestandteil des KI-Hypes geworden: Etwas, das mächtig genug ist, um nüchtern wirkende Ikonen aus Wissenschaft und Industrie über das Ende der Welt nachdenken zu lassen, muss sicherlich auch mächtig genug sein, um Profit zu machen, oder?
Sollten wir uns also Sorgen über existenzielle Risiken durch KI machen? Müssen wir befürchten, dass Sam Altman aus ChatGPT einen Ultron erschafft und dessen KI-Armee osteuropäische Städte auf uns wirft? Sollten wir uns Sorgen machen, dass Peter Thiels Palantir Skynet aufbaut und Roboter mit unerklärlichem österreichischem Akzent in die Vergangenheit schickt, um uns zu töten?
Wahrscheinlich nicht. Wirtschaftsführer haben bisher noch keinen klaren Weg gefunden, wie KI ihre eigenen Rechnungen bezahlen kann, geschweige denn Industrien durcheinanderbringen, und noch weniger die Menschheit in einem Ausmaß bedrohen kann, das mit dem Klimawandel oder Atomwaffen vergleichbar wäre.
Die KI-Modelle, die wir tatsächlich haben, sind kaum in der Lage, die Menschheit auszulöschen. Sie haben Schwierigkeiten, Hände zu zeichnen, können nicht mehr als drei Dinge zählen, denken, es sei in Ordnung, Menschen Käse zu verkaufen, an dem Ratten genagt haben, und führen katholische Taufen mit Gatorade durch. Die mundanen, nicht-existenziellen Risiken der KI – die Art und Weise, wie die Technologie dabei helfen kann, Fehlinformationen zu verbreiten, zu belästigen, Spam zu generieren und von Menschen, die sich ihrer Grenzen nicht bewusst sind, schlecht eingesetzt zu werden – sind besorgniserregend genug.
Aber ein existenzielles Risiko der künstlichen Intelligenz ist definitiv legitim: KI stellt eine klare und gegenwärtige Gefahr für... KI dar.
Diese Befürchtung wird normalerweise als "Model Collapse" bezeichnet und wurde in Shumailov et al. (2023) und Alemohammad et al. (2023) empirisch nachgewiesen. Die Idee ist einfach: Wenn man KI-Modelle mit KI-generierten Daten trainiert und dann die resultierende KI verwendet, um ein weiteres Modell zu trainieren, wobei dieser Prozess über mehrere Generationen wiederholt wird, wird die KI objektiv immer schlechter. Es ist wie eine Fotokopie einer Fotokopie einer Fotokopie.

In letzter Zeit gab es einige Diskussionen über den Model Collapse, und es erscheinen Schlagzeilen darüber, dass KI-Unternehmen die Trainingsdaten ausgehen. Wenn das Internet mit KI-generierten Daten überfüllt wird und von Menschen erstellte Daten schwieriger zu identifizieren und zu nutzen sind, werden KI-Modelle bald an eine Qualitätsgrenze stoßen.
Gleichzeitig gibt es eine zunehmende Verwendung von synthetischen Daten und Model Distillation Techniken in der KI-Entwicklung. Beide bestehen darin, KI-Modelle zumindest teilweise mit der Ausgabe anderer KI-Modelle zu trainieren. Diese beiden Trends scheinen sich zu widersprechen.
Die Dinge sind etwas komplizierter als das. Wird generative KI den Fortschritt durch Spam ersticken und seinen eigenen Fortschritt behindern? Oder wird KI uns helfen, bessere KI zu entwickeln? Oder beides?
Wir werden versuchen, in diesem Artikel einige Antworten zu finden.
tagModel Collapse
So sehr wir Alemohammad et al. dafür schätzen, dass sie den Begriff "Model Autophagy Disorder (MAD)" erfunden haben, "Model Collapse" ist viel eingängiger und kommt ohne griechische Wörter für Selbstkannibalismus aus. Die Metapher vom Anfertigen von Fotokopien von Fotokopien vermittelt das Problem in einfachen Worten, aber es steckt noch etwas mehr hinter der zugrunde liegenden Theorie.
Das Training eines KI-Modells ist eine Art der statistischen Modellierung, eine Erweiterung dessen, was Statistiker und Data Scientists schon lange tun. Aber am ersten Tag der Data Science-Klasse lernt man das Motto des Data Scientists:
Alle Modelle sind falsch, aber einige sind nützlich.
Dieses Zitat, das George Box zugeschrieben wird, ist das blinkende rote Licht, das über jedem KI-Modell stehen sollte. Man kann immer ein statistisches Modell für beliebige Daten erstellen, und dieses Modell wird immer eine Antwort geben, aber absolut nichts garantiert, dass diese Antwort richtig oder auch nur annähernd richtig ist.
Ein statistisches Modell ist eine Annäherung an etwas. Seine Ausgaben können nützlich sein, sie könnten sogar gut genug sein, aber es bleiben Annäherungen. Selbst wenn man ein gut validiertes Modell hat, das im Durchschnitt sehr genau ist, kann und wird es wahrscheinlich trotzdem manchmal große Fehler machen.
KI-Modelle erben alle Probleme der statistischen Modellierung. Jeder, der mit ChatGPT oder einem anderen großen KI-Modell gespielt hat, hat gesehen, wie es Fehler macht.
Wenn also ein KI-Modell eine Annäherung an etwas Reales ist, dann ist ein KI-Modell, das mit der Ausgabe eines anderen KI-Modells trainiert wurde, eine Annäherung an eine Annäherung. Die Fehler häufen sich, und es muss zwangsläufig ein weniger korrektes Modell sein als das Modell, von dem es trainiert wurde.
Alemohammad et al. zeigen, dass man das Problem nicht beheben kann, indem man einige der ursprünglichen Trainingsdaten zur KI-Ausgabe hinzufügt, bevor man das neue "Kind"-Modell trainiert. Das verlangsamt den Model Collapse nur, kann ihn aber nicht aufhalten. Wenn nicht genügend neue, bisher ungesehene Daten aus der realen Welt beim Training mit KI-Ausgabe eingeführt werden, ist der Model Collapse unvermeidlich.
Wie viele neue Daten ausreichend sind, hängt von schwer vorhersehbaren, fallspezifischen Faktoren ab, aber mehr neue, echte Daten und weniger KI-generierte Daten sind immer besser als das Gegenteil.
Und das ist ein Problem, weil alle leicht zugänglichen Quellen für neue, von Menschen erstellte Daten bereits ausgeschöpft sind, während die Menge an KI-generierten Bild- und Textdaten dort draußen sprunghaft zunimmt. Das Verhältnis von menschlich erstellten zu KI-erstellten Inhalten im Internet sinkt, möglicherweise sogar schnell. Es gibt keine zuverlässige Möglichkeit, KI-generierte Daten automatisch zu erkennen, und viele Forscher glauben, dass es keine geben kann. Der öffentliche Zugang zu KI-Bild- und Textgenerierungsmodellen sorgt dafür, dass dieses Problem wachsen wird, wahrscheinlich dramatisch wachsen wird, und keine offensichtliche Lösung hat.
Die Menge an maschineller Übersetzung im Internet könnte bedeuten, dass es bereits zu spät ist. Maschinell übersetzte Texte im Internet verschmutzen unsere Datenquellen schon seit Jahren, lange vor der generativen KI-Revolution. Laut Thompson et al., 2024 könnte möglicherweise die Hälfte der Texte im Internet aus einer anderen Sprache übersetzt sein, und ein sehr großer Teil dieser Übersetzungen ist von schlechter Qualität und zeigt Anzeichen maschineller Erzeugung. Dies kann ein Sprachmodell, das mit solchen Daten trainiert wurde, verzerren.
Als Beispiel sehen Sie unten einen Screenshot von einer Seite der Website Die Welt der Habsburger, der deutliche Anzeichen maschineller Übersetzung zeigt. "Hamster buying" ist eine zu wörtliche Übersetzung des deutschen Wortes hamstern, das to hoard oder panic-buying bedeutet. Zu viele solcher Fälle werden dazu führen, dass ein KI-Modell denkt, "hamster buying" sei eine echte Sache im Englischen und das deutsche hamstern hätte etwas mit Haustierhamstern zu tun.

In fast allen Fällen ist es schlecht, mehr KI-Output in Ihren Trainingsdaten zu haben. Das fast ist wichtig, und wir werden unten zwei Ausnahmen besprechen.
tagSynthetische Daten
Synthetische Daten sind KI-Trainings- oder Evaluierungsdaten, die künstlich erzeugt wurden, anstatt in der realen Welt gefunden zu werden. Nikolenko (2021) datiert synthetische Daten zurück zu frühen Computer-Vision-Projekten in den 1960er Jahren und skizziert ihre Geschichte als wichtiges Element dieses Feldes.
Es gibt viele Gründe, synthetische Daten zu verwenden. Einer der wichtigsten ist die Bekämpfung von Voreingenommenheit.
Große Sprachmodelle und Bildgeneratoren haben viele bekannte Beschwerden über Voreingenommenheit erhalten. Das Wort Voreingenommenheit hat eine strenge Bedeutung in der Statistik, aber diese Beschwerden spiegeln oft moralische, soziale und politische Überlegungen wider, die keine einfache mathematische Form oder technische Lösung haben.
Die Voreingenommenheit, die man nicht leicht sieht, ist weitaus schädlicher und viel schwieriger zu beheben. Die Muster, die KI-Modelle lernen zu replizieren, sind diejenigen, die in ihren Trainingsdaten zu sehen sind, und wo diese Daten systematische Mängel aufweisen, ist Voreingenommenheit eine unvermeidliche Folge. Je mehr verschiedene Dinge wir von KI erwarten - je vielfältiger die Eingaben für das Modell - desto größer ist die Chance, dass es etwas falsch macht, weil es nie genug ähnliche Fälle in seinem Training gesehen hat.
Die Hauptrolle synthetischer Daten im KI-Training heute besteht darin, genügend Beispiele für bestimmte Arten von Situationen in den Trainingsdaten zu gewährleisten, Situationen, die in verfügbaren natürlichen Daten möglicherweise nicht ausreichend vorhanden sind.
Unten ist ein Bild, das MidJourney produzierte, als es mit "doctor" aufgefordert wurde: vier Männer, drei weiß, drei in weißen Kitteln mit Stethoskopen, und einer tatsächlich alt. Dies spiegelt nicht die tatsächliche Rasse, das Alter, das Geschlecht oder die Kleidung echter Ärzte in den meisten Ländern und Kontexten wider, ist aber wahrscheinlich ein Spiegelbild der beschrifteten Bilder, die man im Internet findet.

Bei erneuter Aufforderung produzierte es eine Frau und drei Männer, alle weiß, obwohl einer ein Cartoon ist. KI kann seltsam sein.

Diese besondere Art von Voreingenommenheit ist eine, die KI-Bildgeneratoren zu verhindern versuchen, sodass wir nicht mehr so deutlich voreingenommene Ergebnisse erhalten wie vielleicht noch vor einem Jahr von denselben Systemen. Eine Voreingenommenheit ist sichtbar noch vorhanden, aber es ist nicht offensichtlich, wie ein unvoreingenommenes Ergebnis aussehen würde.
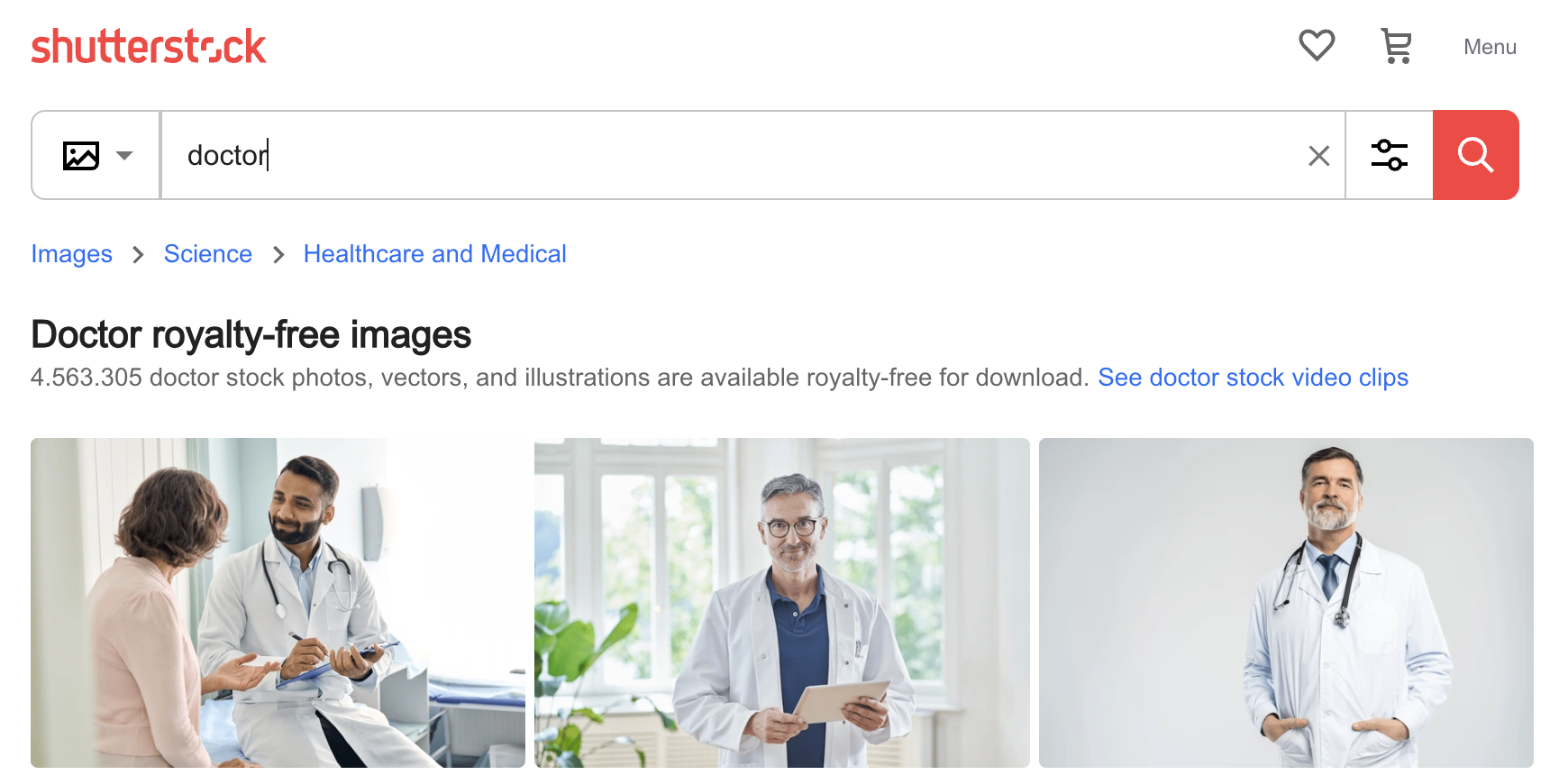
Dennoch ist es nicht schwer zu erkennen, wie eine KI diese Art von Vorurteilen entwickeln könnte. Unten sind die ersten drei Bilder für "doctor" auf der Shutterstock-Foto-Website: Drei Männer, zwei älter und weiß. Die Vorurteile der KI sind die Vorurteile ihres Trainings, und wenn Sie Modelle mit unkurierten Daten trainieren, werden Sie immer diese Art von Voreingenommenheit finden.
Eine Möglichkeit, dieses Problem zu mindern, besteht darin, einen KI-Bildgenerator zu verwenden, um Bilder von jüngeren Ärzten, Ärztinnen, Ärzten verschiedener Hautfarben und Ärzten in OP-Kleidung, Anzügen oder anderer Kleidung zu erstellen und diese dann ins Training einzubeziehen. Auf diese Weise verwendete synthetische Daten können die KI-Modellleistung verbessern, zumindest in Bezug auf eine externe Norm, anstatt zum Modellkollaps zu führen. Allerdings kann die künstliche Verzerrung von Trainingsdatenverteilungen unbeabsichtigte Nebenwirkungen haben, wie Google kürzlich feststellte.
tagModelldestillation
Modelldestillation ist eine Technik zum direkten Training eines Modells von einem anderen. Ein trainiertes generatives Modell - der "Lehrer" - erstellt so viele Daten wie nötig, um ein untrainiertes oder weniger trainiertes "Schüler"-Modell zu trainieren.
Wie zu erwarten, kann das "Schüler"-Modell nie besser sein als der "Lehrer". Auf den ersten Blick erscheint es wenig sinnvoll, ein Modell auf diese Weise zu trainieren, aber es gibt Vorteile. Der wichtigste ist, dass das "Schüler"-Modell viel kleiner, schneller oder effizienter sein kann als der "Lehrer", während es seine Leistung immer noch eng approximiert.
Die Beziehung zwischen Modellgröße, Trainingsdaten und endgültiger Leistung ist kompliziert. Im Großen und Ganzen gilt jedoch unter sonst gleichen Bedingungen:
- Ein größeres Modell leistet mehr als ein kleines.
- Ein Modell, das mit mehr oder besseren Trainingsdaten (oder zumindest vielfältigeren Trainingsdaten) trainiert wurde, leistet mehr als eines mit weniger oder schlechteren Daten.
Dies bedeutet, dass ein kleines Modell manchmal genauso gut funktionieren kann wie ein großes. Zum Beispiel übertrifft jina-embeddings-v2-base-en viele viel größere Modelle bei Standard-Benchmarks deutlich:
| Model | Size in parameters | MTEB average score |
|---|---|---|
| jina-embeddings-v2-base-en | 137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |

| Model | BEIR Score | Parameter count | |
|---|---|---|---|
| jina-reranker-v1-base-en | 52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en | 49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en | 48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |
