


Recientemente se ha escrito mucho sobre los peligros de las empresas de IA que absorben todos los datos de internet, tengan o no "permiso" para hacerlo. Hablaremos del "permiso" más adelante - hay una razón por la que pusimos la palabra entre comillas. Pero ¿qué significa para los LLMs cuando la web abierta ha sido completamente explotada, los proveedores de contenido han cerrado sus puertas, y apenas queda un goteo de nuevos datos para extraer?
tagLos Peligros del Scraping de IA
Las empresas de IA están tratando a internet como un buffet de datos libre, sin preocuparse por los modales. Solo hay que ver cómo Runway extrajo videos de YouTube para entrenar su modelo (contra los términos de servicio de YouTube), Anthropic golpeó a iFixit un millón de veces al día y el New York Times demandó a OpenAI y Microsoft por el uso de obras protegidas por derechos de autor.
Intentar bloquear scrapers en tu robots.txt o términos de servicio no ayuda realmente de ninguna manera. Los scrapers que no les importa seguirán extrayendo datos de todos modos, mientras que los más considerados serán bloqueados. No hay incentivo para que ningún scraper juegue limpio. Podemos ver esto en acción en el reciente artículo de la Data Provenance Initiative:
Esto no es solo un problema abstracto - iFixit pierde dinero y tiene sus recursos de DevOps comprometidos. ReadTheDocs acumuló más de $5,000 en cargos de ancho de banda en solo un mes, con casi 10 TB en un solo día, debido a rastreadores abusivos. Si administras un sitio web y te golpea un rastreador que no sigue las reglas, eso podría significar el fin.
Entonces, ¿qué puede hacer un sitio web? Si las empresas de IA no van a seguir las reglas, espera que aparezcan muros de pago y que el contenido de libre acceso disminuya. La web gratuita ya no existe. Todo lo que queda es pagar para jugar.
tag¿Es Legal el Scraping?
¿Es problemático el scraping? Sí. ¿Es legal? También sí. El web scraping es legal en los Estados Unidos, la Unión Europea, Japón, Corea del Sur y Canadá. Ningún país parece tener leyes que aborden específicamente esta práctica, pero los tribunales de todo el mundo generalmente están de acuerdo en que es legal usar la automatización para visitar sitios web que están abiertos para que cualquiera los vea y hacer copias privadas de su contenido.
La gente a veces cree que colocando algún aviso impreso en una página web o en un archivo robots.txt, pueden prohibir el scraping u otros usos legales de su sitio web y su contenido. Esto realmente no funciona. Los avisos como ese no tienen significado legal, y robots.txt es una convención IETF que no tiene fuerza de ley. Sin algún acto de confirmación, como mínimo hacer clic en el botón marcado "Acepto los Términos de Servicio", no puedes imponer condiciones a los visitantes de tu sitio web, e incluso entonces son frecuentemente legalmente inaplicables.
 Joshua J. Kaufman
Joshua J. KaufmanSin embargo, aunque el scraping es legal, hay algunas limitaciones:
- Las prácticas que podrían reducir la usabilidad de un sitio web para otros, como golpearlo demasiado a menudo o demasiado rápido con tu web-scraper, pueden tener consecuencias civiles o incluso penales en casos extremos.
- Muchos países tienen leyes que penalizan el acceso no autorizado a computadoras. Si hay partes de un sitio web que claramente no están destinadas a ser accedidas por el público en general, puede ser ilegal extraerlas.
- Muchos países tienen leyes que hacen ilegal eludir las tecnologías anti-copia. Si un sitio web ha implementado medidas para evitar que descargues algún contenido, podrías estar infringiendo la ley si lo extraes de todos modos.
- Los sitios web que tienen términos de servicio explícitos, y requieren que confirmes tu aceptación de los mismos, pueden prohibir el scraping y llevarte a la corte si lo haces, pero los resultados son irregulares.
En los Estados Unidos, no hay una ley explícita sobre el scraping, pero los intentos de usar la Ley de Fraude y Abuso Informático de 1986 para prohibirlo han fallado, más recientemente en el caso del Noveno Circuito hiQ Labs v. LinkedIn en 2019. La ley estadounidense es compleja, con muchas distinciones hechas por los tribunales y un sistema de jurisdicciones estatales y federales que significa que a menos que la Corte Suprema se pronuncie sobre algo, no es necesariamente definitivo. (Y a veces no es definitivo incluso entonces.)
La UE tampoco tiene leyes específicas que aborden el scraping, pero ha sido una práctica común y no cuestionada durante mucho tiempo. La cláusula de Minería de Textos y Datos en la Directiva de Derechos de Autor de 2019 de la UE implica fuertemente que el scraping es generalmente legal.
Los mayores problemas legales no están en el acto de scraping sino en lo que sucede después de extraer los datos. Los derechos de autor siguen aplicándose a los datos que extraes de la web. Puedes mantener una copia personal, pero no puedes redistribuirla o revenderla, no sin algún potencial de problemas legales.
Realizar web scraping a gran escala casi siempre significa hacer copias de "datos personales", según lo definido en varias leyes de protección de datos y privacidad. El GDPR europeo (Reglamento General de Protección de Datos) define "datos personales" como:
[C]ualquier información relativa a una persona física identificada o identificable ('interesado'); se considerará persona física identificable toda persona cuya identidad pueda determinarse, directa o indirectamente, en particular mediante un identificador, como por ejemplo un nombre, un número de identificación, datos de localización, un identificador en línea o uno o varios elementos propios de la identidad física, fisiológica, genética, psíquica, económica, cultural o social de dicha persona;
[GDPR, Art. 4.1]
Si posees un almacén de datos personales relacionados con cualquier persona que resida en la UE o actividad que tenga lugar en la UE, tienes responsabilidades legales bajo el GDPR. Su alcance es tan amplio que deberías asumir que es cierto para cualquier gran colección de datos. No importa si recopilaste los datos o lo hizo alguien más, si los tienes ahora, eres responsable de ellos. Si no cumples con tus obligaciones del GDPR, la UE puede castigarte independientemente del país en el que vivas o donde se almacenen o procesen los datos.
La PIPEDA de Canadá (Ley de Protección de Información Personal y Documentos Electrónicos) es similar al GDPR. La APPI de Japón (Ley de Protección de Información Personal) cubre gran parte del mismo terreno. El Reino Unido incorporó la mayoría de los elementos del GDPR en sus leyes nacionales al salir de la UE, y a menos que se modifiquen más tarde, todavía están en vigor.
Estados Unidos no tiene una ley de protección de datos comparable a nivel federal, pero la CCPA (Ley de Privacidad del Consumidor de California) tiene términos similares al GDPR y se aplica si tienes datos sobre personas o actividades en el estado de California.
La mayoría de los países desarrollados tienen leyes de protección de datos que limitan, al menos en algunos aspectos, lo que puedes hacer con colecciones masivas de datos de la web. La mayoría de los procedimientos legales en todo el mundo relacionados con el scraping han sido sobre cómo se usaron los datos, no sobre cómo se recopilaron.
Así que el web scraping casi siempre es legal. Es lo que sucede después lo que se complica.
tag¿Es Legal Entrenar IA a partir del Scraping?
Probablemente.
Un web scrape incluirá, en casi todos los casos realistas, contenido protegido por derechos de autor. La verdadera pregunta es: ¿Puedes usar contenido protegido por derechos de autor para entrenar una IA sin permiso del propietario?
Hay muchos puntos legales individuales que no están completamente resueltos, pero:
- En Europa, el Artículo 4 de la Directiva de Derechos de Autor de la UE de 2019 parece hacerlo legal con algunas advertencias.
- En Japón, el Artículo 30(4) de la Ley de Derechos de Autor, modificada en 2018, se ha interpretado como permitir el uso de obras con derechos de autor para entrenar IA sin permiso.
- En Estados Unidos, ninguna ley aborda específicamente esta situación, sin embargo, durante muchos años se ha dado por sentado que el análisis estadístico de materiales con derechos de autor es legal, incluso cuando el resultado es un producto comercial. Aunque las demandas Authors Guild, Inc. v. Google, Inc. y Authors Guild, Inc. v. HathiTrust no abordan específicamente la IA, amplían el alcance del "uso justo" bajo la ley estadounidense de manera tan amplia que es difícil ver cómo el entrenamiento de IA podría ser ilegal. El sistema legal estadounidense no ofrece una respuesta explícita y varios casos que ponen a prueba esta conclusión están avanzando en los tribunales.
Varias jurisdicciones más pequeñas también han determinado que es legal, y hasta donde sé, ninguna ha determinado que sea ilegal hasta la fecha.
La ley europea de derechos de autor permite a los propietarios de datos con derechos de autor restringir el uso de sus obras para el entrenamiento de IA indicándolo "de manera apropiada". Actualmente no hay orientación sobre cómo deberían hacerlo.
La ley japonesa de derechos de autor limita el uso de materiales protegidos cuando podría "perjudicar injustificadamente los intereses del titular de los derechos". Esto típicamente indica que un titular de derechos tendría que demostrar cómo un modelo específico de IA reduce el valor económico de su trabajo para poder presentar un caso.
Debemos señalar que Google, Microsoft, OpenAI, Adobe, y Shutterstock han ofrecido indemnizar a cualquier usuario de sus productos de IA generativa que enfrente un desafío legal por motivos de derechos de autor. Esto es una fuerte indicación de que sus abogados piensan que lo que están haciendo es legal bajo la ley estadounidense.
tagLo que Significa el Scraping Voraz para la IA
La bonanza del scraping de IA está convirtiendo la web en un Salvaje Oeste digital. Estos scrapers están tratando el robots.txt como si fuera cosa del pasado, bombardeando sitios web como iFixit con infinitas solicitudes. No es solo molesto - es potencialmente destructivo para la web y nos está obligando a repensar cómo funciona el internet abierto. O cómo podría dejar de funcionar en un futuro cercano. Solo desde un punto de vista económico y social, hay muchas cosas que podrían cambiar:
Ruptura de la confianza: Este frenesí de alimentación de IA podría llevar a una ruptura masiva de la confianza en toda la web. Imagina un futuro donde cada sitio web te recibe con una mirada escéptica, obligándote a probar que eres humano antes de que puedas siquiera echar un vistazo a su contenido. Hablamos de más CAPTCHAs, más muros de inicio de sesión, más pruebas de "haz clic en todos los semáforos". Es como intentar entrar en un bar clandestino, pero en lugar de una contraseña secreta, necesitas convencer al portero de que no eres una máquina muy inteligente.
Contenido generado por humanos limitado: Los creadores de contenido, ya recelosos de que su trabajo sea robado, están empezando a cerrar las escotillas. Podríamos ver un aumento en los muros de pago, secciones solo para suscriptores y bloqueos de contenido. Los días de navegar y aprender libremente podrían convertirse en un recuerdo nostálgico, como los sonidos del módem de marcación o los mensajes de ausencia de AIM. Si los humanos ordinarios no pueden acceder a él, es mucho más difícil que un scraper rebelde entre.
Casos legales: Pueden pasar años o incluso décadas antes de que se resuelvan todos los problemas legales relacionados con la IA. Hemos tenido Internet durante unos treinta años, y algunos de sus problemas legales siguen sin resolverse hoy. Ya sea que tengas razón o no, si no puedes permitirte pasar años en los tribunales averiguando qué está permitido y qué no, tienes algo de qué preocuparte.
Los pequeños se arruinan, los gordos engordan: Este frenesí de scraping no es solo una molestia - está poniendo una tensión real en la infraestructura web. Los sitios que lidian con atascos de tráfico inducidos por IA podrían necesitar actualizarse a servidores más potentes, lo cual no es barato. Los sitios más pequeños y los proyectos pasionales interesantes podrían quedar fuera del juego, dejándonos con una web (y datos de entrenamiento de LLM) dominada por aquellos lo suficientemente grandes como para capear el temporal o firmar acuerdos de licencia con las empresas de IA. Es un escenario de "supervivencia del más rico" que podría hacer que internet (y el conocimiento de LLM) sea mucho menos diverso e interesante. Al cerrar la puerta a los datos disponibles gratuitamente, pueden entonces cobrar una tarifa de entrada a las corporaciones de IA, o simplemente licenciar al mejor postor. ¿No tienes el dinero? El portero te mostrará la puerta.
tag¿Los Datos Generados por IA al Rescate?
La captura de datos no solo está sacudiendo los sitios web - está preparando el escenario para una potencial sequía de conocimiento en IA. A medida que la web abierta levanta sus puentes levadizos, los modelos de IA se encontrarán hambrientos de datos frescos y de alta calidad.
Esta escasez de datos podría llevar a un caso desagradable de visión túnel en la IA. Sin un flujo constante de nueva información, los modelos de IA corren el riesgo de convertirse en cámaras de eco de conocimiento obsoleto. Imagina preguntarle a una IA sobre eventos actuales y recibir respuestas que suenan como si fueran del año pasado - o peor, de un universo paralelo donde los hechos se tomaron vacaciones.
Si los datos generados por humanos están bajo llave, las empresas aún tienen que obtener sus datos de entrenamiento de algún lugar. Un ejemplo de esto son los datos sintéticos: Datos creados por LLMs para entrenar otros LLMs. Esto incluye técnicas ampliamente utilizadas como la destilación de modelos y la generación de datos de entrenamiento para compensar el sesgo.

Usar datos sintéticos significa no tener que pasar por el aro para licenciar datos generados por humanos, lo cual como hemos visto se está volviendo cada vez más difícil. También ayuda a equilibrar las cosas - muchos datos en internet no representan la diversidad del mundo real. Generar datos sintéticos puede ayudar a hacer un modelo más representativo de la realidad (o a veces no). Finalmente, para los casos de uso de salud y legales, los datos sintéticos eliminan la necesidad de sanitizar datos para eliminar información personalmente identificable.
Sin embargo, el reverso de la moneda es que los modelos futuros también serán entrenados con datos generados por IA que realmente no quieres que estén entrenándolos, específicamente el "Slop": datos de baja calidad generados por IA, como un blog de tecnología antes amado que ahora publica artículos de bajo valor generados por IA bajo los nombres de su antiguo personal, recetas generadas por IA para platos improbables como mojitos en olla de cocción lenta y helado de salchicha bratwurst, o Shrimp Jesus tomando el control de Facebook.
Dado que esto es mucho más barato y fácil de crear que el buen contenido artesanal de toda la vida, está inundando rápidamente internet.
Basándonos en lo que vemos hoy, el contenido generado por IA está superando al contenido disponible generado por humanos. GPT-5 será entrenado (en parte) con datos creados por GPT-4. GPT-6, a su vez, será entrenado con datos creados por GPT-5. Y así sucesivamente.
tagEl Colapso del Modelo, y Cómo Evitarlo
Usar tus propios resultados como entradas es malo tanto para humanos como para LLMs. Incluso si eres muy selectivo sobre cuántos datos sintéticos usas y de qué tipo, no puedes garantizar que tu modelo no empeorará
Para los modelos de IA generativa en general, la caída en calidad y diversidad de salida es experimentalmente medible y ocurre bastante rápido. Los modelos de generación de imágenes desarrollan anomalías después de algunas generaciones, y en un artículo, un modelo de lenguaje grande entrenado con datos de Wikipedia que daba respuestas coherentes y precisas a las indicaciones, para la novena generación de entrenamiento con su propia salida, respondía a las indicaciones repitiendo las palabras "liebres de cola" una y otra vez.
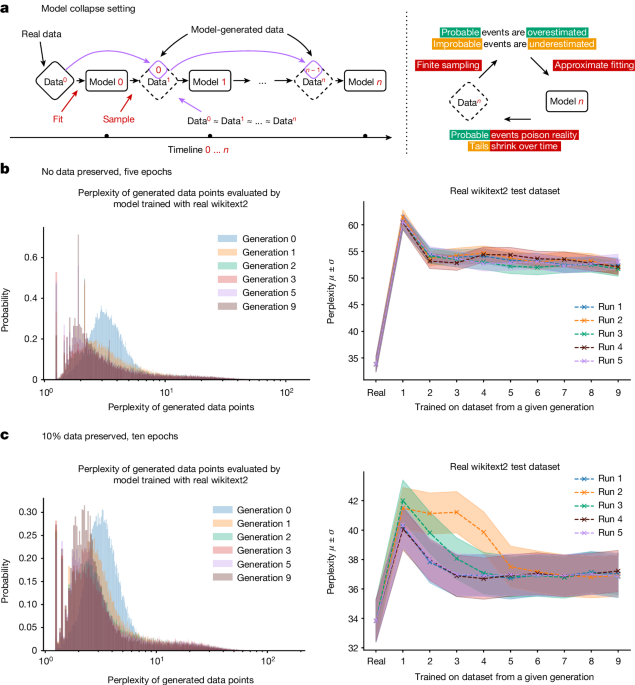
Esto es bastante fácil de explicar: Un modelo de IA es una aproximación de sus datos de entrenamiento. Un modelo de IA entrenado con la salida de otro modelo de IA es una aproximación de una aproximación. En cada ciclo de entrenamiento, la diferencia entre la aproximación y los datos "verdaderos" del mundo real se hace cada vez más grande.
A esto lo llamamos "colapso del modelo".
A medida que los datos generados por IA se vuelven cada vez más generalizados, entrenar nuevos modelos con datos extraídos de Internet arriesga reducir el rendimiento del modelo. Tenemos razones para pensar que mientras la cantidad de datos reales, hechos por humanos, no disminuya, nuestros modelos no empeorarán mucho, pero tampoco mejorarán. Sin embargo, tardarán más en entrenarse si no podemos separar los datos creados por IA de los datos creados por humanos. Los nuevos modelos serán más costosos de crear, sin mejorar.
La ironía aquí es considerable. El voraz apetito de la IA por los datos podría conducir a una hambruna de datos. El Trastorno de Autofagia del Modelo es como la Enfermedad de las Vacas Locas para la IA: Al igual que alimentar a las vacas con desechos de carne llevó a un nuevo tipo de enfermedad cerebral parasitaria, entrenar IA con cantidades crecientes de salida de IA conduce a patologías mentales devastadoras.
La buena noticia es que la IA no puede permitirse reemplazar a la humanidad porque necesita nuestros datos. La mala noticia es que puede frenar su propio crecimiento al arruinar sus fuentes de datos.
Para evitar esta previsible hambruna de conocimiento de IA, necesitamos repensar cómo entrenamos y usamos los modelos de IA. Ya estamos viendo soluciones como la Generación Aumentada por Recuperación, que intenta evitar usar modelos de IA como fuente de información factual y los ve en cambio como dispositivos para evaluar y reorganizar fuentes de información externas. Otro camino a seguir es a través de la especialización, donde adaptamos los modelos para realizar clases específicas de tareas, usando datos de entrenamiento curados enfocados en dominios estrechos. Podríamos reemplazar los supuestos modelos de propósito general como ChatGPT con IAs especializadas: LawLLM, MedLLM, MyLittlePonyLLM, y así sucesivamente.
Hay otras posibilidades, y es difícil decir qué nuevas técnicas descubrirán los investigadores. Tal vez haya una mejor manera de generar datos sintéticos o formas de obtener mejores modelos con menos datos. Pero no hay garantía de que más investigación resolverá el problema.
Al final, este desafío podría forzar a la comunidad de IA a ser creativa. Después de todo, la necesidad es la madre de la invención, y un panorama de IA hambriento de datos podría desencadenar algunas soluciones verdaderamente innovadoras. ¿Quién sabe? El próximo gran avance en IA podría venir no de más datos, sino de descubrir cómo hacer más con menos.
tag¿Qué Sucede Si Solo las Megacorporaciones Pueden Permitirse el Raspado?
Para mucha gente hoy en día, internet es Facebook, Instagram y X, vistos a través de un rectángulo de vidrio negro que sostienen en su mano. Está homogeneizado, es "seguro" y está controlado por guardianes que deciden (a través de políticas y sus algoritmos) qué (y a quién) ves y qué no.
No siempre fue así. Hace apenas un par de décadas teníamos blogs generados por usuarios, sitios web independientes y mucho más. En los ochenta, había docenas de sistemas operativos y estándares de hardware compitiendo. Pero para la década de 2010, Apple y Microsoft habían ganado la partida, iniciando la tendencia de homogeneización.
Vemos lo mismo con los navegadores web, los smartphones y las redes sociales. Comenzamos con una explosión de diversidad y nuevas ideas antes de que los grandes jugadores acaparen la pelota y dificulten que cualquier otro pueda jugar.
Dicho esto, aunque esos jugadores sí tenían un monopolio, algunos peces pequeños se colaron de todos modos. (Tomen Linux y Firefox, por ejemplo). Es poco probable que "el éxito del desvalido" suceda con los LLMs. Cuando los pequeños jugadores carecen del poder financiero para acceder a datos de entrenamiento variados y actualizados, no pueden crear modelos de alta calidad. Y sin eso, ¿cómo pueden mantenerse en el negocio?
Los gigantes tienen los recursos para mantener sus modelos de IA alimentándose de una dieta constante de información fresca, incluso mientras la web en general se aprieta el cinturón. Mientras tanto, los jugadores más pequeños y las startups se quedan raspando el fondo del barril de datos, luchando por nutrir sus algoritmos con migajas rancias. Es una brecha de conocimiento que podría crecer como bola de nieve. A medida que los ricos en datos se vuelven más ricos en perspectivas y capacidades, los pobres en datos corren el riesgo de quedarse más atrás, con sus IAs volviéndose más obsoletas y menos competitivas día a día. Esto no se trata solo de quién tiene los juguetes de IA más brillantes - se trata de quién llega a dar forma al futuro de la tecnología, el comercio e incluso cómo accedemos a la información. Estamos mirando hacia un futuro donde un puñado de gigantes tecnológicos podría tener las llaves de los reinos de IA más avanzados, mientras todos los demás se quedan mirando desde la edad oscura digital.
Con todo el contenido jugoso flotando alrededor para ser licenciado, es poco probable que una Megacorporación sea la única que lo licencie todo, como Netflix en los viejos tiempos. ¿Recuerdan eso? Te suscribías a un servicio y obtenías todos los programas que alguna vez soñaste. Hoy, los programas están dispersos entre Hulu, Netflix, Disney+ y como sea que estén llamando a HBO Max esta semana. A veces un programa que amas puede simplemente evaporarse en el éter. Este podría ser el futuro de los LLMs: Google tiene acceso prioritario a Reddit, mientras que OpenAI obtiene acceso al Financial Times. ¿iFixit? Esos datos simplemente ya no existen, meramente almacenados como algunos embeddings polvorientos, y nunca actualizados. En lugar de un modelo para gobernarlos a todos, podríamos estar mirando hacia la fragmentación y capacidades cambiantes mientras los derechos de licencia se malabarizan entre proveedores de IA.
tagEn Conclusión
El scraping llegó para quedarse, nos guste o no. Los proveedores de contenido ya están erigiendo barreras para limitar el acceso, mientras abren las puertas solo a quienes pueden permitirse licenciar el contenido. Esto limita severamente los recursos de los que cualquier LLM puede aprender, mientras que, al mismo tiempo, las empresas más pequeñas están quedando fuera de la guerra de ofertas por contenido lucrativo, y el resto del botín se está repartiendo entre los LLMs de los gigantes tecnológicos. Es el mundo del streaming post-Netflix otra vez, solo que esta vez es por el conocimiento.
Mientras los datos generados por humanos disminuyen, la "bazofia" generada por IA está en auge. Entrenar modelos con esto puede llevar a una desaceleración en la mejora o incluso al colapso del modelo. La única manera de arreglarlo es pensando fuera de la caja - algo para lo que las startups, con su cultura de innovación y disrupción, están idealmente preparadas. Sin embargo, los mismos datos que se están licenciando solo a los grandes jugadores son el sustento vital que estas startups necesitan para sobrevivir.
Al limitar el acceso justo a los datos, las mega-corporaciones no solo están sofocando la competencia - están estrangulando el futuro de la IA en sí, asfixiando la misma innovación que podría impulsarnos más allá de esta potencial era oscura digital.
La revolución de la IA no es el futuro, la IA es ahora. En palabras de William Gibson: "[E]l futuro ya está aquí, solo que no está distribuido uniformemente". Puede fácilmente volverse aún más desigualmente distribuido.





