


En nuestros posts anteriores, exploramos los desafíos del chunking e introdujimos el concepto de late chunking, que ayuda a reducir la pérdida de contexto al embedar chunks. En este post, nos centraremos en otro desafío: encontrar puntos de corte óptimos. Si bien nuestra estrategia de late chunking ha demostrado ser bastante resiliente a límites deficientes, esto no significa que podamos ignorarlos—siguen siendo importantes tanto para la legibilidad humana como para los LLM. Nuestra perspectiva es esta: al determinar los puntos de corte, ahora podemos concentrarnos completamente en la legibilidad sin preocuparnos por la pérdida semántica o de contexto. El late chunking puede manejar tanto buenos como malos puntos de corte, por lo que la legibilidad se convierte en tu principal preocupación.
Con esto en mente, entrenamos tres modelos de lenguaje pequeños específicamente diseñados para segmentar documentos largos mientras mantienen la coherencia semántica y manejan estructuras de contenido complejas. Estos son:

simple-qwen-0.5, que segmenta el texto basándose en los elementos estructurales del documento.

topic-qwen-0.5, que segmenta el texto basándose en los temas dentro del texto.

summary-qwen-0.5, que genera resúmenes para cada segmento.
En este post, discutiremos por qué desarrollamos este modelo, cómo abordamos sus tres variantes y cómo se comparan con la API Segmenter de Jina AI. Finalmente, compartiremos lo que hemos aprendido y algunas reflexiones para el futuro.
tagProblema de Segmentación
La segmentación es un elemento central en los sistemas RAG. La forma en que dividimos documentos largos en segmentos coherentes y manejables afecta directamente la calidad tanto de los pasos de recuperación como de generación, influyendo en todo, desde la relevancia de las respuestas hasta la calidad de la sumarización. Los métodos tradicionales de segmentación han producido resultados decentes pero no están exentos de limitaciones.
Parafraseando nuestro post anterior:
Al segmentar un documento largo, un desafío clave es decidir dónde crear los segmentos. Esto puede hacerse usando longitudes fijas de tokens, un número determinado de oraciones, o métodos más avanzados como regex y modelos de segmentación semántica. Establecer límites precisos de segmentos es crucial, ya que no solo mejora la legibilidad de los resultados de búsqueda sino que también asegura que los segmentos proporcionados a un LLM en un sistema RAG sean tanto precisos como suficientes.
Si bien el late chunking mejora el rendimiento de recuperación, en aplicaciones RAG, es crucial asegurar que, en la medida de lo posible, cada segmento sea significativo por sí mismo, y no solo un fragmento aleatorio de texto. Los LLM dependen de datos coherentes y bien estructurados para generar respuestas precisas. Si los segmentos están incompletos o carecen de significado, el LLM puede tener dificultades con el contexto y la precisión, afectando el rendimiento general a pesar de los beneficios del late chunking. En resumen, ya sea que uses o no late chunking, tener una estrategia sólida de segmentación es esencial para construir un sistema RAG efectivo (como verás en la sección de benchmark más adelante).
Los métodos tradicionales de segmentación, ya sea dividiendo el contenido en límites simples como nuevas líneas u oraciones, o usando reglas rígidas basadas en tokens, a menudo enfrentan las mismas limitaciones. Ambos enfoques fallan en tener en cuenta los límites semánticos y tienen dificultades con temas ambiguos, llevando a segmentos fragmentados. Para abordar estos desafíos, desarrollamos y entrenamos un modelo de lenguaje pequeño específicamente para segmentación, diseñado para capturar cambios de tema y mantener la coherencia mientras permanece eficiente y adaptable a través de varias tareas.
tag¿Por qué un Modelo de Lenguaje Pequeño?
Desarrollamos un Modelo de Lenguaje Pequeño (SLM) para abordar limitaciones específicas que encontramos con técnicas tradicionales de segmentación, particularmente al manejar fragmentos de código y otras estructuras complejas como tablas, listas y fórmulas. En enfoques tradicionales, que a menudo dependen de conteos de tokens o reglas estructurales rígidas, era difícil mantener la integridad del contenido semánticamente coherente. Por ejemplo, los fragmentos de código frecuentemente se segmentaban en múltiples partes, rompiendo su contexto y dificultando que los sistemas downstream los entendieran o recuperaran con precisión.
Al entrenar un SLM especializado, buscamos crear un modelo que pudiera reconocer y preservar inteligentemente estos límites significativos, asegurando que los elementos relacionados permanecieran juntos. Esto no solo mejora la calidad de recuperación en sistemas RAG sino que también mejora tareas downstream como sumarización y respuesta a preguntas, donde mantener segmentos coherentes y contextualmente relevantes es crítico. El enfoque SLM ofrece una solución más adaptable y específica para la tarea que los métodos tradicionales de segmentación, con sus límites rígidos, simplemente no pueden proporcionar.
tagEntrenando SLMs: Tres Enfoques
Entrenamos tres versiones de nuestro SLM:
simple-qwen-0.5es el modelo más directo, diseñado para identificar límites basándose en los elementos estructurales del documento. Su simplicidad lo hace una solución eficiente para necesidades básicas de segmentación.topic-qwen-0.5, inspirado en el razonamiento Chain-of-Thought, lleva la segmentación un paso más allá al identificar temas dentro del texto, como "el comienzo de la Segunda Guerra Mundial", y usar estos temas para definir límites de segmentos. Este modelo asegura que cada segmento sea coherente temáticamente, haciéndolo adecuado para documentos complejos con múltiples temas. Las pruebas iniciales mostraron que sobresale en segmentar contenido de una manera que refleja estrechamente la intuición humana.summary-qwen-0.5no solo identifica límites de texto sino que también genera resúmenes para cada segmento. Resumir segmentos es altamente ventajoso en aplicaciones RAG, especialmente para tareas como responder preguntas sobre documentos largos, aunque viene con el compromiso de demandar más datos durante el entrenamiento.
Todos los modelos devuelven solo encabezados de segmento—una versión truncada de cada segmento. En lugar de generar segmentos completos, los modelos producen puntos clave o subtemas, lo que mejora la detección de límites y la coherencia al enfocarse en transiciones semánticas en lugar de simplemente copiar el contenido de entrada. Al recuperar los segmentos, el texto del documento se divide basándose en esos encabezados de segmento, y los segmentos completos se reconstruyen en consecuencia.
tagDataset
Usamos el dataset wiki727k, una colección a gran escala de fragmentos de texto estructurados extraídos de artículos de Wikipedia. Contiene más de 727,000 secciones de texto, cada una representando una parte distinta de un artículo de Wikipedia, como una introducción, sección o subsección.
 koomri
koomritagAumento de Datos
Para generar pares de entrenamiento para cada variante del modelo, usamos GPT-4 para aumentar nuestros datos. Para cada artículo en nuestro conjunto de datos de entrenamiento, enviamos el prompt:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()Usamos una división simple para generar secciones de cada artículo, dividiendo en \\n\\n\\n, y luego subdividiendo en \\n\\n para obtener lo siguiente (en este caso, un artículo sobre Common Gateway Interface):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
Luego generamos una estructura JSON con las secciones, temas y resúmenes:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Common Gateway Interface en Servidores Web",
"Historia y Estandarización del CGI",
"Scripts CGI para Edición de Páginas Web",
"Reducción de Sobrecarga en Servidores Web en Invocación de Comandos"
],
"summaries": [
"CGI proporciona un protocolo para que los servidores web ejecuten programas que generan páginas web dinámicas.",
"El NCSA definió inicialmente CGI en 1993, llevando a su adopción como estándar para servidores Web y posterior formalización en RFC 3875 presidido por Ken Coar.",
"Este texto describe cómo un script CGI puede manejar la edición y guardado de contenido de páginas web a través de formularios HTML.",
"El texto discute técnicas para minimizar la sobrecarga del servidor por la invocación frecuente de comandos, incluyendo el prefork de procesos, uso de programas CGI precompilados e implementación de módulos de servidor web personalizados."
]
}
También agregamos ruido mezclando datos, añadiendo caracteres/palabras/letras aleatorias, eliminando puntuación al azar, y siempre eliminando caracteres de nueva línea.
Todo eso puede ayudar en parte a desarrollar un buen modelo - pero solo hasta cierto punto. Para realmente aprovechar al máximo necesitábamos que el modelo creara fragmentos coherentes sin romper los fragmentos de código. Para esto, aumentamos el conjunto de datos con código, fórmulas y listas generadas por GPT-4o.
tagLa Configuración del Entrenamiento
Para entrenar los modelos, implementamos la siguiente configuración:
- Framework: Usamos la biblioteca
transformersde Hugging Face integrada conUnslothpara optimización del modelo. Esto fue crucial para optimizar el uso de memoria y acelerar el entrenamiento, haciendo posible entrenar modelos pequeños con grandes conjuntos de datos de manera efectiva. - Optimizador y Planificador: Usamos el optimizador AdamW con una programación lineal de tasa de aprendizaje y pasos de calentamiento, permitiéndonos estabilizar el proceso de entrenamiento durante las épocas iniciales.
- Seguimiento de Experimentos: Rastreamos todos los experimentos de entrenamiento usando Weights & Biases, y registramos métricas clave como pérdida en entrenamiento y validación, cambios en la tasa de aprendizaje y rendimiento general del modelo. Este seguimiento en tiempo real nos proporcionó información sobre cómo progresaban los modelos, permitiendo ajustes rápidos cuando era necesario para optimizar los resultados del aprendizaje.
tagEl Entrenamiento en Sí
Usando qwen2-0.5b-instruct como modelo base, entrenamos tres variantes de nuestro SLM con Unsloth, cada una con una estrategia de segmentación diferente en mente. Para nuestras muestras usamos pares de entrenamiento, que consistían en el texto de un artículo de wiki727k y los resultantes sections, topics, o summaries (mencionados arriba en la sección "Aumento de Datos") dependiendo del modelo que se estaba entrenando.
simple-qwen-0.5: Entrenamossimple-qwen-0.5con 10,000 muestras durante 5,000 pasos, logrando una convergencia rápida y detectando efectivamente los límites entre secciones cohesivas de texto. La pérdida de entrenamiento fue de 0.16.topic-qwen-0.5: Al igual quesimple-qwen-0.5, entrenamostopic-qwen-0.5con 10,000 muestras durante 5,000 pasos, logrando una pérdida de entrenamiento de 0.45.summary-qwen-0.5: Entrenamossummary-qwen-0.5con 30,000 muestras durante 15,000 pasos. Este modelo mostró promesa pero tuvo una pérdida más alta (0.81) durante el entrenamiento, sugiriendo la necesidad de más datos (aproximadamente el doble de nuestra cantidad original de muestras) para alcanzar su potencial completo.
tagLos Segmentos en Sí
Aquí hay ejemplos de tres segmentos consecutivos de cada estrategia de segmentación, junto con la API de Segmentador de Jina. Para producir estos segmentos primero usamos Jina Reader para extraer un post del blog de Jina AI como texto plano (incluyendo todos los datos de la página, como encabezados, pies de página, etc), luego lo pasamos a cada método de segmentación.

tagAPI del Segmentador de Jina
La API del Segmentador de Jina tomó un enfoque muy granular para segmentar el post, dividiendo en caracteres como \n, \t, etc, para dividir el texto en segmentos a menudo muy pequeños. Solo mirando los primeros tres, extrajo search\\n, notifications\\n y NEWS\\n de la barra de navegación del sitio web, pero nada relevante al contenido del post en sí:

Más adelante, por fin obtuvimos algunos segmentos del contenido real del blog post, aunque se retuvo poco contexto en cada uno:

(En aras de la equidad, mostramos más fragmentos de la API del Segmentador que para los modelos, simplemente porque de otro modo tendría muy pocos segmentos significativos para mostrar)
tagsimple-qwen-0.5
simple-qwen-0.5 dividió el post del blog basándose en la estructura semántica, extrayendo segmentos mucho más largos que tenían un significado coherente:
tagtopic-qwen-0.5
topic-qwen-0.5 primero identificó temas basados en el contenido del documento, luego segmentó el documento basado en esos temas:
tagsummary-qwen-0.5
summary-qwen-0.5 identificó límites de segmentos y generó un resumen del contenido dentro de cada segmento:
tagEvaluación Comparativa de los Modelos
Para evaluar el rendimiento de nuestros modelos, extrajimos ocho posts del blog de Jina AI y generamos seis preguntas y respuestas verdaderas usando GPT-4o.
Aplicamos cada método de segmentación, incluyendo la API del Segmentador de Jina, a estos posts del blog, y luego generamos embeddings para los segmentos resultantes usando jina-embeddings-v3, sin chunking tardío ni reranking.

Cada conjunto de segmentos se indexó por separado y usamos un sistema RAG para consultar cada índice con las preguntas generadas previamente.
topic-qwen-0.5 y summary-qwen-0.5 indexamos solo los segmentos en sí, no los resúmenes o temas generados. Indexar estos datos adicionales probablemente mejoraría aún más el rendimiento.Para medir el rendimiento, comparamos las respuestas generadas del índice de cada método de segmentación con las respuestas verdaderas usando puntuaciones F1 de la evaluación ROUGE-L, donde puntuaciones más altas indican mejor rendimiento.
Por ejemplo, dada la pregunta: "¿Qué factores impactan las capacidades de comparación numérica del modelo jina-embeddings-v2-base-en?", recibimos las siguientes respuestas:
tagVerdad Fundamental (Generada por GPT-4o del Texto Completo del Post):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
tagJina Segmenter API (puntuación: 0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
tagsimple-qwen-0.5 (puntuación: 0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
tagtopic-qwen-0.5 (puntuación: 0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
tagsummary-qwen-0.5 (0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5?Esto es principalmente una casualidad basada en la pregunta particular que le hicimos al modelo. Como puedes ver en la tabla siguiente, la puntuación ROUGE promedio de
topic-qwen-0.5 es la más alta de todas las metodologías de segmentación.También evaluamos la velocidad de cada método (midiendo cuánto tiempo tomó generar e incrustar segmentos) y estimamos el espacio en disco (multiplicando el conteo de embeddings por el tamaño de un solo embedding de 1024 dimensiones de jina-embeddings-v3). Esto nos permitió evaluar tanto la precisión como la eficiencia entre las diferentes estrategias de segmentación.
tagHallazgos Clave
Después de probar las variantes del modelo entre sí y contra la API de Jina Segmenter, nos dimos cuenta de que los nuevos modelos de hecho mostraron puntuaciones mejoradas usando los tres métodos, especialmente la segmentación por temas:
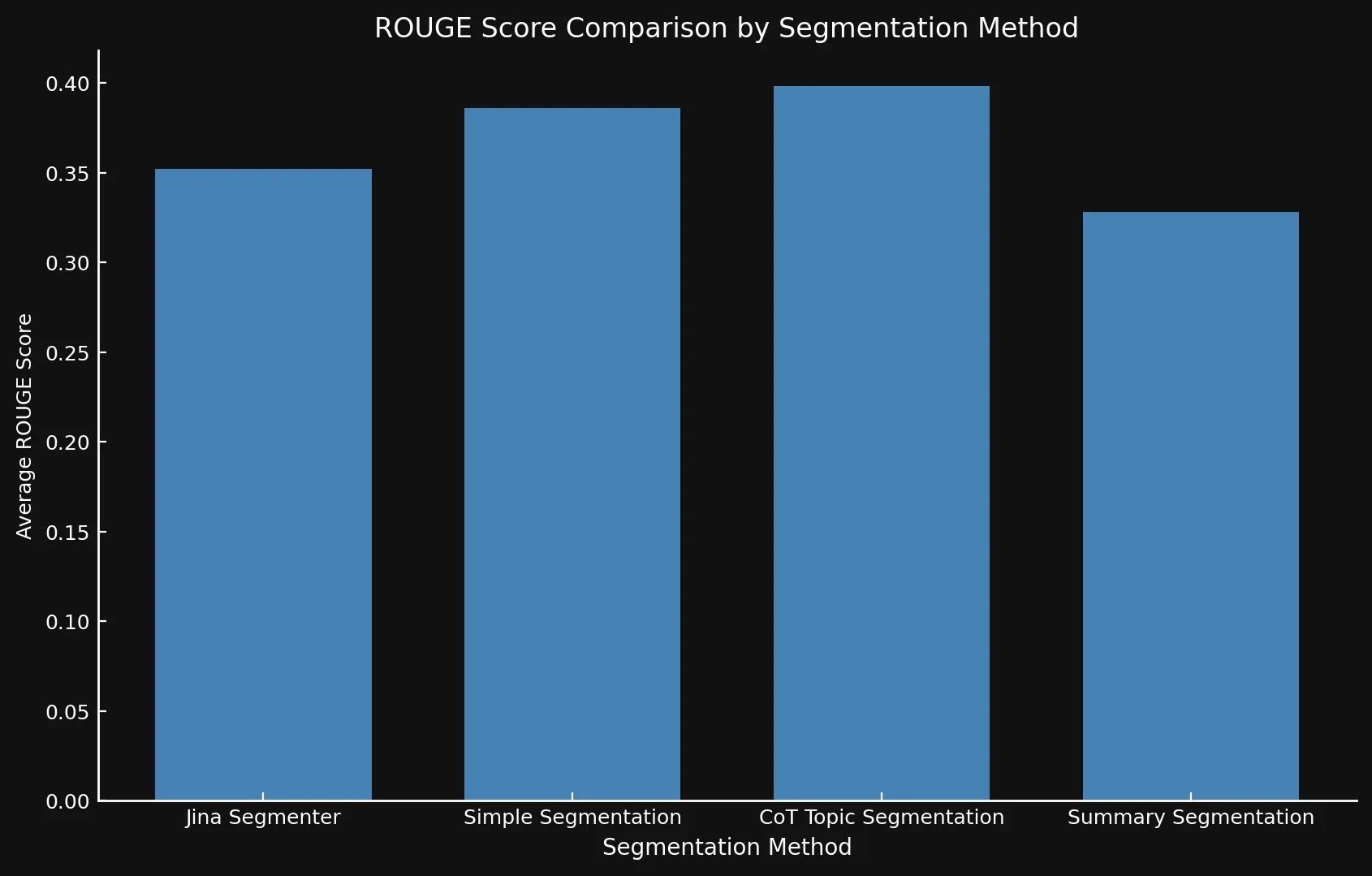
| Método de Segmentación | Puntuación ROUGE Promedio |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 tiene una puntuación ROUGE más baja que topic-qwen-0.5? En resumen, summary-qwen-0.5 mostró una pérdida más alta durante el entrenamiento, revelando la necesidad de más entrenamiento para recibir mejores resultados. Eso podría ser tema de experimentación futura.Sin embargo, sería interesante revisar los resultados con la función de chunking tardío de jina-embeddings-v3, que aumenta la relevancia contextual de los embeddings de segmentos, proporcionando resultados más relevantes. Eso podría ser tema para un futuro post del blog.
Respecto a la velocidad, puede ser difícil comparar los nuevos modelos con Jina Segmenter, ya que este último es una API, mientras que ejecutamos los tres modelos en una GPU Nvidia 3090. Como puedes ver, cualquier rendimiento ganado durante el rápido paso de segmentación de la API Segmenter es rápidamente superado por la necesidad de generar embeddings para tantos segmentos:
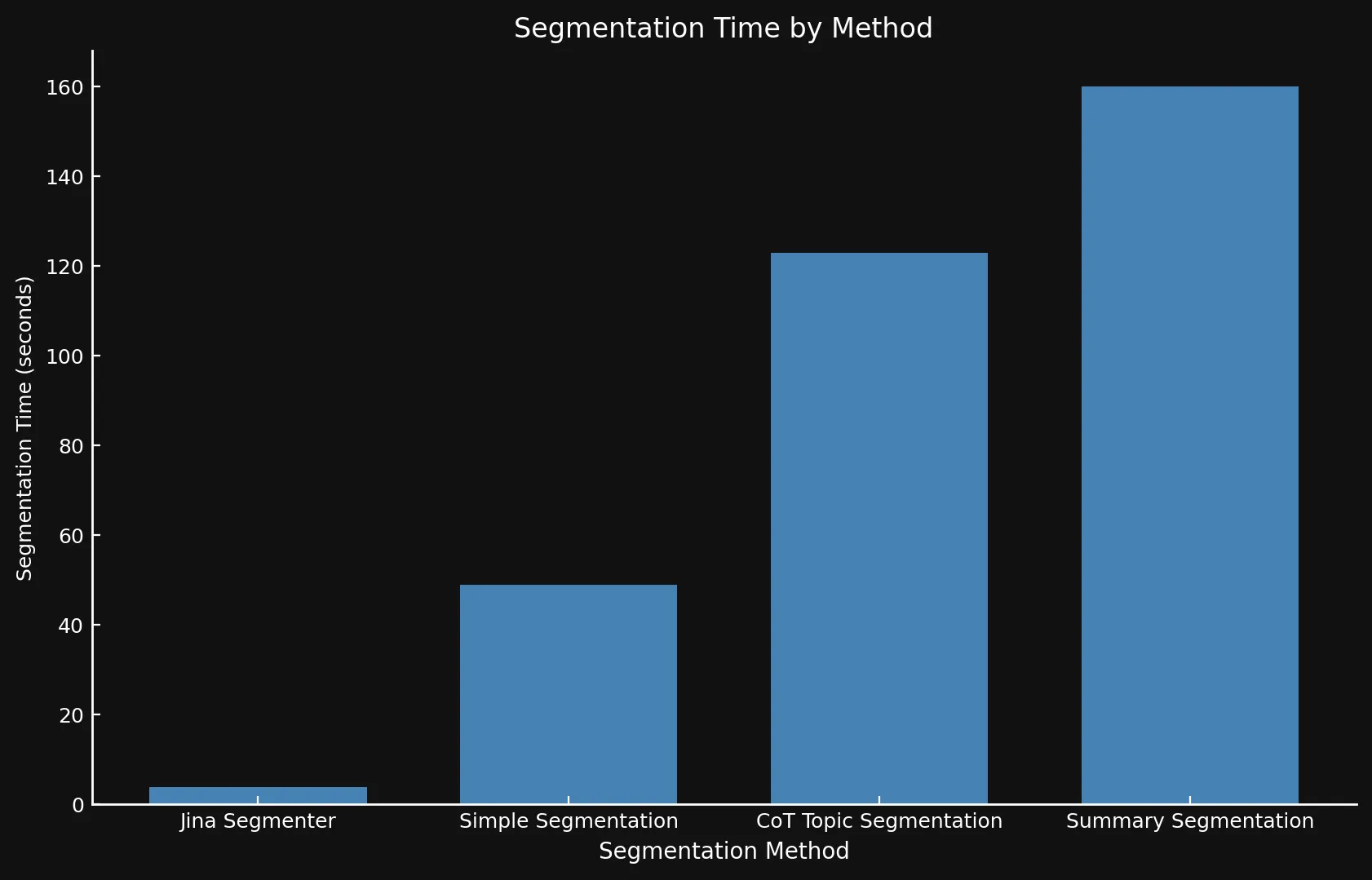
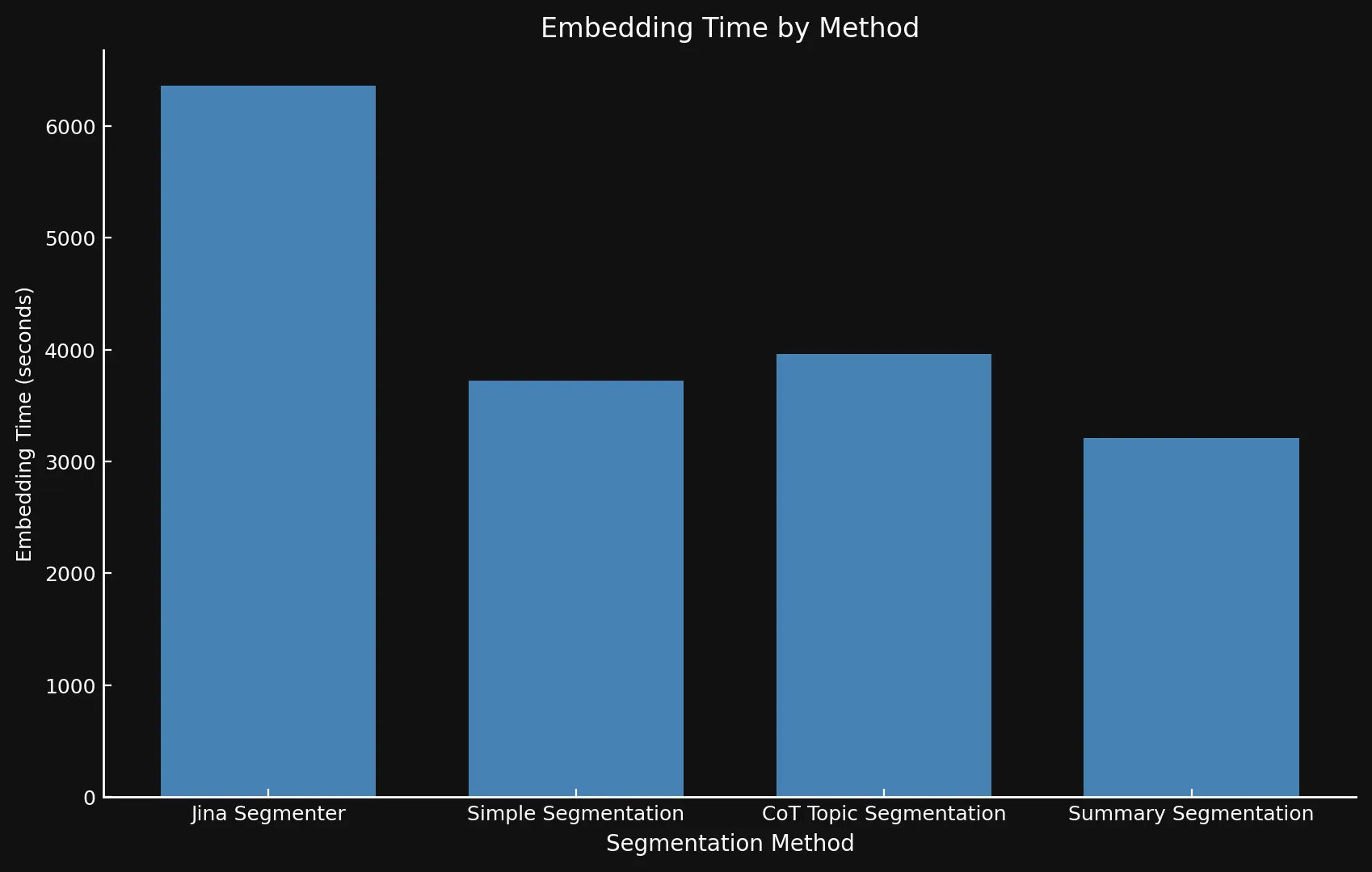
• Usamos diferentes ejes Y en ambos gráficos porque presentar marcos de tiempo tan diferentes con un solo gráfico o ejes Y consistentes no era factible.
• Ya que estábamos realizando esto puramente como un experimento, no usamos procesamiento por lotes al generar embeddings. Hacerlo aceleraría sustancialmente las operaciones para todos los métodos.
Naturalmente, más segmentos significa más embeddings. Y esos embeddings ocupan mucho espacio: Los embeddings para los ocho posts del blog que probamos ocuparon más de 21 MB con la API Segmenter, mientras que Summary Segmentation ocupó un elegante 468 KB. Esto, más las puntuaciones ROUGE más altas de nuestros modelos significa menos segmentos pero mejores segmentos, ahorrando dinero y aumentando el rendimiento:
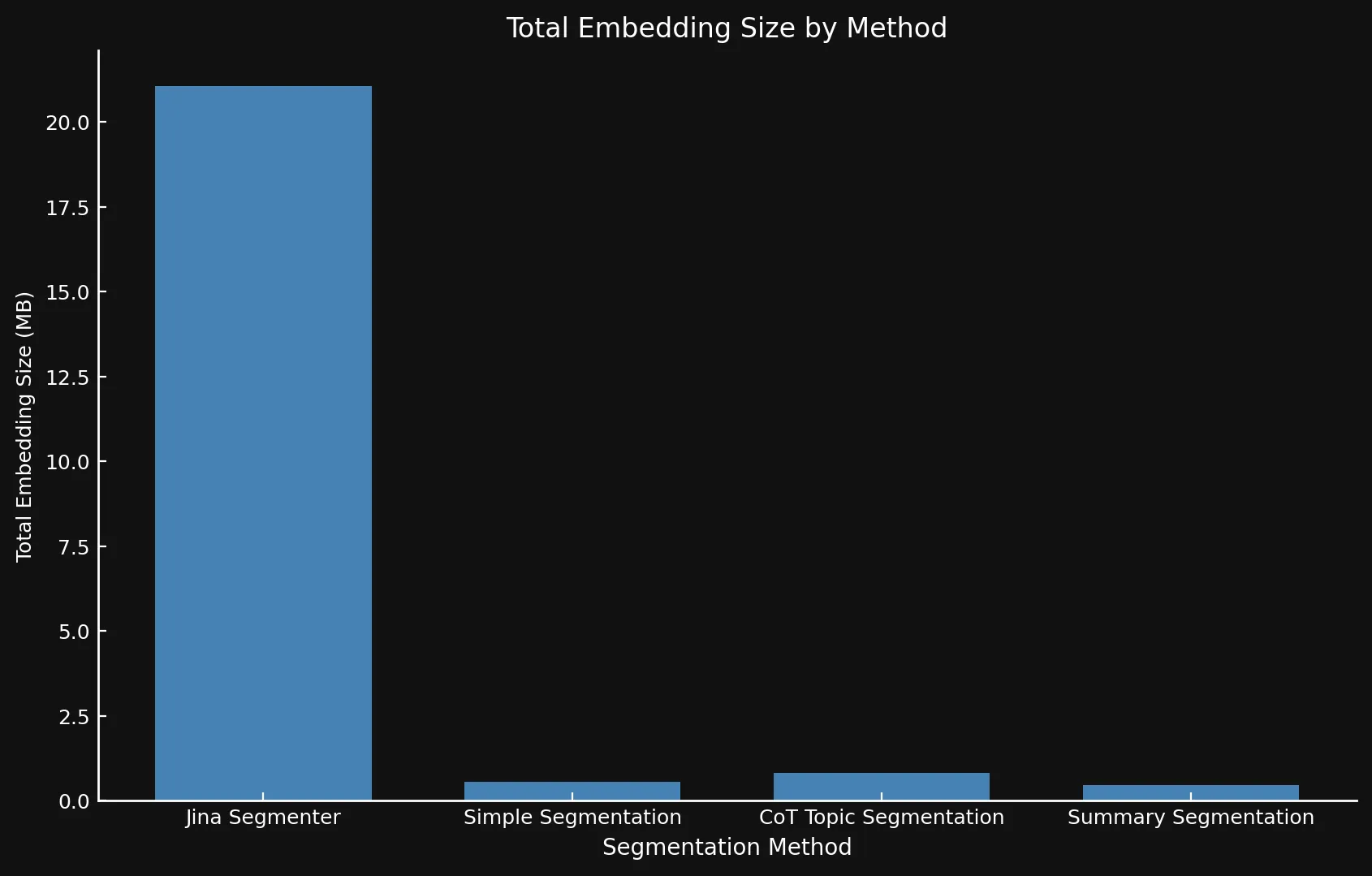
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
tagLo que Aprendimos
tagLa Formulación del Problema es Crítica
Una conclusión clave fue el impacto de cómo enfocamos la tarea. Al hacer que el modelo genere encabezados de segmentos, mejoramos la detección de límites y la coherencia al centrarnos en las transiciones semánticas en lugar de simplemente copiar y pegar el contenido de entrada en segmentos separados. Esto también resultó en un modelo de segmentación más rápido, ya que generar menos texto permitió que el modelo completara la tarea más rápidamente.
tagLos Datos Generados por LLM son Efectivos
El uso de datos generados por LLM, particularmente para contenido complejo como listas, fórmulas y fragmentos de código, amplió el conjunto de entrenamiento del modelo y mejoró su capacidad para manejar diversas estructuras de documentos. Esto hizo que el modelo fuera más adaptable a través de diversos tipos de contenido, una ventaja crucial cuando se trata de documentos técnicos o estructurados.
tagRecopilación de Datos Solo de Salida
Al usar un recopilador de datos solo de salida, nos aseguramos de que el modelo se centrara en predecir los tokens objetivo durante el entrenamiento, en lugar de simplemente copiar de la entrada. El recopilador solo de salida aseguró que el modelo aprendiera de las secuencias objetivo reales, enfatizando las completaciones o límites correctos. Esta distinción permitió que el modelo convergiera más rápido al evitar el sobreajuste a la entrada y ayudó a que generalizara mejor a través de diferentes conjuntos de datos.
tagEntrenamiento Eficiente con Unsloth
Con Unsloth, optimizamos el entrenamiento de nuestro modelo de lenguaje pequeño, logrando ejecutarlo en una GPU Nvidia 4090. Esta pipeline optimizada nos permitió entrenar un modelo eficiente y performante sin necesidad de recursos computacionales masivos.
tagManejo de Textos Complejos
Los modelos de segmentación sobresalieron en el manejo de documentos complejos que contienen código, tablas y listas, que típicamente son difíciles para los métodos más tradicionales. Para contenido técnico, estrategias sofisticadas como topic-qwen-0.5 y summary-qwen-0.5 fueron más efectivas, con el potencial de mejorar las tareas RAG posteriores.
tagMétodos Simples para Contenido más Simple
Para contenido sencillo basado en narrativa, los métodos más simples como el API de Segmenter suelen ser suficientes. Las estrategias de segmentación avanzadas pueden ser necesarias solo para contenido más complejo y estructurado, permitiendo flexibilidad según el caso de uso.
tagPróximos Pasos
Si bien este experimento fue diseñado principalmente como una prueba de concepto, si fuéramos a extenderlo más, podríamos hacer varias mejoras. Primero, aunque es poco probable la continuación de este experimento específico, entrenar summary-qwen-0.5 en un conjunto de datos más grande —idealmente 60,000 muestras en lugar de 30,000— probablemente llevaría a un rendimiento más óptimo. Además, refinar nuestro proceso de evaluación comparativa sería beneficioso. En lugar de evaluar las respuestas generadas por LLM del sistema RAG, nos centraríamos en cambio en comparar los segmentos recuperados directamente con la verdad fundamental. Finalmente, iríamos más allá de las puntuaciones ROUGE y adoptaríamos métricas más avanzadas (posiblemente una combinación de ROUGE y puntuación LLM) que capturan mejor los matices de la calidad de recuperación y segmentación.
tagConclusión
En este experimento, exploramos cómo los modelos de segmentación personalizados diseñados para tareas específicas pueden mejorar el rendimiento de RAG. Al desarrollar y entrenar modelos como simple-qwen-0.5, topic-qwen-0.5, y summary-qwen-0.5, abordamos desafíos clave encontrados en los métodos de segmentación tradicionales, particularmente en mantener la coherencia semántica y manejar efectivamente contenido complejo como fragmentos de código. Entre los modelos probados, topic-qwen-0.5 entregó consistentemente la segmentación más significativa y contextualmente relevante, especialmente para documentos multi-tema.
Si bien los modelos de segmentación proporcionan la base estructural necesaria para los sistemas RAG, cumplen una función diferente en comparación con el chunking tardío, que optimiza el rendimiento de recuperación manteniendo la relevancia contextual a través de los segmentos. Estos dos enfoques pueden ser complementarios, pero la segmentación es particularmente crucial cuando se necesita un método que se centre en dividir documentos para flujos de trabajo de generación coherentes y específicos para cada tarea.





