


Las discusiones sobre la IA suelen ser apocalípticas. Parte de la culpa la tiene la forma en que la ciencia ficción apocalíptica ha creado nuestra imagen mental de la inteligencia artificial. Las visiones de máquinas inteligentes que pueden crear más máquinas han sido un tema común en la ciencia ficción durante generaciones.
Muchas personas han expresado su preocupación sobre los riesgos existenciales de los recientes avances en IA, muchos de ellos líderes empresariales involucrados en la comercialización de la IA, e incluso algunos científicos e investigadores. Se ha convertido en un componente del bombo publicitario de la IA: algo lo suficientemente poderoso como para hacer que figuras aparentemente sobrias de la ciencia y la industria contemplen el fin del mundo debe ser sin duda lo suficientemente poderoso como para generar beneficios, ¿verdad?
Entonces, ¿deberíamos preocuparnos por los riesgos existenciales de la IA? ¿Debemos temer que Sam Altman cree a Ultron a partir de ChatGPT y tenga su ejército de IA lanzándonos ciudades de Europa del Este? ¿Deberíamos preocuparnos de que Palantir de Peter Thiel esté construyendo Skynet y enviando robots con inexplicables acentos austriacos al pasado para matarnos?
Probablemente no. Los líderes de la industria aún no han identificado ninguna manera clara de hacer que la IA pague sus propias cuentas, mucho menos disrumpir industrias, y menos aún amenazar a la humanidad a un nivel comparable al cambio climático o las armas nucleares.
Los modelos de IA que realmente tenemos difícilmente están a la altura de exterminar a la humanidad. Luchan por dibujar manos, no pueden contar más de tres cosas, piensan que está bien vender queso que las ratas han mordisqueado, y realizan bautizos católicos con Gatorade. Los riesgos mundanos y no existenciales de la IA — la forma en que la tecnología puede ayudar a desinformar, acosar, generar spam y ser mal utilizada por personas que no comprenden sus limitaciones — son suficientemente preocupantes.
Pero hay un riesgo existencial de la inteligencia artificial que definitivamente es legítimo: la IA representa un peligro claro y presente para... la IA.
Este temor generalmente se denomina "colapso del modelo" y ha recibido una sólida demostración empírica en Shumailov et al. (2023) y Alemohammad et al. (2023). La idea es simple: si entrenas modelos de IA con datos generados por IA, luego tomas la IA resultante y usas su salida para entrenar otro modelo, repitiendo el proceso durante múltiples generaciones, la IA se volverá objetivamente peor y peor. Es como hacer una fotocopia de una fotocopia de una fotocopia.

Últimamente ha habido algunas discusiones sobre el colapso del modelo, y están apareciendo titulares en la prensa sobre la IA quedándose sin datos. Si Internet se llena de datos generados por IA, y los datos creados por humanos se vuelven más difíciles de identificar y usar, entonces, en poco tiempo, los modelos de IA se encontrarán con un techo de calidad.
Al mismo tiempo, hay un uso creciente de técnicas de datos sintéticos y destilación de modelos en el desarrollo de IA. Ambas consisten en entrenar modelos de IA al menos en parte con la salida de otros modelos de IA. Estas dos tendencias parecen contradecirse entre sí.
Las cosas son un poco más complicadas que eso. ¿La IA generativa saturará el sistema y sofocará su propio progreso? ¿O la IA nos ayudará a crear mejor IA? ¿O ambas cosas?
Intentaremos obtener algunas respuestas en este artículo.
tagColapso del Modelo
Por mucho que apreciemos a Alemohammad et al. por inventar el término "Trastorno de Autofagia del Modelo (MAD)", "colapso del modelo" es mucho más pegadizo y no involucra palabras griegas para el auto-canibalismo. La metáfora de hacer fotocopias de fotocopias comunica el problema en términos simples, pero hay algo más en la teoría subyacente.
Entrenar un modelo de IA es un tipo de modelado estadístico, una extensión de lo que los estadísticos y científicos de datos han estado haciendo durante mucho tiempo. Pero, en el primer día de clase de ciencia de datos, aprendes el lema del científico de datos:
Todos los modelos están equivocados, pero algunos son útiles.
Esta cita, atribuida a George Box, es la luz roja intermitente que debería estar sobre cada modelo de IA. Siempre puedes hacer un modelo estadístico para cualquier conjunto de datos, y ese modelo siempre te dará una respuesta, pero absolutamente nada garantiza que esa respuesta sea correcta o siquiera se acerque a serlo.
Un modelo estadístico es una aproximación de algo. Sus salidas pueden ser útiles, incluso podrían ser lo suficientemente buenas, pero siguen siendo aproximaciones. Incluso si tienes un modelo bien validado que, en promedio, es muy preciso, puede y probablemente cometerá grandes errores a veces.
Los modelos de IA heredan todos los problemas del modelado estadístico. Cualquiera que haya jugado con ChatGPT o cualquier otro modelo grande de IA ha visto que comete errores.
Entonces, si un modelo de IA es una aproximación de algo real, un modelo de IA entrenado con la salida de otro modelo de IA es una aproximación de una aproximación. Los errores se acumulan, y inherentemente tiene que ser un modelo menos correcto que el modelo del que fue entrenado.
Alemohammad et al. muestran que no puedes arreglar el problema agregando algunos de los datos de entrenamiento originales a la salida de la IA antes de entrenar el nuevo modelo "hijo". Eso solo ralentiza el colapso del modelo, no puede detenerlo. A menos que introduzcas suficientes datos nuevos, previamente no vistos, del mundo real siempre que entrenes con salida de IA, el colapso del modelo es inevitable.
Cuántos datos nuevos son suficientes depende de factores difíciles de predecir y específicos de cada caso, pero más datos nuevos y reales y menos datos generados por IA siempre es mejor que lo contrario.
Y eso es un problema porque todas las fuentes fácilmente accesibles de datos nuevos creados por humanos ya están agotadas mientras que la cantidad de datos de imagen y texto generados por IA está creciendo a pasos agigantados. La proporción de contenido creado por humanos versus contenido creado por IA en Internet está cayendo, posiblemente cayendo rápido. No hay manera confiable de detectar automáticamente datos generados por IA y muchos investigadores creen que no puede haberla. El acceso público a modelos de generación de imágenes y texto por IA asegura que este problema crecerá, probablemente de manera dramática, y no tiene una solución obvia.
La cantidad de traducción automática en Internet podría significar que ya es demasiado tarde. El texto traducido por máquinas en Internet ha estado contaminando nuestras fuentes de datos durante años, mucho antes de la revolución de la IA generativa. Según Thompson, et al., 2024, posiblemente la mitad del texto en Internet puede estar traducido de otro idioma, y una gran parte de esas traducciones son de baja calidad y muestran señales de generación automática. Esto puede distorsionar un modelo de lenguaje entrenado con dichos datos.
Como ejemplo, a continuación se muestra una captura de pantalla de una página del sitio web Die Welt der Habsburger que muestra clara evidencia de traducción automática. "Hamster buying" es una traducción demasiado literal de la palabra alemana hamstern, que significa acaparar o comprar en pánico. Demasiados casos como este llevarán a un modelo de IA a pensar que "hamster buying" es algo real en inglés y que el término alemán hamstern tiene algo que ver con hámsteres mascota.

En casi todos los casos, tener más contenido generado por IA en tus datos de entrenamiento es malo. El casi es importante, y discutiremos dos excepciones a continuación.
tagDatos Sintéticos
Los datos sintéticos son datos de entrenamiento o evaluación de IA que han sido generados artificialmente en lugar de encontrados en el mundo real. Nikolenko (2021) sitúa los orígenes de los datos sintéticos en los primeros proyectos de visión por computadora en los años 1960 y describe su historia como un elemento importante de ese campo.
Hay muchas razones para usar datos sintéticos. Una de las más importantes es combatir el sesgo.
Los modelos de lenguaje grandes y los generadores de imágenes han recibido muchas críticas de alto perfil sobre sesgos. La palabra sesgo tiene un significado estricto en estadística, pero estas críticas a menudo reflejan consideraciones morales, sociales y políticas que no tienen una forma matemática simple ni una solución de ingeniería.
El sesgo que no se ve fácilmente es mucho más dañino y más difícil de corregir. Los patrones que los modelos de IA aprenden a replicar son los que ven en sus datos de entrenamiento, y donde esos datos tienen deficiencias sistemáticas, el sesgo es una consecuencia inevitable. Cuantas más cosas diferentes esperamos que haga la IA —cuanto más diversos sean los inputs al modelo— más probabilidades hay de que se equivoque porque nunca vio suficientes casos similares en su entrenamiento.
El papel principal de los datos sintéticos en el entrenamiento de IA hoy en día es asegurar que haya suficientes ejemplos de ciertos tipos de situaciones en los datos de entrenamiento, situaciones que pueden no estar suficientemente presentes en los datos naturales disponibles.
A continuación se muestra una imagen que MidJourney produjo cuando se le indicó "doctor": cuatro hombres, tres blancos, tres con batas blancas y estetoscopios, y uno genuinamente mayor. Esto no refleja la raza, edad, género o vestimenta real de los médicos en la mayoría de los países y contextos, pero probablemente refleja las imágenes etiquetadas que se encuentran en Internet.

Cuando se le pidió de nuevo, produjo una mujer y tres hombres, todos blancos, aunque uno es un dibujo animado. La IA puede ser extraña.

Esta fuente particular de sesgo es una que los generadores de imágenes de IA han estado tratando de prevenir, por lo que ya no obtenemos resultados tan claramente sesgados como quizás hace un año de los mismos sistemas. Un sesgo es visiblemente presente todavía, pero no es obvio cómo sería un resultado sin sesgo.
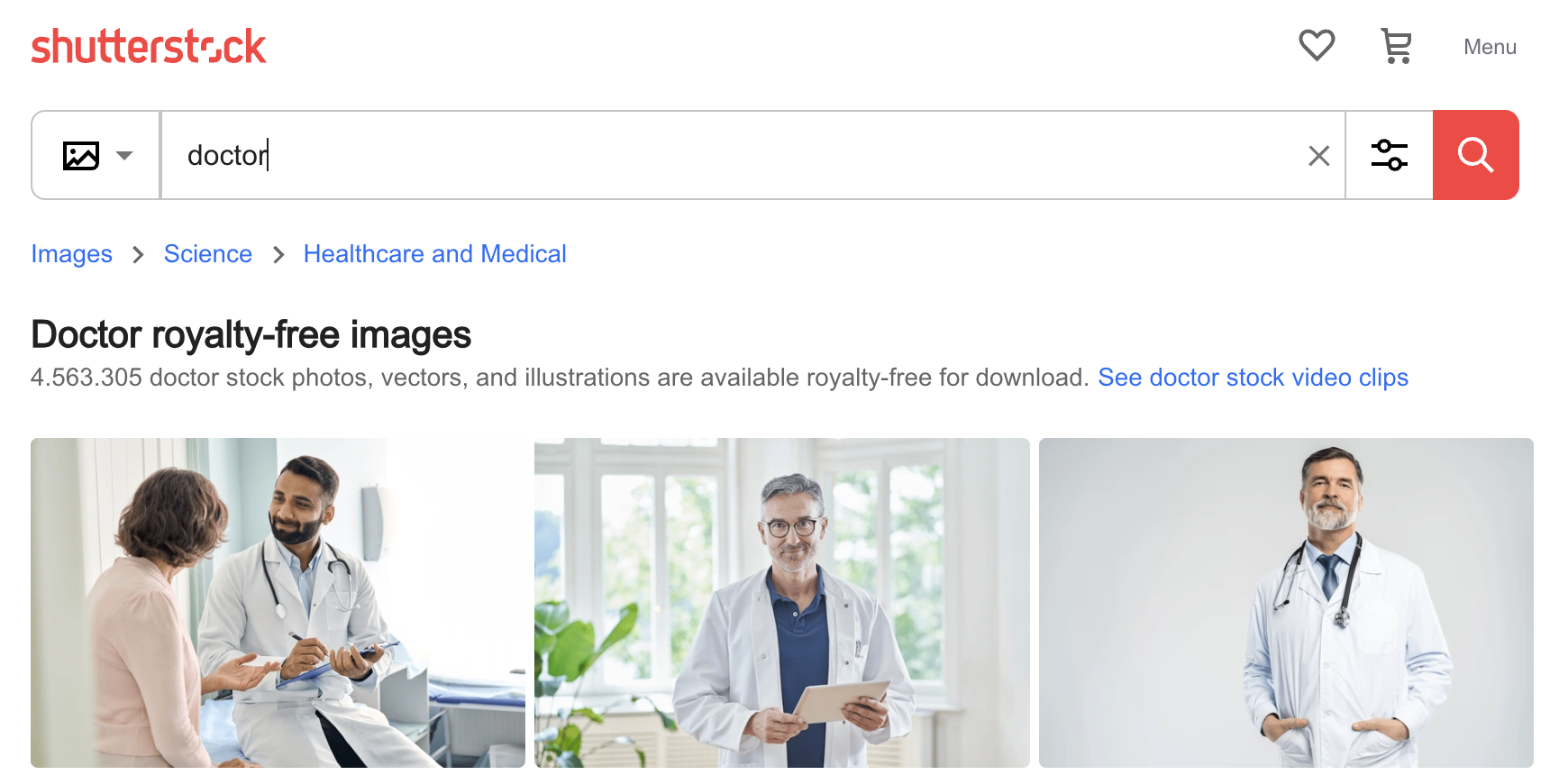
Aun así, no es difícil entender cómo una IA podría adquirir este tipo de prejuicios. A continuación se muestran las primeras tres imágenes encontradas para "doctor" en el sitio web de fotos Shutterstock: Tres hombres, dos mayores y blancos. Los sesgos de la IA son los sesgos de su entrenamiento, y si entrenas modelos usando datos sin curar, siempre encontrarás este tipo de sesgos.
Una forma de mitigar este problema es usar un generador de imágenes de IA para crear imágenes de médicos más jóvenes, médicas mujeres, médicos que son personas de color, y médicos vistiendo scrubs, trajes u otra vestimenta, y luego incluirlas en el entrenamiento. Los datos sintéticos usados de esta manera pueden mejorar el rendimiento del modelo de IA, al menos en relación con alguna norma externa, en lugar de llevar al colapso del modelo. Sin embargo, distorsionar artificialmente las distribuciones de datos de entrenamiento puede crear efectos secundarios no deseados, como Google descubrió recientemente.
tagDestilación de Modelos
La destilación de modelos es una técnica para entrenar un modelo directamente de otro. Un modelo generativo entrenado —el "profesor"— crea tantos datos como sean necesarios para entrenar un modelo "estudiante" sin entrenar o menos entrenado.
Como era de esperar, el modelo "estudiante" nunca puede ser mejor que el "profesor". A primera vista, parece tener poco sentido entrenar un modelo de esa manera, pero hay beneficios. El principal es que el modelo "estudiante" puede ser mucho más pequeño, rápido o eficiente que el "profesor", mientras sigue aproximando de cerca su rendimiento.
La relación entre el tamaño del modelo, los datos de entrenamiento y el rendimiento final es complicada. Sin embargo, en general, todo lo demás siendo igual:
- Un modelo más grande funciona mejor que uno pequeño.
- Un modelo entrenado con más o mejores datos de entrenamiento (o al menos datos de entrenamiento más diversos) funciona mejor que uno entrenado con menos datos o datos de menor calidad.
Esto significa que un modelo pequeño puede, a veces, funcionar tan bien como uno grande. Por ejemplo, jina-embeddings-v2-base-en supera significativamente a muchos modelos mucho más grandes en benchmarks estándar:
| Model | Size in parameters | MTEB average score |
|---|---|---|
| jina-embeddings-v2-base-en | 137M | 60.38 |
multilingual-e5-base |
278M | 59.45 |
sentence-t5-xl |
1240M | 57.87 |

| Model | BEIR Score | Parameter count | |
|---|---|---|---|
| jina-reranker-v1-base-en | 52.45 | 137M | |
| Distilled | jina-reranker-v1-turbo-en | 49.60 | 38M |
| Distilled | jina-reranker-v1-tiny-en | 48.54 | 33M |
mxbai-rerank-base-v1 |
49.19 | 184M | |
mxbai-rerank-xsmall-v1 |
48.80 | 71M | |
bge-reranker-base |
47.89 | 278M |
