

La classification est une tâche en aval courante pour les embeddings. Les embeddings de texte peuvent catégoriser le texte en étiquettes prédéfinies pour la détection de spam ou l'analyse de sentiment. Les embeddings multimodaux comme jina-clip-v1 peuvent être appliqués au filtrage basé sur le contenu ou à l'annotation de tags. Récemment, la classification a également trouvé une utilité dans le routage des requêtes vers les LLM appropriés en fonction de leur complexité et de leur coût, par exemple les requêtes arithmétiques simples peuvent être dirigées vers un petit modèle de langage. Les tâches de raisonnement complexe pourraient être dirigées vers des LLM plus puissants mais plus coûteux.
Aujourd'hui, nous présentons la nouvelle API Classifier de Jina AI's Search Foundation. Supportant la classification zero-shot et few-shot en ligne, elle est construite sur nos derniers modèles d'embedding comme jina-embeddings-v3 et jina-clip-v1. L'API Classifier s'appuie sur l'apprentissage passif-agressif en ligne, lui permettant de s'adapter aux nouvelles données en temps réel. Les utilisateurs peuvent commencer avec un classificateur zero-shot et l'utiliser immédiatement. Ils peuvent ensuite mettre à jour progressivement le classificateur en soumettant de nouveaux exemples ou lorsqu'une dérive conceptuelle se produit. Cela permet une classification efficace et évolutive à travers divers types de contenu sans données étiquetées initiales importantes. Les utilisateurs peuvent également publier leurs classificateurs pour un usage public. Lorsque nos nouveaux embeddings sont publiés, comme le prochain jina-clip-v2 multilingue, les utilisateurs peuvent y accéder immédiatement via l'API Classifier, garantissant des capacités de classification à jour.

tagClassification Zero-Shot
L'API Classifier offre de puissantes capacités de classification zero-shot, vous permettant de catégoriser du texte ou des images sans pré-entraînement sur des données étiquetées. Chaque classificateur commence avec des capacités zero-shot, qui peuvent ensuite être améliorées avec des données d'entraînement supplémentaires ou des mises à jour - un sujet que nous explorerons dans la section suivante.
tagExemple 1 : Routage des requêtes LLM
Voici un exemple utilisant l'API classifier pour le routage des requêtes LLM :
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-embeddings-v3",
"labels": [
"Simple task",
"Complex reasoning",
"Creative writing"
],
"input": [
"Calculate the compound interest on a principal of $10,000 invested for 5 years at an annual rate of 5%, compounded quarterly.",
"分析使用CRISPR基因编辑技术在人类胚胎中的伦理影响。考虑潜在的医疗益处和长期社会后果。",
"AIが自意識を持つディストピアの未来を舞台にした短編小説を書いてください。人間とAIの関係や意識の本質をテーマに探求してください。",
"Erklären Sie die Unterschiede zwischen Merge-Sort und Quicksort-Algorithmen in Bezug auf Zeitkomplexität, Platzkomplexität und Leistung in der Praxis.",
"Write a poem about the beauty of nature and its healing power on the human soul.",
"Translate the following sentence into French: The quick brown fox jumps over the lazy dog."
]
}'Cet exemple démontre l'utilisation de jina-embeddings-v3 pour router les requêtes utilisateur en plusieurs langues (anglais, chinois, japonais et allemand) en trois catégories, qui correspondent à trois tailles différentes de LLM. Le format de réponse de l'API est le suivant :
{
"usage": {"total_tokens": 256, "prompt_tokens": 256},
"data": [
{"object": "classification", "index": 0, "prediction": "Simple task", "score": 0.35216382145881653},
{"object": "classification", "index": 1, "prediction": "Complex reasoning", "score": 0.34310275316238403},
{"object": "classification", "index": 2, "prediction": "Creative writing", "score": 0.3487184941768646},
{"object": "classification", "index": 3, "prediction": "Complex reasoning", "score": 0.35207709670066833},
{"object": "classification", "index": 4, "prediction": "Creative writing", "score": 0.3638903796672821},
{"object": "classification", "index": 5, "prediction": "Simple task", "score": 0.3561534285545349}
]
}La réponse inclut :
usage: Informations sur l'utilisation des tokens.data: Un tableau de résultats de classification, un pour chaque entrée.- Chaque résultat contient l'étiquette prédite (
prediction) et un score de confiance (score). Lescorepour chaque classe est calculé via la normalisation softmax - pour le zero-shot, il est basé sur les similarités cosinus entre les embeddings d'entrée et d'étiquette sous le task-LoRAclassification; tandis que pour le few-shot, il est basé sur les transformations linéaires apprises de l'embedding d'entrée pour chaque classe - résultant en des probabilités qui somment à 1 sur toutes les classes. - L'
indexcorrespond à la position de l'entrée dans la requête originale.
- Chaque résultat contient l'étiquette prédite (
tagExemple 2 : Catégorisation d'Images et de Textes
Explorons un exemple multimodal utilisant jina-clip-v1. Ce modèle peut classifier à la fois du texte et des images, ce qui le rend idéal pour la catégorisation de contenu à travers différents types de médias. Considérons l'appel API suivant :
curl https://api.jina.ai/v1/classify \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY_HERE" \
-d '{
"model": "jina-clip-v1",
"labels": [
"Food and Dining",
"Technology and Gadgets",
"Nature and Outdoors",
"Urban and Architecture"
],
"input": [
{"text": "A sleek smartphone with a high-resolution display and multiple camera lenses"},
{"text": "Fresh sushi rolls served on a wooden board with wasabi and ginger"},
{"image": "https://picsum.photos/id/11/367/267"},
{"image": "https://picsum.photos/id/22/367/267"},
{"text": "Vibrant autumn leaves in a dense forest with sunlight filtering through"},
{"image": "https://picsum.photos/id/8/367/267"}
]
}'Notez comment nous téléchargeons des images dans la requête, vous pouvez également utiliser une chaîne base64 pour représenter une image. L'API renvoie les résultats de classification suivants :
{
"usage": {"total_tokens": 12125, "prompt_tokens": 12125},
"data": [
{"object": "classification", "index": 0, "prediction": "Technology and Gadgets", "score": 0.30329811573028564},
{"object": "classification", "index": 1, "prediction": "Food and Dining", "score": 0.2765541970729828},
{"object": "classification", "index": 2, "prediction": "Nature and Outdoors", "score": 0.29503118991851807},
{"object": "classification", "index": 3, "prediction": "Urban and Architecture", "score": 0.2648046910762787},
{"object": "classification", "index": 4, "prediction": "Nature and Outdoors", "score": 0.3133063316345215},
{"object": "classification", "index": 5, "prediction": "Technology and Gadgets", "score": 0.27474141120910645}
]
}tagExemple 3 : Détecter si Jina Reader obtient du contenu authentique
Une application intéressante de la classification zero-shot est la détermination de l'accessibilité des sites web via Jina Reader. Bien que cela puisse sembler une tâche simple, c'est étonnamment complexe en pratique. Les messages de blocage varient largement d'un site à l'autre, apparaissant dans différentes langues et citant diverses raisons (paywalls, limites de taux, pannes de serveur). Cette diversité rend difficile de s'appuyer sur des regex ou des règles fixes pour capturer tous les scénarios.
import requests
import json
response1 = requests.get('https://r.jina.ai/https://jina.ai')
url = 'https://api.jina.ai/v1/classify'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer $YOUR_API_KEY_HERE'
}
data = {
'model': 'jina-embeddings-v3',
'labels': ['Blocked', 'Accessible'],
'input': [{'text': response1.text[:8000]}]
}
response2 = requests.post(url, headers=headers, data=json.dumps(data))
print(response2.text)Le script récupère le contenu via r.jina.ai et le classe comme "Blocked" ou "Accessible" en utilisant l'API Classifier. Par exemple, https://r.jina.ai/https://www.crunchbase.com/organization/jina-ai serait probablement "Blocked" en raison des restrictions d'accès, tandis que https://r.jina.ai/https://jina.ai devrait être "Accessible".
{"usage":{"total_tokens":185,"prompt_tokens":185},"data":[{"object":"classification","index":0,"prediction":"Blocked","score":0.5392698049545288}]}L'API Classifier peut efficacement distinguer entre le contenu authentique et les résultats bloqués de Jina Reader.
Cet exemple utilise jina-embeddings-v3 et offre un moyen rapide et automatisé de surveiller l'accessibilité des sites web, utile pour les systèmes d'agrégation de contenu ou de web scraping, particulièrement dans des contextes multilingues.
tagExemple 4 : Filtrage des déclarations et des opinions pour le grounding
Une autre application intrigante de la classification zéro-shot est le filtrage des affirmations de type factuel par rapport aux opinions dans les longs documents. Notez que le classificateur ne peut pas déterminer si quelque chose est factuellement vrai. Au lieu de cela, il identifie le texte qui est écrit dans le style d'une affirmation factuelle, qui peut ensuite être vérifié via une API de grounding, souvent très coûteuse. Ce processus en deux étapes est essentiel pour une vérification des faits efficace : d'abord filtrer toutes les opinions et sentiments, puis envoyer les affirmations restantes pour vérification.
Considérez ce paragraphe sur la Course à l'Espace des années 1960 :
The Space Race of the 1960s was a breathtaking testament to human ingenuity. When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era. The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance. NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973. While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent. On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars. The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination. The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle.
Ce texte mélange intentionnellement différents types d'écriture - des affirmations de type factuel (comme "Sputnik 1 a été lancé le 4 octobre 1959"), des opinions claires ("témoignage époustouflant"), un langage émotionnel ("a semé la peur dans les cœurs"), et des affirmations interprétatives ("marquant le début indéniable d'une nouvelle ère").
Le rôle du classificateur zéro-shot est purement sémantique - il identifie si un texte est écrit comme une affirmation ou comme une opinion/interprétation. Par exemple, "The Soviet Union launched Sputnik 1 on October 4, 1959" est écrit comme une affirmation, tandis que "The Space Race was a breathtaking testament" est clairement écrit comme une opinion.
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
# Step 1: Split text and classify
chunks = [chunk.strip() for chunk in text.split('.') if chunk.strip()]
labels = [
"subjective, opinion, feeling, personal experience, creative writing, position",
"fact"
]
# Classify chunks
classify_response = requests.post(
'https://api.jina.ai/v1/classify',
headers=headers,
json={
"model": "jina-embeddings-v3",
"input": [{"text": chunk} for chunk in chunks],
"labels": labels
}
)
# Sort chunks
subjective_chunks = []
factual_chunks = []
for chunk, classification in zip(chunks, classify_response.json()['data']):
if classification['prediction'] == labels[0]:
subjective_chunks.append(chunk)
else:
factual_chunks.append(chunk)
print("\nSubjective statements:", subjective_chunks)
print("\nFactual statements:", factual_chunks)Et vous obtiendrez :
Subjective statements: ['The Space Race of the 1960s was a breathtaking testament to human ingenuity', 'The silvery beeping of that simple satellite struck fear into the hearts of millions, as if the very stars had betrayed Western dominance', 'While some cynics claimed this was a waste of resources, the technological breakthroughs were absolutely worth every penny spent', "The Soviet space program, despite its early victories, ultimately couldn't match the superior American engineering and determination"]
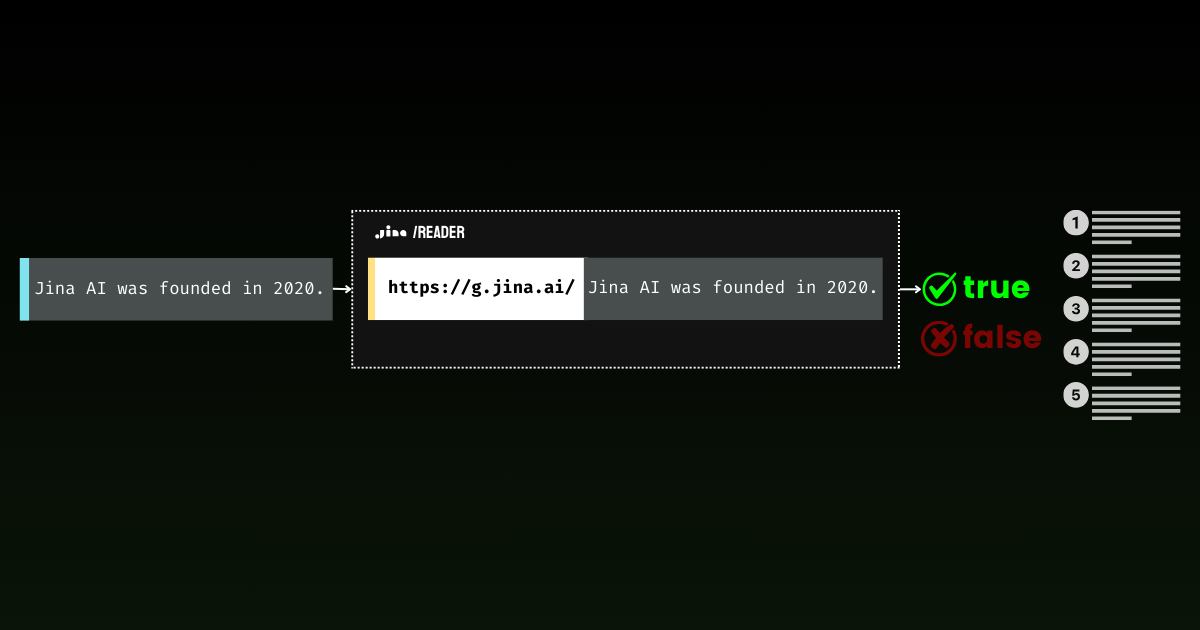
Factual statements: ['When the Soviet Union launched Sputnik 1 on October 4, 1957, it sent shockwaves through American society, marking the undeniable start of a new era', "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973", "On July 20, 1969, Neil Armstrong and Buzz Aldrin achieved the most magnificent triumph in human history by walking on the moon, their footprints marking humanity's destiny among the stars", 'The moon landing was not just a victory for America - it represented the most inspiring moment in human civilization, proving that our species was meant to reach beyond our earthly cradle']Rappelez-vous, ce n'est pas parce que quelque chose est écrit comme une affirmation que c'est vrai. C'est pourquoi nous avons besoin de la deuxième étape - alimenter ces affirmations de type factuel dans une API de grounding pour une vérification factuelle réelle. Par exemple, vérifions cette affirmation : "NASA was founded in 1958 as America's response, and they poured an astounding $28 billion into the Apollo program between 1960 and 1973" avec le code ci-dessous.
ground_headers = {
'Accept': 'application/json',
'Authorization': f'Bearer {API_KEY}'
}
ground_response = requests.get(
f'https://g.jina.ai/{quote(factual_chunks[1])}',
headers=ground_headers
)
print(ground_response.json())qui vous donne :
{'code': 200, 'status': 20000, 'data': {'factuality': 1, 'result': True, 'reason': "The statement is supported by multiple references confirming NASA's founding in 1958 and the significant financial investment in the Apollo program. The $28 billion figure aligns with the data provided in the references, which detail NASA's expenditures during the Apollo program from 1960 to 1973. Additionally, the context of NASA's budget peaking during this period further substantiates the claim. Therefore, the statement is factually correct based on the available evidence.", 'references': [{'url': 'https://en.wikipedia.org/wiki/Budget_of_NASA', 'keyQuote': "NASA's budget peaked in 1964–66 when it consumed roughly 4% of all federal spending. The agency was building up to the first Moon landing and the Apollo program was a top national priority, consuming more than half of NASA's budget.", 'isSupportive': True}, {'url': 'https://en.wikipedia.org/wiki/NASA', 'keyQuote': 'Established in 1958, it succeeded the National Advisory Committee for Aeronautics (NACA)', 'isSupportive': True}, {'url': 'https://nssdc.gsfc.nasa.gov/planetary/lunar/apollo.html', 'keyQuote': 'More details on Apollo lunar landings', 'isSupportive': True}, {'url': 'https://usafacts.org/articles/50-years-after-apollo-11-moon-landing-heres-look-nasas-budget-throughout-its-history/', 'keyQuote': 'NASA has spent its money so far.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/history/', 'keyQuote': 'Discover the history of our human spaceflight, science, technology, and aeronautics programs.', 'isSupportive': True}, {'url': 'https://www.nasa.gov/the-apollo-program/', 'keyQuote': 'Commander for Apollo 11, first to step on the lunar surface.', 'isSupportive': True}, {'url': 'https://www.planetary.org/space-policy/cost-of-apollo', 'keyQuote': 'A rich data set tracking the costs of Project Apollo, free for public use. Includes unprecedented program-by-program cost breakdowns.', 'isSupportive': True}, {'url': 'https://www.statista.com/statistics/1342862/nasa-budget-project-apollo-costs/', 'keyQuote': 'NASA's monetary obligations compared to Project Apollo's total costs from 1960 to 1973 (in million U.S. dollars)', 'isSupportive': True}], 'usage': {'tokens': 10640}}}Avec un score de factualité de 1, l'API de grounding confirme que cette affirmation est bien fondée historiquement. Cette approche ouvre des possibilités fascinantes, de l'analyse de documents historiques à la vérification des faits dans les articles d'actualité en temps réel. En combinant la classification zéro-shot avec la vérification des faits, nous créons un pipeline puissant pour l'analyse automatisée de l'information - d'abord en filtrant les opinions, puis en vérifiant les affirmations restantes auprès de sources fiables.
tagRemarques sur la Classification Zéro-Shot
Utilisation des Étiquettes Sémantiques
Lorsque vous travaillez avec la classification zéro-shot, il est crucial d'utiliser des étiquettes sémantiquement significatives plutôt que des symboles abstraits ou des nombres. Par exemple, "Technology", "Nature", et "Food" sont beaucoup plus efficaces que "Class1", "Class2", "Class3" ou "0", "1", "2". "Positive sentiment" est plus efficace que "Positive" et "True". Les modèles d'embedding comprennent les relations sémantiques, donc des étiquettes descriptives permettent au modèle d'exploiter ses connaissances pré-entraînées pour des classifications plus précises. Notre article précédent explore comment créer des étiquettes sémantiques efficaces pour de meilleurs résultats de classification.

Nature Sans État
La classification zéro-shot est fondamentalement sans état, contrairement aux approches traditionnelles d'apprentissage automatique. Cela signifie que pour une même entrée et un même modèle, les résultats seront toujours cohérents, peu importe qui utilise l'API ou quand. Le modèle n'apprend pas et ne se met pas à jour en fonction des classifications qu'il effectue ; chaque tâche est indépendante. Cela permet une utilisation immédiate sans configuration ni entraînement, et offre la flexibilité de changer de catégories entre les appels API.
Cette nature sans état contraste fortement avec les approches d'apprentissage few-shot et en ligne, que nous explorerons ensuite. Dans ces méthodes, les modèles peuvent s'adapter à de nouveaux exemples, donnant potentiellement des résultats différents au fil du temps ou entre les utilisateurs.
tagClassification Few-Shot
La classification few-shot offre une approche facile pour créer et mettre à jour des classificateurs avec un minimum de données étiquetées. Cette méthode fournit deux points d'accès principaux : train et classify.
Le point d'accès train vous permet de créer ou de mettre à jour un classificateur avec un petit ensemble d'exemples. Votre premier appel à train retournera un
classifier_id, que vous pouvez utiliser pour les entraînements ultérieurs lorsque vous avez de nouvelles données, constatez des changements dans la distribution des données ou devez ajouter de nouvelles classes. Cette approche flexible permet à votre classifieur d'évoluer au fil du temps, s'adaptant à de nouveaux modèles et catégories sans repartir de zéro.Comme pour la classification zero-shot, vous utiliserez le point de terminaison classify pour faire des prédictions. La principale différence est que vous devrez inclure votre classifier_id dans la requête, mais vous n'aurez pas besoin de fournir des labels candidats puisqu'ils font déjà partie de votre modèle entraîné.
tagExemple : Entraîner un Assignateur de Tickets de Support
Explorons ces fonctionnalités à travers un exemple de classification des tickets de support client pour l'attribution à différentes équipes dans une startup technologique en pleine croissance.
Entraînement initial
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"model": "jina-embeddings-v3",
"access": "private",
"input": [
{
"text": "I cant log into my account after the latest app update.",
"label": "team1"
},
{
"text": "My subscription renewal failed due to an expired credit card.",
"label": "team2"
},
{
"text": "How do I export my data from the platform?",
"label": "team3"
}
],
"num_iters": 10
}'Notez que dans l'apprentissage few-shot, nous sommes libres d'utiliser team1 team2 comme labels de classe même s'ils n'ont pas de signification sémantique intrinsèque. Dans la réponse, vous obtiendrez un classifier_id qui représente ce nouveau classifieur.
{
"classifier_id": "918c0846-d6ae-4f34-810d-c0c7a59aee14",
"num_samples": 3,
}
Notez bien le classifier_id, vous en aurez besoin pour faire référence à ce classifieur plus tard.
Mise à jour du Classifieur pour Adapter la Restructuration d'Équipe
À mesure que l'entreprise exemple grandit, de nouveaux types de problèmes émergent et la structure de l'équipe change également. La beauté de la classification few-shot réside dans sa capacité à s'adapter rapidement à ces changements. Nous pouvons facilement mettre à jour le classifieur en donnant le classifier_id et de nouveaux exemples, introduisant de nouvelles catégories d'équipes (par exemple team4) ou réaffectant les types de problèmes existants à différentes équipes au fur et à mesure que l'organisation évolue.
curl -X 'POST' \
'https://api.jina.ai/v1/train' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "Im getting a 404 error when trying to access the new AI chatbot feature.",
"label": "team4"
},
{
"text": "The latest security patch is conflicting with my company firewall.",
"label": "team1"
},
{
"text": "I need help setting up SSO for my organization account.",
"label": "team5"
}
],
"num_iters": 10
}'Utilisation d'un Classifieur Entraîné
Pendant l'inférence, vous n'avez besoin que de fournir le texte d'entrée et le classifier_id. L'API gère la correspondance entre votre entrée et les classes précédemment entraînées, renvoyant le label le plus approprié basé sur l'état actuel du classifieur.
curl -X 'POST' \
'https://api.jina.ai/v1/classify' \
-H 'accept: application/json' \
-H 'Authorization: Bearer YOUR_API_KEY_HERE' \
-H 'Content-Type: application/json' \
-d '{
"classifier_id": "b36b7b23-a56c-4b52-a7ad-e89e8f5439b6",
"input": [
{
"text": "The new feature is causing my dashboard to load slowly."
},
{
"text": "I need to update my billing information for tax purposes."
}
]
}'Le mode few-shot a deux paramètres uniques.
tagParamètre num_iters
Le paramètre num_iters ajuste l'intensité avec laquelle le classifieur apprend de vos exemples d'entraînement. Bien que la valeur par défaut de 10 fonctionne bien dans la plupart des cas, vous pouvez ajuster stratégiquement cette valeur en fonction de votre confiance dans les données d'entraînement. Pour des exemples de haute qualité qui sont cruciaux pour la classification, augmentez num_iters pour renforcer leur importance. À l'inverse, pour des exemples moins fiables, diminuez num_iters pour minimiser leur impact sur les performances du classifieur. Ce paramètre peut également être utilisé pour implémenter un apprentissage tenant compte du temps, où les exemples plus récents obtiennent des nombres d'itérations plus élevés pour s'adapter aux modèles évolutifs tout en maintenant les connaissances historiques.
tagParamètre access
Le paramètre access vous permet de contrôler qui peut utiliser votre classifieur. Par défaut, les classifieurs sont privés et uniquement accessibles à vous. Le réglage de l'accès sur "public" permet à quiconque possédant votre classifier_id de l'utiliser avec sa propre clé API et son quota de jetons. Cela permet le partage des classifieurs tout en maintenant la confidentialité - les utilisateurs ne peuvent pas voir vos données d'entraînement ou votre configuration, et vous ne pouvez pas voir leurs requêtes de classification. Ce paramètre n'est pertinent que pour la classification few-shot, car les classifieurs zero-shot sont sans état. Il n'est pas nécessaire de partager les classifieurs zero-shot puisque des requêtes identiques donneront toujours les mêmes réponses, quel que soit leur auteur.
tagRemarques sur l'Apprentissage Few-Shot
La classification few-shot dans notre API présente certaines caractéristiques uniques à noter. Contrairement aux modèles d'apprentissage automatique traditionnels, notre implémentation utilise un apprentissage en ligne en une passe - les exemples d'entraînement sont traités pour mettre à jour les poids du classifieur mais ne sont pas stockés par la suite. Cela signifie que vous ne pouvez pas récupérer les données d'entraînement historiques, mais cela garantit une meilleure confidentialité et efficacité des ressources.
Bien que l'apprentissage few-shot soit puissant, il nécessite une période de mise en route pour surpasser la classification zero-shot. Nos tests de référence montrent que 200-400 exemples d'entraînement fournissent généralement assez de données pour voir des performances supérieures. Cependant, vous n'avez pas besoin de fournir des exemples pour toutes les classes dès le départ - le classifieur peut évoluer pour accueillir de nouvelles classes au fil du temps. Sachez simplement que les classes nouvellement ajoutées peuvent connaître une brève période de démarrage à froid ou un déséquilibre de classes jusqu'à ce que suffisamment d'exemples soient fournis.
tagBenchmark
Pour notre analyse comparative, nous avons évalué les approches zero-shot et few-shot sur divers jeux de données, incluant des tâches de classification de texte comme la détection d'émotions (6 classes) et la détection de spam (2 classes), ainsi que des tâches de classification d'images comme CIFAR10 (10 classes). Le cadre d'évaluation a utilisé des divisions standard train-test, le zero-shot ne nécessitant aucune donnée d'entraînement et le few-shot utilisant des portions de l'ensemble d'entraînement. Nous avons suivi des métriques clés comme la taille d'entraînement et le nombre de classes cibles, permettant des comparaisons contrôlées. Pour assurer la robustesse, particulièrement pour l'apprentissage few-shot, chaque entrée est passée par plusieurs itérations d'entraînement. Nous avons comparé ces approches modernes avec des références traditionnelles comme le SVM Linéaire et le SVM RBF pour donner un contexte à leurs performances.



Les scores F1 sont représentés. Pour les paramètres complets du benchmark, veuillez consulter ce tableur Google.
Les graphiques F1 révèlent des tendances intéressantes à travers trois tâches. Sans surprise, la classification zero-shot montre une performance constante dès le départ, indépendamment de la taille des données d'entraînement. En revanche, l'apprentissage few-shot démontre une courbe d'apprentissage rapide, commençant plus bas mais dépassant rapidement les performances du zero-shot à mesure que les données d'entraînement augmentent. Les deux méthodes finissent par atteindre une précision comparable autour des 400 échantillons, avec un léger avantage pour le few-shot. Ce modèle se vérifie tant pour les scénarios de classification multi-classes que pour la classification d'images, suggérant que l'apprentissage few-shot peut être particulièrement avantageux lorsque des données d'entraînement sont disponibles, tandis que le zero-shot offre des performances fiables même sans exemples d'entraînement. Le tableau ci-dessous résume la différence entre la classification zero-shot et few-shot du point de vue de l'utilisateur de l'API.
| Feature | Zero-shot | Few-shot |
|---|---|---|
| Primary Use Case | Default solution for general classification | For data outside v3/clip-v1's domain or time-sensitive data |
| Training Data Required | No | Yes |
| Labels Required in /train | N/A | Yes |
| Labels Required in /classify | Yes | No |
| Classifier ID Required | No | Yes |
| Semantic Labels Required | Yes | No |
| State Management | Stateless | Stateful |
| Continuous Model Updates | No | Yes |
| Access Control | No | Yes |
| Maximum Classes | 256 | 16 |
| Maximum Classifiers | N/A | 16 |
| Maximum Inputs per Request | 1,024 | 1,024 |
| Maximum Token Length per Input | 8,192 tokens | 8,192 tokens |
tagRésumé
L'API Classifier offre une classification zero-shot et few-shot puissante pour le contenu textuel et les images, alimentée par des modèles d'embedding avancés comme jina-embeddings-v3 et jina-clip-v1. Nos tests de performance montrent que la classification zero-shot fournit des performances fiables sans données d'entraînement, ce qui en fait un excellent point de départ pour la plupart des tâches avec une prise en charge jusqu'à 256 classes. Bien que l'apprentissage few-shot puisse atteindre une précision légèrement meilleure avec des données d'entraînement, nous recommandons de commencer par la classification zero-shot pour ses résultats immédiats et sa flexibilité.
La polyvalence de l'API prend en charge diverses applications, du routage des requêtes LLM à la détection de l'accessibilité des sites web et à la catégorisation de contenu multilingue. Que vous commenciez avec le zero-shot ou que vous passiez à l'apprentissage few-shot pour des cas spécialisés, l'API maintient une interface cohérente pour une intégration transparente dans votre pipeline. Nous sommes particulièrement impatients de voir comment les développeurs exploiteront cette API dans leurs applications, et nous déploierons prochainement la prise en charge de nouveaux modèles d'embedding comme jina-clip-v2.




