


Il est difficile de dire si les gens détestent aimer le RAG ou aiment détester le RAG.
Selon les discussions récentes sur X et HN, le RAG devrait être mort, encore une fois. Cette fois, les critiques se concentrent sur la sur-ingénierie de la plupart des frameworks RAG qui, comme l'ont démontré @jeremyphoward @HamelHusain @Yampeleg, pourraient être réalisés avec 20 lignes de code Python.
La dernière fois que nous avons eu cette ambiance, c'était peu après la sortie de Claude/Gemini avec une fenêtre de contexte très longue. Ce qui rend cette fois-ci pire, c'est que même le RAG de Google génère des résultats amusants comme l'ont montré @icreatelife @mark_riedl, ce qui est ironique car en avril, lors du Google Next à Las Vegas, Google présentait le RAG comme la solution d'ancrage.
tagDeux problèmes du RAG
Je vois deux problèmes avec les frameworks et solutions RAG que nous avons aujourd'hui.
tagPropagation avant uniquement
Premièrement, presque tous les frameworks RAG implémentent uniquement un chemin de « propagation avant » et manquent d'un chemin de « rétropropagation ». C'est un système incomplet. Je me souviens de @swyx, dans l'un des épisodes de @latentspacepod, argumentant que le RAG ne sera pas tué par la longue fenêtre de contexte des LLM car :
- le contexte long est coûteux pour les développeurs et
- le contexte long est difficile à déboguer et manque de décomposabilité.
Mais si tous les frameworks RAG se concentrent uniquement sur le chemin de propagation avant, en quoi est-ce plus facile à déboguer qu'un LLM ? Il est également intéressant de voir combien de personnes s'enthousiasment pour les résultats auto-magiques du RAG à partir de quelques POC aléatoires et oublient complètement qu'ajouter plus de couches de propagation avant sans ajustement arrière est une terrible idée. Nous savons tous qu'ajouter une couche supplémentaire à vos réseaux de neurones étend son espace paramétrique et donc sa capacité de représentation, lui permettant de faire plus de choses potentielles, mais sans entraînement, ce n'est rien. Il y a pas mal de startups dans la Bay Area qui travaillent sur l'évaluation — essentiellement en essayant d'évaluer la perte d'un système de propagation avant. Est-ce utile ? Oui. Mais cela aide-t-il à fermer la boucle du RAG ? Non.
Alors qui travaille sur la rétropropagation du RAG ? À ma connaissance, pas beaucoup. Je connais principalement DSPy, une bibliothèque de @stanfordnlp @lateinteraction qui s'est donné cette mission.
 stanfordnlp
stanfordnlpMais même pour DSPy, l'accent principal est mis sur l'optimisation des démonstrations few-shot, pas sur le système complet (ou du moins selon l'usage de la communauté). Mais pourquoi ce problème est-il difficile ? Parce que le signal est très épars, et optimiser un système de pipeline non différentiable est essentiellement un problème combinatoire — en d'autres termes, extrêmement difficile. J'ai appris quelques optimisations sous-modulaires pendant mon doctorat, et j'ai le sentiment que cette technique sera bien utilisée dans l'optimisation RAG.
tagL'ancrage dans la nature est difficile
Je suis d'accord que le RAG sert à l'ancrage, malgré les résultats de recherche amusants de Google. Il existe deux types d'ancrage : l'ancrage de recherche, qui utilise les moteurs de recherche pour étendre les connaissances mondiales des LLM, et l'ancrage de vérification, qui utilise des connaissances privées (par exemple, des données propriétaires) pour faire de la vérification des faits.
Dans les deux cas, il cite des connaissances externes pour améliorer la factualité du résultat, à condition que ces ressources externes soient fiables. Dans les résultats de recherche amusants de Google, on peut facilement voir que tout sur le web n'est pas fiable (oui, grande surprise, qui l'eût cru !), ce qui fait paraître l'ancrage de recherche mauvais. Mais je crois que vous ne pouvez en rire que pour l'instant. Il existe des mécanismes de feedback implicites derrière l'interface utilisateur de Google Search qui collectent les réactions des utilisateurs à ces résultats et pondèrent la crédibilité du site web pour un meilleur ancrage. En général, cela devrait être assez temporaire, car ce RAG doit juste passer le démarrage à froid, et les résultats s'amélioreront avec le temps.
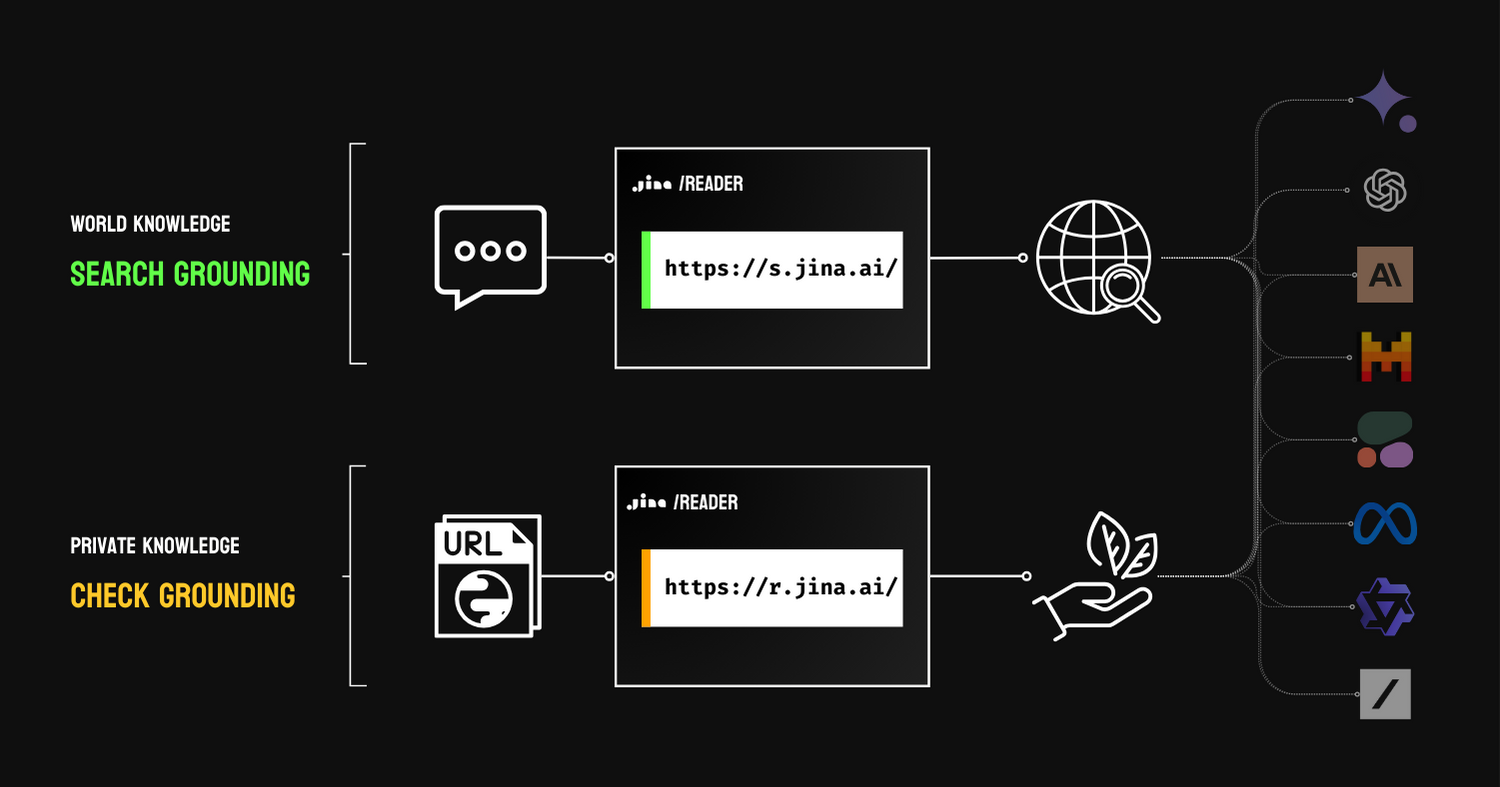


RAG a été présenté comme une solution d'ancrage lors de la conférence Google Next.
tagMon point de vue
RAG n'est ni mort ni vivant ; alors arrêtez d'en débattre. RAG n'est qu'un modèle algorithmique parmi d'autres que vous pouvez utiliser. Mais si vous en faites l'algorithme et que vous l'idolâtrez, alors vous vivez dans une bulle que vous avez créée, et cette bulle finira par éclater.
