



Nei nostri post precedenti, abbiamo esplorato le sfide del chunking e introdotto il concetto di late chunking, che aiuta a ridurre la perdita di contesto durante l'embedding dei chunk. In questo post, ci concentreremo su un'altra sfida: trovare i punti di interruzione ottimali. Mentre la nostra strategia di late chunking si è dimostrata piuttosto resiliente a confini non ottimali, questo non significa che possiamo ignorarli—sono ancora importanti sia per la leggibilità umana che per quella LLM. Ecco la nostra prospettiva: quando si determinano i punti di interruzione, possiamo ora concentrarci completamente sulla leggibilità senza preoccuparci della perdita semantica o di contesto. Il late chunking può gestire sia confini buoni che cattivi, quindi la leggibilità diventa la tua preoccupazione principale.
Con questo in mente, abbiamo addestrato tre piccoli modelli linguistici specificamente progettati per segmentare documenti lunghi mantenendo la coerenza semantica e gestendo strutture di contenuto complesse. Sono:

simple-qwen-0.5, che segmenta il testo basandosi sugli elementi strutturali del documento.

topic-qwen-0.5, che segmenta il testo basandosi sui topic presenti nel testo.

summary-qwen-0.5, che genera riassunti per ogni segmento.
In questo post, discuteremo perché abbiamo sviluppato questo modello, come abbiamo approcciato le sue tre varianti e come si confrontano con la Segmenter API di Jina AI. Infine, condivideremo ciò che abbiamo imparato e alcune riflessioni per il futuro.
tagIl Problema della Segmentazione
La segmentazione è un elemento fondamentale nei sistemi RAG. Il modo in cui dividiamo i documenti lunghi in segmenti coerenti e gestibili influenza direttamente la qualità sia delle fasi di recupero che di generazione, influenzando tutto, dalla pertinenza delle risposte alla qualità della sintesi. I metodi di segmentazione tradizionali hanno prodotto risultati discreti ma non sono privi di limitazioni.
Per parafrasare il nostro post precedente:
Quando si segmenta un documento lungo, una sfida chiave è decidere dove creare i segmenti. Questo può essere fatto usando lunghezze fisse di token, un numero fisso di frasi o metodi più avanzati come regex e modelli di segmentazione semantica. Stabilire confini di segmento accurati è cruciale, poiché non solo migliora la leggibilità dei risultati di ricerca ma assicura anche che i segmenti forniti a un LLM in un sistema RAG siano sia precisi che sufficienti.
Mentre il late chunking migliora le prestazioni di recupero, nelle applicazioni RAG, è cruciale assicurarsi che, per quanto possibile, ogni segmento sia significativo di per sé, e non solo un chunk casuale di testo. Gli LLM si basano su dati coerenti e ben strutturati per generare risposte accurate. Se i segmenti sono incompleti o privi di significato, l'LLM potrebbe avere difficoltà con il contesto e l'accuratezza, impattando le prestazioni complessive nonostante i benefici del late chunking. In breve, che si utilizzi o meno il late chunking, avere una solida strategia di segmentazione è essenziale per costruire un sistema RAG efficace (come vedrai nella sezione benchmark più avanti).
I metodi di segmentazione tradizionali, sia che dividano il contenuto a confini semplici come nuove righe o frasi, sia che utilizzino regole rigide basate sui token, spesso affrontano le stesse limitazioni. Entrambi gli approcci non tengono conto dei confini semantici e faticano con topic ambigui, portando a segmenti frammentati. Per affrontare queste sfide, abbiamo sviluppato e addestrato un piccolo modello linguistico specificamente per la segmentazione, progettato per catturare i cambi di topic e mantenere la coerenza pur rimanendo efficiente e adattabile a vari compiti.
tagPerché un Small Language Model?
Abbiamo sviluppato uno Small Language Model (SLM) per affrontare specifiche limitazioni che abbiamo incontrato con le tecniche di segmentazione tradizionali, in particolare quando si gestiscono snippet di codice e altre strutture complesse come tabelle, liste e formule. Negli approcci tradizionali, che spesso si basano su conteggi di token o regole strutturali rigide, era difficile mantenere l'integrità di contenuti semanticamente coerenti. Per esempio, gli snippet di codice venivano frequentemente segmentati in più parti, rompendo il loro contesto e rendendo più difficile per i sistemi downstream comprenderli o recuperarli accuratamente.
Addestrando uno SLM specializzato, miravamo a creare un modello che potesse riconoscere intelligentemente e preservare questi confini significativi, assicurando che gli elementi correlati rimanessero insieme. Questo non solo migliora la qualità del recupero nei sistemi RAG ma migliora anche i task downstream come la sintesi e il question-answering, dove mantenere segmenti coerenti e contestualmente rilevanti è critico. L'approccio SLM offre una soluzione più adattabile e specifica per il task che i metodi di segmentazione tradizionali, con i loro confini rigidi, semplicemente non possono fornire.
tagAddestramento degli SLM: Tre Approcci
Abbiamo addestrato tre versioni del nostro SLM:
simple-qwen-0.5è il modello più diretto, progettato per identificare i confini basati sugli elementi strutturali del documento. La sua semplicità lo rende una soluzione efficiente per esigenze di segmentazione di base.topic-qwen-0.5, ispirato al ragionamento Chain-of-Thought, porta la segmentazione un passo avanti identificando i topic all'interno del testo, come "l'inizio della Seconda Guerra Mondiale", e utilizzando questi topic per definire i confini dei segmenti. Questo modello assicura che ogni segmento sia coeso dal punto di vista tematico, rendendolo ben adatto per documenti complessi con più topic. I test iniziali hanno mostrato che eccelle nel segmentare contenuti in un modo che rispecchia da vicino l'intuizione umana.summary-qwen-0.5non solo identifica i confini del testo ma genera anche riassunti per ogni segmento. Riassumere i segmenti è altamente vantaggioso nelle applicazioni RAG, specialmente per task come il question-answering su documenti lunghi, sebbene comporti il compromesso di richiedere più dati durante l'addestramento.
Tutti i modelli restituiscono solo segment heads—una versione troncata di ogni segmento. Invece di generare segmenti interi, i modelli producono punti chiave o sottotopic, che migliora il rilevamento dei confini e la coerenza concentrandosi sulle transizioni semantiche piuttosto che semplicemente copiare il contenuto di input. Quando si recuperano i segmenti, il testo del documento viene diviso basandosi su queste segment heads, e i segmenti completi vengono ricostruiti di conseguenza.
tagDataset
Abbiamo utilizzato il dataset wiki727k, una vasta collezione di snippet di testo strutturati estratti da articoli di Wikipedia. Contiene oltre 727.000 sezioni di testo, ognuna rappresentante una parte distinta di un articolo di Wikipedia, come un'introduzione, una sezione o una sottosezione.
 koomri
koomritagData Augmentation
Per generare coppie di addestramento per ogni variante del modello, abbiamo utilizzato GPT-4 per aumentare i nostri dati. Per ogni articolo nel nostro dataset di addestramento, abbiamo inviato il seguente prompt:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()Abbiamo utilizzato una semplice divisione per generare sezioni da ogni articolo, dividendo su \\n\\n\\n, e poi suddividendo ulteriormente su \\n\\n per ottenere quanto segue (in questo caso, un articolo su Common Gateway Interface):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
Abbiamo poi generato una struttura JSON con le sezioni, gli argomenti e i riassunti:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Common Gateway Interface in Web Servers",
"The History and Standardization of CGI",
"CGI Scripts for Editing Web Pages",
"Reducing Web Server Overhead in Command Invocation"
],
"summaries": [
"CGI fornisce un protocollo per i web server per eseguire programmi che generano pagine web dinamiche.",
"NCSA ha inizialmente definito CGI nel 1993, portando alla sua adozione come standard per i Web server e alla successiva formalizzazione in RFC 3875 presieduta da Ken Coar.",
"Questo testo descrive come uno script CGI può gestire la modifica e il salvataggio del contenuto delle pagine web attraverso form HTML.",
"Il testo discute le tecniche per minimizzare il sovraccarico del server dovuto alla frequente invocazione di comandi, incluso il preforking dei processi, l'utilizzo di programmi CGI precompilati e l'implementazione di moduli web server personalizzati."
]
}
Abbiamo anche aggiunto rumore mescolando i dati, aggiungendo caratteri/parole/lettere casuali, rimuovendo casualmente la punteggiatura e rimuovendo sempre i caratteri di nuova riga.
Tutto ciò può contribuire in parte allo sviluppo di un buon modello, ma solo fino a un certo punto. Per ottenere davvero il massimo, avevamo bisogno che il modello creasse blocchi coerenti senza compromettere gli snippet di codice. Per fare questo, abbiamo arricchito il dataset con codice, formule ed elenchi generati da GPT-4o.
tagIl Setup dell'Addestramento
Per addestrare i modelli, abbiamo implementato il seguente setup:
- Framework: Abbiamo utilizzato la libreria
transformersdi Hugging Face integrata conUnslothper l'ottimizzazione del modello. Questo è stato cruciale per ottimizzare l'uso della memoria e accelerare l'addestramento, rendendo possibile addestrare efficacemente modelli piccoli con dataset di grandi dimensioni. - Optimizer e Scheduler: Abbiamo utilizzato l'ottimizzatore AdamW con un learning rate lineare e warm-up steps, permettendoci di stabilizzare il processo di addestramento durante le epoche iniziali.
- Monitoraggio degli Esperimenti: Abbiamo monitorato tutti gli esperimenti di addestramento utilizzando Weights & Biases, registrando metriche chiave come la loss di training e validazione, i cambiamenti del learning rate e le prestazioni complessive del modello. Questo monitoraggio in tempo reale ci ha fornito indicazioni su come i modelli progredivano, permettendo rapidi aggiustamenti quando necessario per ottimizzare i risultati dell'apprendimento.
tagL'Addestramento
Utilizzando qwen2-0.5b-instruct come modello base, abbiamo addestrato tre varianti del nostro SLM con Unsloth, ciascuna con una diversa strategia di segmentazione in mente. Per i nostri campioni abbiamo utilizzato coppie di training, composte dal testo di un articolo da wiki727k e i risultanti sections, topics, o summaries (menzionati sopra nella sezione "Data Augmentation") a seconda del modello in addestramento.
simple-qwen-0.5: Abbiamo addestratosimple-qwen-0.5su 10.000 campioni con 5.000 step, ottenendo una rapida convergenza e rilevando efficacemente i confini tra sezioni di testo coese. La loss di training era 0,16.topic-qwen-0.5: Comesimple-qwen-0.5, abbiamo addestratotopic-qwen-0.5su 10.000 campioni con 5.000 step, ottenendo una loss di training di 0,45.summary-qwen-0.5: Abbiamo addestratosummary-qwen-0.5su 30.000 campioni con 15.000 step. Questo modello ha mostrato potenziale ma ha avuto una loss più alta (0,81) durante l'addestramento, suggerendo la necessità di più dati (circa il doppio del nostro conteggio campioni originale) per raggiungere il suo pieno potenziale.
tagI Segmenti
Ecco esempi di tre segmenti consecutivi da ciascuna strategia di segmentazione, insieme alla Jina Segmenter API. Per produrre questi segmenti abbiamo prima utilizzato Jina Reader per estrarre un post dal blog di Jina AI come testo semplice (inclusi tutti i dati della pagina, come header, footer, ecc), poi lo abbiamo passato a ciascun metodo di segmentazione.

tagJina Segmenter API
Jina Segmenter API ha adottato un approccio molto granulare alla segmentazione del post, dividendo su caratteri come \n, \t, ecc, per suddividere il testo in segmenti spesso molto piccoli. Guardando solo i primi tre, ha estratto search\\n, notifications\\n e NEWS\\n dalla barra di navigazione del sito web, ma nulla di rilevante per il contenuto del post stesso:

Più avanti, abbiamo finalmente ottenuto alcuni segmenti dal contenuto effettivo del blog post, anche se con poco contesto conservato in ciascuno:

(Nell'interesse dell'equità, abbiamo mostrato più segmenti per Segmenter API rispetto ai modelli, semplicemente perché altrimenti avrebbe avuto pochissimi segmenti significativi da mostrare)
tagsimple-qwen-0.5
simple-qwen-0.5 ha suddiviso il post del blog basandosi sulla struttura semantica, estraendo segmenti molto più lunghi con un significato coeso:
tagtopic-qwen-0.5
topic-qwen-0.5 ha prima identificato i topic basandosi sul contenuto del documento, poi ha segmentato il documento in base a questi topic:
tagsummary-qwen-0.5
summary-qwen-0.5 ha identificato i confini dei segmenti e generato un riassunto del contenuto all'interno di ciascun segmento:
tagBenchmark dei Modelli
Per valutare le prestazioni dei nostri modelli, abbiamo estratto otto post dal blog di Jina AI e generato sei domande e risposte di riferimento utilizzando GPT-4o.
Abbiamo applicato ogni metodo di segmentazione, inclusa Jina Segmenter API, a questi post del blog, e poi generato embedding per i segmenti risultanti utilizzando jina-embeddings-v3, senza late chunking o reranking.

Ogni set di segmenti è stato poi indicizzato separatamente e abbiamo utilizzato un sistema RAG per interrogare ciascun indice con le domande generate in precedenza.
topic-qwen-0.5 e summary-qwen-0.5 abbiamo indicizzato solo i segmenti stessi, non i riassunti o gli argomenti generati. L'indicizzazione di questi dati aggiuntivi probabilmente migliorerebbe ulteriormente le prestazioni.Per misurare le prestazioni, abbiamo confrontato le risposte generate dall'indice di ciascun metodo di segmentazione con le risposte di riferimento utilizzando i punteggi F1 dalla valutazione ROUGE-L, dove punteggi più alti indicano prestazioni migliori.
Per esempio, data la domanda: "Quali fattori influenzano le capacità di confronto numerico del modello jina-embeddings-v2-base-en?", abbiamo ricevuto le seguenti risposte:
tagRisposta di Riferimento (Generata da GPT-4o dal Testo Completo del Post):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
tagJina Segmenter API (punteggio: 0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
tagsimple-qwen-0.5 (punteggio: 0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
tagtopic-qwen-0.5 (punteggio: 0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
tagsummary-qwen-0.5 (0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5 è così basso?Questo è principalmente un caso particolare basato sulla specifica domanda che abbiamo posto al modello. Come si può vedere nella tabella sottostante, il punteggio ROUGE medio di
topic-qwen-0.5 è il più alto tra tutte le metodologie di segmentazione.Abbiamo anche valutato la velocità di ciascun metodo (misurando il tempo necessario per generare ed incorporare i segmenti) e stimato lo spazio su disco (moltiplicando il numero di embedding per la dimensione di un singolo embedding a 1024 dimensioni da jina-embeddings-v3). Questo ci ha permesso di valutare sia l'accuratezza che l'efficienza tra le diverse strategie di segmentazione.
tagRisultati Chiave
Dopo aver testato le varianti del modello tra loro e con la Jina Segmenter API, abbiamo scoperto che i nuovi modelli hanno effettivamente mostrato punteggi migliori utilizzando tutti e tre i metodi, specialmente la segmentazione per argomenti:
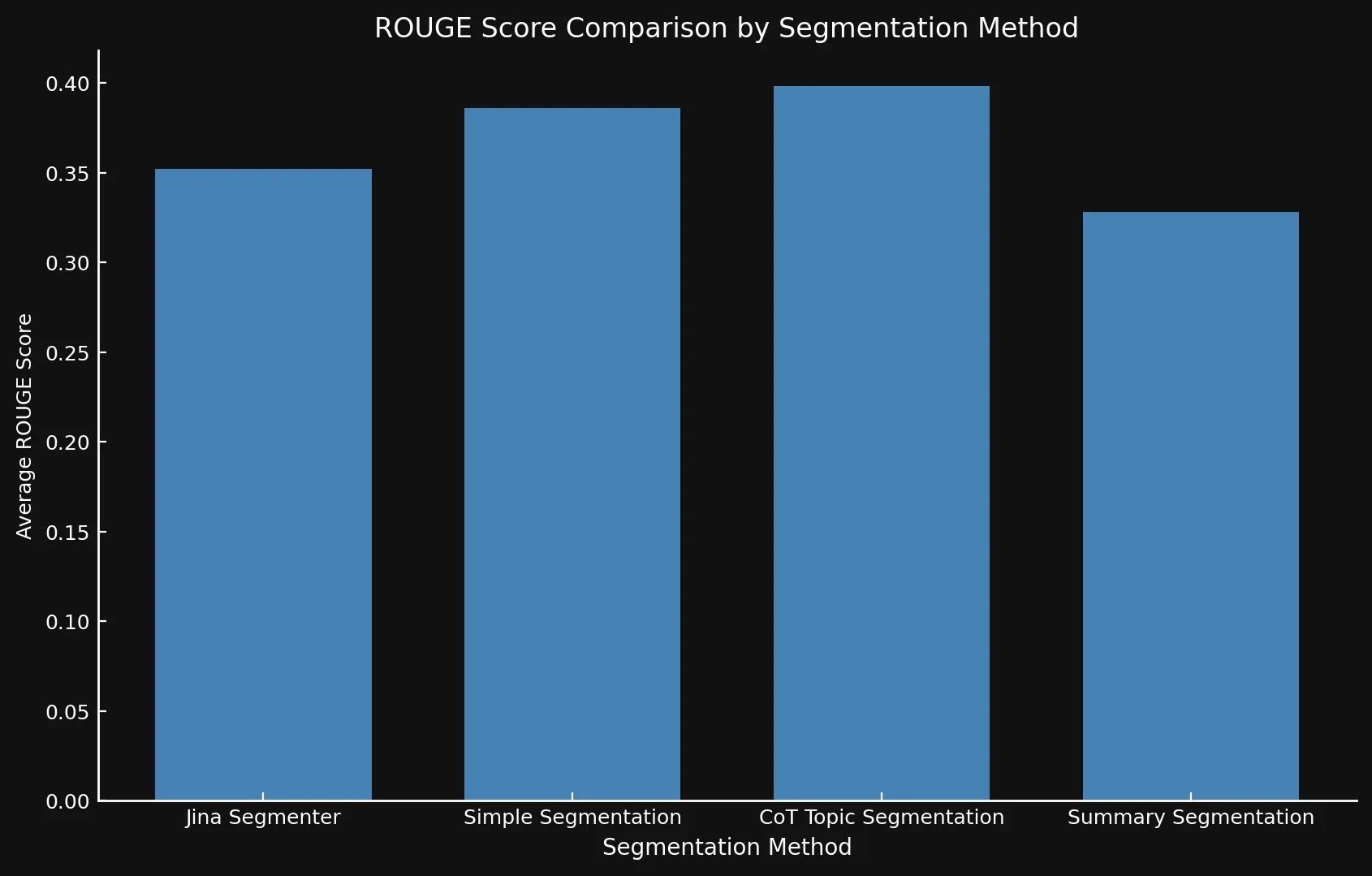
| Segmentation Method | Average ROUGE Score |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 ha un punteggio ROUGE più basso di topic-qwen-0.5? In breve, summary-qwen-0.5 ha mostrato una perdita più elevata durante l'addestramento, rivelando la necessità di un maggiore addestramento per ottenere risultati migliori. Questo potrebbe essere oggetto di sperimentazioni future.Tuttavia, sarebbe interessante rivedere i risultati con la funzionalità di chunking ritardato di jina-embeddings-v3, che aumenta la rilevanza contestuale degli embedding dei segmenti, fornendo risultati più pertinenti. Questo potrebbe essere argomento di un futuro post sul blog.
Per quanto riguarda la velocità, può essere difficile confrontare i nuovi modelli con Jina Segmenter, poiché quest'ultimo è un'API, mentre abbiamo eseguito i tre modelli su una GPU Nvidia 3090. Come si può vedere, qualsiasi vantaggio di prestazioni ottenuto durante la rapida fase di segmentazione dell'API Segmenter viene rapidamente superato dalla necessità di generare embedding per così tanti segmenti:
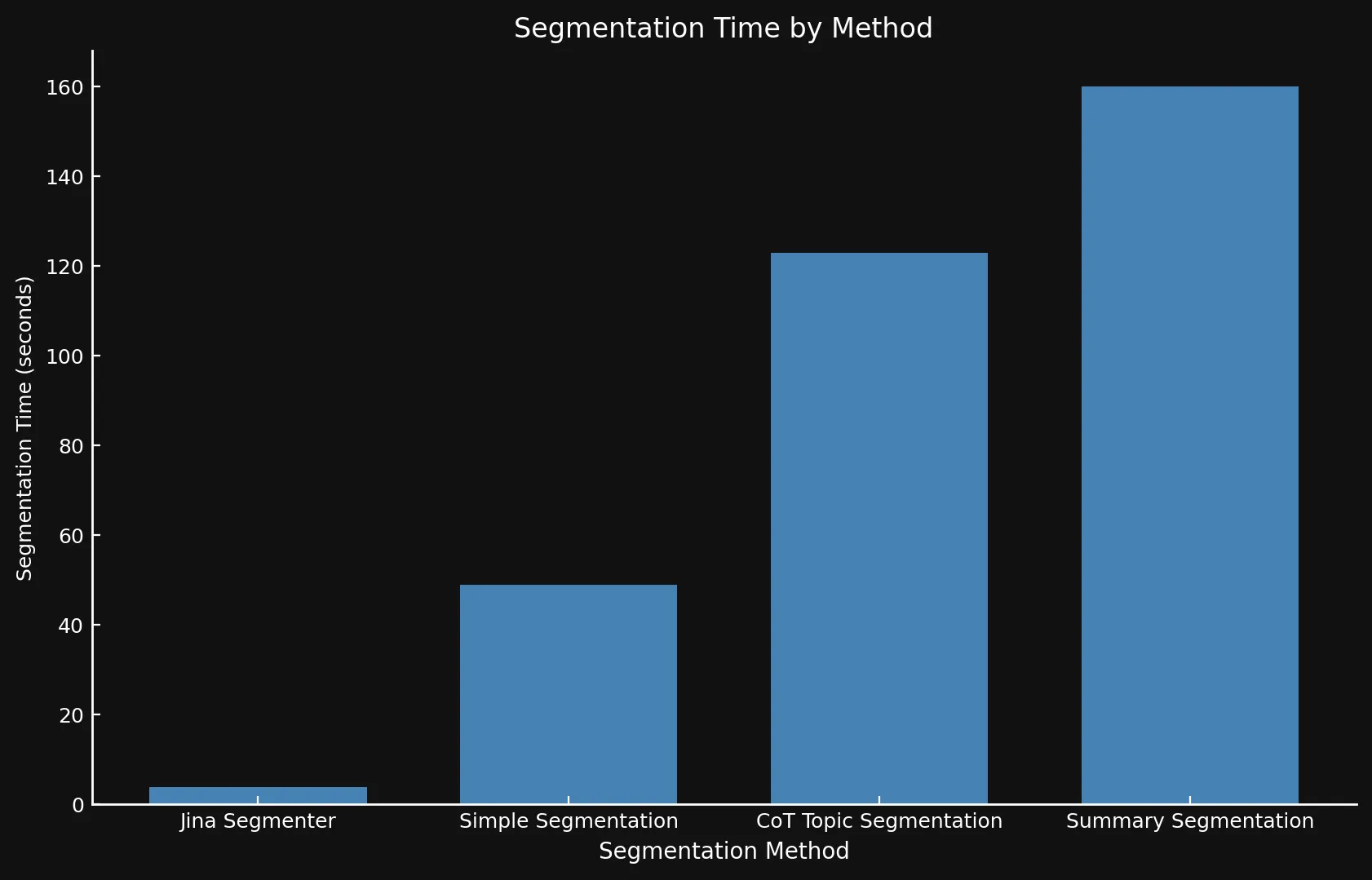
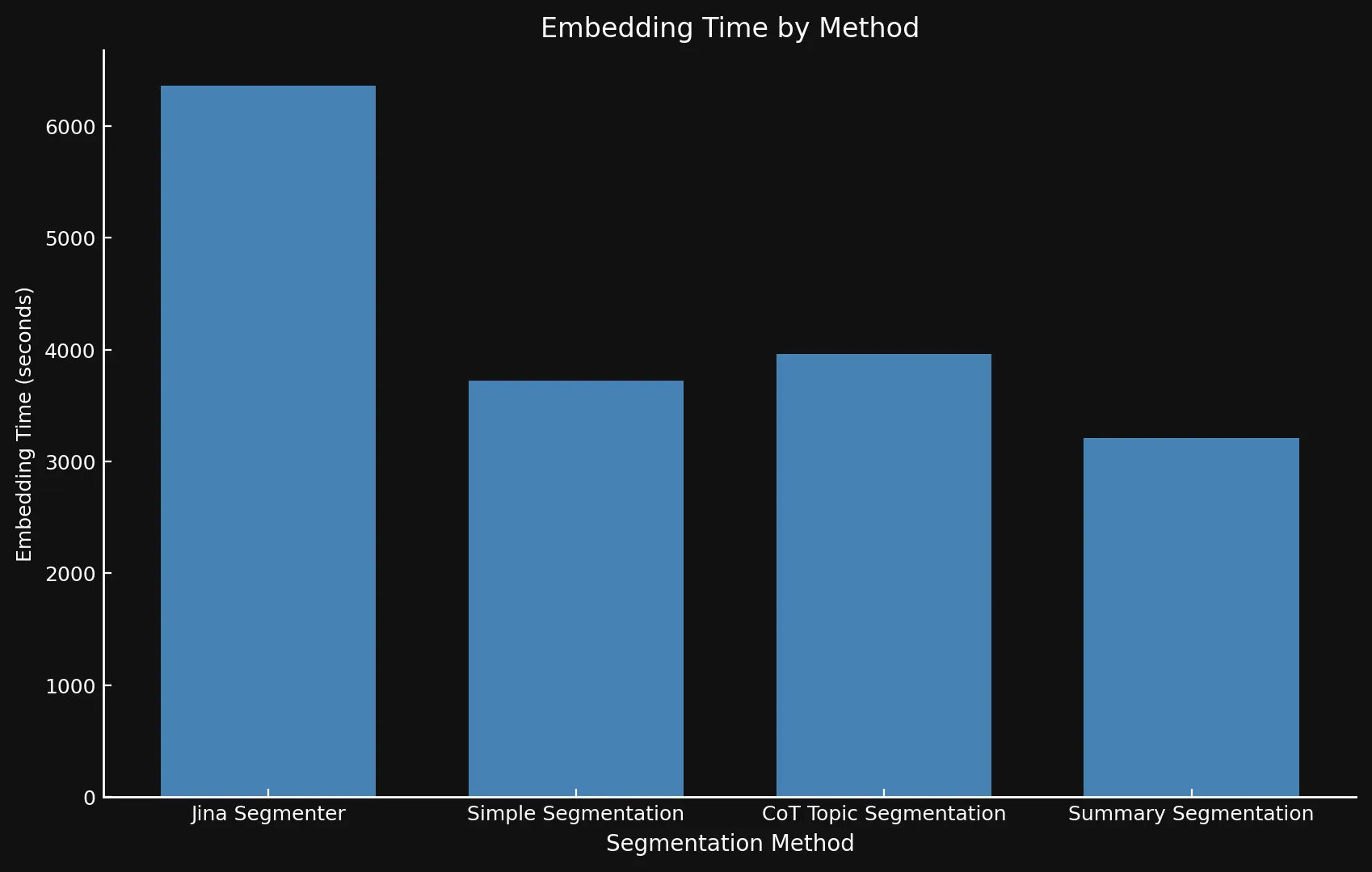
• Usiamo assi Y differenti su entrambi i grafici perché presentare intervalli di tempo così diversi con un solo grafico o assi Y coerenti non era fattibile.
• Poiché stavamo eseguendo questo puramente come esperimento, non abbiamo utilizzato il batching durante la generazione degli embedding. Farlo accelererebbe sostanzialmente le operazioni per tutti i metodi.
Naturalmente, più segmenti significano più embedding. E questi embedding occupano molto spazio: Gli embedding per gli otto post del blog che abbiamo testato occupavano oltre 21 MB con Segmenter API, mentre la Segmentazione per Riassunti si è attestata su un agile 468 KB. Questo, insieme ai punteggi ROUGE più alti dei nostri modelli, significa meno segmenti ma segmenti migliori, risparmiando denaro e aumentando le prestazioni:
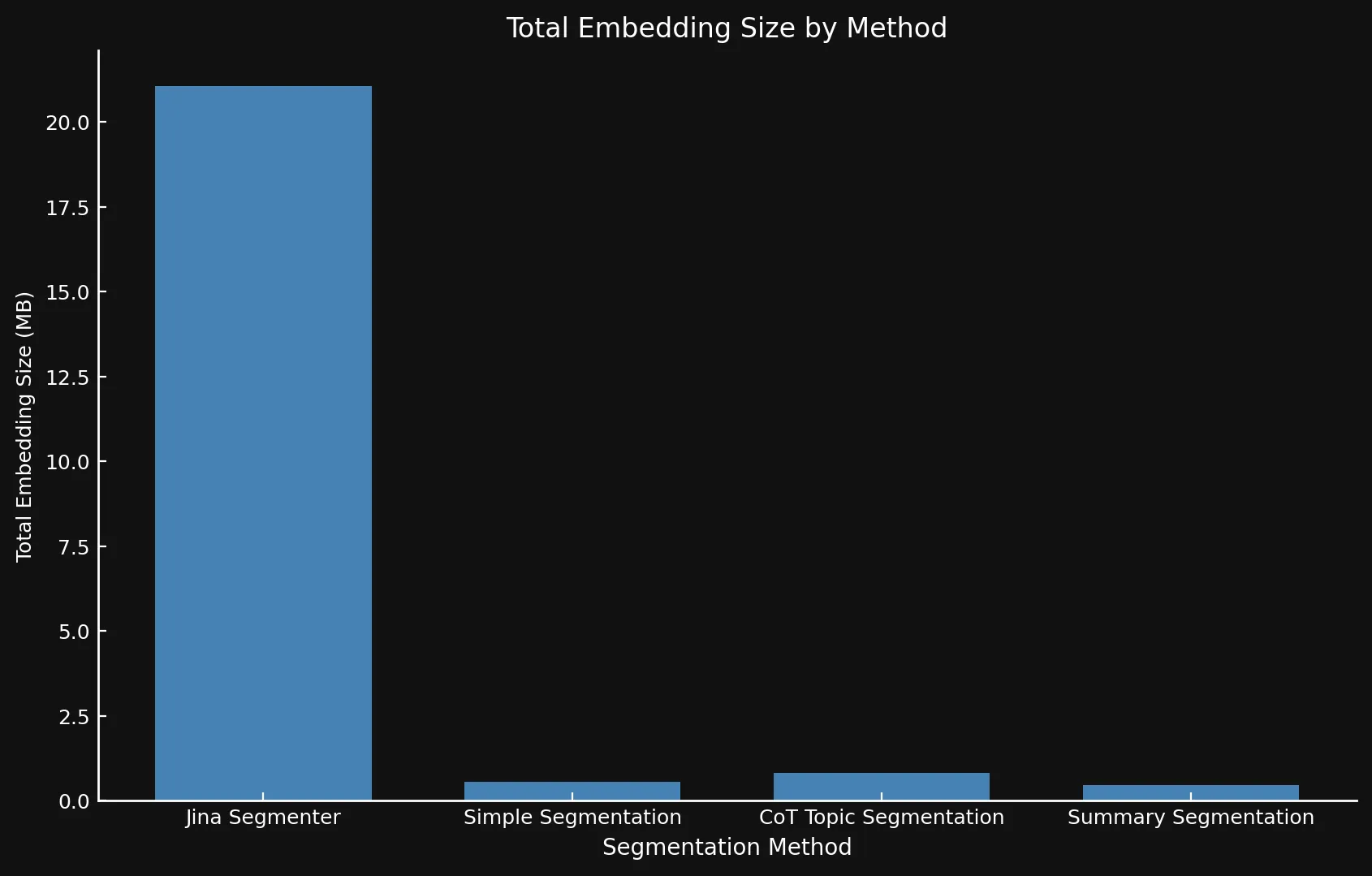
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
tagCosa Abbiamo Imparato
tagLa Formulazione del Problema è Fondamentale
Un'intuizione chiave è stata l'impatto di come abbiamo inquadrato il compito. Facendo generare al modello le intestazioni dei segmenti, abbiamo migliorato il rilevamento dei confini e la coerenza concentrandoci sulle transizioni semantiche piuttosto che semplicemente copiare e incollare il contenuto di input in segmenti separati. Questo ha anche portato a un modello di segmentazione più veloce, poiché la generazione di meno testo ha permesso al modello di completare il compito più rapidamente.
tagI Dati Generati da LLM sono Efficaci
L'utilizzo di dati generati da LLM, in particolare per contenuti complessi come liste, formule e snippet di codice, ha ampliato il set di training del modello e migliorato la sua capacità di gestire strutture documentali diverse. Questo ha reso il modello più adattabile a vari tipi di contenuti, un vantaggio cruciale quando si tratta di documenti tecnici o strutturati.
tagRaccolta Dati Solo Output
Utilizzando un data collator solo output, abbiamo assicurato che il modello si concentrasse sulla previsione dei token target durante l'addestramento, piuttosto che limitarsi a copiare dall'input. Il collator solo output ha garantito che il modello apprendesse dalle effettive sequenze target, enfatizzando i completamenti o i confini corretti. Questa distinzione ha permesso al modello di convergere più velocemente evitando l'overfitting sull'input e lo ha aiutato a generalizzare meglio su diversi dataset.
tagTraining Efficiente con Unsloth
Con Unsloth, abbiamo ottimizzato l'addestramento del nostro piccolo modello linguistico, riuscendo a eseguirlo su una GPU Nvidia 4090. Questa pipeline ottimizzata ci ha permesso di addestrare un modello efficiente e performante senza la necessità di enormi risorse computazionali.
tagGestione di Testi Complessi
I modelli di segmentazione si sono distinti nella gestione di documenti complessi contenenti codice, tabelle e liste, che sono tipicamente difficili per i metodi più tradizionali. Per contenuti tecnici, strategie sofisticate come topic-qwen-0.5 e summary-qwen-0.5 sono state più efficaci, con il potenziale di migliorare le attività RAG a valle.
tagMetodi Semplici per Contenuti più Semplici
Per contenuti lineari e narrativi, metodi più semplici come l'API Segmenter sono spesso sufficienti. Le strategie di segmentazione avanzate potrebbero essere necessarie solo per contenuti più complessi e strutturati, consentendo flessibilità a seconda del caso d'uso.
tagProssimi Passi
Sebbene questo esperimento fosse progettato principalmente come proof of concept, se dovessimo estenderlo ulteriormente, potremmo apportare diversi miglioramenti. Innanzitutto, anche se è improbabile la continuazione di questo specifico esperimento, l'addestramento di summary-qwen-0.5 su un dataset più grande—idealmente 60.000 campioni invece di 30.000—porterebbe probabilmente a prestazioni più ottimali. Inoltre, sarebbe vantaggioso perfezionare il nostro processo di benchmarking. Invece di valutare le risposte generate dall'LLM dal sistema RAG, ci concentreremmo invece sul confronto diretto dei segmenti recuperati con la verità di base. Infine, andremmo oltre i punteggi ROUGE e adotteremmo metriche più avanzate (possibilmente una combinazione di ROUGE e punteggio LLM) che catturino meglio le sfumature della qualità del recupero e della segmentazione.
tagConclusione
In questo esperimento, abbiamo esplorato come i modelli di segmentazione personalizzati progettati per compiti specifici possano migliorare le prestazioni del RAG. Sviluppando e addestrando modelli come simple-qwen-0.5, topic-qwen-0.5 e summary-qwen-0.5, abbiamo affrontato le sfide chiave riscontrate nei metodi di segmentazione tradizionali, in particolare nel mantenimento della coerenza semantica e nella gestione efficace di contenuti complessi come gli snippet di codice. Tra i modelli testati, topic-qwen-0.5 ha costantemente fornito la segmentazione più significativa e contestualmente rilevante, specialmente per documenti multi-argomento.
Mentre i modelli di segmentazione forniscono la base strutturale necessaria per i sistemi RAG, svolgono una funzione diversa rispetto al late chunking, che ottimizza le prestazioni di recupero mantenendo la rilevanza contestuale tra i segmenti. Questi due approcci possono essere complementari, ma la segmentazione è particolarmente cruciale quando è necessario un metodo che si concentri sulla suddivisione dei documenti per flussi di lavoro di generazione coerenti e specifici per il compito.
