
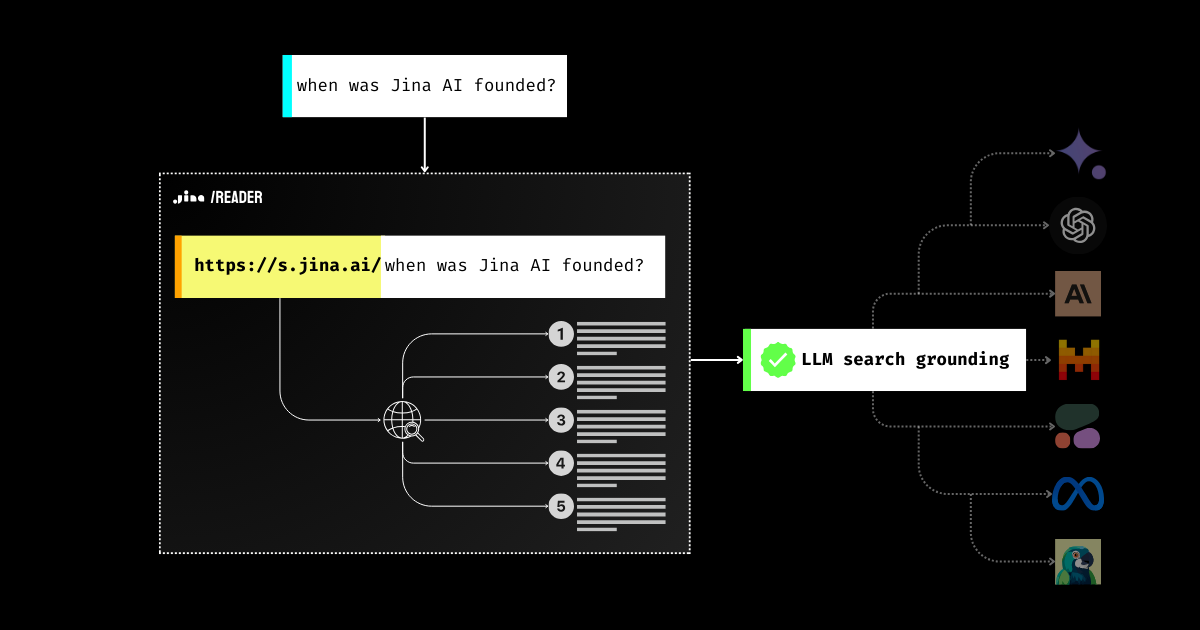

Il grounding è assolutamente essenziale per le applicazioni GenAI.
Probabilmente hai visto molti strumenti, prompt e pipeline RAG progettati per migliorare la fattualità degli LLM dal 2023. Perché? Perché la principale barriera che impedisce alle aziende di distribuire gli LLM a milioni di utenti è la fiducia: la risposta è genuina o è una mera allucinazione del modello? Questo è un problema che riguarda tutta l'industria e Jina AI sta lavorando duramente per risolverlo. Oggi, con la nuova funzionalità di ricerca di Jina Reader, puoi semplicemente usare https://s.jina.ai/YOUR_SEARCH_QUERY per cercare le ultime conoscenze dal web. Con questo, sei un passo più vicino a migliorare la fattualità degli LLM, rendendo le loro risposte più affidabili e utili.

API, demo disponibile nella pagina del prodotto
tagIl Problema della Fattualità degli LLM
Sappiamo tutti che gli LLM possono inventare cose e danneggiare la fiducia degli utenti. Gli LLM potrebbero dire cose non fattuali (cioè allucinare), specialmente riguardo argomenti che non hanno appreso durante l'addestramento. Questo potrebbe essere sia informazioni nuove create dopo l'addestramento sia conoscenze di nicchia che sono state "marginalizzate" durante l'addestramento.
Di conseguenza, quando si tratta di domande come "Che tempo fa oggi?" o "Chi ha vinto l'Oscar come Migliore Attrice quest'anno?" il modello risponderà con "Non lo so" oppure fornirà informazioni obsolete.
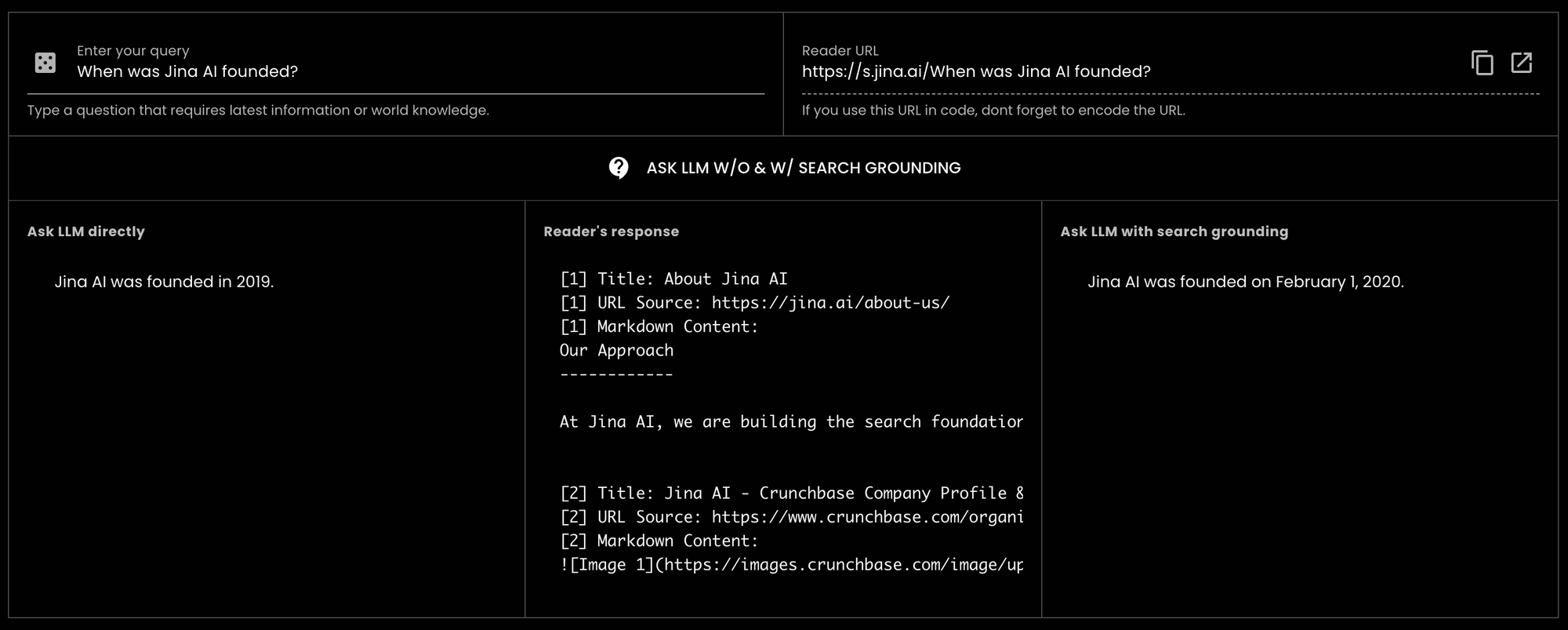
GPT-3.5-turbo "Quando è stata fondata Jina AI?" e abbiamo ricevuto una risposta errata. Tuttavia, utilizzando Reader per il search grounding, lo stesso LLM è stato in grado di fornire la risposta corretta. In effetti, è stato preciso fino alla data esatta.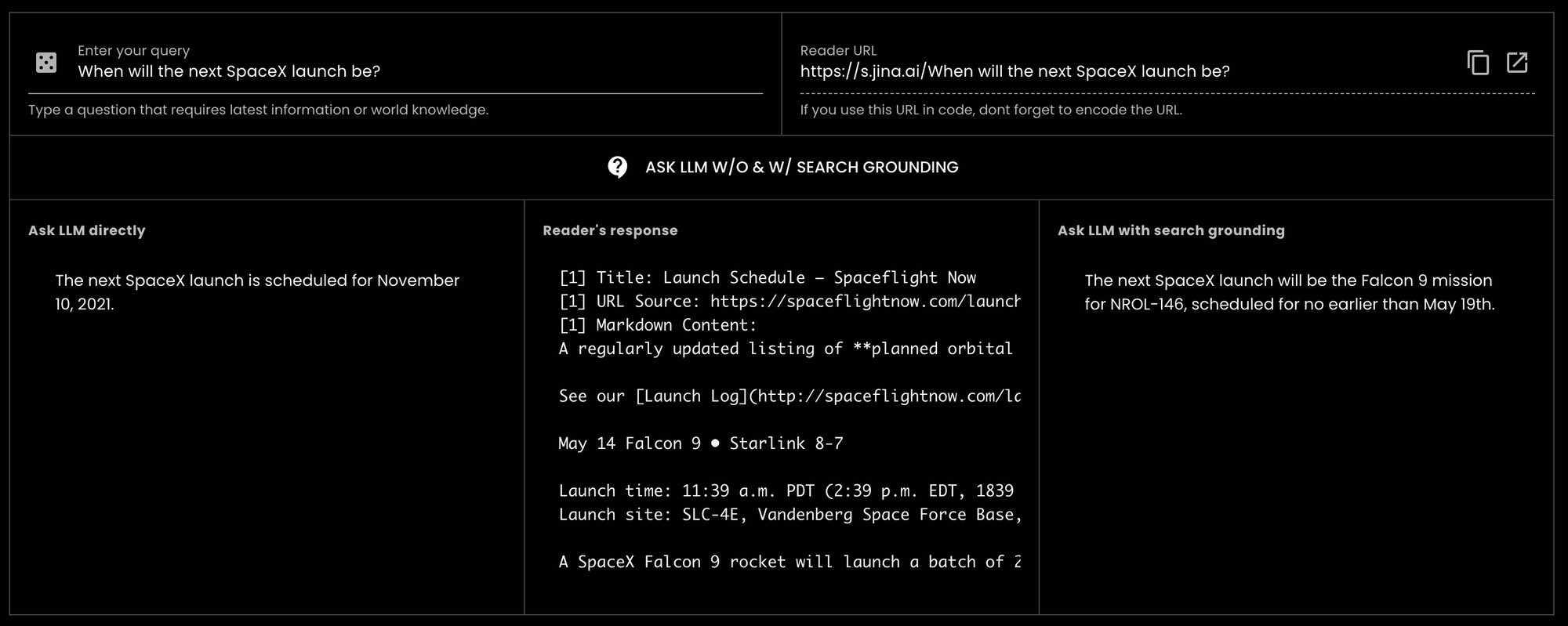
GPT-3.5-turbo "Quando sarà il prossimo lancio SpaceX?" (oggi è il 14 maggio 2024) e il modello ha risposto con informazioni vecchie del 2021.tagCome Jina Reader Aiuta a Migliorare il Grounding
In precedenza, gli utenti potevano facilmente anteporre https://r.jina.ai per leggere contenuti testuali e immagini da un particolare URL in un formato compatibile con LLM e utilizzarlo per il check grounding e la verifica dei fatti. Dalla sua prima release il 15 aprile, abbiamo servito oltre 18 milioni di richieste da tutto il mondo, suggerendo la sua popolarità.
Oggi siamo entusiasti di fare un ulteriore passo avanti introducendo l'API di search grounding https://s.jina.ai. Semplicemente anteponendola alla tua query, Reader cercherà sul web e recupererà i 5 risultati migliori. Ogni risultato include un titolo, markdown compatibile con LLM (contenuto completo! non abstract), e un URL che permette di attribuire la fonte. Ecco un esempio qui sotto, sei anche incoraggiato a provare la nostra demo live qui.
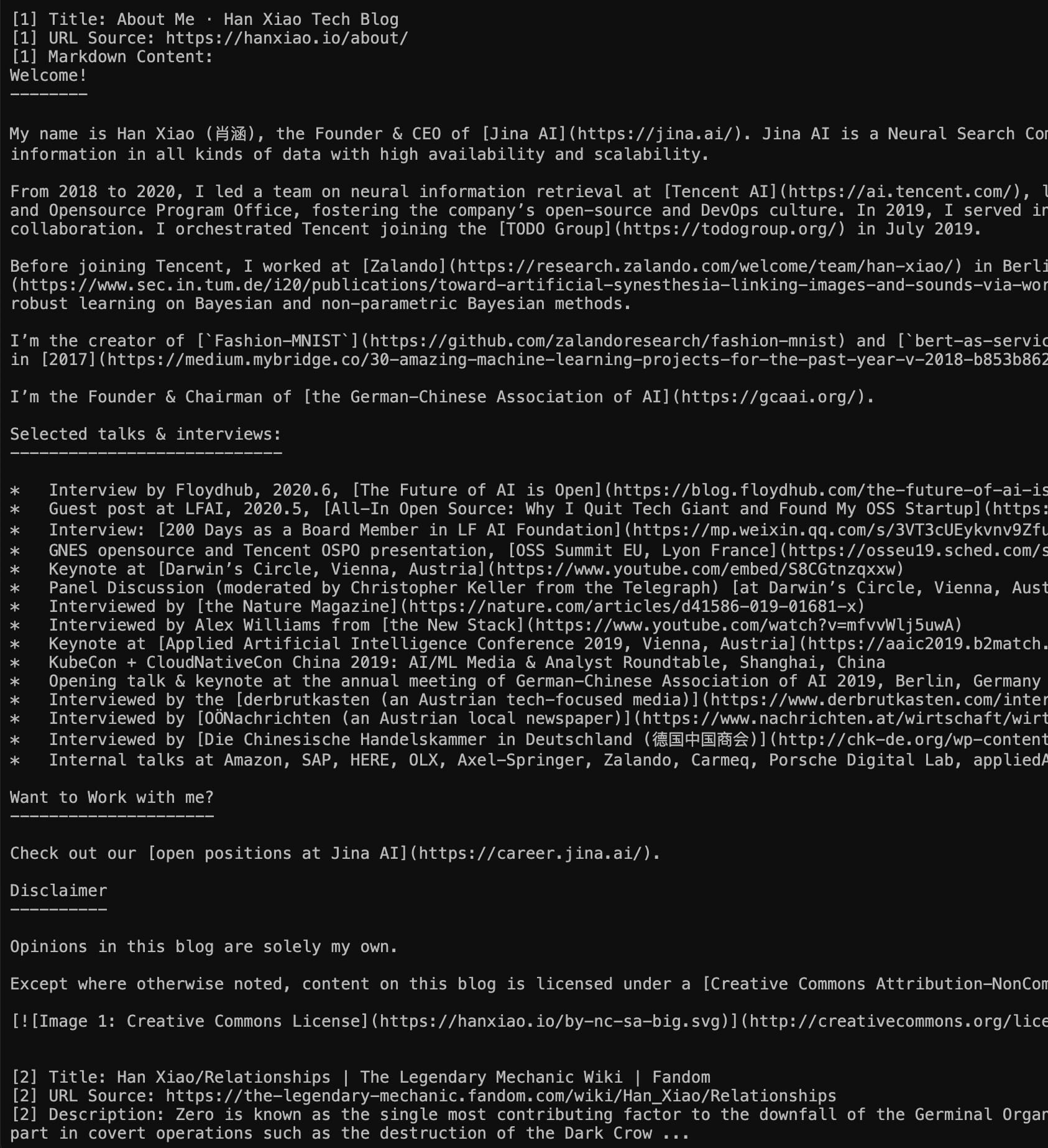
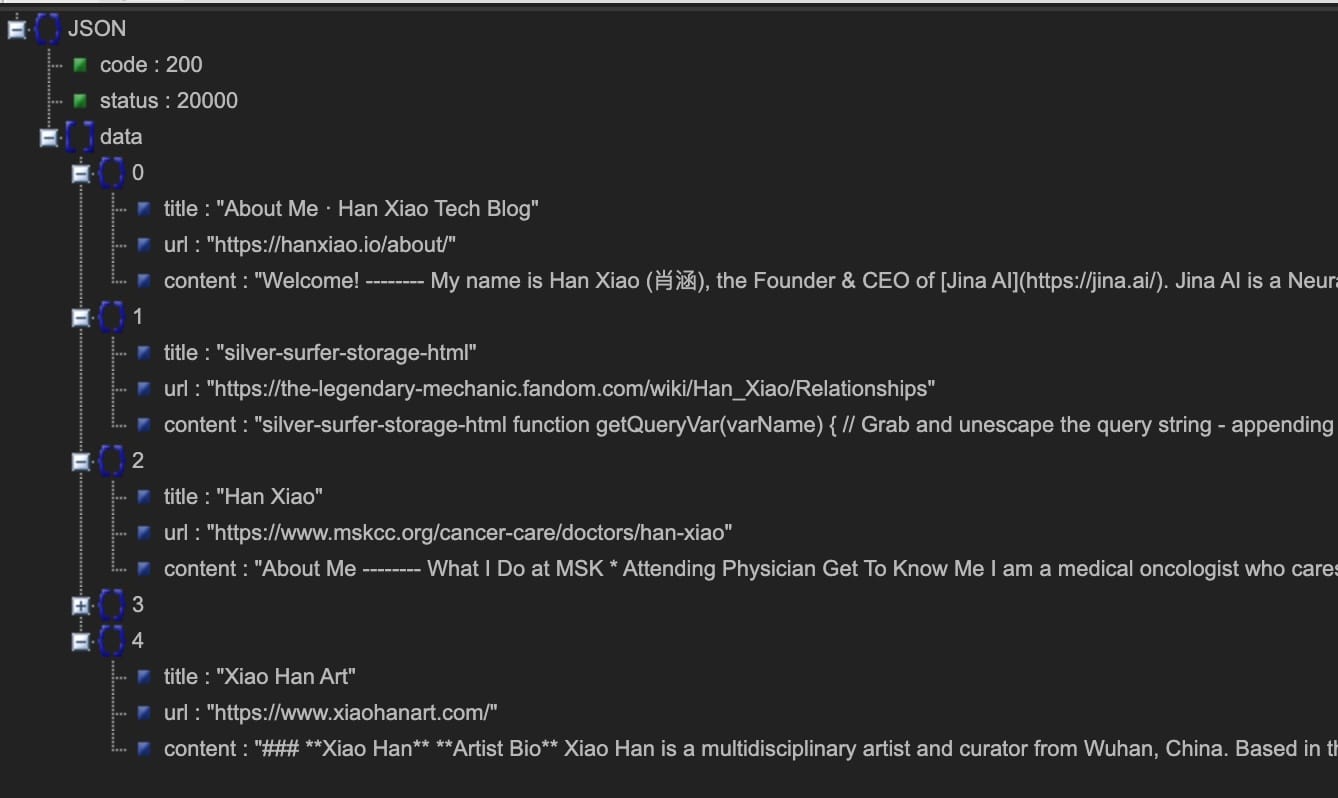
Sinistra: Modalità Markdown (visita direttamente https://s.jina.ai/who+is+han+xiao); Destra: Modalità JSON (usando curl https://s.jina.ai/who+is+han+xiao -H 'accept: application/json'). A proposito, una domanda ego come questa serve sempre come buon caso di test.
Ci sono tre principi nella progettazione del search grounding in Reader:
- Migliorare la fattualità;
- Accedere a informazioni aggiornate, cioè conoscenza del mondo;
- Collegare una risposta alla sua fonte.
Oltre ad essere estremamente facile da usare, s.jina.ai è anche altamente scalabile e personalizzabile poiché sfrutta l'infrastruttura flessibile e scalabile esistente di r.jina.ai. Puoi impostare parametri per controllare la generazione di didascalie delle immagini, la granularità del filtro, ecc., tramite gli header della richiesta.
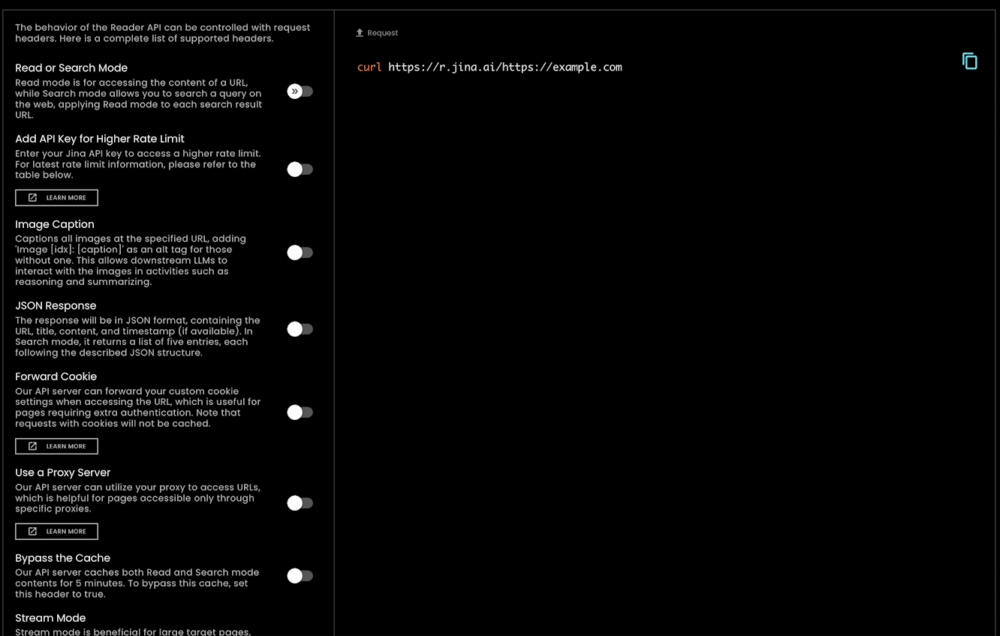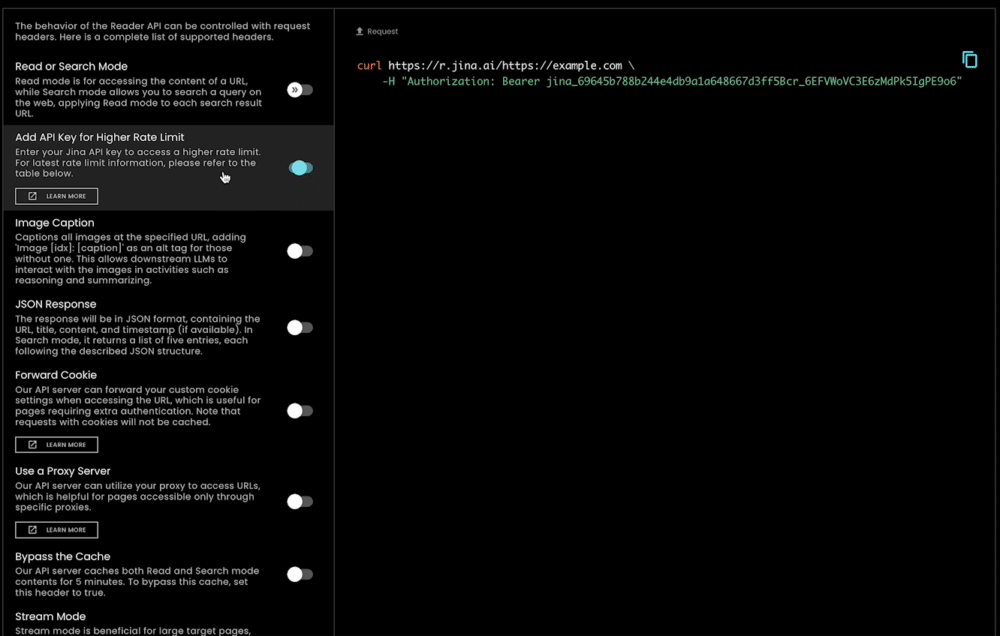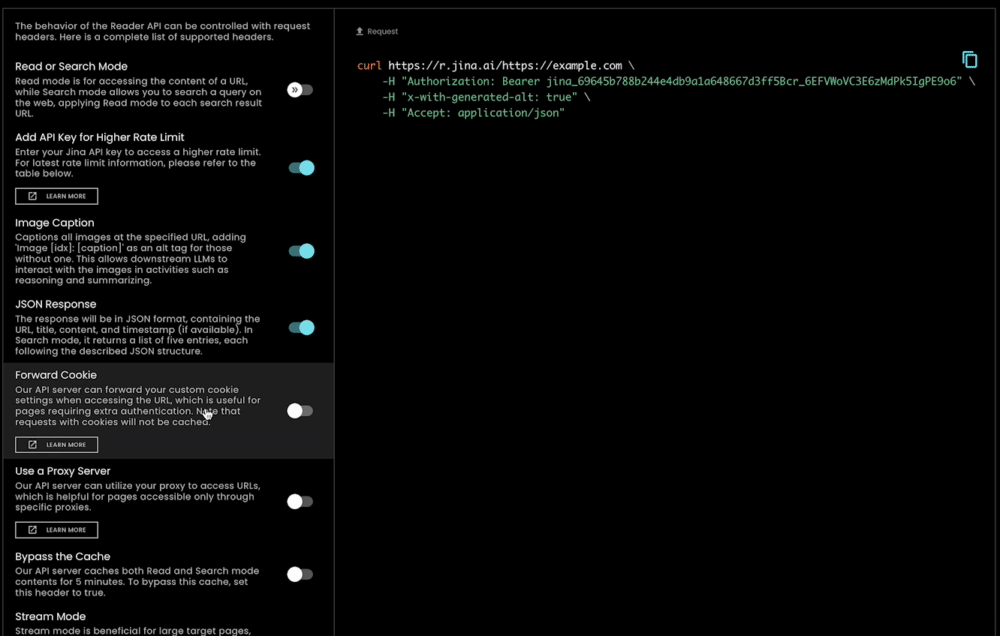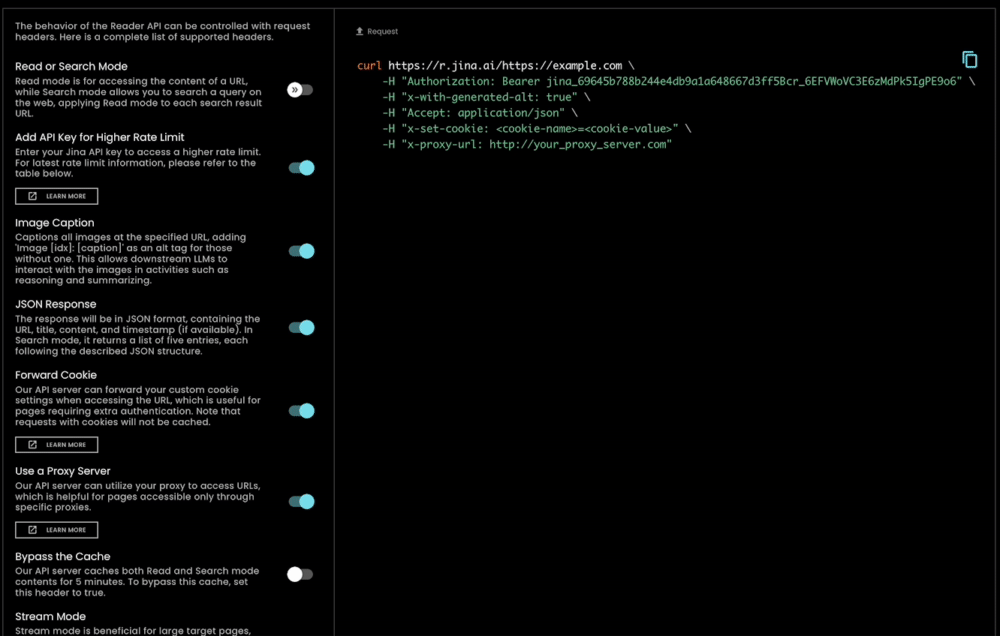
tagJina Reader come Soluzione Completa di Grounding

Se combiniamo il search grounding (s.jina.ai) e il check grounding (r.jina.ai), possiamo costruire una soluzione di grounding molto completa per LLM, agenti e sistemi RAG. In un tipico workflow RAG affidabile, Jina Reader funziona come segue:
- L'utente inserisce una domanda;
- Recupera le ultime informazioni dal web usando
s.jina.ai; - Genera una risposta iniziale con una citazione al risultato della ricerca dal passaggio precedente;
- Usa
r.jina.aiper ancorare la risposta con il tuo URL; oppure leggi gli URL inline dalla fonte restituita dal passaggio 3 per ottenere un ancoraggio più profondo; - Generazione della risposta finale e evidenziazione di potenziali affermazioni non ancorate all'utente.
tagLimiti di Velocità Più Alti con le API Key
Gli utenti possono utilizzare gratuitamente il nuovo endpoint di ricerca con ancoraggio senza autorizzazione. Inoltre, quando si fornisce una Jina AI API key nell'header della richiesta (la stessa chiave può essere utilizzata nelle API di Embedding/Reranking), si può immediatamente usufruire di 200 richieste al minuto per IP per r.jina.ai e 40 richieste al minuto per IP per s.jina.ai. I dettagli sono riportati nella tabella seguente:
| Endpoint | Descrizione | Limite richieste senza API key | Limite richieste con API key | Schema conteggio token | Latenza media |
|---|---|---|---|---|---|
r.jina.ai | Legge un URL e restituisce il suo contenuto, utile per verificare l'ancoraggio | 20 RPM | 200 RPM | Basato sui token di output | 3 secondi |
s.jina.ai | Ricerca sul web restituendo i primi 5 risultati, utile per l'ancoraggio della ricerca | 5 RPM | 40 RPM | Basato sui token di output per tutti i 5 risultati di ricerca | 30 secondi |
tagConclusione
Crediamo che l'ancoraggio sia essenziale per le applicazioni GenAI, e la creazione di soluzioni ancorate dovrebbe essere facile per tutti. È per questo che abbiamo introdotto il nuovo endpoint di ricerca con ancoraggio, s.jina.ai, che permette agli sviluppatori di incorporare facilmente la conoscenza del mondo nelle loro applicazioni GenAI. Vogliamo che gli sviluppatori stabiliscano la fiducia degli utenti, forniscano risposte spiegabili e ispirino la curiosità in milioni di utenti.
