



前回の投稿では、チャンキングの課題を探り、チャンクの埋め込み時のコンテキスト損失を減らすのに役立つレイトチャンキングの概念を紹介しました。今回の投稿では、もう1つの課題である最適な分割点の発見に焦点を当てます。私たちのレイトチャンキング戦略は不適切な境界に対してかなりの耐性があることが証明されていますが、これは境界を無視できるということではありません。境界は人間と LLM の両方の読みやすさにとって依然として重要です。私たちの視点は次の通りです:分割点を決定する際、意味やコンテキストの損失を心配することなく、読みやすさに完全に集中できます。レイトチャンキングは良い分割点も悪い分割点も処理できるので、読みやすさが主な関心事となります。
これを踏まえて、長文書を意味的一貫性を保ちながら分割し、複雑なコンテンツ構造を処理するように特別に設計された3つの小規模言語モデルを訓練しました。それらは:

simple-qwen-0.5:文書の構造要素に基づいてテキストを分割します。

topic-qwen-0.5:テキスト内のトピックに基づいてテキストを分割します。

summary-qwen-0.5:各セグメントの要約を生成します。
この投稿では、なぜこのモデルを開発したのか、3つのバリアントにどのようにアプローチしたのか、そしてJina AI の Segmenter API に対してどのようにベンチマークを行ったのかについて説明します。最後に、学んだことと今後の展望を共有します。
tagセグメンテーションの問題
セグメンテーションは RAG システムの中核要素です。長文書をどのように一貫性のある管理可能なセグメントに分割するかは、検索と生成の両方のステップの品質に直接影響を与え、回答の関連性から要約の品質まで、すべてに影響を及ぼします。従来のセグメンテーション手法は適度な結果を生み出してきましたが、限界がないわけではありません。
前回の投稿を言い換えると:
長文書をセグメント化する際の重要な課題は、セグメントをどこで作成するかを決定することです。これは固定トークン長、一定数の文、または正規表現や意味的セグメンテーションモデルなどのより高度な手法を使用して行うことができます。正確なセグメント境界を確立することは、検索結果の読みやすさを向上させるだけでなく、RAG システムで LLM に提供されるセグメントが正確で十分であることを保証するために重要です。
レイトチャンキングは検索パフォーマンスを向上させますが、RAG アプリケーションでは、可能な限りすべてのセグメントがランダムなテキストの断片ではなく、それ自体で意味を持つことを確保することが重要です。LLM は正確な応答を生成するために一貫性があり、よく構造化されたデータに依存しています。セグメントが不完全であったり意味が欠けている場合、レイトチャンキングの利点があるにもかかわらず、LLM はコンテキストと正確性に苦労し、全体的なパフォーマンスに影響を与える可能性があります。つまり、レイトチャンキングを使用するかどうかにかかわらず、効果的な RAG システムを構築するには堅実なセグメンテーション戦略が不可欠です(後のベンチマークセクションで見るように)。
改行や文などの単純な境界で内容を分割する方法や、厳密なトークンベースのルールを使用する従来のセグメンテーション手法は、同じような限界に直面します。どちらのアプローチも意味的な境界を考慮せず、あいまいなトピックの処理に苦労し、断片化されたセグメントにつながります。これらの課題に対応するため、私たちはセグメンテーション専用の小規模言語モデルを開発・訓練し、トピックの変化を捉え、一貫性を保ちながら、様々なタスクで効率的で適応可能なものとなるように設計しました。
tagなぜ小規模言語モデルなのか?
私たちは、従来のセグメンテーション技術で遭遇した特定の制限、特にコードスニペットやテーブル、リスト、数式などの複雑な構造を処理する際の制限に対応するために、Small Language Model (SLM) を開発しました。トークン数や厳格な構造的ルールに依存する従来のアプローチでは、意味的に一貫性のあるコンテンツの整合性を維持することが困難でした。例えば、コードスニペットは頻繁に複数の部分に分割され、そのコンテキストが破壊され、下流のシステムが正確に理解または検索することが困難になっていました。
専門的な SLM を訓練することで、これらの意味のある境界を知的に認識して保持し、関連要素を一緒に保つことができるモデルの作成を目指しました。これは RAG システムでの検索品質を向上させるだけでなく、一貫性のある文脈的に関連性のあるセグメントの維持が重要な要約や質問応答などの下流タスクも向上させます。SLM アプローチは、厳格な境界を持つ従来のセグメンテーション手法では単純に提供できない、より適応性が高く、タスク固有のソリューションを提供します。
tagSLM の訓練:3つのアプローチ
私たちは SLM の3つのバージョンを訓練しました:
simple-qwen-0.5は最も単純なモデルで、文書の構造要素に基づいて境界を識別するように設計されています。その単純さは、基本的なセグメンテーションニーズに対する効率的なソリューションとなっています。topic-qwen-0.5は Chain-of-Thought 推論に触発され、「第二次世界大戦の開始」などのテキスト内のトピックを識別し、これらのトピックを使用してセグメント境界を定義することで、セグメンテーションをさらに一歩進めています。このモデルは各セグメントがトピック的に一貫していることを確保し、複雑な多トピック文書に適しています。初期のテストでは、人間の直感に近い方法でコンテンツを分割することに優れていることが示されました。summary-qwen-0.5はテキストの境界を識別するだけでなく、各セグメントの要約も生成します。セグメントの要約は RAG アプリケーションで非常に有利です。特に長文書の質問応答などのタスクで有効ですが、訓練時により多くのデータを必要とするというトレードオフがあります。
すべてのモデルはセグメントヘッドのみを返します。これは各セグメントの切り詰めたバージョンです。モデルは入力コンテンツを単にコピーするのではなく、意味的な遷移に焦点を当てることで、境界検出と一貫性を向上させる重要なポイントやサブトピックを出力します。セグメントを取得する際、文書テキストはそれらのセグメントヘッドに基づいて分割され、それに応じて完全なセグメントが再構築されます。
tagデータセット
私たちはwiki727k データセットを使用しました。これは Wikipedia 記事から抽出された構造化テキストスニペットの大規模なコレクションです。イントロダクション、セクション、サブセクションなど、Wikipedia 記事の異なる部分を表す727,000以上のセクションが含まれています。
 koomri
koomritagデータ拡張
各モデルバリアントのトレーニングペアを生成するため、GPT-4 を使用してデータを拡張しました。トレーニングデータセット内の各記事に対して、以下のプロンプトを送信しました:
f"""
Generate a five to ten words topic and a one sentence summary for this chunk of text.
```
{text}
```
Make sure the topic is concise and the summary covers the main topic as much as possible.
Please respond in the following format:
```
Topic: ...
Summary: ...
```
Directly respond with the required topic and summary, do not include any other details, and do not surround your response with quotes, backticks or other separators.
""".strip()単純な分割を使用して各記事からセクションを生成し、\\n\\n\\nで分割し、さらに\\n\\nで分割して以下のようになりました(この例では、Common Gateway Interface に関する記事):
[
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
その後、セクション、トピック、要約を含む JSON 構造を生成しました:
{
"sections": [
[
"In computing, Common Gateway Interface (CGI) offers a standard protocol for web servers to execute programs that execute like Console applications (also called Command-line interface programs) running on a server that generates web pages dynamically.",
"Such programs are known as \\"CGI scripts\\" or simply as \\"CGIs\\".",
"The specifics of how the script is executed by the server are determined by the server.",
"In the common case, a CGI script executes at the time a request is made and generates HTML."
],
[
"In 1993 the National Center for Supercomputing Applications (NCSA) team wrote the specification for calling command line executables on the www-talk mailing list; however, NCSA no longer hosts the specification.",
"The other Web server developers adopted it, and it has been a standard for Web servers ever since.",
"A work group chaired by Ken Coar started in November 1997 to get the NCSA definition of CGI more formally defined.",
"This work resulted in RFC 3875, which specified CGI Version 1.1.",
"Specifically mentioned in the RFC are the following contributors: \\n1. Alice Johnson\\n2. Bob Smith\\n3. Carol White\\n4. David Nguyen\\n5. Eva Brown\\n6. Frank Lee\\n7. Grace Kim\\n8. Henry Carter\\n9. Ingrid Martinez\\n10. Jack Wilson",
"Historically CGI scripts were often written using the C language.",
"RFC 3875 \\"The Common Gateway Interface (CGI)\\" partially defines CGI using C, as in saying that environment variables \\"are accessed by the C library routine getenv() or variable environ\\"."
],
[
"CGI is often used to process inputs information from the user and produce the appropriate output.",
"An example of a CGI program is one implementing a Wiki.",
"The user agent requests the name of an entry; the Web server executes the CGI; the CGI program retrieves the source of that entry's page (if one exists), transforms it into HTML, and prints the result.",
"The web server receives the input from the CGI and transmits it to the user agent.",
"If the \\"Edit this page\\" link is clicked, the CGI populates an HTML textarea or other editing control with the page's contents, and saves it back to the server when the user submits the form in it.\\n",
"\\n# CGI script to handle editing a page\\ndef handle_edit_request(page_content):\\n html_form = f'''\\n <html>\\n <body>\\n <form action=\\"/save_page\\" method=\\"post\\">\\n <textarea name=\\"page_content\\" rows=\\"20\\" cols=\\"80\\">\\n {page_content}\\n </textarea>\\n <br>\\n <input type=\\"submit\\" value=\\"Save\\">\\n </form>\\n </body>\\n </html>\\n '''\\n return html_form\\n\\n# Example usage\\npage_content = \\"Existing content of the page.\\"\\nhtml_output = handle_edit_request(page_content)\\nprint(\\"Generated HTML form:\\")\\nprint(html_output)\\n\\ndef save_page(page_content):\\n with open(\\"page_content.txt\\", \\"w\\") as file:\\n file.write(page_content)\\n print(\\"Page content saved.\\")\\n\\n# Simulating form submission\\nsubmitted_content = \\"Updated content of the page.\\"\\nsave_page(submitted_content)"
],
[
"Calling a command generally means the invocation of a newly created process on the server.",
"Starting the process can consume much more time and memory than the actual work of generating the output, especially when the program still needs to be interpreted or compiled.",
"If the command is called often, the resulting workload can quickly overwhelm the server.",
"The overhead involved in process creation can be reduced by techniques such as FastCGI that \\"prefork\\" interpreter processes, or by running the application code entirely within the web server, using extension modules such as mod_perl or mod_php.",
"Another way to reduce the overhead is to use precompiled CGI programs, e.g.",
"by writing them in languages such as C or C++, rather than interpreted or compiled-on-the-fly languages such as Perl or PHP, or by implementing the page generating software as a custom webserver module.",
"Several approaches can be adopted for remedying this: \\n1. Implementing stricter regulations\\n2. Providing better education and training\\n3. Enhancing technology and infrastructure\\n4. Increasing funding and resources\\n5. Promoting collaboration and partnerships\\n6. Conducting regular audits and assessments",
"The optimal configuration for any Web application depends on application-specific details, amount of traffic, and complexity of the transaction; these tradeoffs need to be analyzed to determine the best implementation for a given task and time budget."
]
],
"topics": [
"Web サーバーにおける Common Gateway Interface",
"CGI の歴史と標準化",
"Web ページ編集用の CGI スクリプト",
"コマンド実行におけるWeb サーバーのオーバーヘッド削減"
],
"summaries": [
"CGI は Web サーバーが動的なウェブページを生成するプログラムを実行するためのプロトコルを提供します。",
"NCSA が1993年に CGI を定義し、Web サーバーの標準として採用され、後に Ken Coar 議長のもと RFC 3875 として正式化されました。",
"このテキストは、CGI スクリプトが HTML フォームを通じてウェブページの内容を編集・保存する方法を説明しています。",
"頻繁なコマンド実行によるサーバーのオーバーヘッドを最小限に抑えるため、プロセスのプリフォーク、プリコンパイル済み CGI プログラムの使用、カスタム Web サーバーモジュールの実装などの技術について説明しています。"
]
}
また、データをシャッフルしたり、ランダムな文字/単語/文字を追加したり、句読点をランダムに削除したり、そして必ず改行文字を削除することでノイズを追加しました。
これらはすべて良いモデルを開発する上で一定の効果がありますが、それには限界があります。本当に全力を尽くすためには、コードスニペットを壊すことなく、モデルが一貫した塊を作成する必要がありました。そのために、GPT-4o で生成したコード、数式、リストでデータセットを拡張しました。
tagトレーニングのセットアップ
モデルのトレーニングには、以下のセットアップを実装しました:
- フレームワーク:Hugging Face の
transformersライブラリをUnslothと統合してモデルの最適化を行いました。これはメモリ使用量を最適化し、トレーニングを高速化するために重要で、大規模なデータセットで小規模なモデルを効果的に訓練することを可能にしました。 - オプティマイザとスケジューラ:初期エポックでトレーニングプロセスを安定させるため、線形学習率スケジュールとウォームアップステップを備えた AdamW オプティマイザを使用しました。
- 実験の追跡:すべてのトレーニング実験を Weights & Biases で追跡し、トレーニングと検証のロス、学習率の変化、モデル全体のパフォーマンスなどの主要な指標を記録しました。このリアルタイムの追跡により、モデルの進捗状況を把握でき、学習成果を最適化するために必要に応じて素早い調整が可能になりました。
tagトレーニング自体
qwen2-0.5b-instruct をベースモデルとして使用し、異なるセグメンテーション戦略を念頭に置いた 3 つのバリエーションの SLM を Unsloth でトレーニングしました。サンプルとして、wiki727k の記事のテキストと、トレーニングするモデルに応じて得られた sections、topics、または summaries(上記の「データ拡張」セクションで言及)からなるトレーニングペアを使用しました。
simple-qwen-0.5:10,000 サンプルで 5,000 ステップトレーニングを行い、迅速な収束を達成し、テキストの一貫したセクション間の境界を効果的に検出しました。トレーニングロスは 0.16 でした。topic-qwen-0.5:simple-qwen-0.5と同様に、10,000 サンプルで 5,000 ステップトレーニングを行い、トレーニングロス 0.45 を達成しました。summary-qwen-0.5:30,000 サンプルで 15,000 ステップトレーニングを行いました。このモデルは有望な結果を示しましたが、トレーニング中のロスが高く(0.81)、その潜在能力を十分に発揮するにはより多くのデータ(元のサンプル数の約 2 倍)が必要であることを示唆しています。
tagセグメント自体について
各セグメンテーション戦略と Jina の Segmenter API による連続する 3 つのセグメントの例を示します。これらのセグメントを生成するために、まず Jina Reader を使用して Jina AI ブログの投稿をプレーンテキストとしてスクレイピングし(ヘッダー、フッターなどのすべてのページデータを含む)、その後各セグメンテーション手法に渡しました。

tagJina Segmenter API
Jina Segmenter API は投稿の分割に非常に細かいアプローチを取り、\n、\t などの文字で分割して、しばしば非常に小さなセグメントに分割しました。最初の 3 つを見ただけでも、ウェブサイトのナビゲーションバーから search\\n、notifications\\n、NEWS\\n を抽出しましたが、投稿の内容に関連するものは何も抽出されませんでした:

さらに進むと、ようやくブログ投稿の実際の内容からのセグメントが得られましたが、それぞれのコンテキストはほとんど保持されていませんでした:

(公平を期すため、Segmenter API については他のモデルよりも多くのチャンクを示しました。そうしなければ、意味のあるセグメントがほとんど表示されなかったためです)
tagsimple-qwen-0.5
simple-qwen-0.5 はブログ投稿を意味的構造に基づいて分解し、一貫した意味を持つより長いセグメントを抽出しました:
tagtopic-qwen-0.5
topic-qwen-0.5 はまず文書の内容に基づいてトピックを特定し、それらのトピックに基づいて文書をセグメント化しました:
tagsummary-qwen-0.5
summary-qwen-0.5 はセグメントの境界を特定し、各セグメント内の内容の要約を生成しました:
tagモデルのベンチマーク
モデルのパフォーマンスをベンチマークするために、Jina AI ブログから 8 つのブログ投稿をスクレイピングし、GPT-4o を使用して 6 つの質問と正解を生成しました。
Jina Segmenter API を含む各セグメンテーション手法をこれらのブログ投稿に適用し、その結果得られたセグメントに対して jina-embeddings-v3 を使用して、後期チャンキングやリランキングを行わずに埋め込みを生成しました。

その後、各セグメントセットを別々にインデックス化し、前に生成した質問を使って各インデックスに対して RAG システムでクエリを実行しました。
topic-qwen-0.5 と summary-qwen-0.5 のテスト時には、生成されたサマリーやトピックは含めず、セグメント自体のみをインデックス化しました。この追加データをインデックス化すれば、さらにパフォーマンスが向上する可能性があります。パフォーマンスを測定するために、各分割方法のインデックスから生成された回答を、ROUGE-L 評価の F1 スコアを使用して正解と比較しました。スコアが高いほど、パフォーマンスが良いことを示します。
例えば、「jina-embeddings-v2-base-en モデルの数値比較能力に影響を与える要因は何か?」という質問に対して、以下のような回答を得ました:
tag正解(全文から GPT-4o が生成):
"The two key factors are tokenization and training data. Tokenization determines how numbers are segmented into tokens, and training data influences numerical reasoning abilities."
tagJina Segmenter API(スコア:0.166667)
"The context does not provide specific factors that impact the numerical comparison abilities of the jina-embeddings-v2-base-en model."
tagsimple-qwen-0.5(スコア:0.279070)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by tokenization and training data."
tagtopic-qwen-0.5(スコア:0.190476)
"The numerical comparison abilities of the jina-embeddings-v2-base-en model are impacted by factors such as tokenization and its ability to handle different numerical formats, including small integers, large numbers, floats, negative numbers, currency, dates, and times."
tagsummary-qwen-0.5(0.318182)
"The factors impacting the numerical comparison abilities of the jina-embeddings-v2-base-en model are tokenization and training data."
topic-qwen-0.5 のスコアがこんなに低いのか?これは主にモデルに尋ねた特定の質問に基づく偶然の結果です。下の表に示されているように、
topic-qwen-0.5 の平均 ROUGE スコアは、すべての分割手法の中で最も高くなっています。また、各手法の速度(セグメントの生成と埋め込みにかかる時間を計測)とディスク容量(埋め込み数に jina-embeddings-v3 の 1024 次元の単一埋め込みのサイズを掛けて推定)も評価しました。これにより、異なる分割戦略の精度と効率性の両方を評価することができました。
tag主な発見
モデルのバリエーションを互いに、そして Jina の Segmenter API と比較テストした結果、新しいモデルは特にトピック分割において、すべての 3 つの手法で改善されたスコアを示しました:
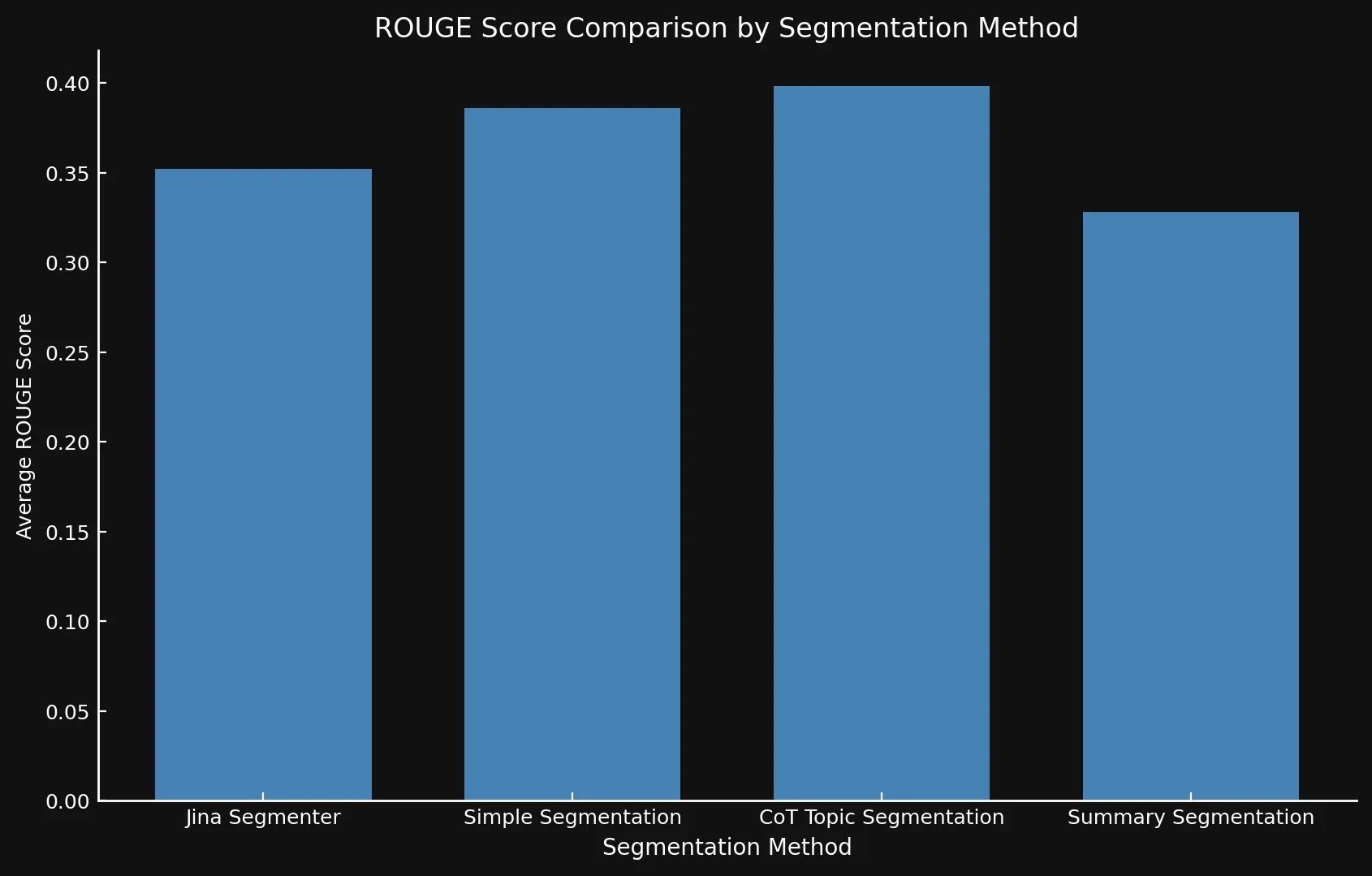
| Segmentation Method | Average ROUGE Score |
|---|---|
| Jina Segmenter | 0.352126 |
simple-qwen-0.5 |
0.386096 |
topic-qwen-0.5 |
0.398340 |
summary-qwen-0.5 |
0.328143 |
summary-qwen-0.5 の ROUGE スコアは topic-qwen-0.5 より低いのでしょうか?端的に言えば、summary-qwen-0.5 はトレーニング中により高い損失を示し、より良い結果を得るにはさらなるトレーニングが必要であることが明らかになりました。これは今後の実験のテーマとなるかもしれません。ただし、セグメントの埋め込みのコンテキストの関連性を高め、より関連性の高い結果を提供する jina-embeddings-v3 の遅延チャンキング機能を使用した結果を確認するのも興味深いでしょう。これは将来のブログ投稿のテーマになるかもしれません。
速度に関しては、後者が API である一方で、3 つのモデルを Nvidia 3090 GPU で実行したため、新しいモデルと Jina Segmenter を比較するのは難しい場合があります。Segmenter API の高速な分割ステップで得られたパフォーマンスの向上は、多数のセグメントの埋め込みを生成する必要性によってすぐに相殺されてしまいます:
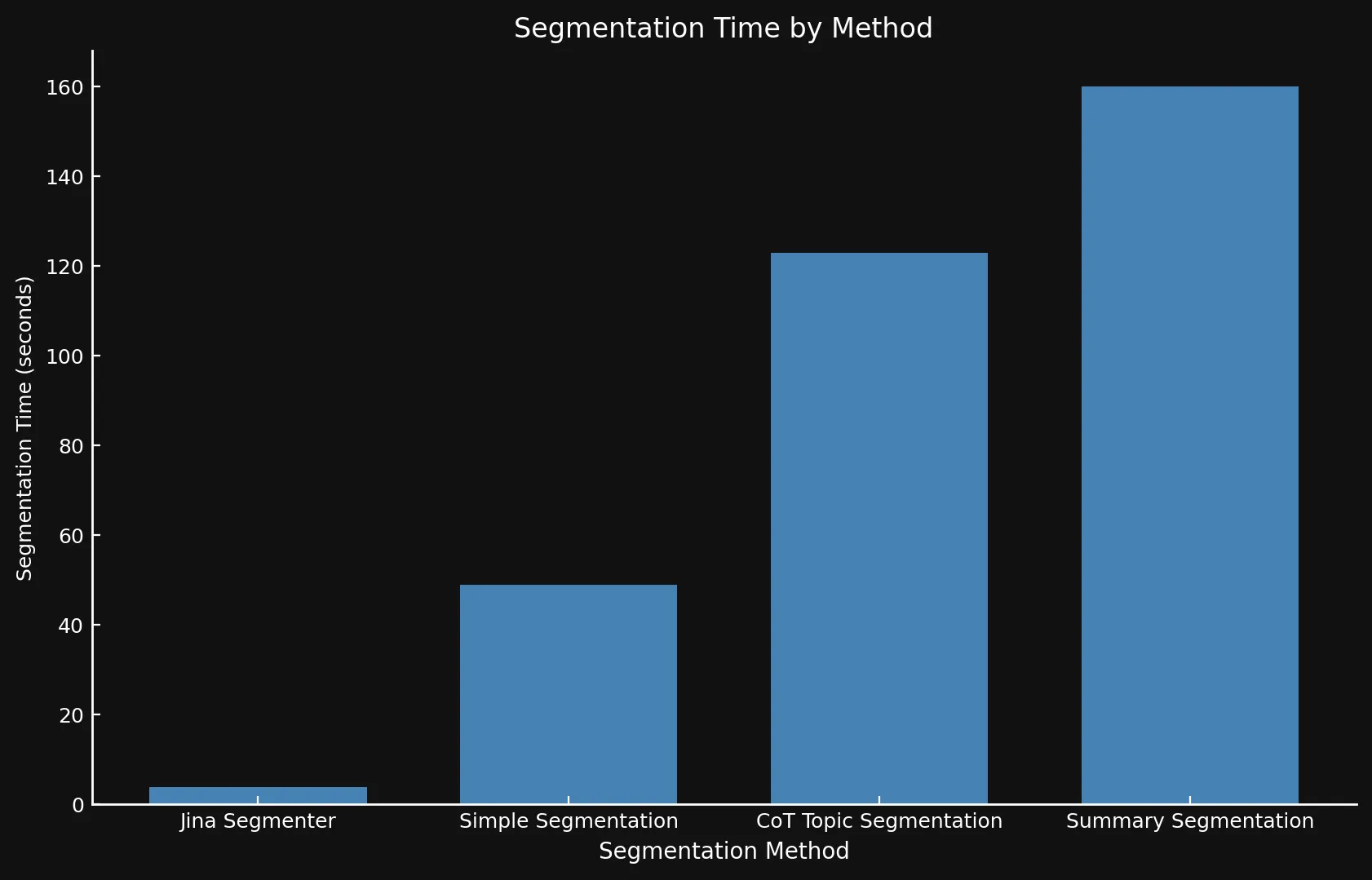
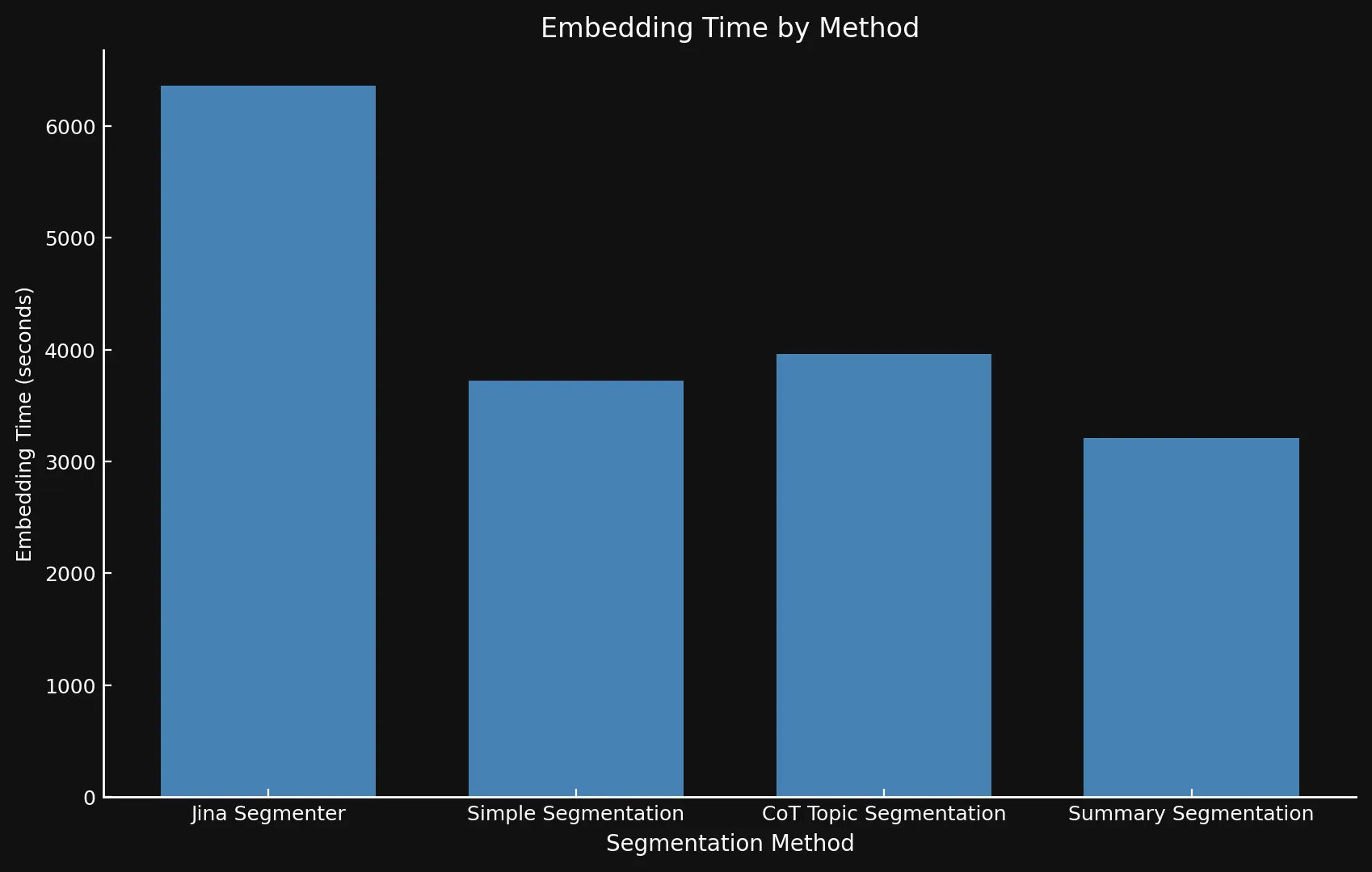
• 両グラフで異なる Y 軸を使用しています。これほど異なる時間枠を 1 つのグラフまたは一貫した Y 軸で表示することは現実的ではありませんでした。
• これは純粋な実験として行ったため、埋め込みの生成時にバッチ処理を使用しませんでした。バッチ処理を行えば、すべての手法で大幅な速度向上が見込めます。
当然、セグメントが多いということは、埋め込みも多いということです。そしてこれらの埋め込みは多くの容量を占めます:テストに使用した 8 つのブログ投稿の埋め込みは、Segmenter API では 21 MB 以上を占めましたが、Summary Segmentation では 468 KB と軽量でした。これに加えて、私たちのモデルからの高い ROUGE スコアは、より少ないセグメントでより良いセグメントが得られることを意味し、コストを節約しながらパフォーマンスを向上させます:
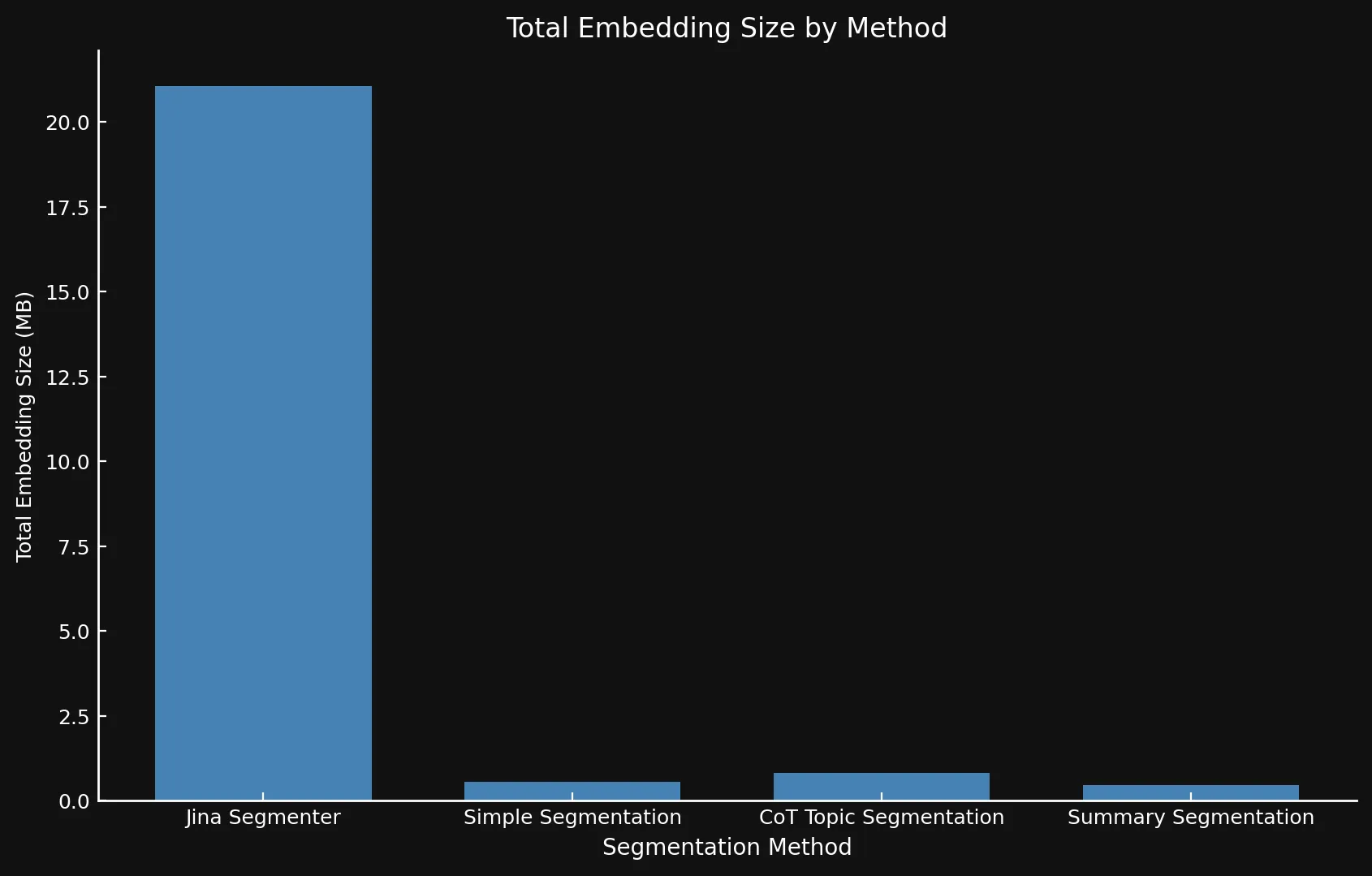
| Segmentation Method | Segment Count | Average Length (characters) | Segmentation Time (minutes/seconds) | Embedding Time (hours/minutes) | Total Embedding Size |
|---|---|---|---|---|---|
| Jina Segmenter | 1,755 | 82 | 3.8s | 1h 46m | 21.06 MB |
simple-qwen-0.5 |
48 | 1,692 | 49s | 1h 2m | 576 KB |
topic-qwen-0.5 |
69 | 1,273 | 2m 3s | 1h 6m | 828 KB |
summary-qwen-0.5 |
39 | 1,799 | 2m 40s | 53m | 468 KB |
tag学んだこと
tag問題設定が重要
重要な洞察の1つは、タスクの枠組みの影響でした。モデルにセグメントヘッドを出力させることで、単に入力コンテンツを別々のセグメントにコピー&ペーストするのではなく、意味的な遷移に焦点を当てることで、境界の検出と一貫性を改善しました。また、生成するテキストが少なくなったことで、モデルがタスクをより迅速に完了できるようになり、より高速なセグメンテーションモデルとなりました。
tagLLM生成データの効果
リスト、数式、コードスニペットなどの複雑なコンテンツに特に LLM 生成データを使用することで、モデルのトレーニングセットを拡大し、多様なドキュメント構造を処理する能力が向上しました。これにより、モデルはさまざまなコンテンツタイプに対応できるようになり、技術的または構造化されたドキュメントを扱う際に重要な利点となりました。
tag出力専用データコレーション
出力専用のデータコレーターを使用することで、トレーニング中に入力からの単なるコピーではなく、ターゲットトークンの予測にモデルが集中できるようになりました。出力専用コレーターにより、モデルは実際のターゲットシーケンスから学習し、正しい補完や境界を強調することができました。この区別により、モデルは入力へのオーバーフィッティングを避けて収束が早くなり、異なるデータセット間でのより良い一般化が可能になりました。
tagUnslothによる効率的なトレーニング
Unslothを使用することで、小規模な言語モデルのトレーニングを効率化し、Nvidia 4090 GPU で実行することができました。この最適化されたパイプラインにより、大規模な計算リソースを必要とせずに、効率的で高性能なモデルをトレーニングすることができました。
tag複雑なテキストの処理
セグメンテーションモデルは、従来の手法では通常困難なコード、表、リストを含む複雑なドキュメントの処理に優れていました。技術的なコンテンツに関しては、topic-qwen-0.5やsummary-qwen-0.5などの高度な戦略がより効果的で、下流の RAG タスクを強化する可能性を持っています。
tagシンプルなコンテンツにはシンプルな方法
ストレートな物語主導のコンテンツには、Segmenter API のようなシンプルな方法で十分です。高度なセグメンテーション戦略は、より複雑で構造化されたコンテンツにのみ必要となる可能性があり、ユースケースに応じて柔軟に対応できます。
tag次のステップ
この実験は主に概念実証として設計されましたが、さらに拡張する場合、いくつかの改善が可能です。まず、この特定の実験の継続は考えにくいものの、summary-qwen-0.5を30,000サンプルではなく理想的には60,000サンプルの大規模なデータセットでトレーニングすることで、より最適なパフォーマンスが得られる可能性があります。また、ベンチマーキングプロセスの改善も有益でしょう。RAGシステムから生成された LLM の回答を評価する代わりに、取得されたセグメントを直接グランドトルースと比較することに焦点を当てます。最後に、ROUGE スコアを超えて、取得とセグメンテーションの品質のニュアンスをより良く捉える高度なメトリクス(おそらく ROUGE と LLM スコアリングの組み合わせ)を採用します。
tag結論
この実験では、特定のタスク向けにカスタマイズされたセグメンテーションモデルが RAG のパフォーマンスをどのように向上させることができるかを探りました。simple-qwen-0.5、topic-qwen-0.5、summary-qwen-0.5などのモデルを開発・トレーニングすることで、意味的な一貫性の維持やコードスニペットなどの複雑なコンテンツの効果的な処理など、従来のセグメンテーション手法に見られる主要な課題に対処しました。テストしたモデルの中で、topic-qwen-0.5は特にマルチトピックドキュメントにおいて、最も意味のある文脈的に関連性の高いセグメンテーションを一貫して提供しました。
セグメンテーションモデルは RAG システムに必要な構造的基盤を提供しますが、セグメント間の文脈的関連性を維持して検索パフォーマンスを最適化する後期チャンキングとは異なる機能を果たします。これらの2つのアプローチは相補的になり得ますが、セグメンテーションは特に、一貫性のあるタスク固有の生成ワークフロー向けにドキュメントを分割する方法が必要な場合に重要です。
